Downloaded 37 times






![Study - Data Structures
public class Selection_sort<E> {
//selection sort
public static <E extends Comparable<E>> void
selectionSort(E[] list) {
for(int i=0; i<list.length -1; i++) {
int iSmallest = i;
for(int j=i+1; j<list.length; j++) {
if(list[iSmallest].compareTo((list[j])) > 0
) {
iSmallest = j;
}
}
E iSwap = list[iSmallest];
list[iSmallest] = list[i];
list[i] = iSwap;
}
}
}
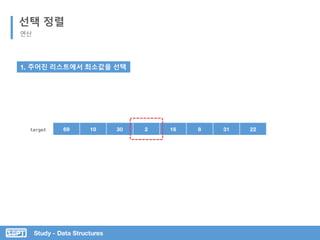
선택 정렬
코드 분석
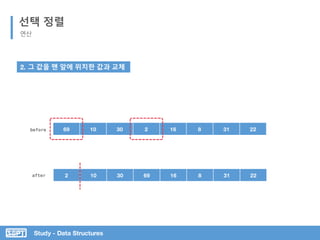
주어진 리스트에서 최소값을 찾는다 (isSmallest)
찾은 최소값을 리스트의 맨 앞의 원소와 교체
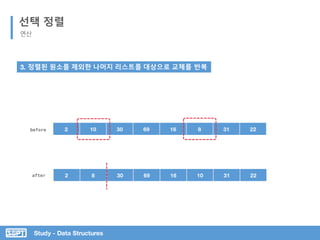
교체된 맨 앞의 원소를 제외한 나머지 리스트를
대상으로 반복 실행](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-10-320.jpg)




![Study - Data Structures
public class Insertion_sort<T> {
public <T extends Comparable<T>> void
doInsertionSort(T[] input) {
if (input == null) {
throw new RuntimeException("Input array
cannot be null");
}
int length = input.length;
if (length == 1) return;
int i, j;
T temp;
for (i = 1; i < length; i++) {
temp = input[i];
for (j = i; (j > 0 &&
(temp.compareTo(input[j - 1]) < 0)); j--) {
input[j] = input[j - 1];
}
input[j] = temp;
}
}
}
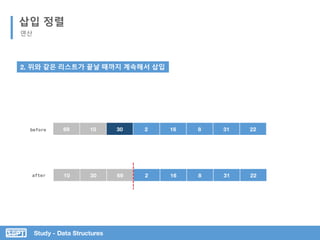
삽입 정렬
코드 분석
두번째 원소 부터 앞의 정렬된 리스트와 비교하여
적절한 자리에 삽입
정렬하고자 하는 원소를 temp에 임의 저장
삽입 된 후 다음 원소(세번째 원소)를 대상으로
반복 실행](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-16-320.jpg)





![Study - Data Structures
public class Bubble_sort<E> {
public static <E> void bubbleSort(E[] unsorted) {
for(int iter =1; iter< unsorted.length; iter++){
for(int inner = 0; inner < unsorted.length - iter; inner
++){
if((((Comparable)(unsorted[inner])).compareTo(unsorted[inner+1])) >
0){
E tmp = unsorted[inner];
unsorted[inner] = unsorted[inner + 1];
unsorted[inner + 1] = tmp;
}
}
}
}
}
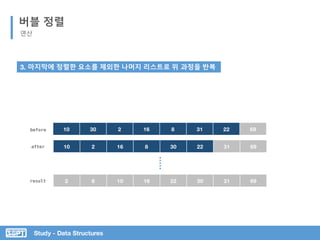
버블 정렬
코드 분석
리스트의 첫 원소부터 바로 인접한 다음
원소와 비교
두 원소를 비교하여 더 큰 원소를
temp 에 저장하고 둘 중 뒤에 배열
같은 방법으로 가장 큰 수가 리스트의
가장 마지막에 정렬될 때까지 반복 실행
정렬 된 리스트를 제외한 나머지를 대상으로
반복 실행](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-23-320.jpg)



