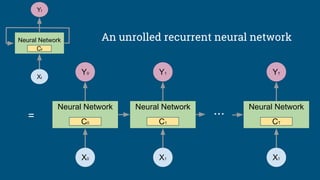
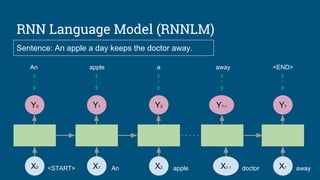
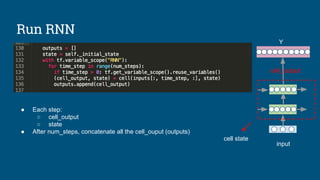
This document summarizes how to train a recurrent neural network (RNN) language model. It discusses preprocessing training data, defining the RNN model with parameters and cells, looking up word embeddings, running the RNN, calculating loss between outputs and targets, calculating gradients with backpropagation, and training the model by updating variables. Tips are provided on processing text, initializing states, clipping gradients to address vanishing/exploding gradients, and experimenting with hyperparameters like learning rate and model architecture. Official TensorFlow tutorials are referenced for implementing and running the code.








![Inputs look up word embedding
● embedding is a tensor of shape [vocabulary_size, embedding_size]
● tf.nn.embedding_lookup(...):
The word IDs are embedded into vector representations.
X = input
embedding_size =3
Y](https://image.slidesharecdn.com/rnnlmintensorflow-170825145210/85/RNNLM-in-TensorFlow-11-320.jpg)
![Calculate the loss between the output and the target
We are learning RNN language models.
input = language
Y = logits
Input_.target
P(language | input)
P(models | input)
[0 0 0 1 0 0 0 0 0 0]
We are learning RNN language models.
models](https://image.slidesharecdn.com/rnnlmintensorflow-170825145210/85/RNNLM-in-TensorFlow-13-320.jpg)























![_Deep learning in python Trustworthy [RNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythonrnn-251207084551-1fa069f9-thumbnail.jpg?width=640&height=640&fit=bounds)



















![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)








