><
•DB에서 중요시 되는것의 일부
•실시간 접근성
•항시 변화함
•동시 공유
…
•은행, 결제, 게임, 계정정보 등에
사용
주요한 것들 중 하나: 탄생배경
SEARCH ENGINE WORKFLOW
무엇이 다를까?
7
•검색엔진이 중요시 하는 것들
•정확도 (precision)
•재현율 (recall)*
…
•원하는 문헌을 찾기 쉽게 하기 위해
•webpage검색, 서적, 국가기록 등에
사용
8.
><
•DB는 사용하는 데이터를직접 관
리할 수 있다.
주요한 것들 중 하나: 데이터
SEARCH ENGINE WORKFLOW
무엇이 다를까?
8
•검색엔진은 웹을 여행하면서 문헌을
찾고, 핵심단어(term)를 색인 하여 미
리 보여주는 역할
•블로그에 글을 올렸지만 검색에 한참
뒤에 반영 되지 않는 이유
><SEARCH ENGINE WORKFLOW
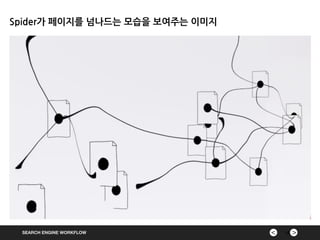
Spider에대하여
14
•문서 수집을 위한 검색엔진의 수집장치( Spider, Crawler 등으로 불림)
•사용자가 검색과는 관계없이 별도로 움직이는 수집만을 위한 장치
•시작점에서 URL을 타고 들어가고, 그곳에서 다른 URL을 만나면 다시 타고
들어간다
><SEARCH ENGINE WORKFLOW16
Q: White.Cotton에 Spider가 방문하면?
A: Home, Best, New, Sale,상품 페이지의
Link를 Spider가 기억 후 방문
Spider에 대하여
17.
><SEARCH ENGINE WORKFLOW
Spider특징들
17
•공손함 : Spider는 수집 금지 설정이 되어있는 페이지는 수집하지 않는다.
•분산성 : Spider는 여러개의 분산처리 가능한 환경이 요구된다.
•우수성 : 유용한 것을 먼저 가져올 수 있어야 한다.
><SEARCH ENGINE WORKFLOW
색인의필요성
21
•수많은 데이터 중에 사용자에가 원하는 적합한 정보를 단시간에 찾기란 불가능
•사용자의 검색어에 걸맞는 추천을 위해, 사전 연산작업이 필요
22.
><SEARCH ENGINE WORKFLOW
용어어휘 정리
22
•불용어를 전처리 (ex. of, as, in, is)
•영어기준으로 복수형, 동사 과거/미래형, 대소문자 등 -> 원형으로 변형
•용어를 통일하고, 해당 문헌에 어떤 단어가 어느 위치에 존재하는지 색인
23.
><SEARCH ENGINE WORKFLOW
점수계산
23
•동일한 검색어를 가진 많은 문헌 중 양질의 문헌을 얻기 위해 각 문헌마다
점수를 부여한다.
•점수 계산법
•단어 가중치
•페이지 참조 수
•HTML Header Tag 설정 완성도
24.
><SEARCH ENGINE WORKFLOW
점수계산 - 단어 가중치
24
•Boolean 검색
•해당 키워드가 있으면 1 없으면 0이다. 1이 전부 나오는 항목들을 검색
결과에 보여주는 검색방법.
•우선순위가 없다.
•AND, OR, NOT 연산자로 다른 키워드를 결합할 수 있다.
25.
><SEARCH ENGINE WORKFLOW
점수계산 - 단어 가중치
25
•TF(Term Frequency)
•문헌 내 단어의 빈도 수를 의미 // {‘류준열’: {'count': 7}, '팬': {'count': 6}, '미팅': {'count': 5}}
•단어의 빈도 수가 증가되면 점수가 1차곡선 처럼 상승한다.
•이외에도 가중치의 영향력을 줄이기 위해 log Scale, 길이에 따라 빈도
를 완화시키는 증가 빈도 등이 있다.
26.
><SEARCH ENGINE WORKFLOW
점수계산 - 단어 가중치
26
•IDF(Inverse Document Frequency)
•단어가 얼마나 흔한지의 정도를 파악하는 수식
•흔할수록 점수가 낮게 되어 검색 결과가 정확할 수 없다.
•Unique 할수록 문헌에서 결정적인 역할을 하는 key로써 작용할 수 있
다.
27.
><SEARCH ENGINE WORKFLOW
점수계산 - 단어 가중치
27
•TF-IDF
•TF값과 IDF값을 곱한 수치
•상용에서 많이 사용된 점수계산방법
•TF만으로는 단순히 큰 의미 없지만 높게나올 수 있는 ‘공개’, ‘일’과 같은
단어의 점수로 인해 만족스럽지 못한 항목들이 있게된다.
•IDF는 TF의 이런 부작용을 바로잡아줄 수 있다.




































![[제12회 인터넷 리더십] 온라인 네트워크를 전략적 홍보_검색_전은서](https://cdn.slidesharecdn.com/ss_thumbnails/041821-140424032159-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[4차]구글 알고리즘 분석(151106)](https://cdn.slidesharecdn.com/ss_thumbnails/4-151106-160217170051-thumbnail.jpg?width=640&height=640&fit=bounds)

















