Download to read offline












![Australia
We will [establish] policies to:
•accelerate Government 2.0 efforts to engage online,
make agencies transparent and provide expanded
access to useful public sector data;
…The next wave of opportunities to improve the quality
and effectiveness of government services are likely to be
driven by access to (appropriately anonymized) public
sector data sets and ‘big data’.
The Hon Andrew Robb AO MP, The Hon Malcolm Turnbull MP
Liberal Party of Australia, 2 Sep 2013](https://image.slidesharecdn.com/iswc-2013-woolf-131023195351-phpapp02/75/SemWeb-4-Gov-opportunities-and-challenges-15-2048.jpg)












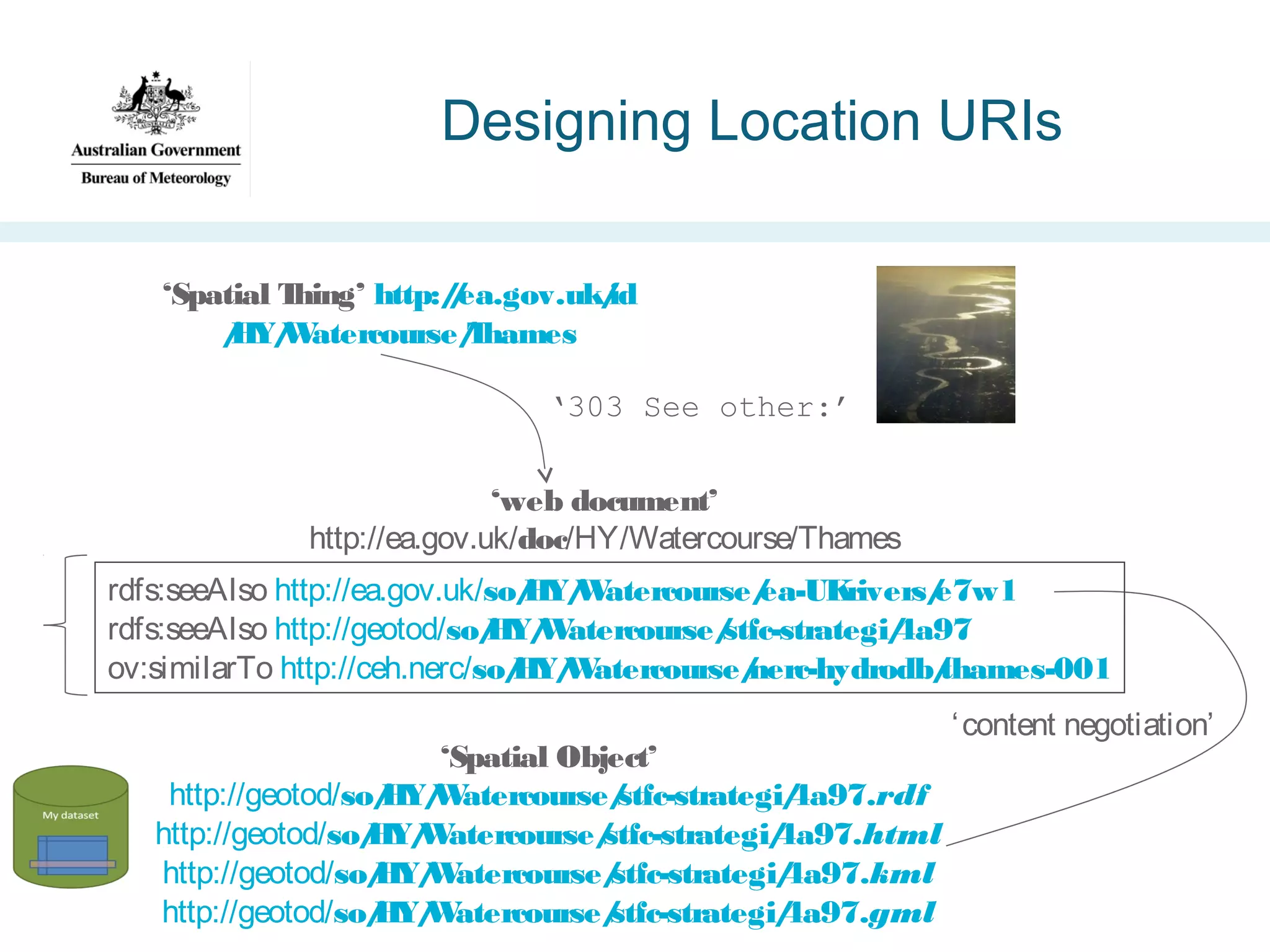
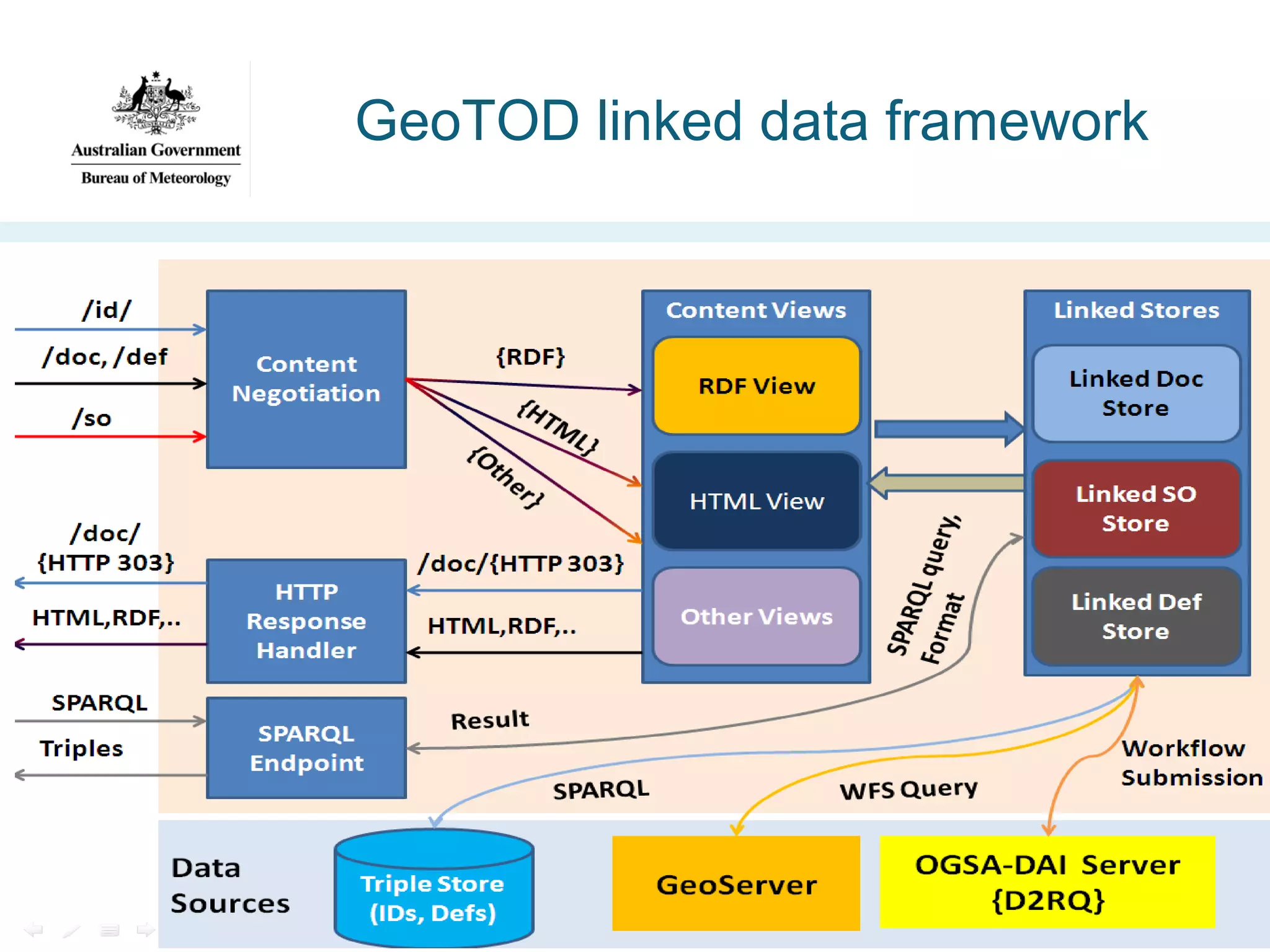
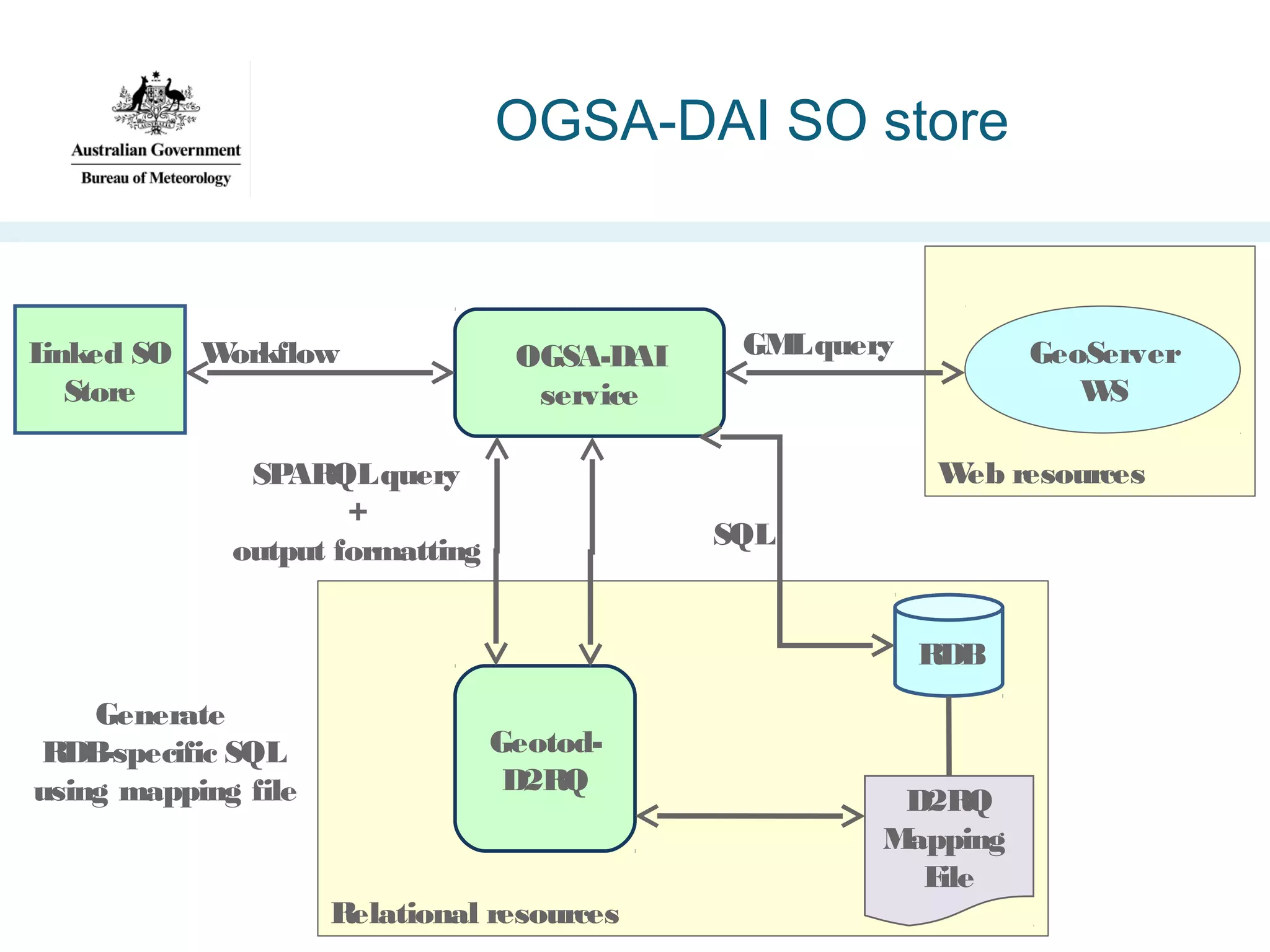
![Geospatial Transformation with
OGSA-DAI (GeoTOD) [2010]
•Project aims:
