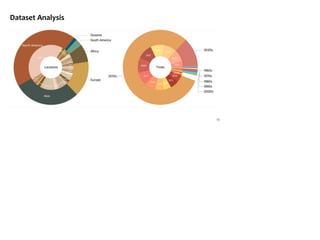
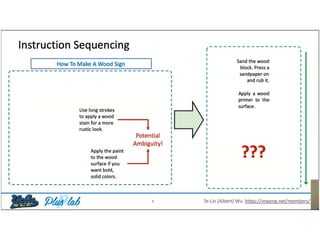
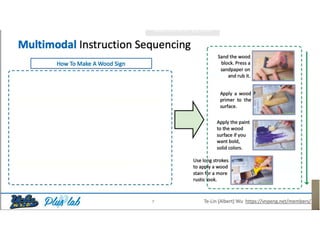
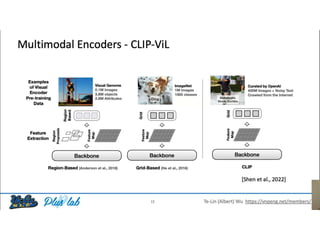
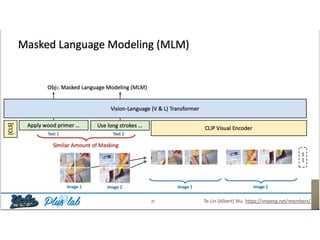
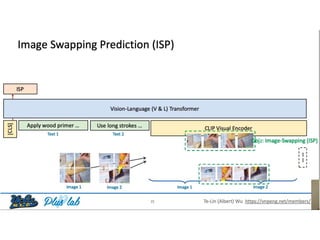
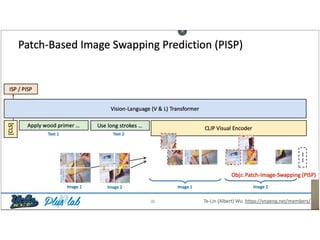
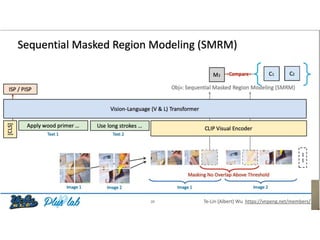
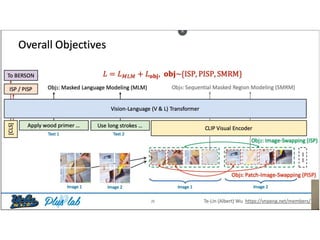
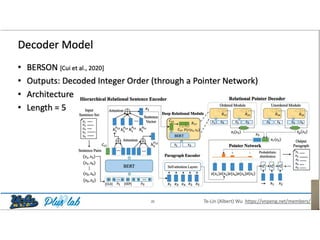
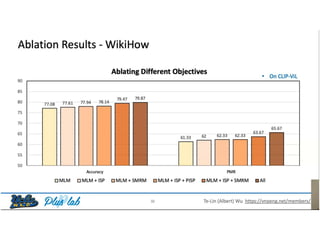
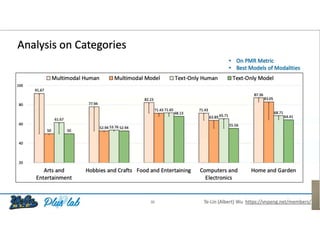
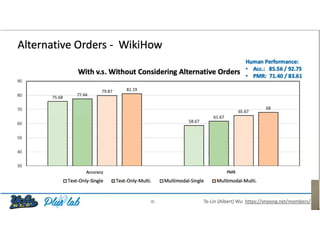
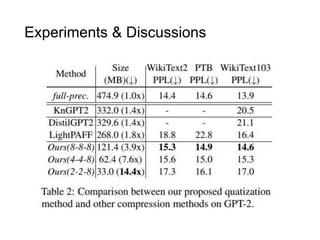
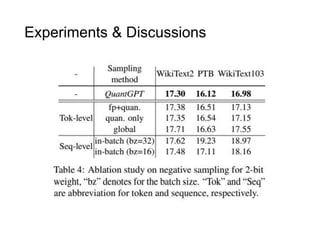
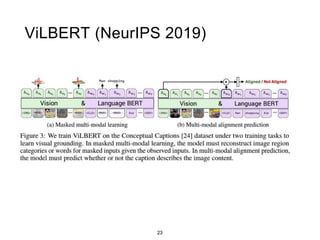
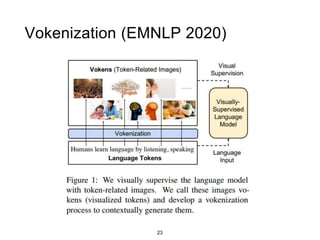
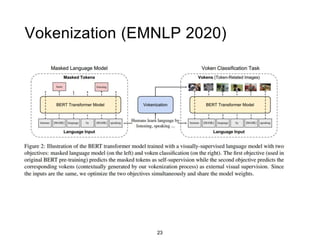
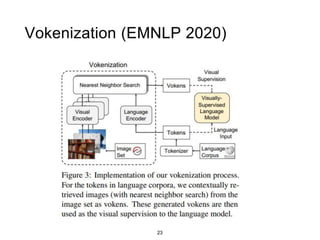
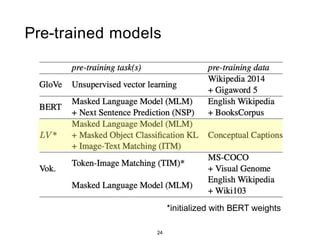
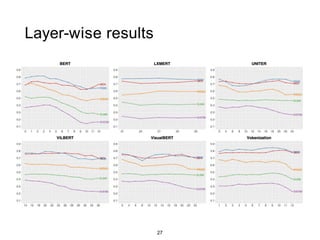
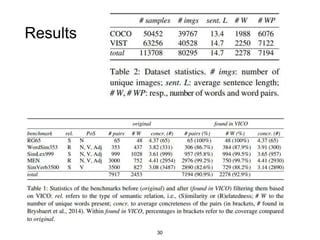
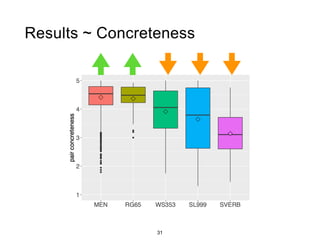
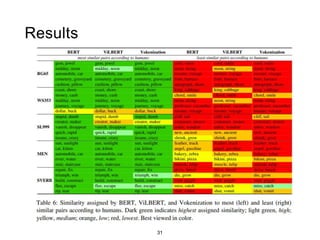
