The document summarizes Dr. Timo Borst's presentation on improving library services with semantic web technology, specifically regarding repository systems.
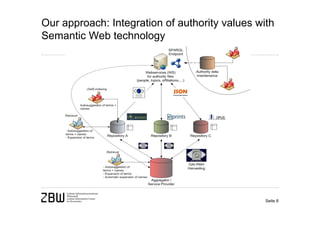
[1] Current library applications generate and manage siloed metadata collections, making aggregation and standardization of metadata difficult for expanded services.
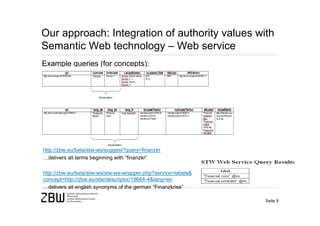
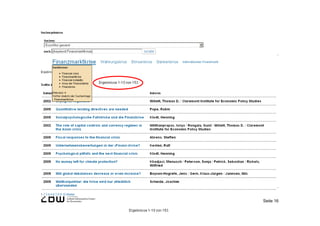
[2] Semantic web services as part of an overarching authority data infrastructure can help standardize metadata early in the process while still allowing for local differences.
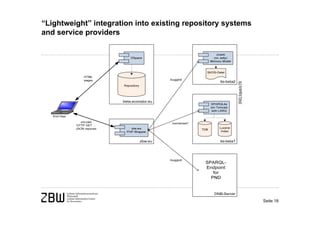
[3] If these services are widely adopted and used, there is potential for greater networking of locally managed metadata while improving data-driven services through lightweight integration into existing library applications.




















![•[1] http://wiki.dspace.org/index.php/Authority_Control_of_Metadata_Values
Literatur
•[2] http://minds.wisconsin.edu/handle/1793/31735
•[3] http://dsug09.ub.gu.se/index.php/dsug/dsug09/paper/view/22/3
•[4] http://subjectobject.net/2006/11/09/the-dspace-digital-repository-a-project-analysis/
•[5] http://code.google.com/p/dspace-agrisap/wiki/ThesaurusAddOn
•[6] http://edoc.hu-berlin.de/conferences/dc-2008/subirats-imma-199/PDF/subirats.pdf
•[7] http://www.jisc.ac.uk/media/documents/programmes/sharedservices/na
mes-phase-one-final-report,.pdf
•[8] http://idea.library.drexel.edu/bitstream/1860/3173/1/20070051011.pdf
•[9] http://ptsefton.com/blog/2006/06/06/the_affiliation_issue_in
_institutional_repository_software/
•[10] http://library.ust.hk/info/nac/nac-technical.html
•[11] http://www.seco.tkk.fi/publications/2009/kurki-hyvonen-onki-people-2009.pdf
•[12] http://journals.sfu.ca/archivar/index.php/archivaria/article/download/11883/12836
•[13] http://www.dini.de/fileadmin/workshops/oa-netzwerk-
juni2009/vernetzungstage_2009_malitz.pdf
Seite 25](https://image.slidesharecdn.com/icdk2011enfinal-110704080907-phpapp02/85/Improving-library-services-with-semantic-web-technology-in-the-realm-of-repositories-25-320.jpg)














































