– Exploit a high-profile
outcome from the >£200M
UK government-funded eScience program
– Implement the UK Cabinet
Office guidelines on ‘URI
Sets for Location’
– Enable dynamic
transformation of existing
large spatial datasets
http://data.gov.uk/sites/default/files/
Designing_URI_Sets_for_Location-V1.0_10.pdf](https://image.slidesharecdn.com/iswc-2013-woolf-131023195351-phpapp02/75/SemWeb-4-Gov-opportunities-and-challenges-33-2048.jpg)

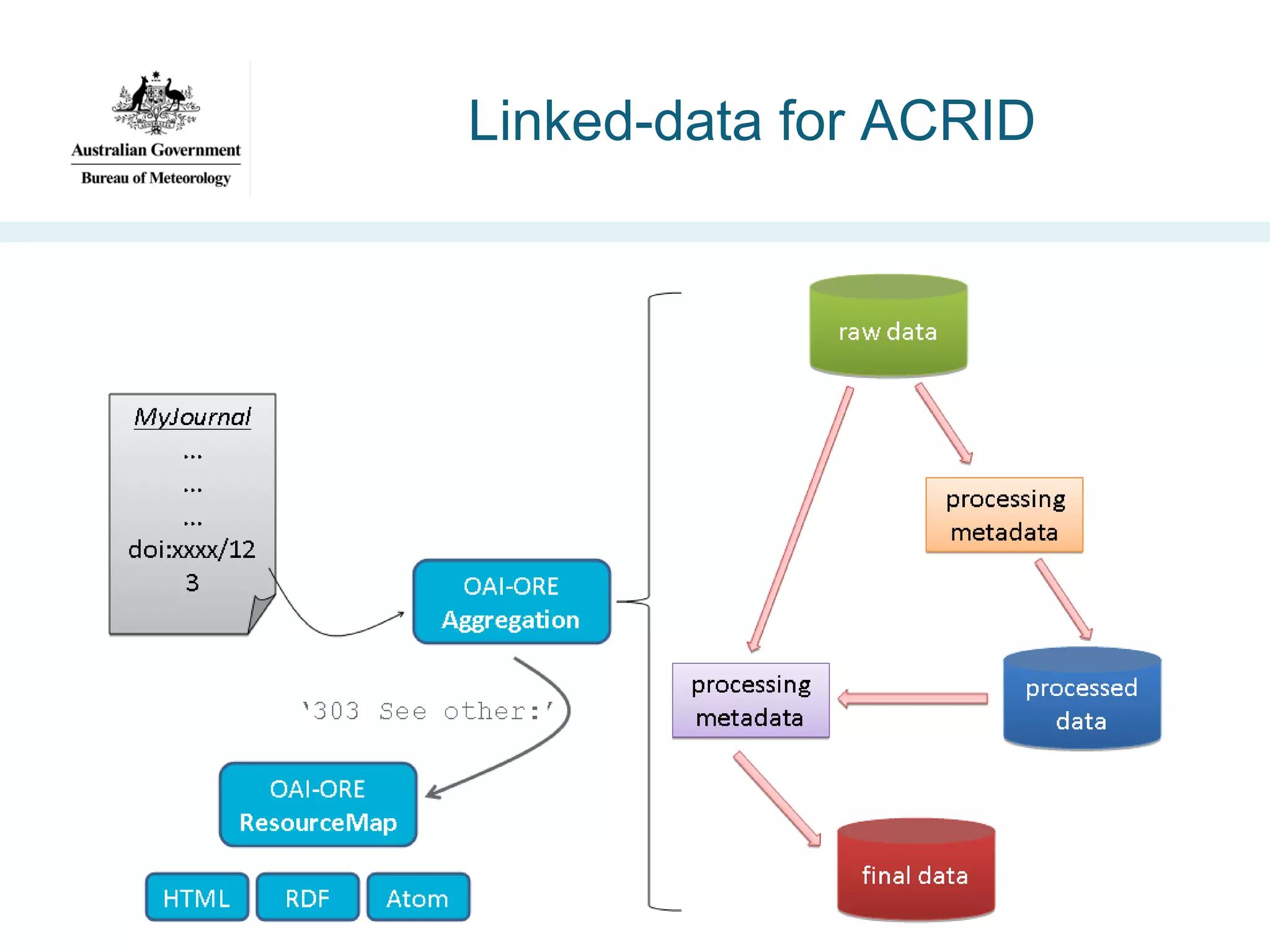
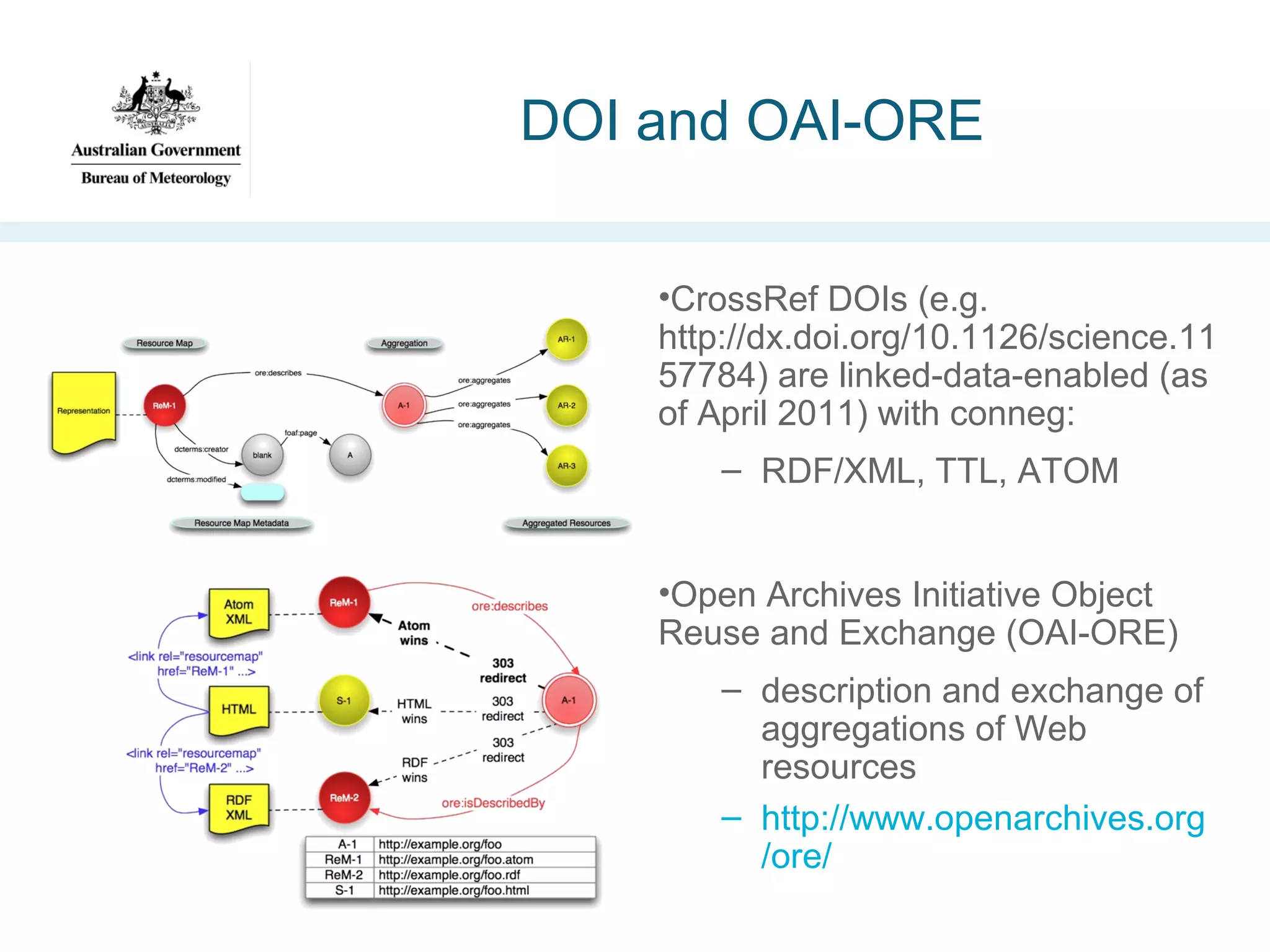
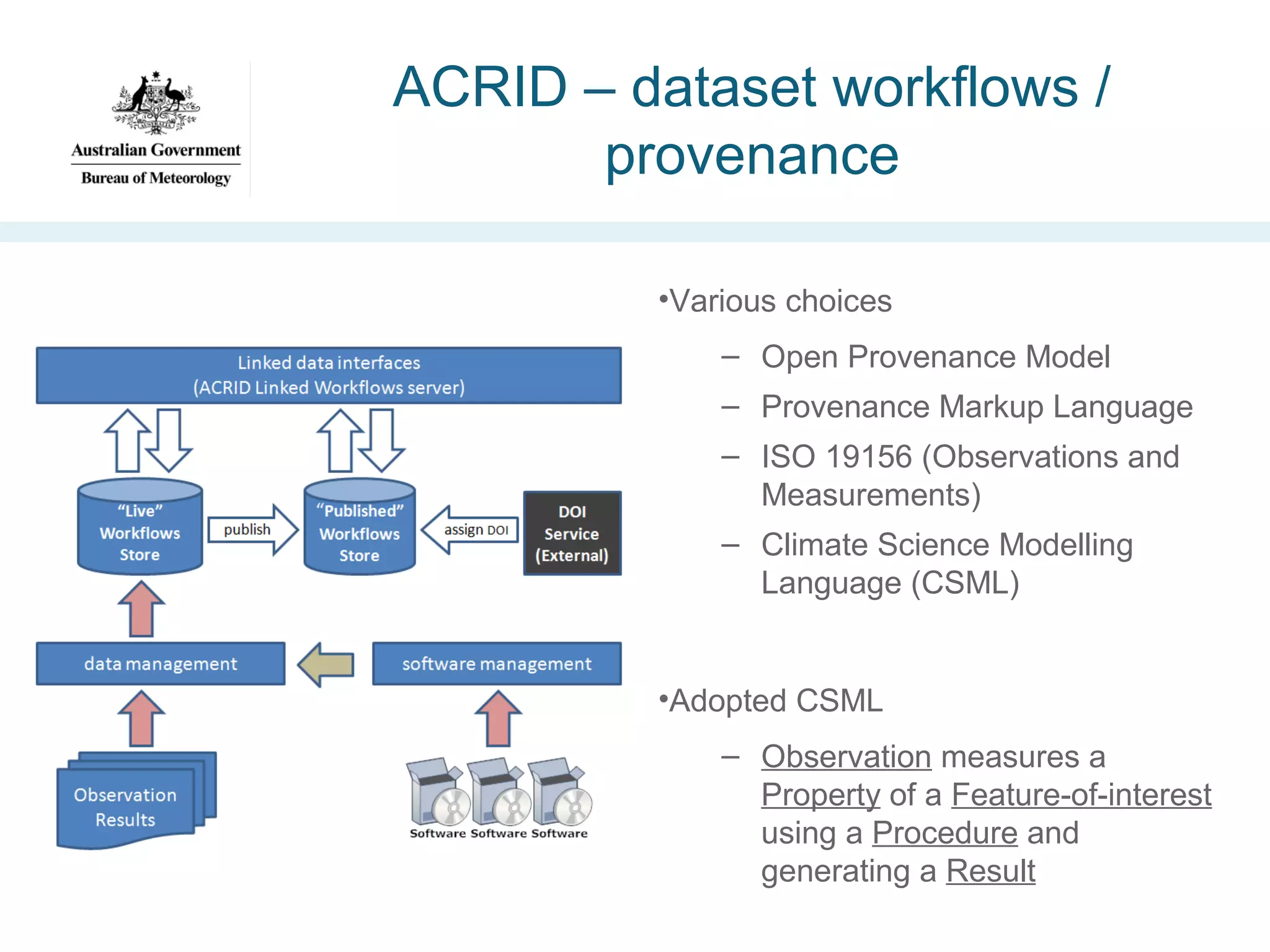
![Advanced Climate Research Infrastructure
for Data (ACRID) [2010]
https://www.uea.ac.uk/mac/
comm/media/press/2010/july/
climatedataproject
•Project aims:
–
–
–
–
Address Climategate concerns re publishing climate data
Enable seamless link from research publication to data
Include dataset provenance information