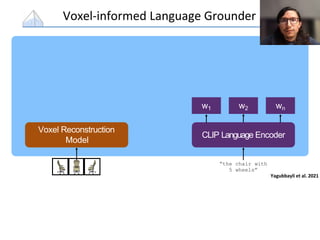
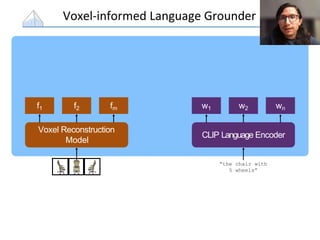
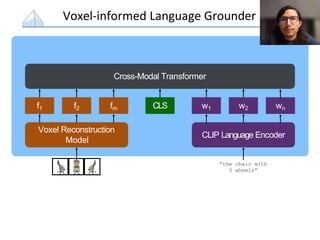
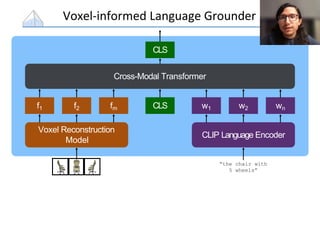
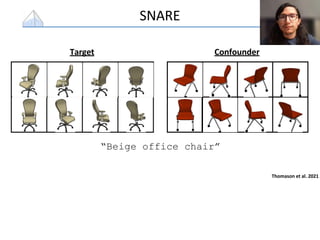
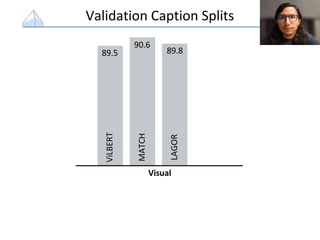
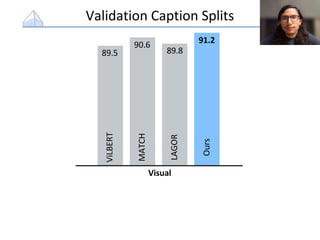
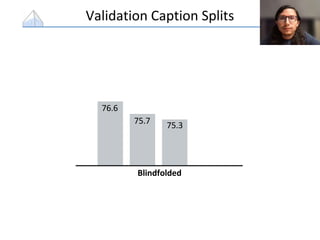
The document presents a study that evaluates the quality of word representations learned by multimodal pre-trained transformers. It discusses prior work showing that human concepts are grounded in sensory experiences and the advantage of multimodal representations over text-only ones, particularly for concrete words. The study aims to intrinsically evaluate how well semantic representations from models like LXMERT and ViLBERT align with human intuitions by comparing word similarity to human judgments. It obtains static embeddings from contextualized representations to measure semantic similarity independent of context.





