Downloaded 13 times








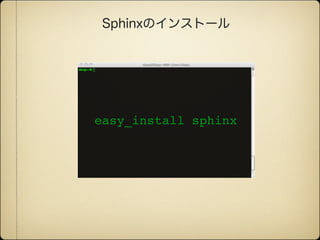






Sphinx is a tool that generates documentation from reStructuredText source files. It can generate HTML, LaTeX, and other formats. Sphinx focuses on hand-written documentation rather than auto-generated API docs. The document provides information on installing Sphinx and converting documentation from other formats like HTML, LaTeX, and Docbook to the Sphinx reStructuredText format.















































