Download to read offline





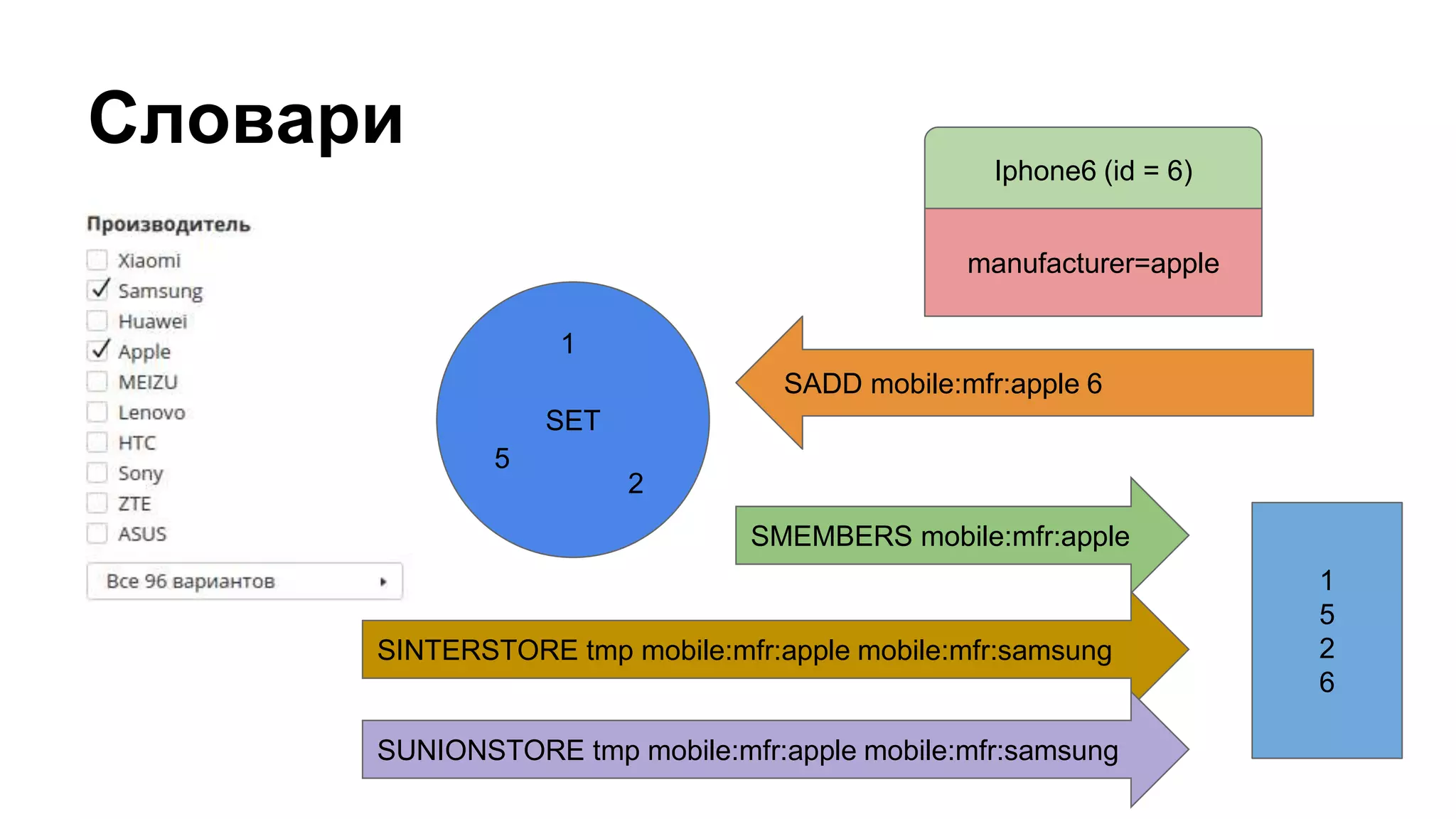
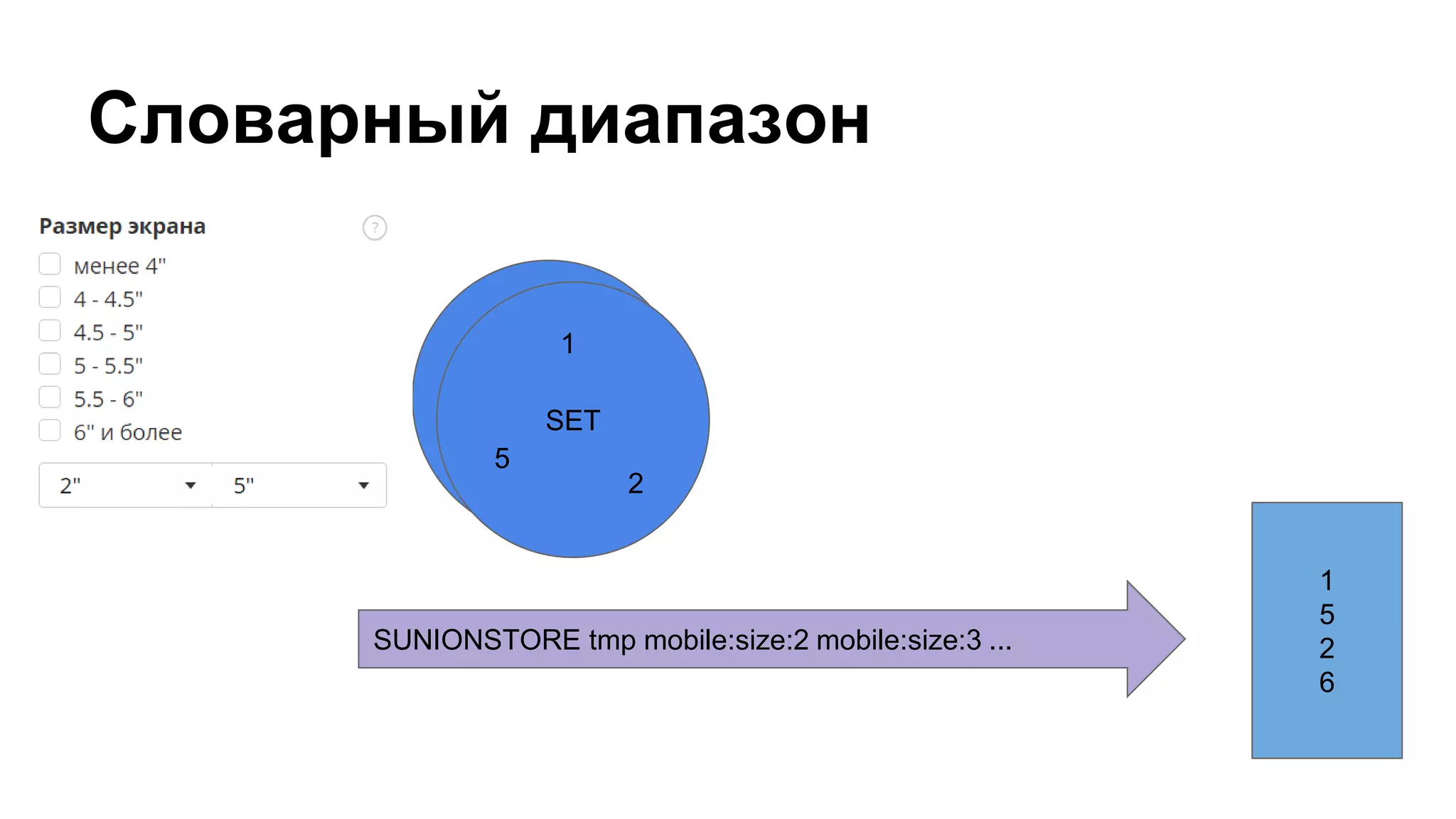
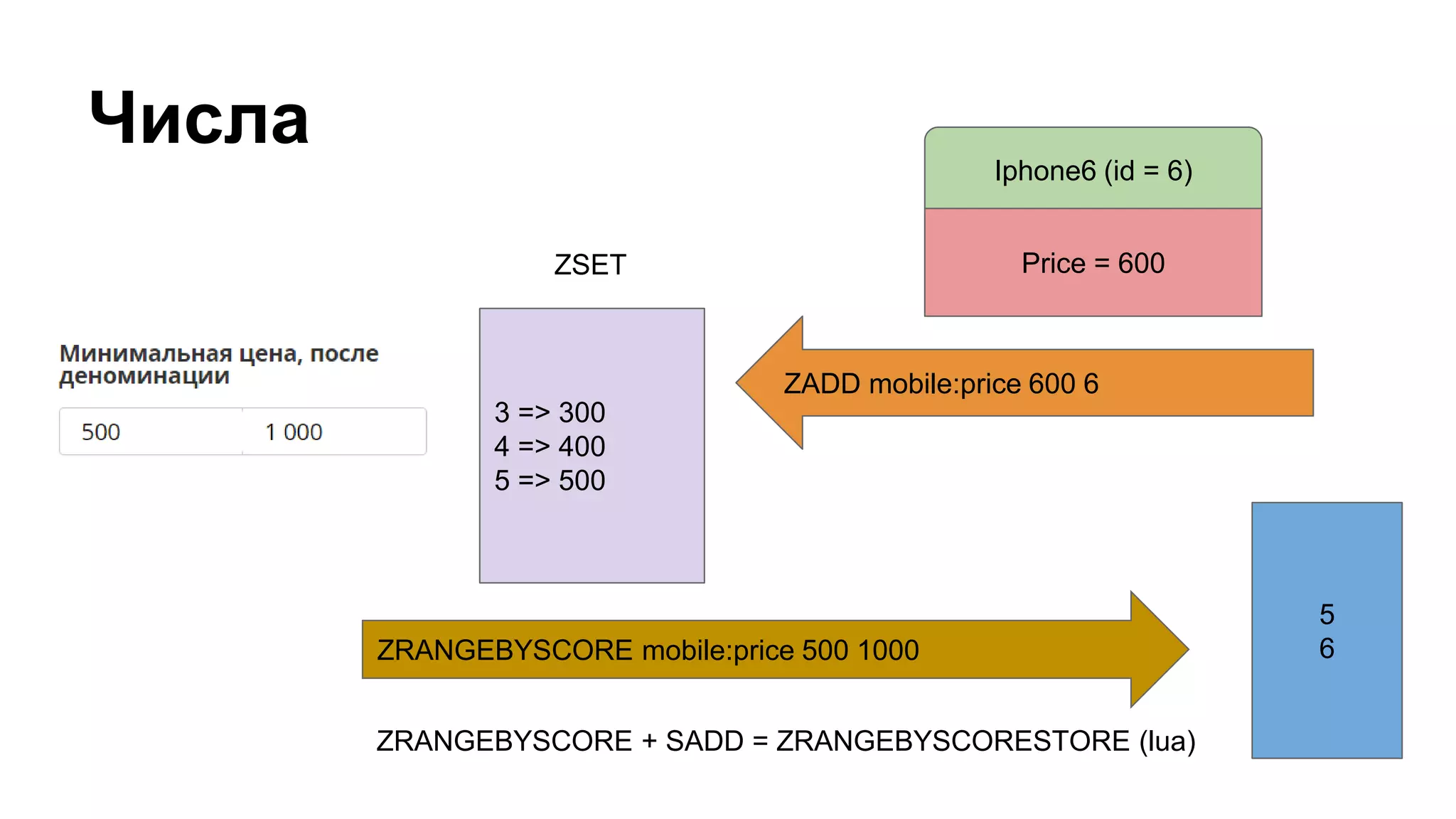
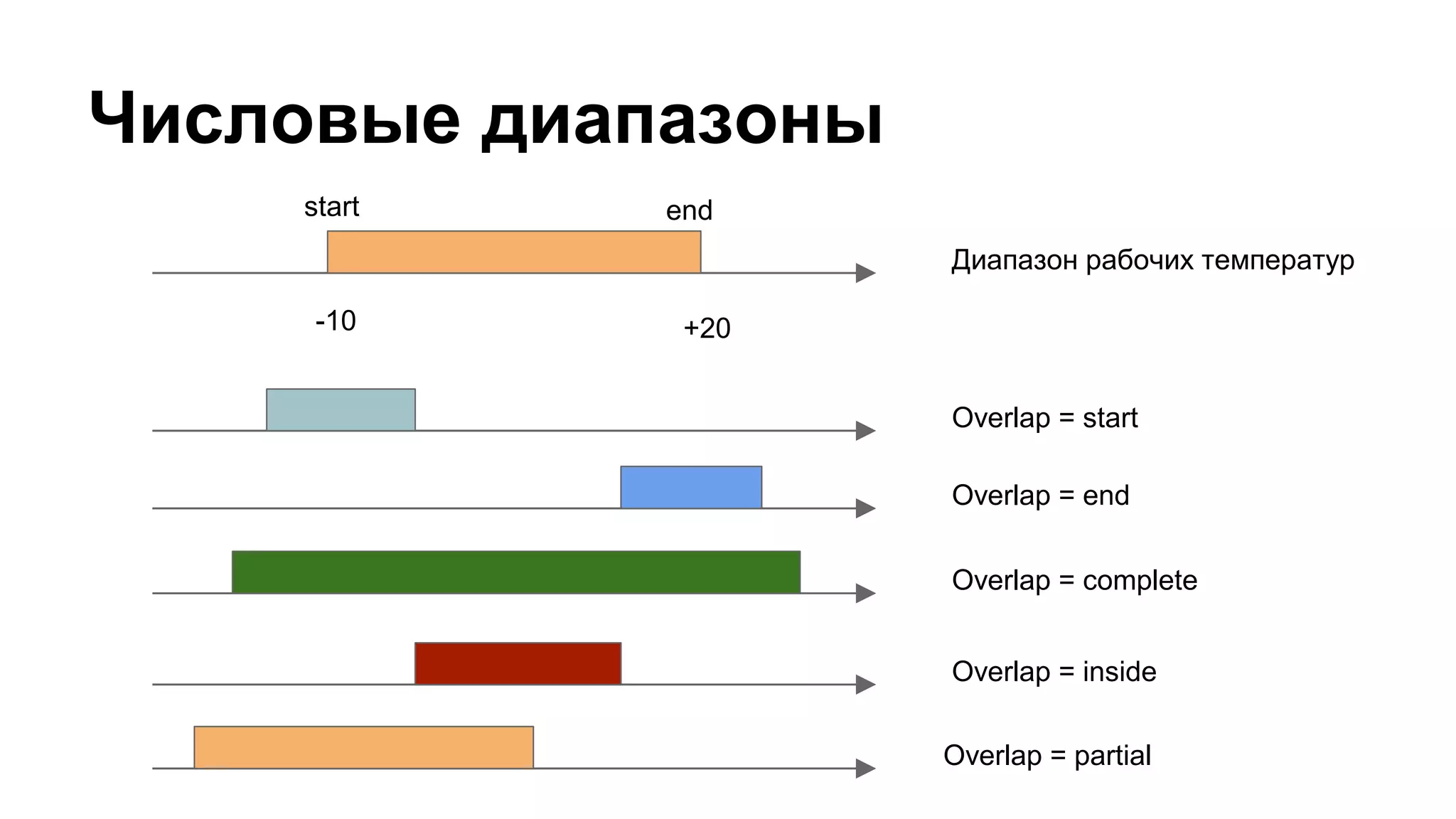
![Группировка
Object_id => parent_id
ZSET
