Downloaded 10 times










![Test Characteristics
Kaner, Falk, and Nguyen [Kan93] suggest the following
attributes of a ―good‖ test:
• A good test has a high probability of finding an error
• A good test is not redundant
• A good test should be ―best of breed‖
• A good test should be neither too simple nor too complex](https://image.slidesharecdn.com/unit-4-240520104741-b0d72a4c/85/Software-Engineering-TESTING-AND-MAINTENANCE-11-320.jpg)



















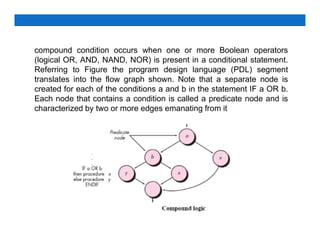












![Loop Testing
Loop testing is a white-box testing technique that focuses
exclusively on the validity of loop constructs. Four different
classes of loops [Bei90] can be defined: simple loops,
concatenated loops, nested loops, and unstructured
loops as shown in Figure.](https://image.slidesharecdn.com/unit-4-240520104741-b0d72a4c/85/Software-Engineering-TESTING-AND-MAINTENANCE-44-320.jpg)






















































































































The document outlines software testing principles, techniques, and the importance of testing in software development. It distinguishes between debugging and testing, emphasizes the need for test planning, and describes various testing strategies such as black-box and white-box testing. Testing ensures software meets specifications, identifies defects, and maintains product quality, ultimately enhancing customer satisfaction.










































