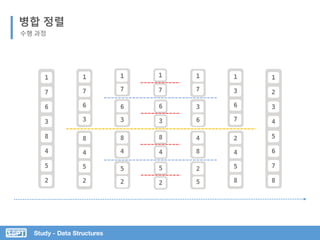
![병합 정렬
Study - Data Structures
최소 원소를 가질 때 까지 두 부분으로 분할
public class MergeSort<T> {
public <T extends Comparable<T>> void MergeSort(T[] a) {
MergeSort(a, 0, a.length - 1);
}
public <T extends Comparable<T>> void MergeSort(T[] a,
int left, int right){
if (right - left < 1) return;
int mid = (left + right) / 2;
MergeSort(a, left, mid);
MergeSort(a, mid + 1, right);
merge(a, left, mid, right);
}
코드 분석](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-29-320.jpg)
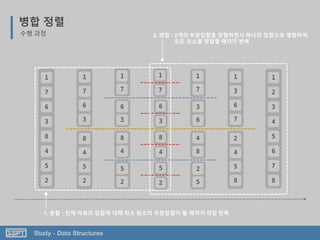
![Study - Data Structures
병합 정렬
코드 분석
public <T extends Comparable<T>> void merge(T[] a, int left,
int mid, int right) {
Object[] tmp = new Object[right - left + 1];
int L = left;
int R = mid + 1;
int S = 0;
while (L <= mid && R <= right) {
if (a[L].compareTo(a[R]) <= 0)
tmp[S] = a[L++];
else
tmp[S] = a[R++];
S++;
}
if (L <= mid && R > right) {
while (L <= mid)
tmp[S++] = a[L++];
} else {
while (R <= right)
tmp[S++] = a[R++];
}
for (S = 0; S < tmp.length; S++) {
a[S + left] = (T) (tmp[S]);
}
}
}
왼쪽, 오른쪽 파트 중 한 쪽이 다 정렬 될 때까지
부분 집합의 원소를 비교하며 병합
오른쪽파트가 먼저 정렬이 끝난 경우
데이터 이동
왼쪽파트가 먼저 정렬이 끝난 경우](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-30-320.jpg)



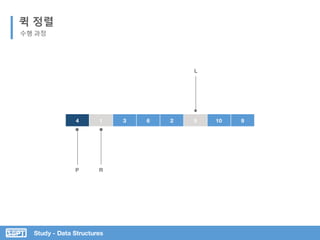
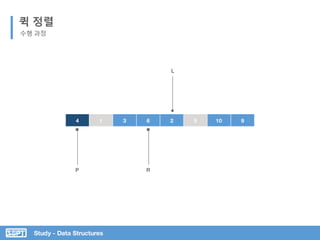
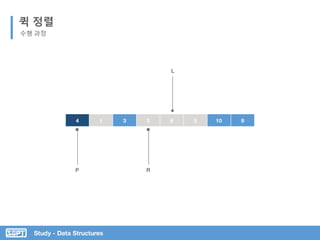
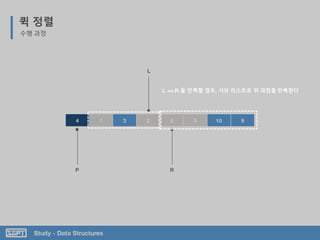
![Study - Data Structures
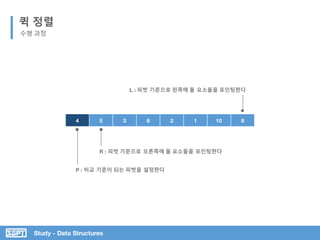
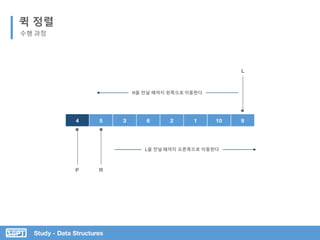
L은 오른쪽 이동하며 Pivot보다
크거나 같은 값 찾기
R은 왼쪽 이동하며 Pivot 보다
작은 값 찾기
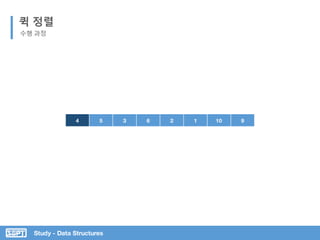
퀵 정렬
코드 분석
public class QuickSort<T> {
public <T extends Comparable<T>> void QuickSort(T[] array) {
quick_sort(array, 0, array.length - 1);
}
public static <T extends Comparable<T>> void quick_sort(T[]
arr, int left, int right) {
if (left < right) {
int L = left, R = right;
T pivot = arr[(L + R) / 2];
do {
while (arr[L].compareTo(pivot) < 0) L++;
while (pivot.compareTo(arr[R]) < 0) R--;
if (L <= R) {
T tmp = arr[L];
arr[L] = arr[R];
arr[R] = tmp;
L++;
R--;
}
} while (L <= R);
quick_sort(arr, left, R);
quick_sort(arr, L, right);
}
}
}
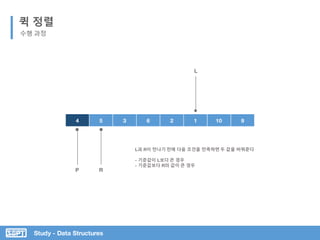
서브 리스트로 위 과정을 반복
Pivot 값을 임의 지정
L과 R이 가르키는 값 바꾸기](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-42-320.jpg)




