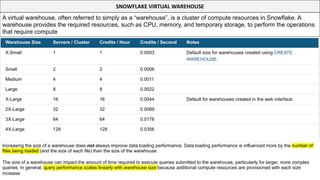
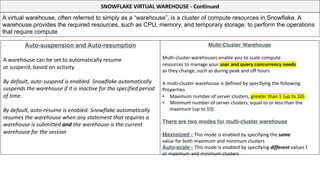
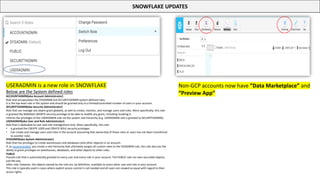
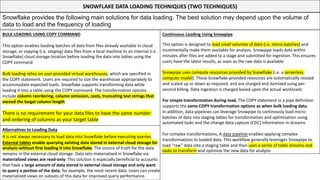
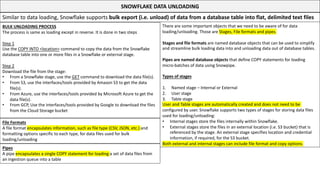
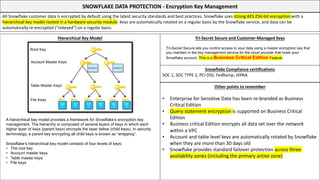
This document serves as a comprehensive cheatsheet for Snowflake certification, covering the architecture, key components, roles, data loading techniques, and features like zero-copy cloning. It emphasizes best practices for data management, performance optimization, and system administration within the Snowflake platform. It also warns against using Snowflake for transactional workloads due to its micro-partitioning method.