Download as PDF, PPTX

























![分詞(tokenization)
Today is a beautiful day
利用空白
[Today] [is] [a] [beautiful] [day]](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-28-2048.jpg)
![分詞(tokenization)
Today is a beautiful day
利用空白
[Today] [is] [a] [beautiful] [day]
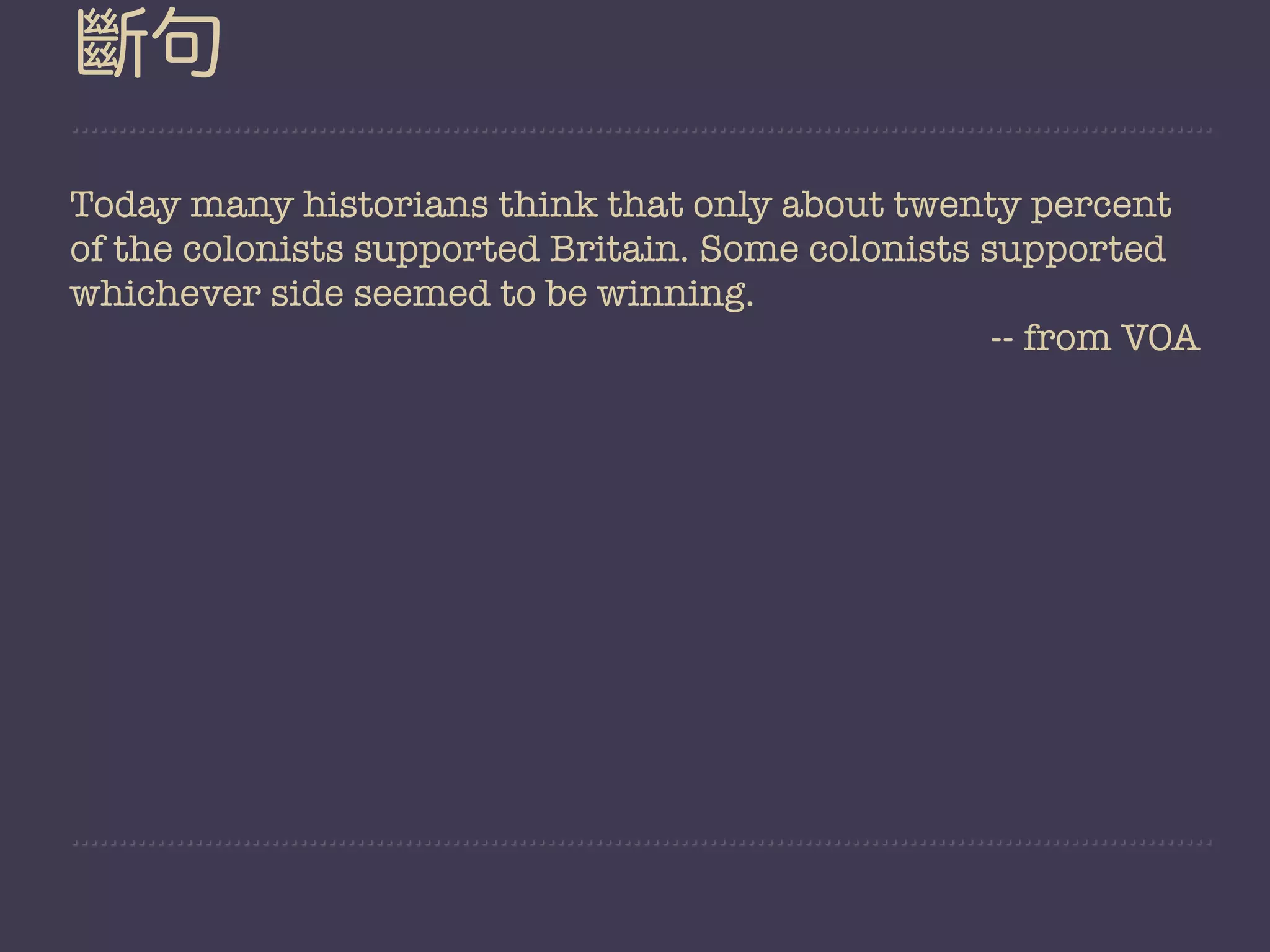
beautiful day.
“Who knows?”