ZINTER tmp set map
WEIGHTS 0 1
parent_id[]](https://image.slidesharecdn.com/redis-170220093525/75/Redis-18-2048.jpg)



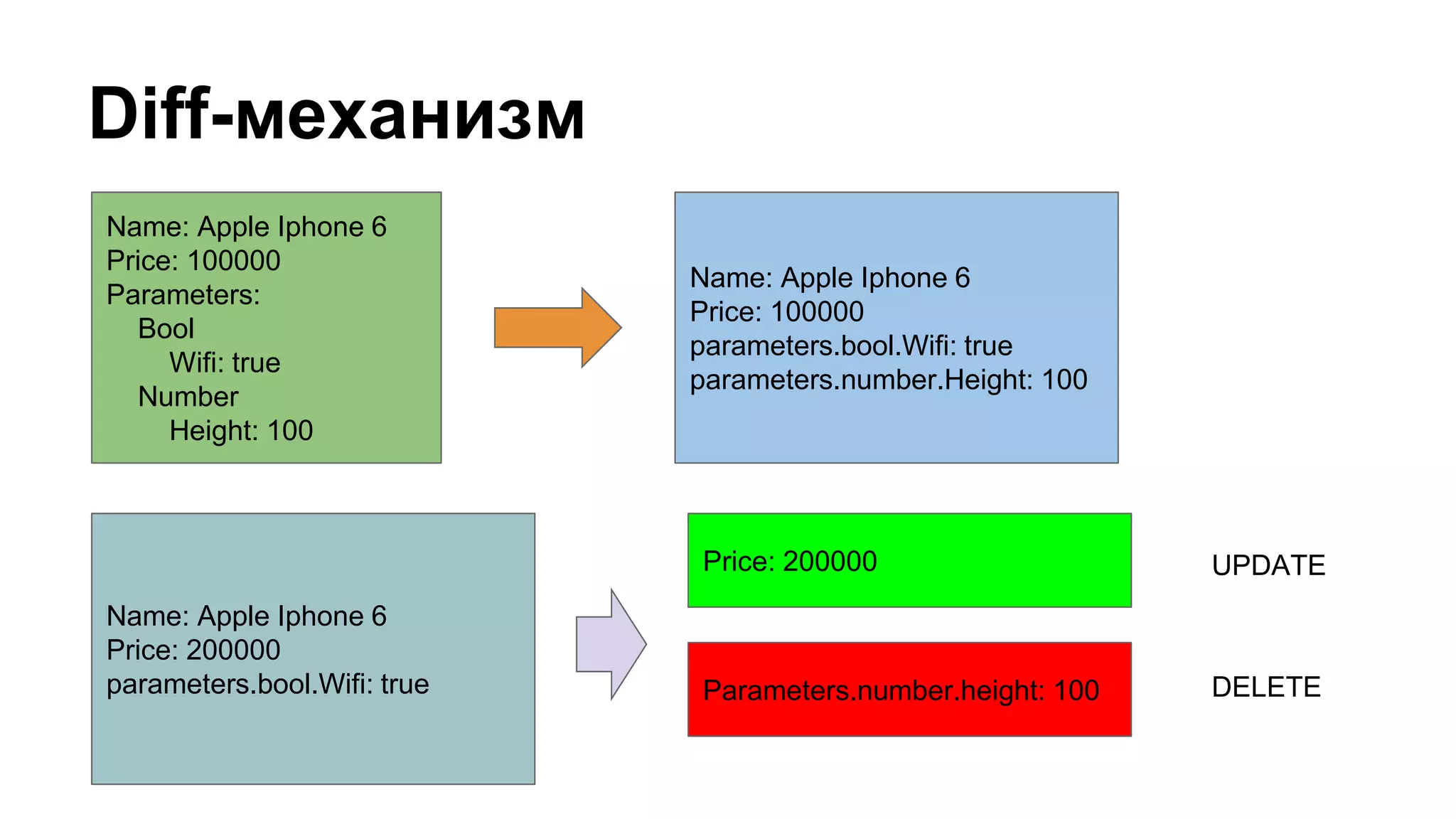

![Пример index builder-а
class BoolIndex extends Builder
{
public function matches($key)