Verify linked-data principles for this problem](https://image.slidesharecdn.com/iswc-2013-woolf-131023195351-phpapp02/75/SemWeb-4-Gov-opportunities-and-challenges-38-2048.jpg)
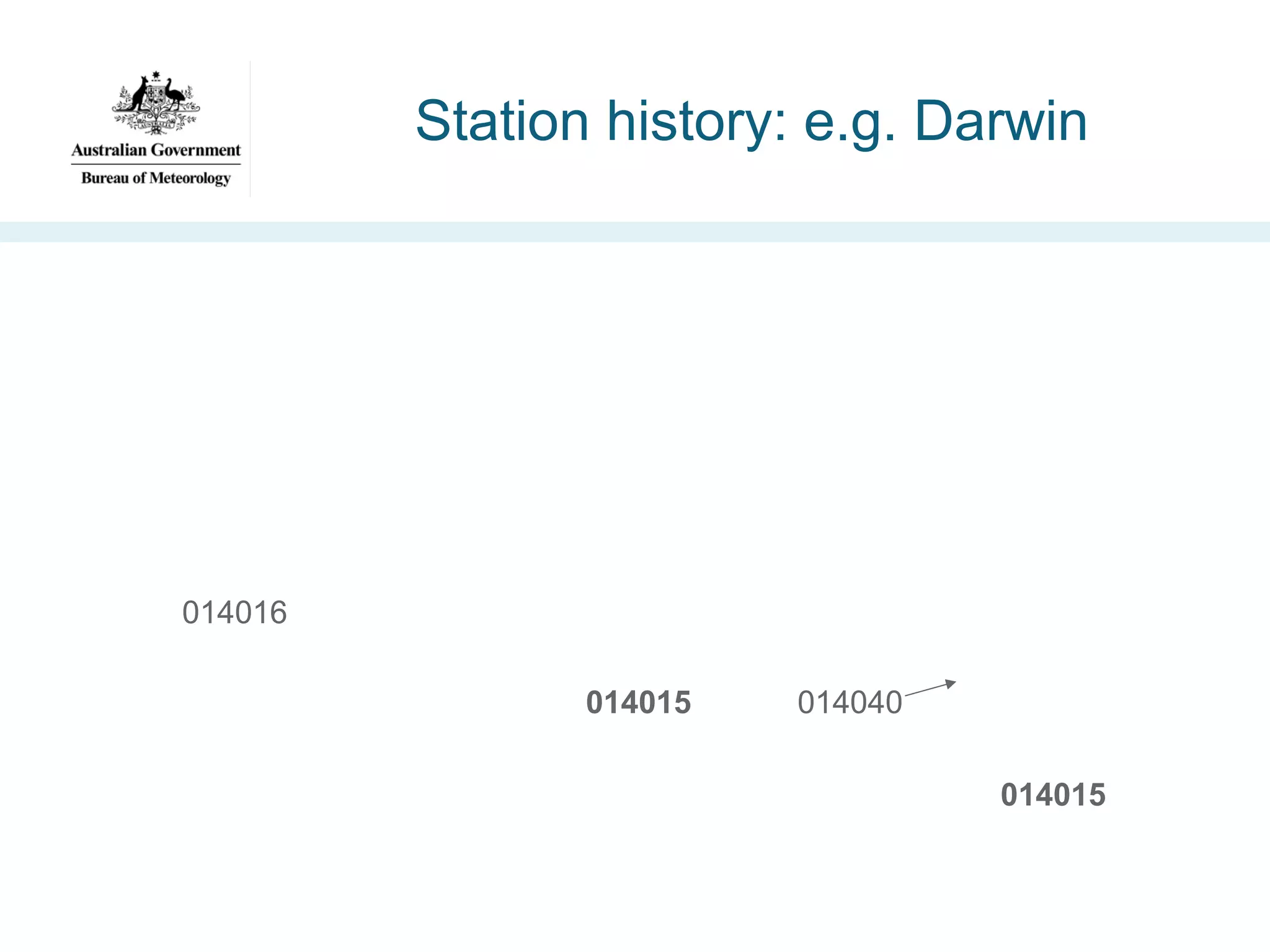
![Australian Climate Observations
Reference Network – Surface Air
Temperature (ACORN-SAT) [2012]
•High-quality daily surface temperature
(min/max) timeseries’
•112 stations
•Over 100 years of records
•Homogenised for
– Site relocations
– Instrument replacement
– Local changes](https://image.slidesharecdn.com/iswc-2013-woolf-131023195351-phpapp02/75/SemWeb-4-Gov-opportunities-and-challenges-42-2048.jpg)















The document outlines opportunities and challenges regarding the integration of the semantic web in government operations, emphasizing the importance of open access to data, collaboration among agencies, and the adoption of semantic web standards. It highlights various international efforts, national plans, and projects aimed at improving data accessibility and utilization for enhancing government services. Key lessons include the need for pragmatic implementation, infrastructure establishment, and skill development among ICT contractors to support this initiative.









































































