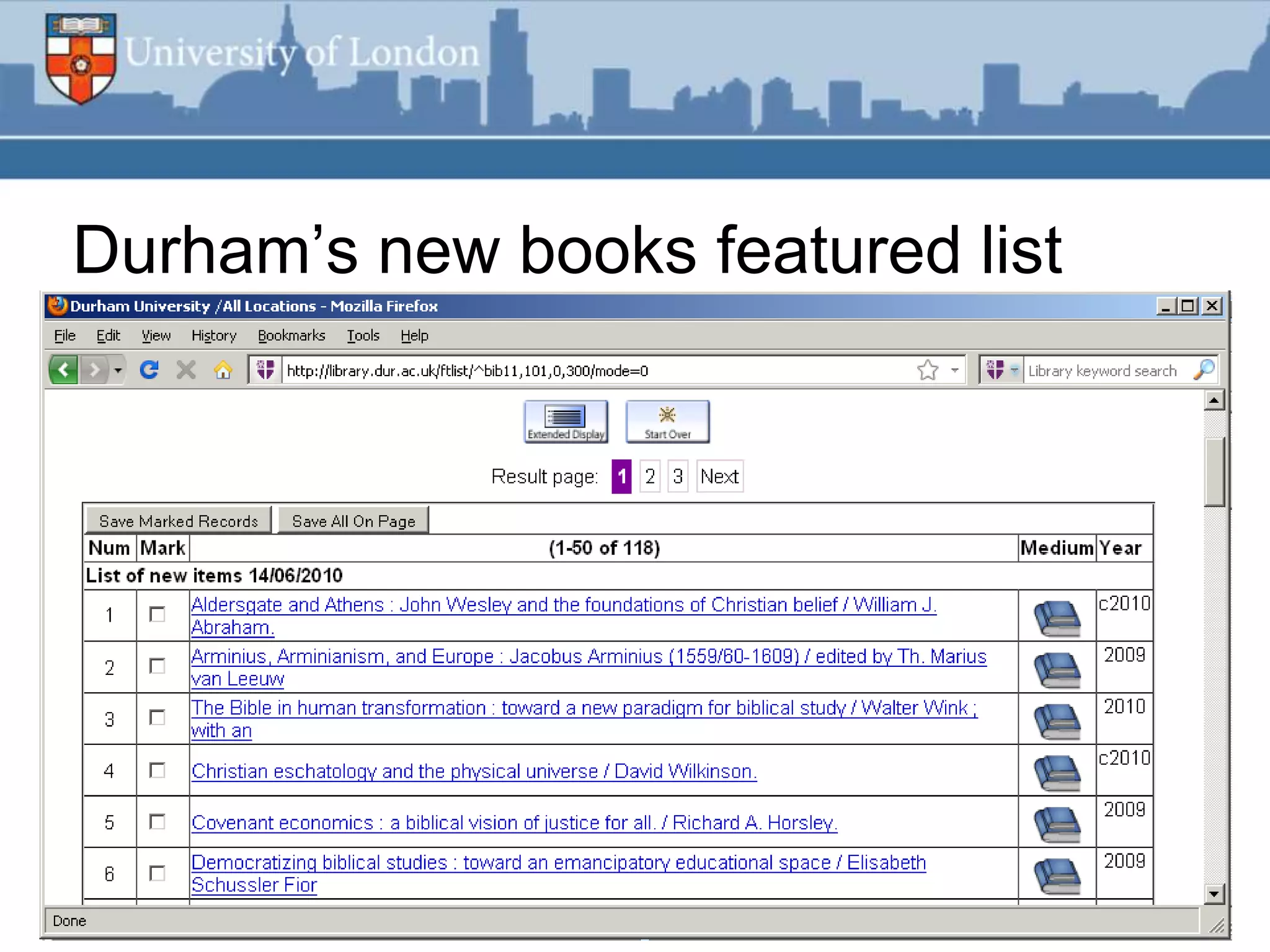
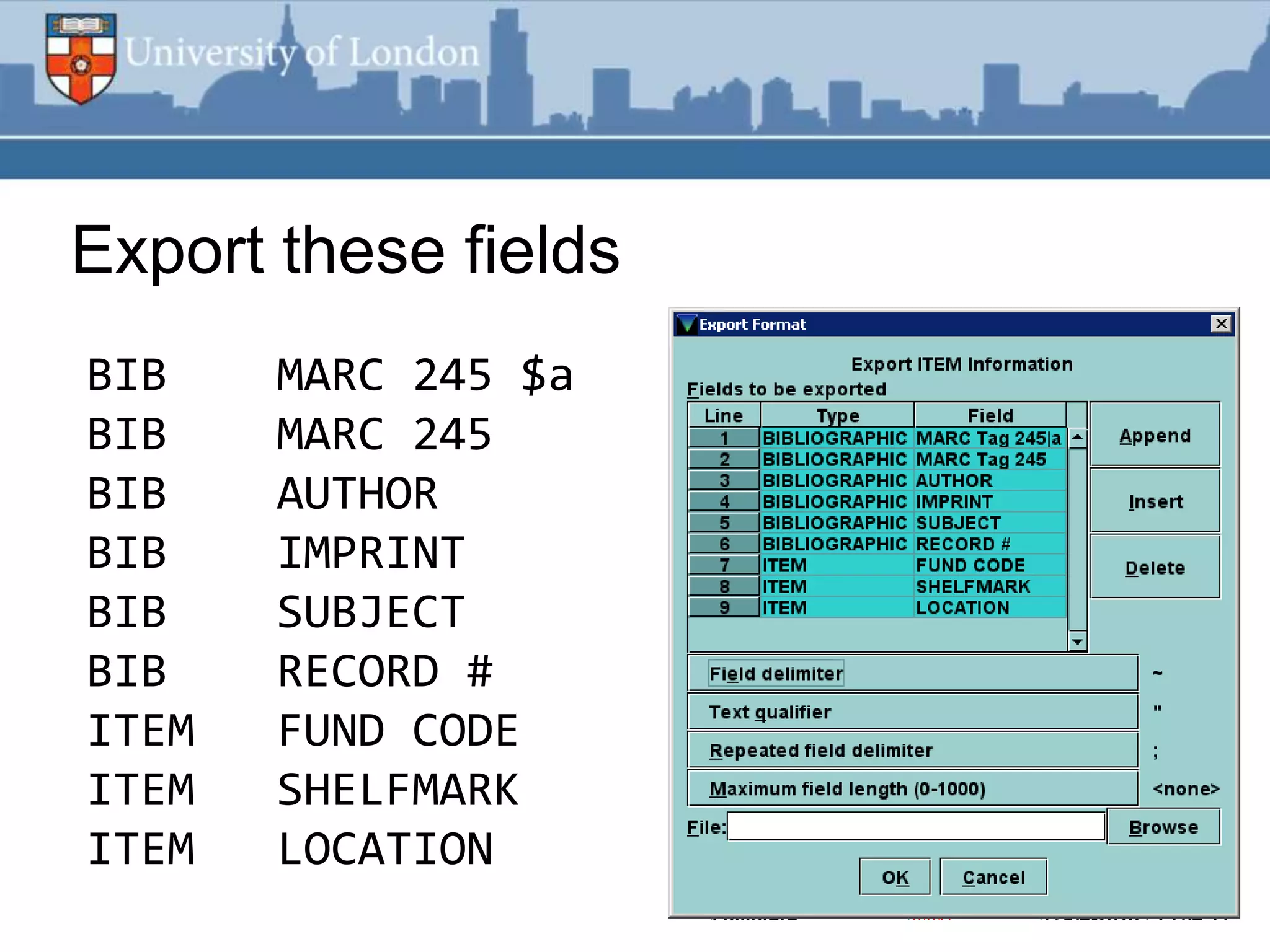
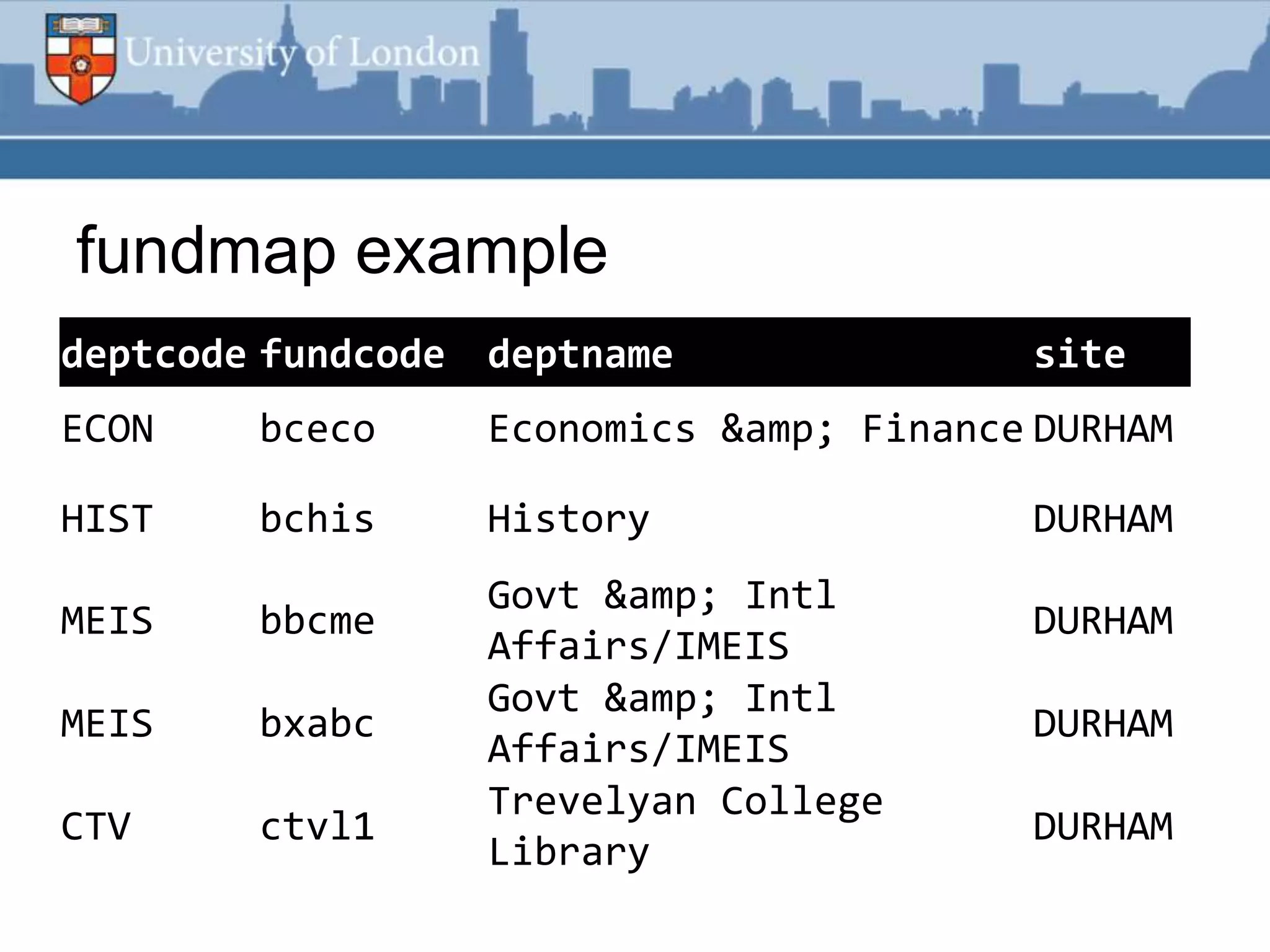