![Study - Data Structures
기수 정렬
수행 과정
1. 원소의 키 값에 해당하는 큐에 원소를 분배
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
69 10 30 2 16before
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-47-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
1. 원소의 키 값에 해당하는 큐에 원소를 분배
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
69
69 10 30 2 16before
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-48-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
1. 원소의 키 값에 해당하는 큐에 원소를 분배
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
10 69
69 10 30 2 16before
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-49-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
1. 원소의 키 값에 해당하는 큐에 원소를 분배
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
10 69
30
69 10 30 2 16before
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-50-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
1. 원소의 키 값에 해당하는 큐에 원소를 분배
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
10 2 69
30
69 10 30 2 16before
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-51-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
1. 원소의 키 값에 해당하는 큐에 원소를 분배
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
10 2 16 69
30
69 10 30 2 16before
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-52-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
10 2 16 69
30
69 10 30 2 16
10
before
after
2. 버켓의 순서대로 원소를 꺼내 재분배](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-53-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
30 2 16 69
69 10 30 2 16
10 30
before
2. 버켓의 순서대로 원소를 꺼내 재분배
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-54-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
2 16 69
69 10 30 2 16
10 30 2
before
2. 버켓의 순서대로 원소를 꺼내 재분배
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-55-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
16 69
69 10 30 2 16
10 30 2 16
before
2. 버켓의 순서대로 원소를 꺼내 재분배
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-56-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
69
69 10 30 2 16
10 30 2 16 69
before
2. 버켓의 순서대로 원소를 꺼내 재분배
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-57-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
69 10 30 2 16
10 30 2 16 69
before
2. 버켓의 순서대로 원소를 꺼내 재분배
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-58-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
2 10 30 69
16
10 30 2 16 69before
3. 키 값의 자릿수만큼 위의 과정을 반복
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-59-320.jpg)
![Study - Data Structures
기수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
2 10 30 69
16
10 30 2 16 69
2 10 16 30 69
before
3. 키 값의 자릿수만큼 위의 과정을 반복
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-60-320.jpg)
![Study - Data Structures
기수 정렬
코드 분석
원소들의 최대 자릿수를 구해줌
큐 생성
큐에 넣어주는 과정
public void radixsort(T[] arr){
int max_digit = 0;
//최대 자릿수를 구해줌
for(int i=0; i< arr.length; i++) {
if(arr[i].toString().length() > max_digit)
max_digit =arr[i].toString().length();
}
Queue<T>[] queues = new Queue[52];
for(int i=0; i<queues.length;i++){
queues[i] = new Queue<T>();
}
for(int i=0;i<max_digit;i++) {
for (int j = 0; j < arr.length; j++) {
Node<T> node = new Node(arr[j]);
int digit = arr[j].toString().length() -
(i+1);
if(digit<0){
queues[0].enqueue(node);
}else {
String idx =
arr[j].toString().substring(digit, digit + 1);
char[] chars = idx.toCharArray();
if(chars[0]>=48 && chars[0]<=57) { //
숫자일 경우
queues[Integer.parseInt(idx)].enqueue(node);
}else{ //문자일 경우
queues[alphaToInt(chars[0])].enqueue(node);
}
}
}
비교할 자릿수를 구해줌(digit)
숫자일 경우와 문자일 경우로 나누어
enqueue 해줌](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-61-320.jpg)
![Study - Data Structures
기수 정렬
코드 분석
큐에서 차례대로 꺼내어 정렬
int newArrayIndex=0;
for (int j = 0; j < queues.length; j++) {
while (!queues[j].isEmpty()) {
arr[newArrayIndex++] =
queues[j].dequeue().t;
}
}
}
}
private int alphaToInt(char alphabet){
if(alphabet>=65 && alphabet<=90) return (alphabet-
65); // 대문자
else return (alphabet-97+26); //소문자
}](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-62-320.jpg)





