Download to read offline



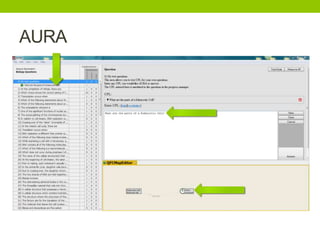
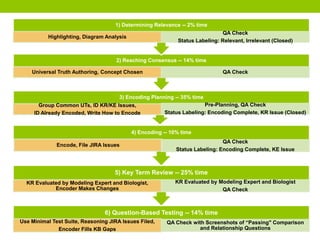
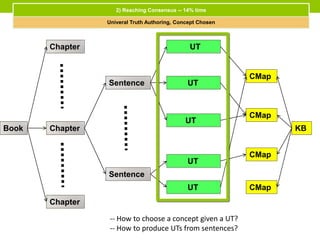



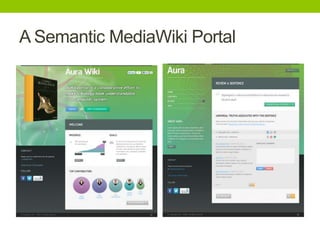


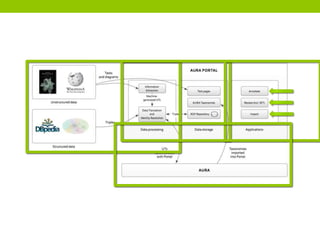

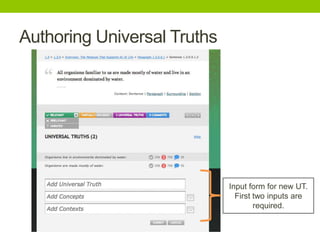















The document outlines a project focused on crowd-sourcing the authoring of universal truths for textbooks using a semantic mediawiki called Aura. It details processes such as encoding, consensus reaching, and the roles of domain experts, specifically students from the University of Washington, in generating over 100 universal truths per session. The project aims to enhance textbook encoding efficiency by involving domain experts and exploring gamification and social networks for authoring support.














