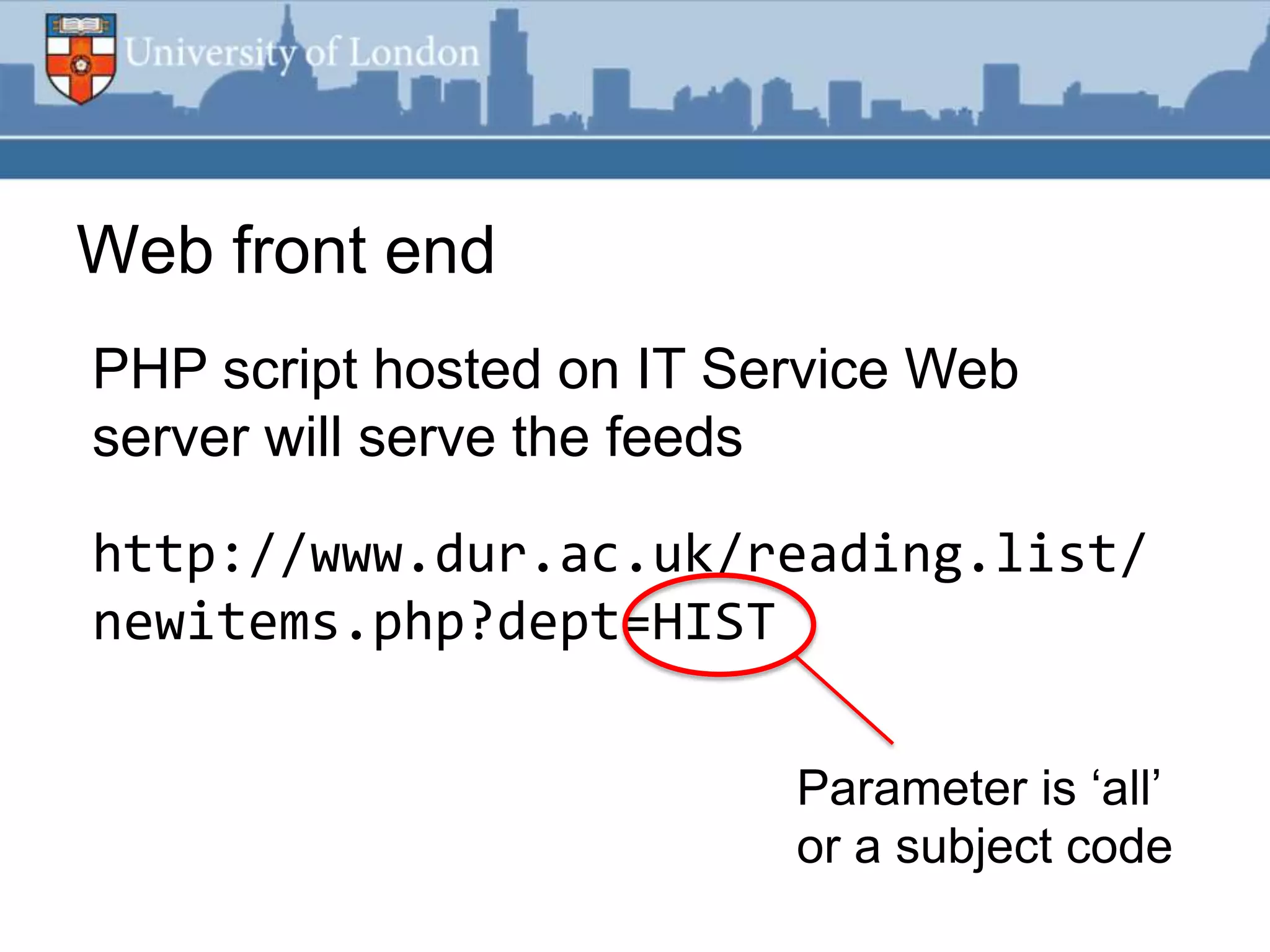
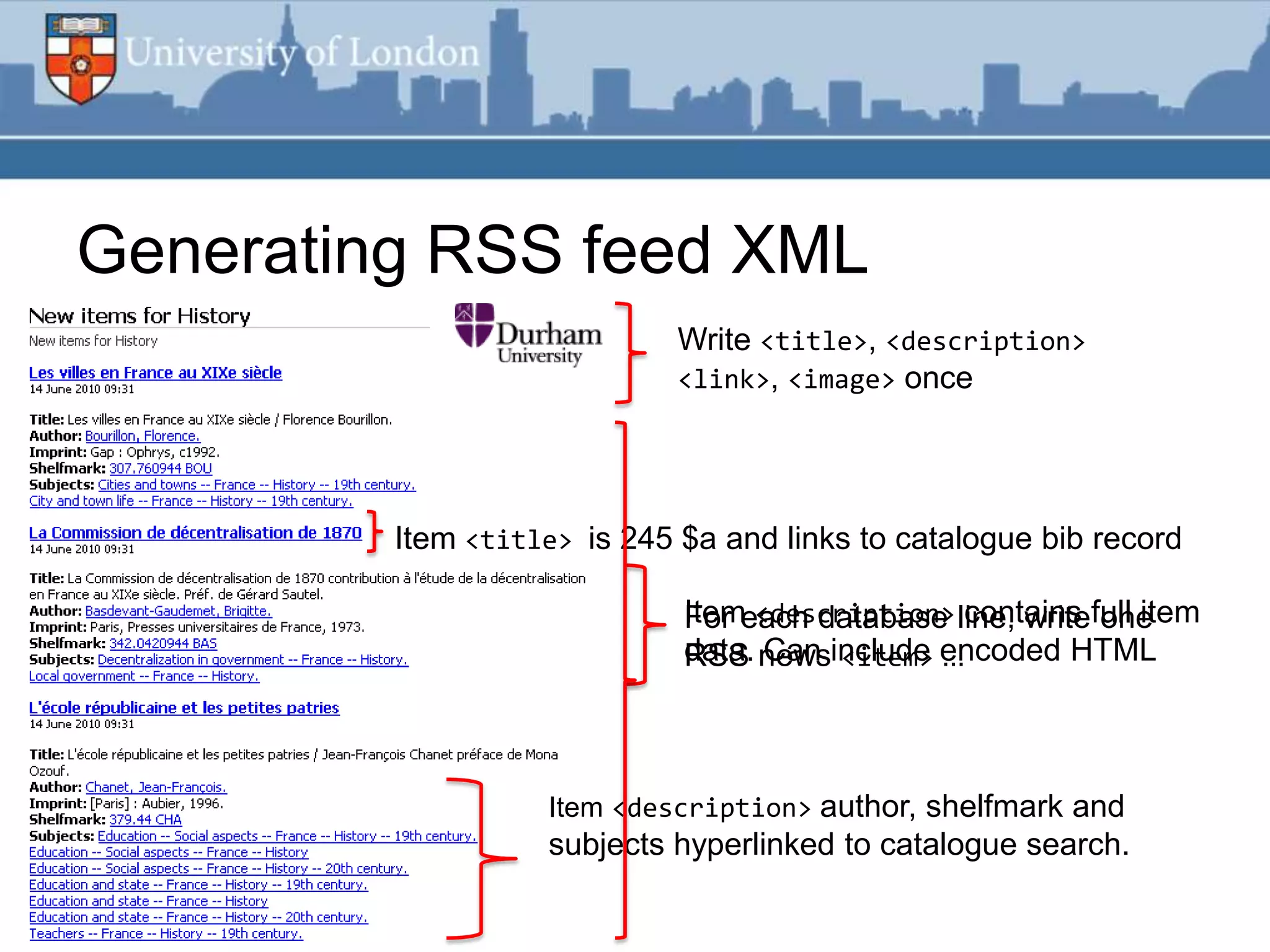
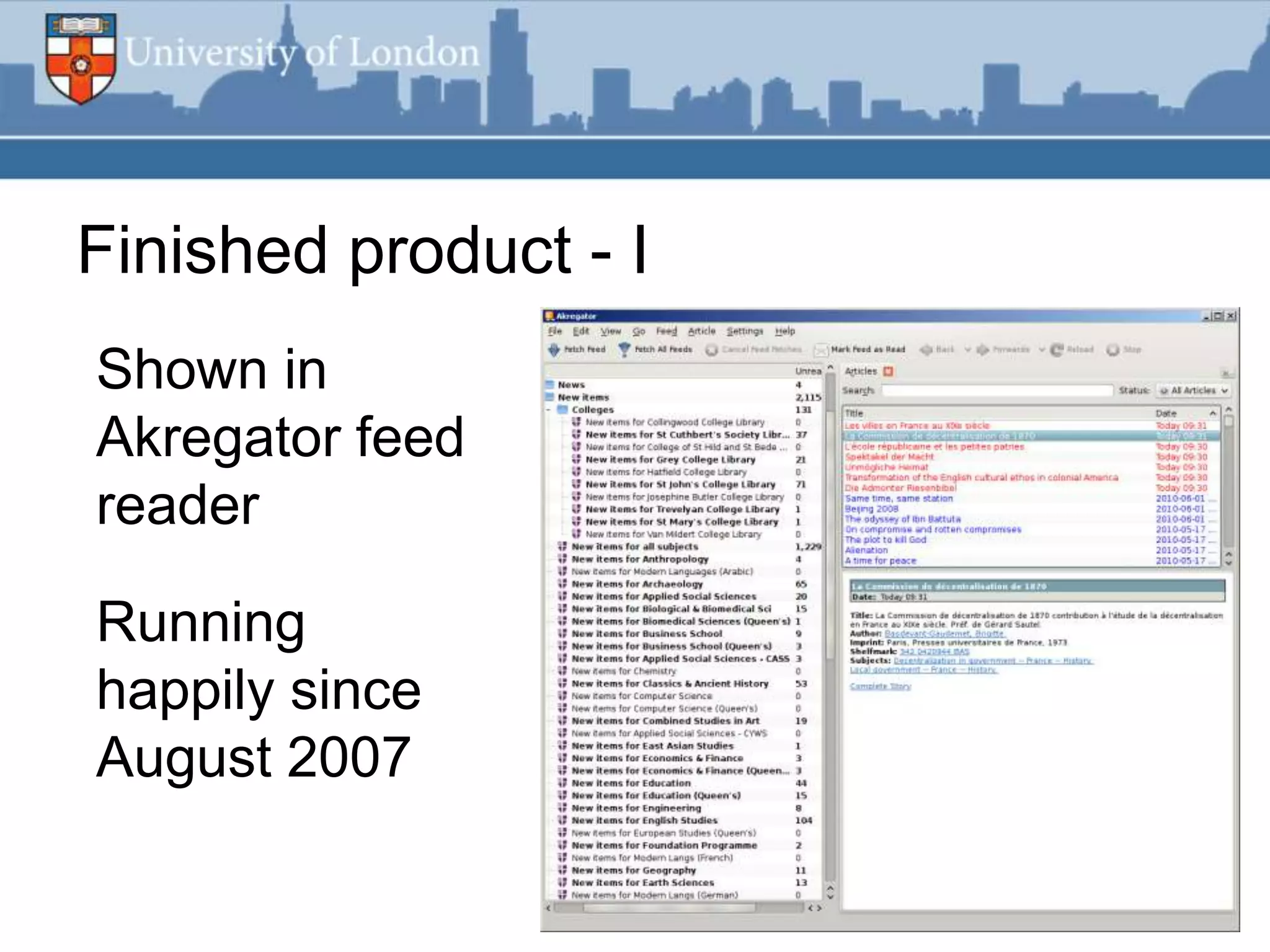