{
return str_is($this->filter, $key);
}
public function update($redis, array $product, $key, $value)
{
if ($value) {
$redis->sadd($key, $product['id']);
}
}
public function delete($redis, array $product, $key, $value)
{
if ($value) {
$redis->srem($key, $product['id']);
}
}
}](https://image.slidesharecdn.com/redis-170220093525/75/Redis-24-2048.jpg)

![Методы обновления индекса
patchIndex
частичное обновление индекса
new = array_merge(previous, new)
putIndex
полная перезапись индекса
deleteIndex
удаление объекта из индекса
new = []](https://image.slidesharecdn.com/redis-170220093525/75/Redis-26-2048.jpg)





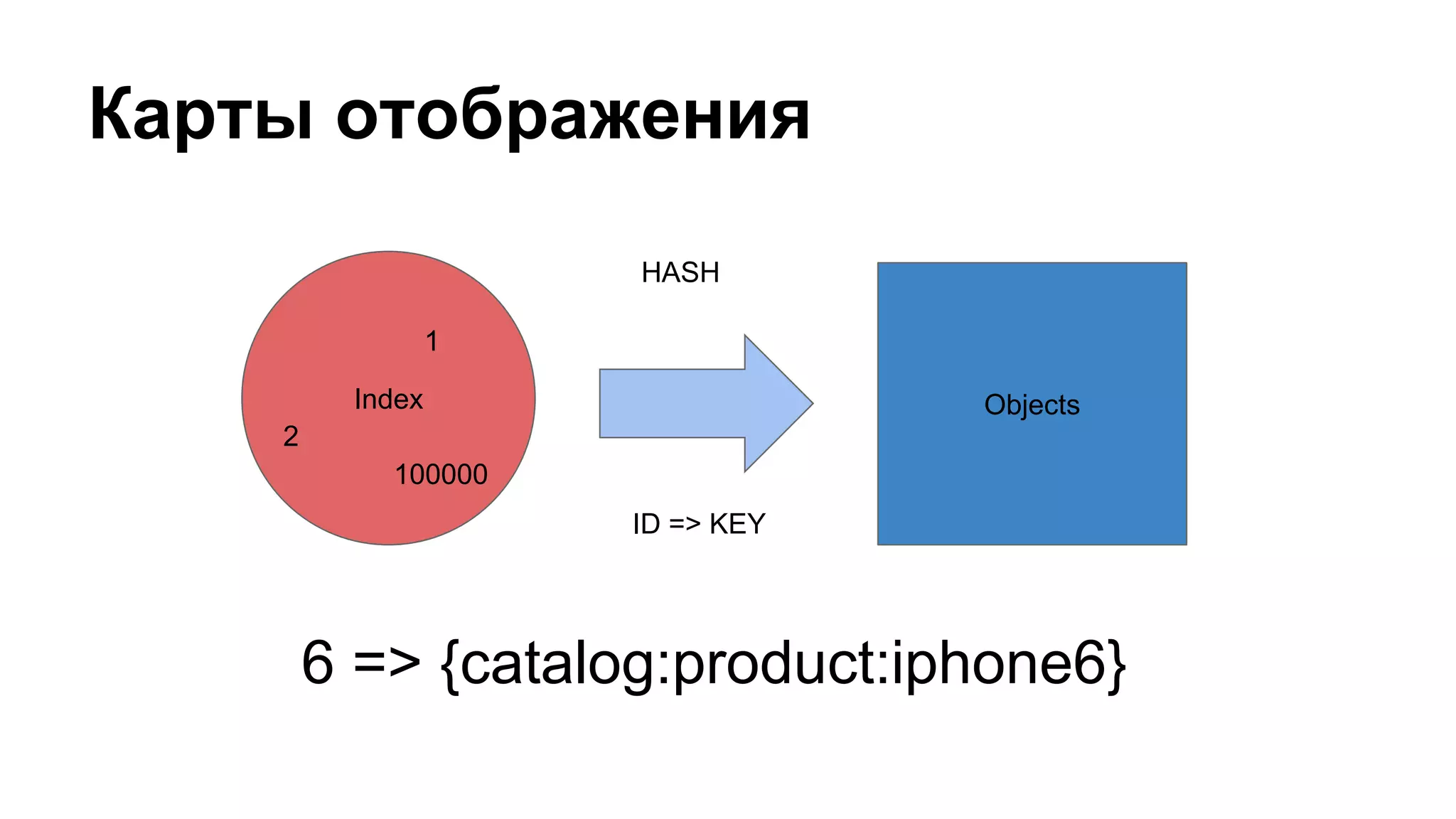
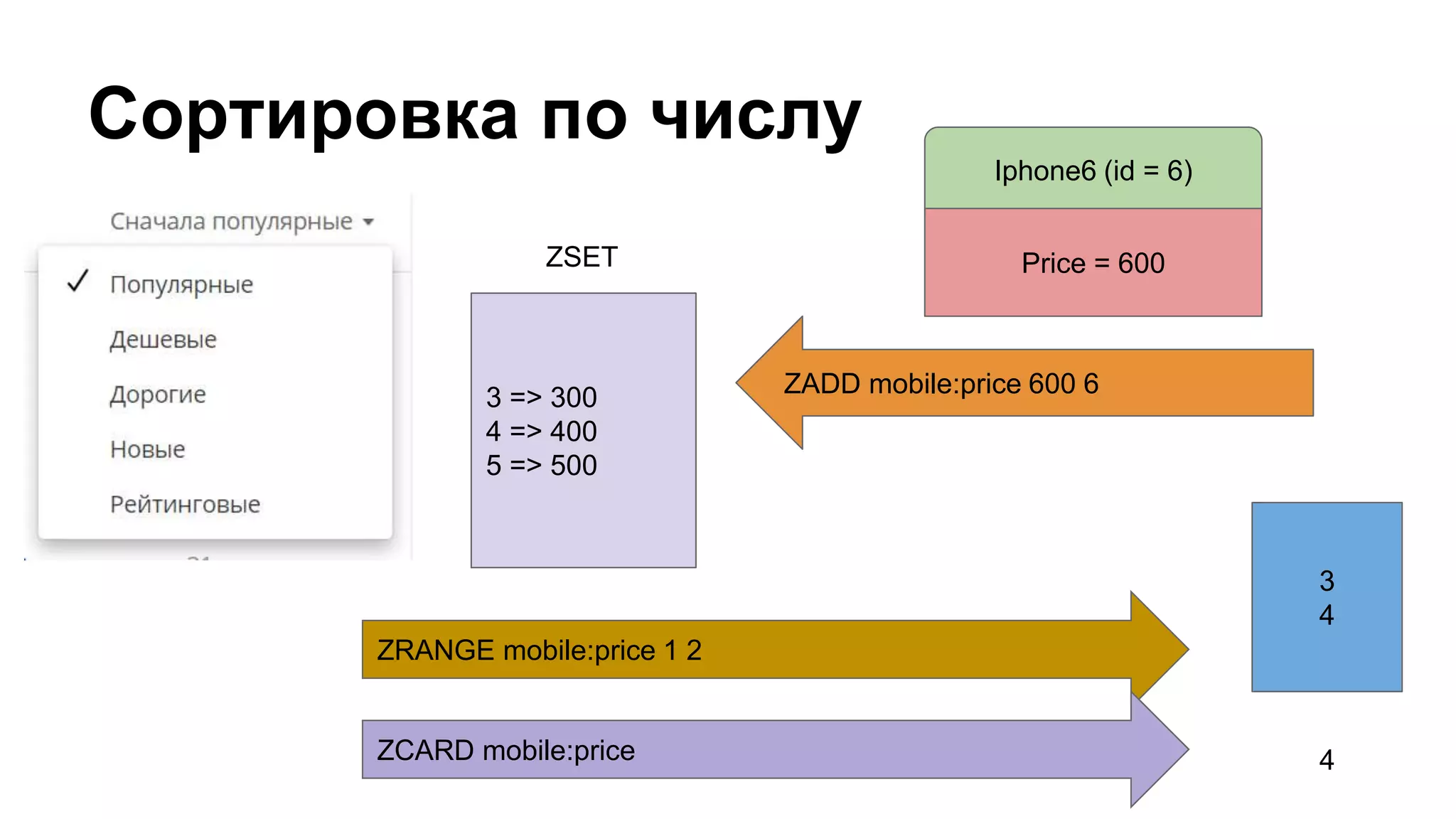