![Study - Data Structures
계수 정렬
수행 과정
1. 해당 원소의 값을 인덱스로 하는 count 배열을 사용하여 각 원소의 개수를 셈
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
0 0 0 0 0 0 0 0 0 0
9 1 7 2 1 8 1 2before
after](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-69-320.jpg)
![Study - Data Structures
계수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
0 3 2 0 0 0 0 1 1 1
9 1 7 2 1 8 1 2before
count
after
1. 해당 원소의 값을 인덱스로 하는 count 배열을 사용하여 각 원소의 개수를 셈](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-70-320.jpg)
![Study - Data Structures
계수 정렬
수행 과정
2. count 배열의 첫 원소부터 차례대로 갯수를 세어 재배치
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
0 3 2 0 0 0 0 1 1 1
9 1 7 2 1 8 1 2
1 1 1
before
after
count](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-71-320.jpg)
![Study - Data Structures
계수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
0 3 2 0 0 0 0 1 1 1
9 1 7 2 1 8 1 2
1 1 1 2 2
before
after
count
2. count 배열의 첫 원소부터 차례대로 갯수를 세어 재배치](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-72-320.jpg)
![Study - Data Structures
계수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
0 3 2 0 0 0 0 1 1 1
9 1 7 2 1 8 1 2
1 1 1 2 2 7
before
after
count
2. count 배열의 첫 원소부터 차례대로 갯수를 세어 재배치](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-73-320.jpg)
![Study - Data Structures
계수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
0 3 2 0 0 0 0 1 1 1
9 1 7 2 1 8 1 2
1 1 1 2 2 7 8
before
after
count
2. count 배열의 첫 원소부터 차례대로 갯수를 세어 재배치](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-74-320.jpg)
![Study - Data Structures
계수 정렬
수행 과정
queue[0] queue[1] queue[2] queue[3] queue[4] queue[5] queue[6] queue[7] queue[8] queue[9]
0 3 2 0 0 0 0 1 1 1
9 1 7 2 1 8 1 2
1 1 1 2 2 7 8 9
before
after
count
2. count 배열의 첫 원소부터 차례대로 갯수를 세어 재배치](https://image.slidesharecdn.com/3-151013102240-lva1-app6892/85/SOPT-03-75-320.jpg)