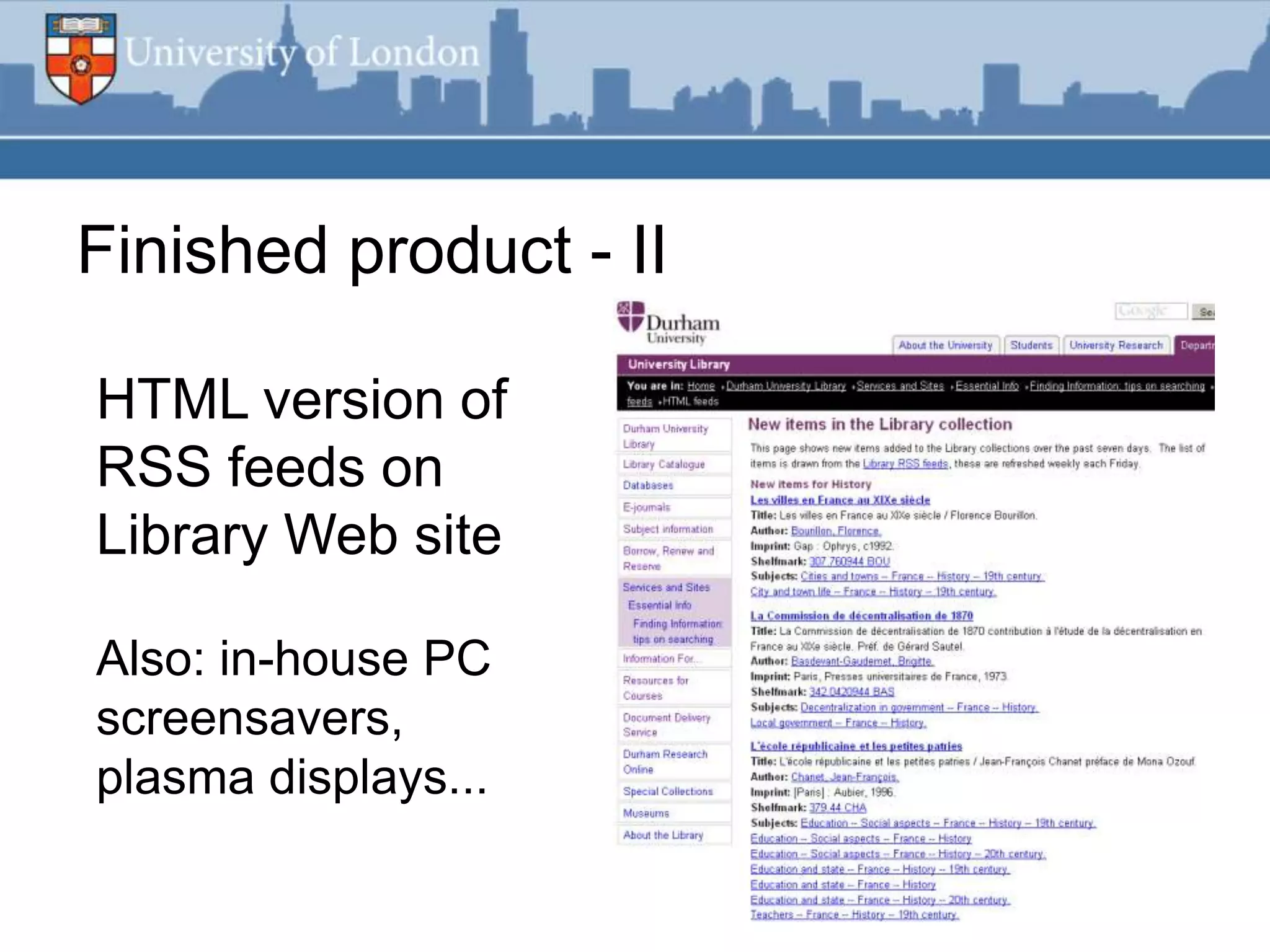
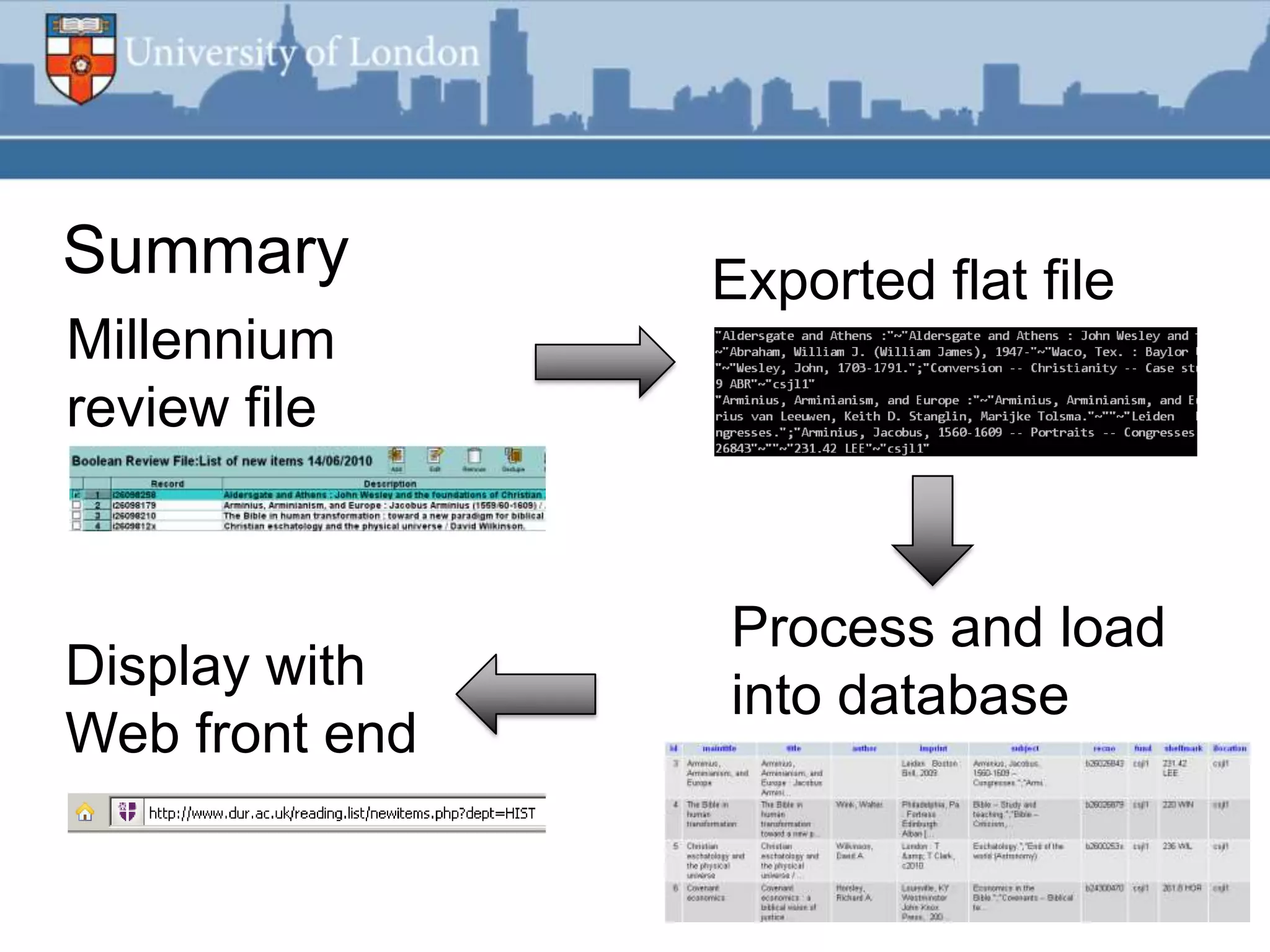
This document summarizes an RSS feed project at Durham University Library to automatically export new book metadata from their Millennium system into an RSS feed. The project aimed to minimize staff maintenance effort while providing a standards-compliant, automated way for readers to access new titles. Perl scripts processed the exported flat file data, loaded it into a MySQL database, and generated valid RSS XML. The finished product provided HTML and feed reader views of new titles that were refreshed weekly with minimal effort. Lessons learned included using Unicode, validating RSS, and the potential for more automation.