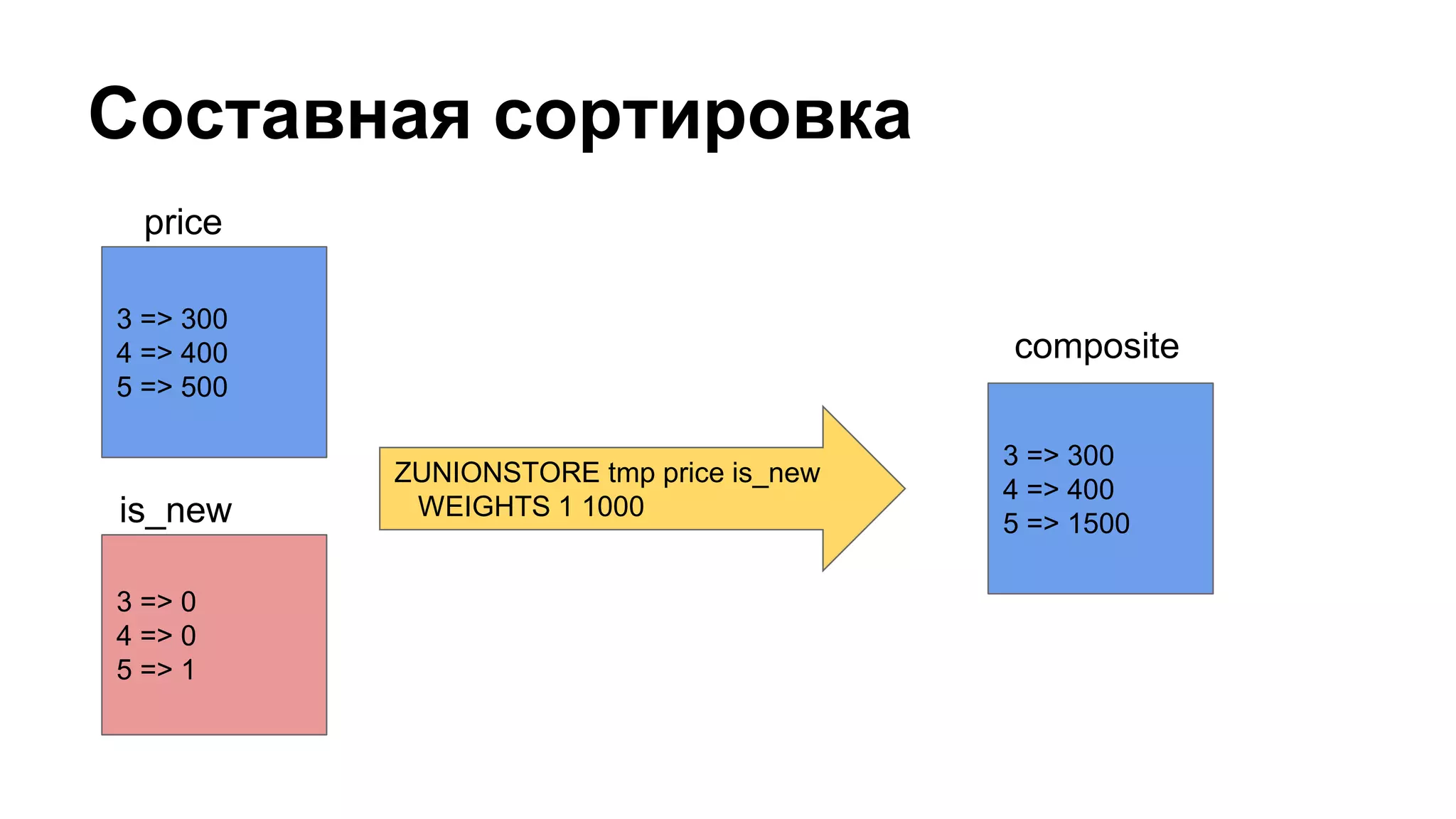
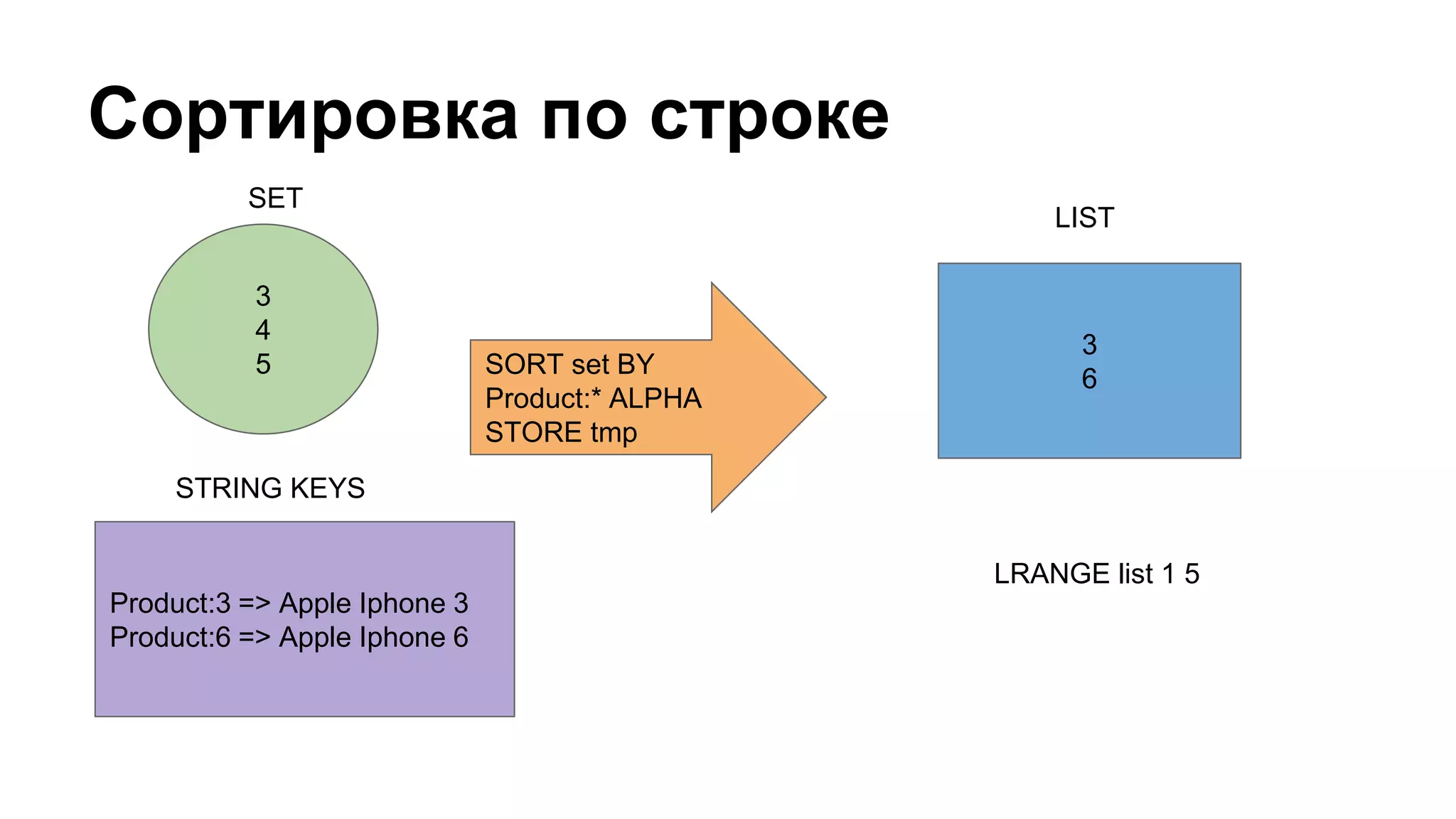
Документ охватывает создание и управление индексами в Redis для каталога товаров, включая процесс индексирования, обновления и поиска по параметрам. Приведены примеры реализации индексных строителей и запросов, описывающих работу с данными в Redis, а также механизмов кэширования и денормализации. Документ включает детали о структурировании данных, их параметрах и процессах сортировки и группировки.









![[B31,32]SQL Server Internal と パフォーマンスチューニング by Yukio Kumazawa](https://cdn.slidesharecdn.com/ss_thumbnails/sqlserverinternalupload-140204185245-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

































