Download to read offline





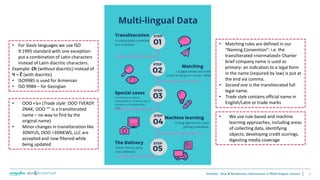




This document discusses multi-lingual data processing and natural language processing techniques used by Interfax - Dun & Bradstreet. It provides details on: 1. The main stages of processing multi-lingual business data including naming conventions, transliteration, and matching. 2. Official languages, populations, and use of Russian as a second language across countries in the CIS and Georgia region. 3. Techniques used for named entity recognition, fact extraction, sentiment analysis, and verification of media coverage including support vector machines, Bayes classification, and rule-based approaches.





























![[EN] "Multilingual Information and Retrieval Systems Technology and Applicati...](https://cdn.slidesharecdn.com/ss_thumbnails/mlengl-190524161133-thumbnail.jpg?width=640&height=640&fit=bounds)
![[EN] Multilingual Information and Retrieval Systems, Technology and Applicati...](https://cdn.slidesharecdn.com/ss_thumbnails/mlengl-190412151047-thumbnail.jpg?width=640&height=640&fit=bounds)






