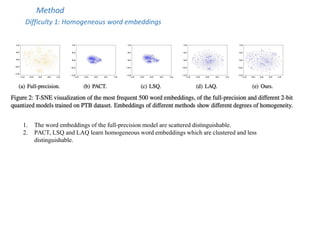



![Method
Difficulty 2: Varied Distribution of Weights.
Previous method
1. Hard to find a good initial value for the learnable clipping factor 𝛼.
2. Does not consider the effect of weight within [−𝛼, 𝛼].
Could we solve these two problems with a new quantizer?](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-16-320.jpg)

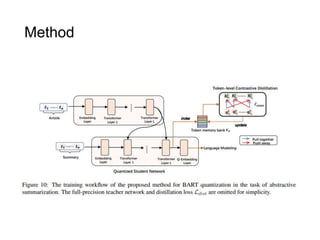

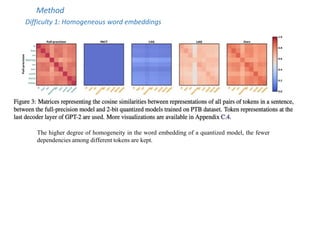
![Method
Proposal 2: Module-dependent Dynamic Scaling
Instead of directly learning the clipping factor α as PACT, we turn to learn a new scaling factor γ
The gradient of γ :
2. Consider the effect of
weight within [- α, α]
1. Be proportional to the averaged
weight magnitude](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-22-320.jpg)




![8
Theoretical background
Evidence that meaning of words is multimodal:
• Human concepts are grounded in our senses [Barsalou,
2008; De Vega et al., 2012]
• Sensory-motor experiences play an important role in
determining word meaning [Meteyard et al., 2012]](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-32-320.jpg)

![Previous work
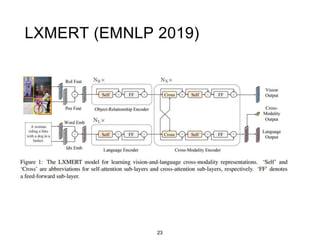
Classic (pre-Transformers) approaches combining
representations from language and vision:
• Advantage of multimodal over text-only representations
[Bruni et al. 2014; Lazaridou et al. 2015; Kiela et al. 2016]
• Advantage typically for concrete — but not abstract —
words [Hill and Korhonen, 2014]
image: Beinborn et al. 2018
13](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-34-320.jpg)
![16
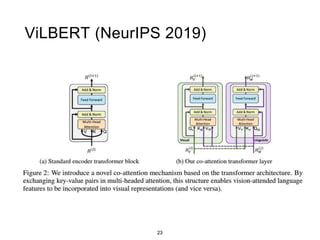
Multimodal Transformers
• Current state-of-the-art in most language and vision
tasks, e.g., VQA, Visual reasoning, Visual Dialogue, etc.
• Claimed to encode “task agnostic” representations
thanks to their (massive) pre-training
• ‘Extrinsic’ evaluation and probing [Cao et al. 2020;
Parcalabescu et al. 2021; Bugliarello et al. 2021; Thrush et al. 2022]](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-35-320.jpg)