[소스 코드] https://github.com/donghyundonghyun/Sorting https://github.com/henlix/counting-sort [설명] 대학생 연합 IT 벤처 창업 동아리 S.O.P.T (Shout Our Passion Together - http://sopt.org) 에서 내부적으로 진행하는 전공 과목 기초 스터디 자료입니다. 이번주에 배운 내용은 대학 서적에서 주로 다루는 정렬 (기본, 효율, 초효율) 에 대한 것입니다. 스터디 자료는 다음과 같은 순서대로 올라갈 예정입니다. 1. 데이터 구조 및 알고리즘 2. 운영체제 3. 네트워크
![[SOPT] 데이터 구조 및 알고리즘 스터디 - #05 : AVL 트리](https://cdn.slidesharecdn.com/ss_thumbnails/5-151013102305-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SOPT] 데이터 구조 및 알고리즘 스터디 - #04 : 트리 기초, 이진 트리, 우선순위 큐](https://cdn.slidesharecdn.com/ss_thumbnails/4-151013103145-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SOPT] 데이터 구조 및 알고리즘 스터디 - #02 : 스택, 큐, 수식 연산](https://cdn.slidesharecdn.com/ss_thumbnails/2-150829011309-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SOPT] 데이터 구조 및 알고리즘 스터디 - #01 : 개요, 점근적 복잡도, 배열, 연결리스트](https://cdn.slidesharecdn.com/ss_thumbnails/1-150824001021-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Swift] Data Structure - Dequeue](https://cdn.slidesharecdn.com/ss_thumbnails/swiftdatastructure-dequeue-200527055025-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[Swift] Data Structure - Binary Search Tree](https://cdn.slidesharecdn.com/ss_thumbnails/swiftdatastructure-binarysearchtree-200603091904-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Swift] Data Structure - Heap](https://cdn.slidesharecdn.com/ss_thumbnails/swiftdatastructure-heap-200529005142-thumbnail.jpg?width=640&height=640&fit=bounds)

![[SOPT] Core Team 회의정리](https://cdn.slidesharecdn.com/ss_thumbnails/cdocumentsandsettingsgfgfgcore-091025104729-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Nux]12 nux](https://cdn.slidesharecdn.com/ss_thumbnails/nux12nux-121126230107-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[MSD01]Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/msd01introduction-130308012312-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Msd12]interface design123](https://cdn.slidesharecdn.com/ss_thumbnails/msd12interfacedesign123-130528082439-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[I3 d]11 designui(2)](https://cdn.slidesharecdn.com/ss_thumbnails/i3d11designui2-121121002752-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Nux]09 nux](https://cdn.slidesharecdn.com/ss_thumbnails/nux09nux-121114224052-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Info01]introduction](https://cdn.slidesharecdn.com/ss_thumbnails/info01introduction-150310064403-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Msd02]mobile servicedesign](https://cdn.slidesharecdn.com/ss_thumbnails/msd02mobileservicedesign-130312084407-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Info04]visual thinking02](https://cdn.slidesharecdn.com/ss_thumbnails/info04visualthinking02-150508114525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Info02]definition](https://cdn.slidesharecdn.com/ss_thumbnails/info02definition-130315051430-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






![[데브루키]노대영_알고리즘 스터디](https://cdn.slidesharecdn.com/ss_thumbnails/devrookiealgorithm-180926091907-thumbnail.jpg?width=640&height=640&fit=bounds)




![[D2CAMPUS] Algorithm tips - ALGOS](https://cdn.slidesharecdn.com/ss_thumbnails/algospart1-d2-170223060957-thumbnail.jpg?width=640&height=640&fit=bounds)







![[알고리즘 스터디 2주차]병합정렬/퀵정렬/힙정렬](https://cdn.slidesharecdn.com/ss_thumbnails/2mergequickheap-161127154726-thumbnail.jpg?width=640&height=640&fit=bounds)


