Download as PDF, PPTX













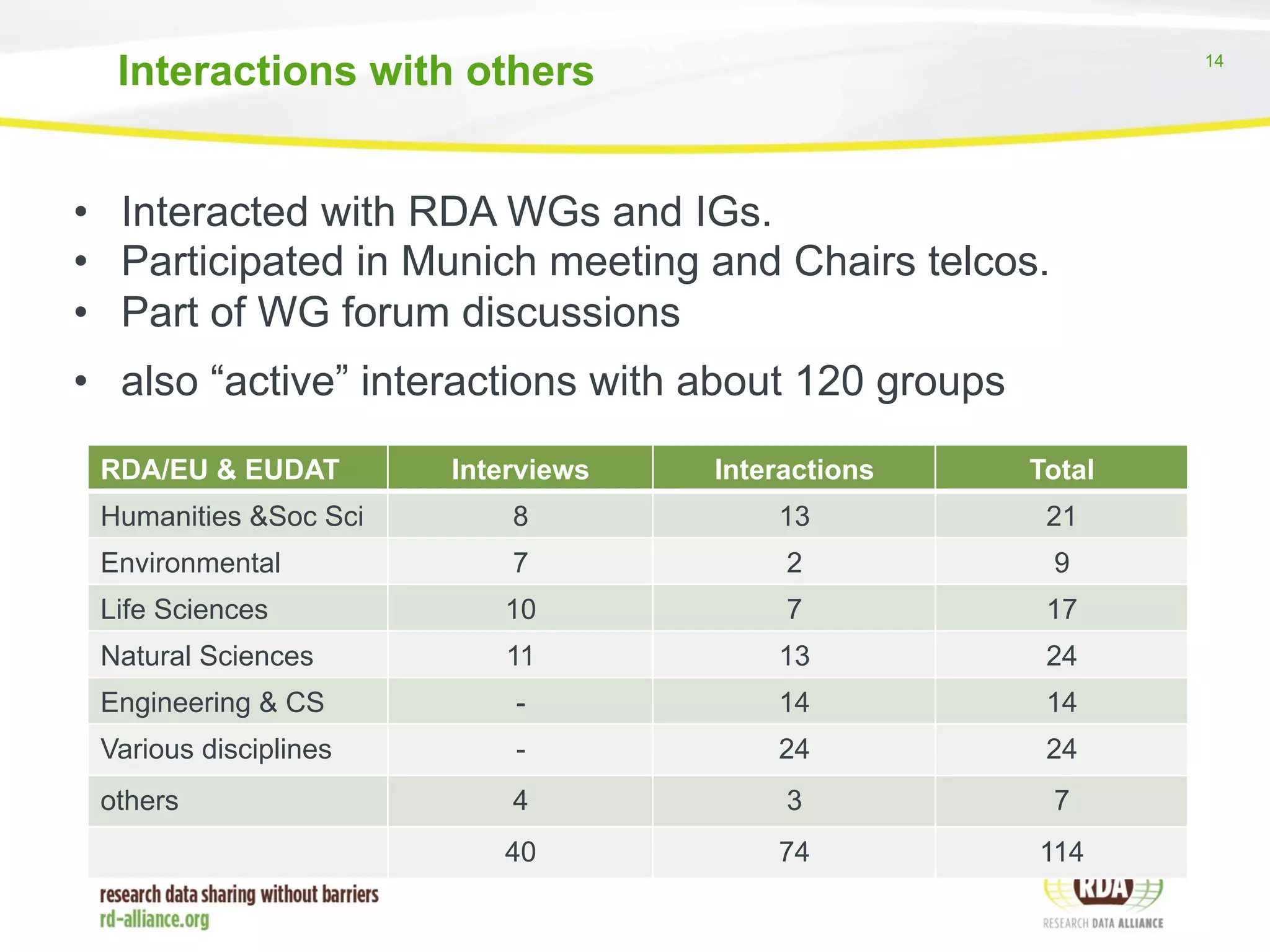













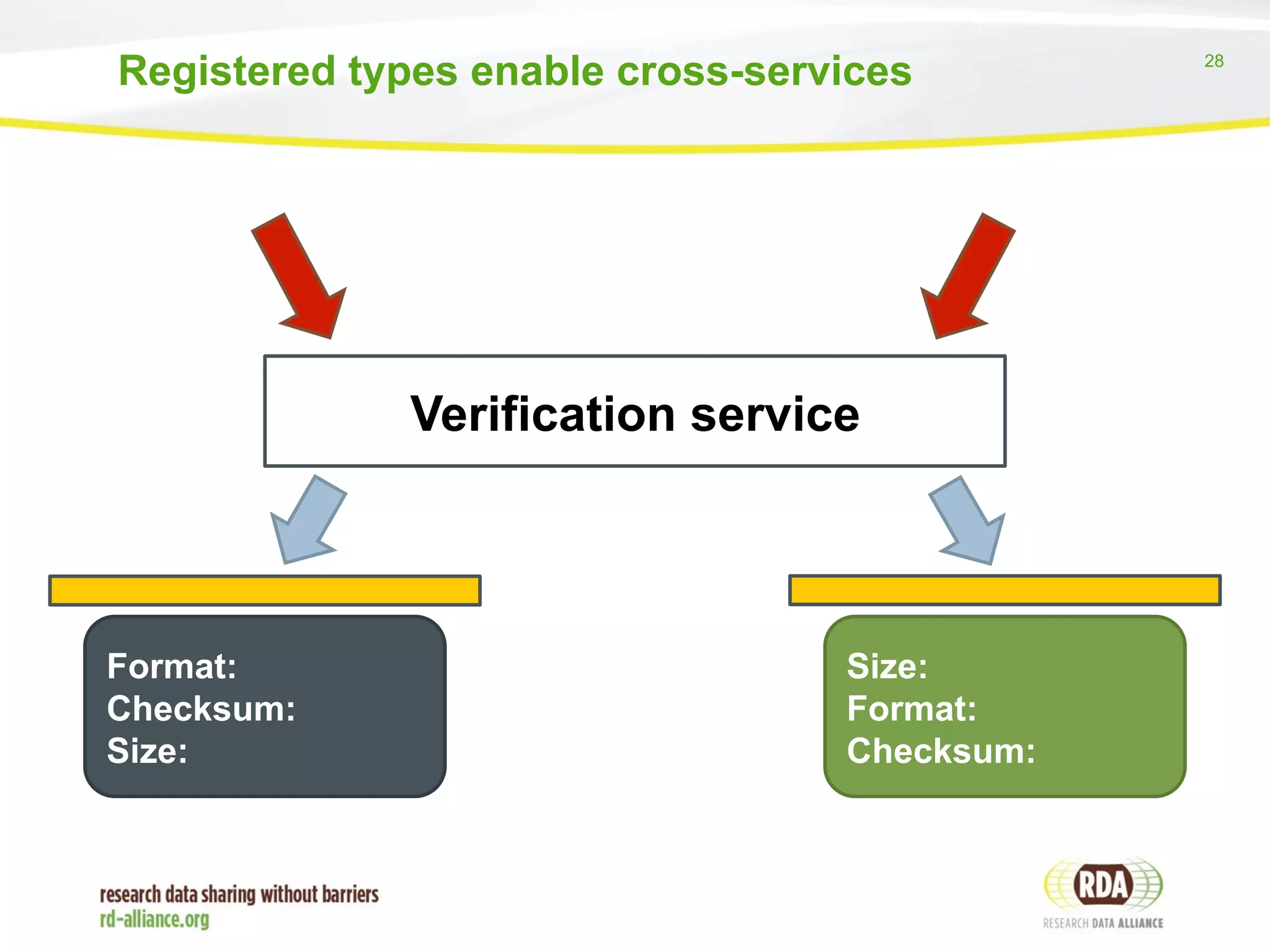








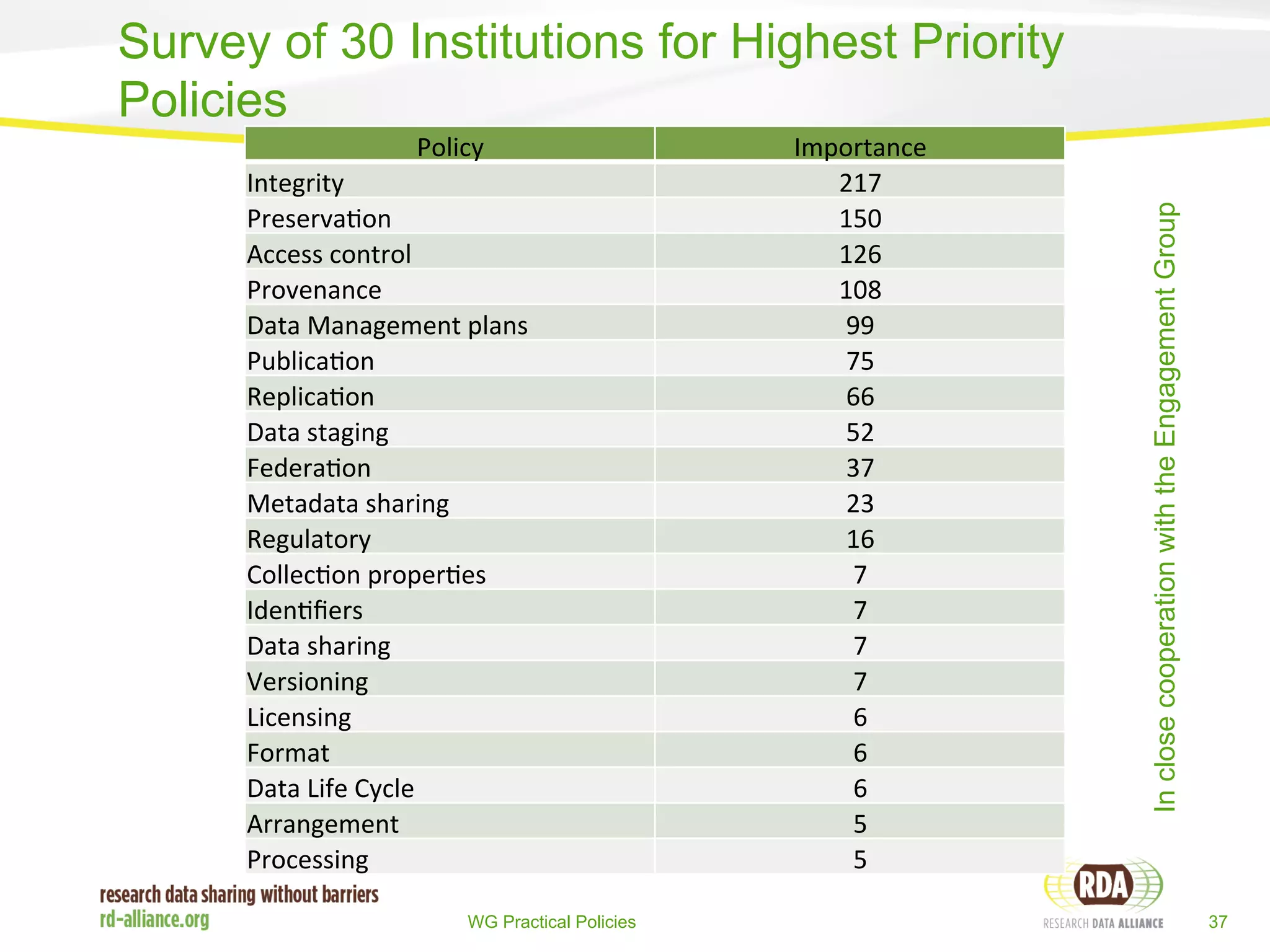
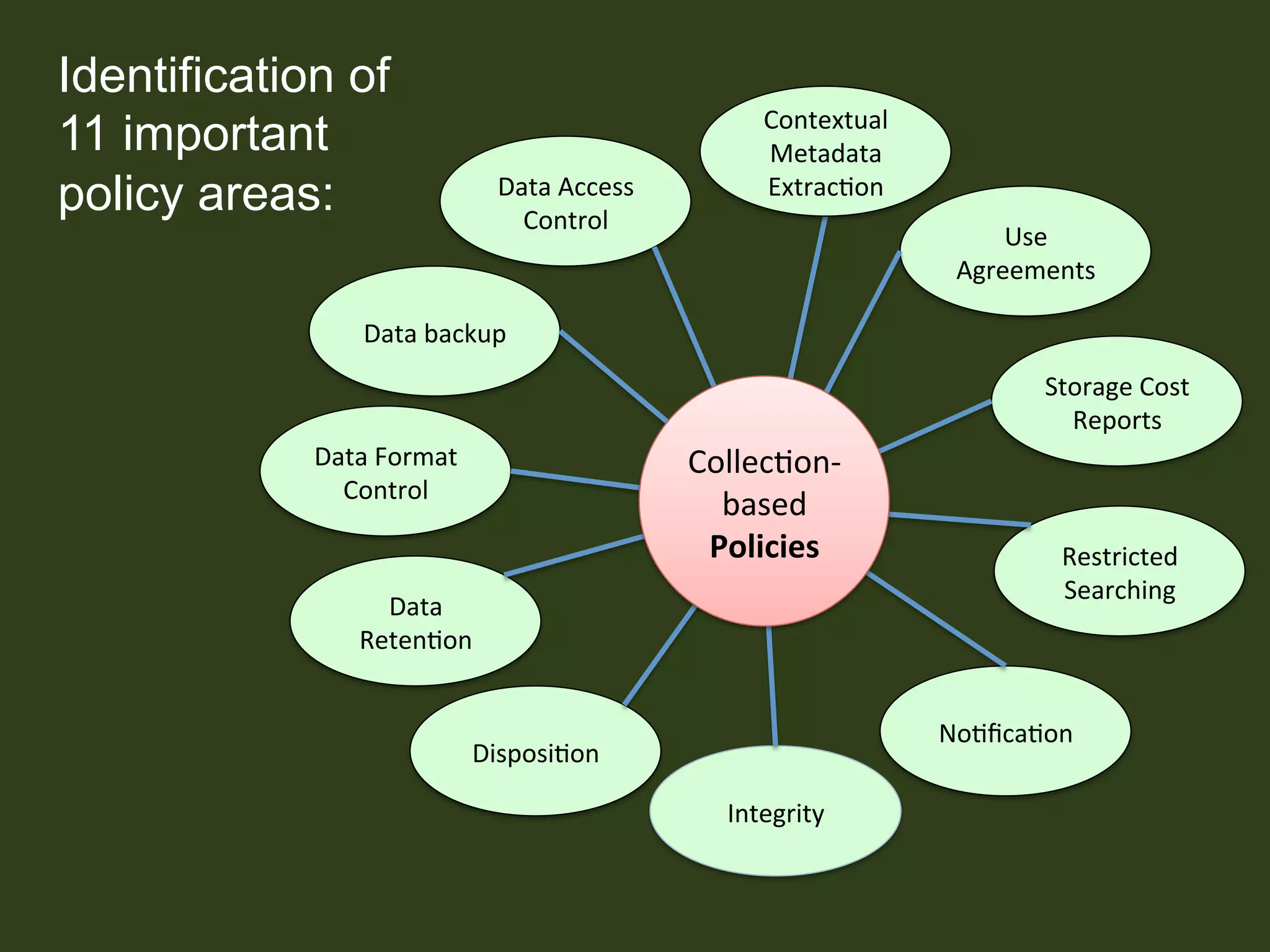











The report discusses the progress and challenges of the Research Data Alliance (RDA) in promoting data adoption, emphasizing the importance of motivated groups and reducing reliance on volunteer labor. It highlights the need for clear definitions and harmonization of data terms and policies to support effective data management and sharing across disciplines. The report outlines ongoing initiatives and collaboration efforts to enhance data interoperability and encourages deeper engagement with organizations for the adoption of RDA outputs.



































