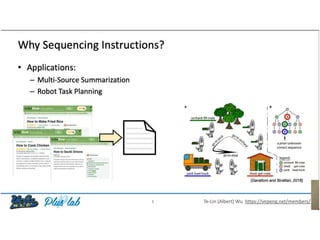
![Method
• Obtain static embeddings from contextualized ones that
are dependent on the actual linguistic context
• Approach used with text-only BERT [Bommassani et al. 2020]
features
features
features
features
features
features
features
features
features
features
features
features
features
features
features
features
M different contexts for 'donut' Language Layer 1 h Layer L h
s1
mean
wC
s1
mean
wC
>&L6@a man buys a SinN don ut at ... s2 ... s2
embeds
tO tl t2 t3 t4 t5 t6 t7 t8 ...
mean mean
s1 s2 Vision
M wC1 M wC1
... ...
features w w
vl v2 v3 v4 ... v36
donut ⃗ = mean(wdonut , wdonut , …, wdonut)
1 2 N
19](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-37-320.jpg)
![Method
• Obtain static embeddings from contextualized ones that
are dependent on the actual linguistic context
• Approach used with text-only BERT [Bommassani et al. 2020]
donut ⃗ = mean(wdonut , wdonut , …, wdonut)
1 2 N
mean
mean
Layer 1
features
features
features
features
features
...
don ut at ...
features
features
features
features
embeds
s1
s2 ...
v36
vl v2 v3 v4 ...
Layer L
Language
Vision
s1 s2
M different contexts for 'donut'
features
features
features
features
wC1
M
mean
w
...
wC
>&L6@a man buys a SinN
t tl t2 t3 t4 t
s1
s2
features
features
features
features
wC1
mean
w
wC
M
20
t6 t t ...
h h](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-38-320.jpg)


![Representations
• Pre-trained models used in inference mode (no fine-tuning)
• Sentences (BERT, Vokenization) or <sentence,image> pairs
(MM models) from COCO [Lin et al. 2014] + VIST [Huang et al. 2016]
25](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-48-320.jpg)

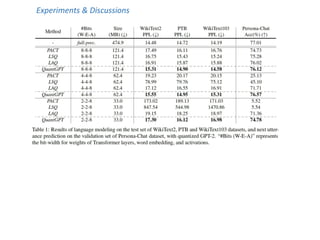
![Best results: MEN
MEN [Bruni et al. 2014]
Spearman’s
correlation
28
0,82
0,81
0,80
0,79
0,78
0,77
0,76
0,75
0,74
0,73
0,72](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-51-320.jpg)
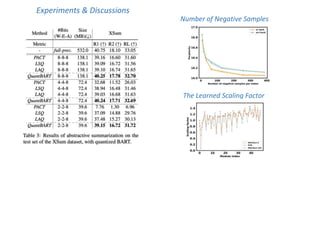
![Best results: SimLex999
SimLex999 [Hill et al. 2015]
Spearman’s
correlation
29
0,53
0,52
0,51
0,50
0,49
0,48
0,47
0,46
0,45
0,44
0,43](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-52-320.jpg)























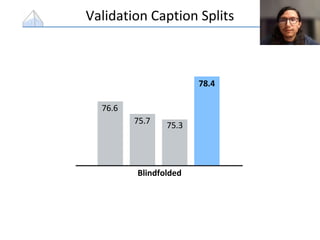






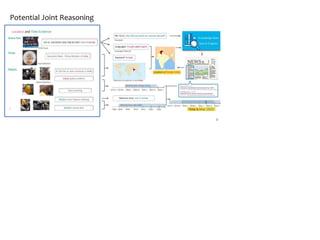
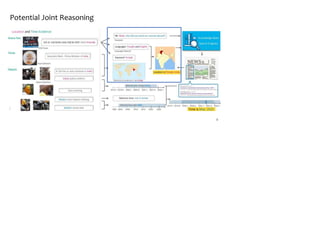




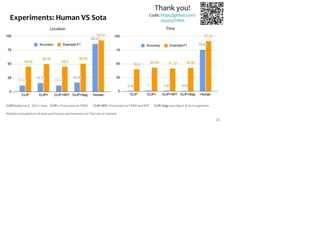
![Evaluation Metrics
● Hierarchical Labels
○ “Philadelphia, Pennsylvania, United States, North America” ⇒
[“Philadelphia, Pennsylvania, United States, North America”, “United States, North America”,
“North America”]
○ “1967-7-14” ⇒
[“1967-7-14”, “1967-7”, “1967”, “1960s”, “20th century”].
● Evaluation Metrics
○ Accuracy
○ Example-F1
14](https://image.slidesharecdn.com/slide-acl2022-combinedsan-230704104407-0ed175f9/85/slide-acl2022-combined_san-pptx-110-320.jpg)