The document summarizes a research paper on Deep Crossing, a deep learning model that automatically combines features for web-scale modeling without manually crafted combinatorial features. The key points are:
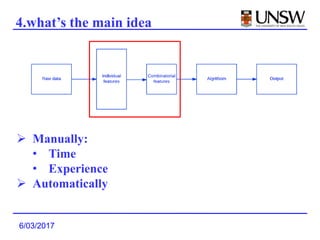
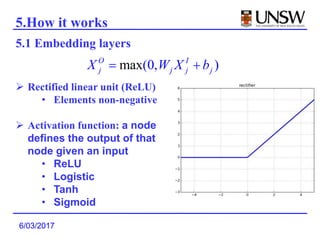
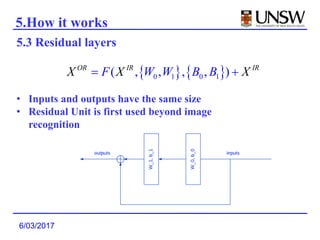
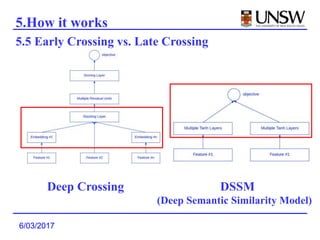
1. Deep Crossing uses a neural network to automatically learn combinatorial features from individual features, avoiding the manual feature engineering required by previous models.
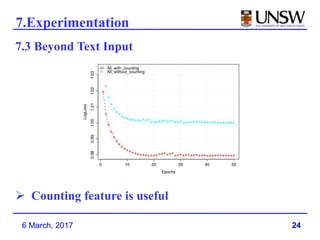
2. It was shown to outperform previous models like DSSM that used late feature crossing. Deep Crossing's early feature crossing was more effective.
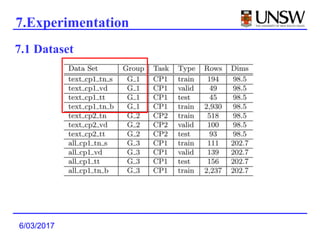
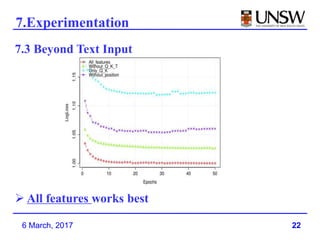
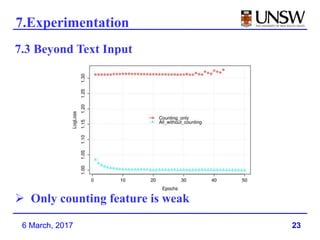
3. Deep Crossing was able to achieve better performance than production models using much less training data, and is easier to build and maintain than manually engineered models.






































![[FOSS4G 2017 Boston]Development of an extension of Geoserver for handling 3D ...](https://cdn.slidesharecdn.com/ss_thumbnails/v2oglr9ztj6rozsfllyr-signature-7a758961d3f50ce339111f96a982ffa97fdeafa443a72eaf3f00f44b1d62f961-poli-170822063420-thumbnail.jpg?width=640&height=640&fit=bounds)



![Introducing TiDB [Delivered: 09/25/18 at Portland Cloud Native Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/portlandk8smeetupintroducingtidb-180926052719-thumbnail.jpg?width=640&height=640&fit=bounds)

































































