Download to read offline


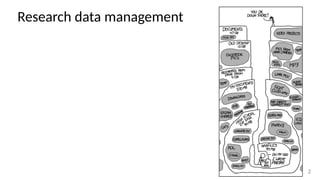
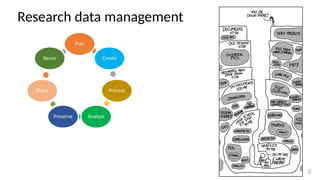
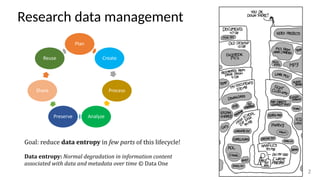
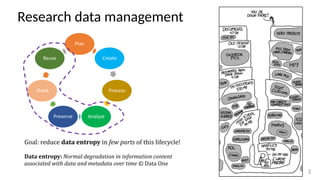
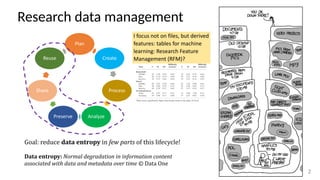
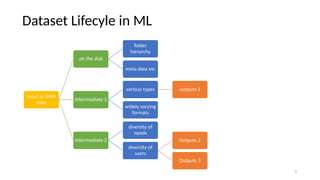
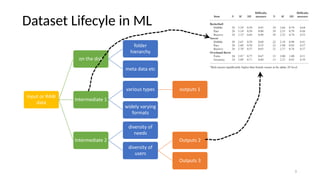













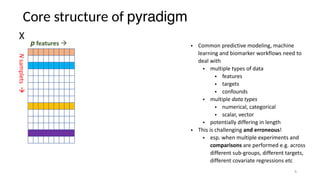
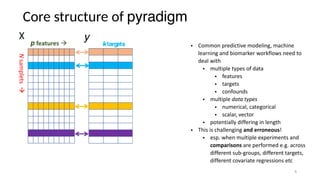
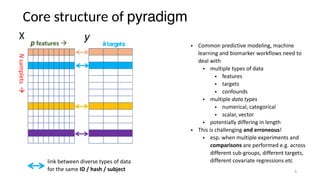
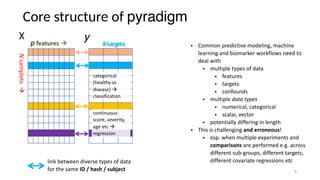
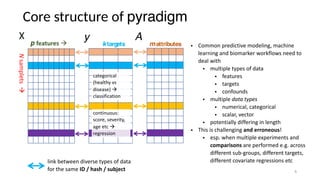
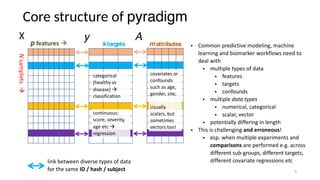


















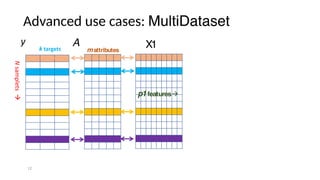
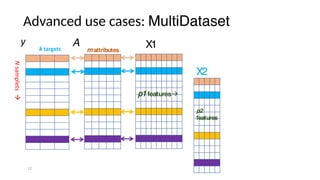
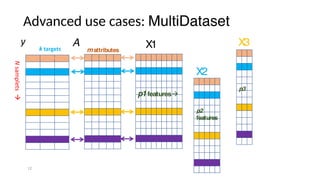
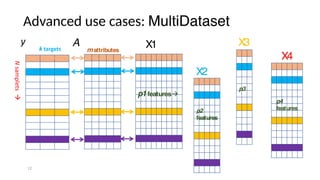
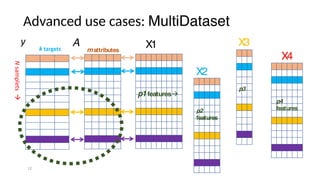


The document discusses research data management (RDM) for medical data, focusing on the need to reduce data entropy and manage diverse data types throughout the dataset lifecycle for machine learning and predictive modeling. It highlights the challenges faced, such as mixed data types, frequent changes of personnel, and the inadequacies of current libraries that add cognitive burdens. The author proposes a system called Pyradigm to streamline this process, aiming for improved accessibility, validation, and usability in handling complex datasets.



![Bio ontologies and semantic technologies[2]](https://cdn.slidesharecdn.com/ss_thumbnails/bioontologiesandsemantictechnologies2-180509123734-thumbnail.jpg?width=640&height=640&fit=bounds)

























































