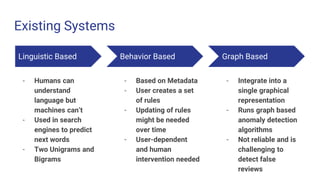
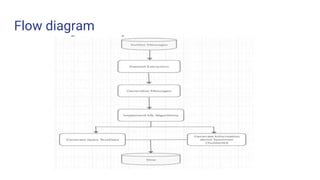
The document discusses spam detection using machine learning. It outlines the problems of fake reviews, malicious tweets, and false information online. Existing detection systems are described as linguistic-based, behavior-based, or graph-based, each with advantages and limitations. The proposed solution uses both behavioral and linguistic features to identify spam. These include early time frames, rating deviations, personal pronouns, content similarity, and burstiness of reviews. The implementation flow diagram and advantages of reducing spam through an accurate, statistics-based approach with less human interaction are presented.