$50
industry’s
for youths;](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-29-2048.jpg)
![分詞(tokenization)
Today is a beautiful day
利用空白
[Today] [is] [a] [beautiful] [day]
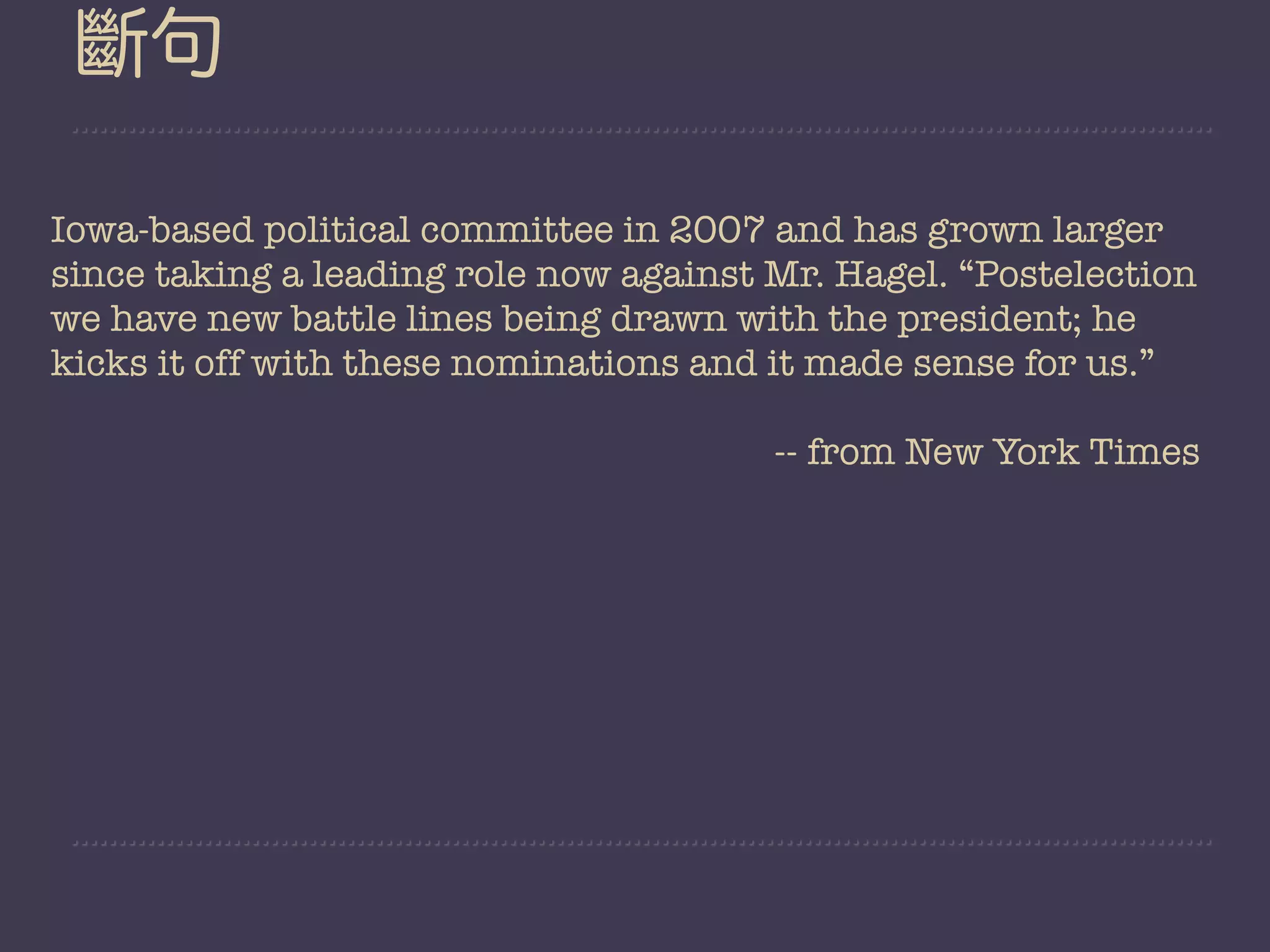
beautiful day.
$50
?
for youths;
“Who knows?”
industry’s](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-30-2048.jpg)





![Demo1
#!/usr/bin/env python
import nltk
from urllib import urlopen
url="http://www.voanews.com/articleprintview/1587223.html"
html = urlopen(url).read()
raw = nltk.clean_html(html)
#nltk.download(‘punkt’)
sent_tokenizer=nltk.data.load('tokenizers/punkt/
english.pickle')
sents = sent_tokenizer.tokenize(raw)
token = nltk.word_tokenize(sents[1])
#nltk.download(‘maxent_treebank_pos_tagger’)
pos = nltk.pos_tag(token)](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-40-2048.jpg)
![Demo1
#!/usr/bin/env python
import nltk
from urllib import urlopen
url="http://www.voanews.com/articleprintview/1587223.html"
html = urlopen(url).read()
raw = nltk.clean_html(html) 清除html tag
#nltk.download(‘punkt’)
sent_tokenizer=nltk.data.load('tokenizers/punkt/
english.pickle')
sents = sent_tokenizer.tokenize(raw)
token = nltk.word_tokenize(sents[1])
#nltk.download(‘maxent_treebank_pos_tagger’)
pos = nltk.pos_tag(token)](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-41-2048.jpg)
![Demo1
#!/usr/bin/env python
import nltk
from urllib import urlopen
url="http://www.voanews.com/articleprintview/1587223.html"
html = urlopen(url).read()
raw = nltk.clean_html(html)
#nltk.download(‘punkt’)
sent_tokenizer=nltk.data.load('tokenizers/punkt/
english.pickle')
sents = sent_tokenizer.tokenize(raw) 斷句
token = nltk.word_tokenize(sents[1])
#nltk.download(‘maxent_treebank_pos_tagger’)
pos = nltk.pos_tag(token)](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-42-2048.jpg)
![Demo1
#!/usr/bin/env python
import nltk
from urllib import urlopen
url="http://www.voanews.com/articleprintview/1587223.html"
html = urlopen(url).read()
raw = nltk.clean_html(html)
#nltk.download(‘punkt’)
sent_tokenizer=nltk.data.load('tokenizers/punkt/
english.pickle')
sents = sent_tokenizer.tokenize(raw)
token = nltk.word_tokenize(sents[1]) 分詞
#nltk.download(‘maxent_treebank_pos_tagger’)
pos = nltk.pos_tag(token)](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-43-2048.jpg)
![Demo1
#!/usr/bin/env python
import nltk
from urllib import urlopen
url="http://www.voanews.com/articleprintview/1587223.html"
html = urlopen(url).read()
raw = nltk.clean_html(html)
#nltk.download(‘punkt’)
sent_tokenizer=nltk.data.load('tokenizers/punkt/
english.pickle')
sents = sent_tokenizer.tokenize(raw)
token = nltk.word_tokenize(sents[1])
#nltk.download(‘maxent_treebank_pos_tagger’)
pos = nltk.pos_tag(token) 詞性標記](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-44-2048.jpg)
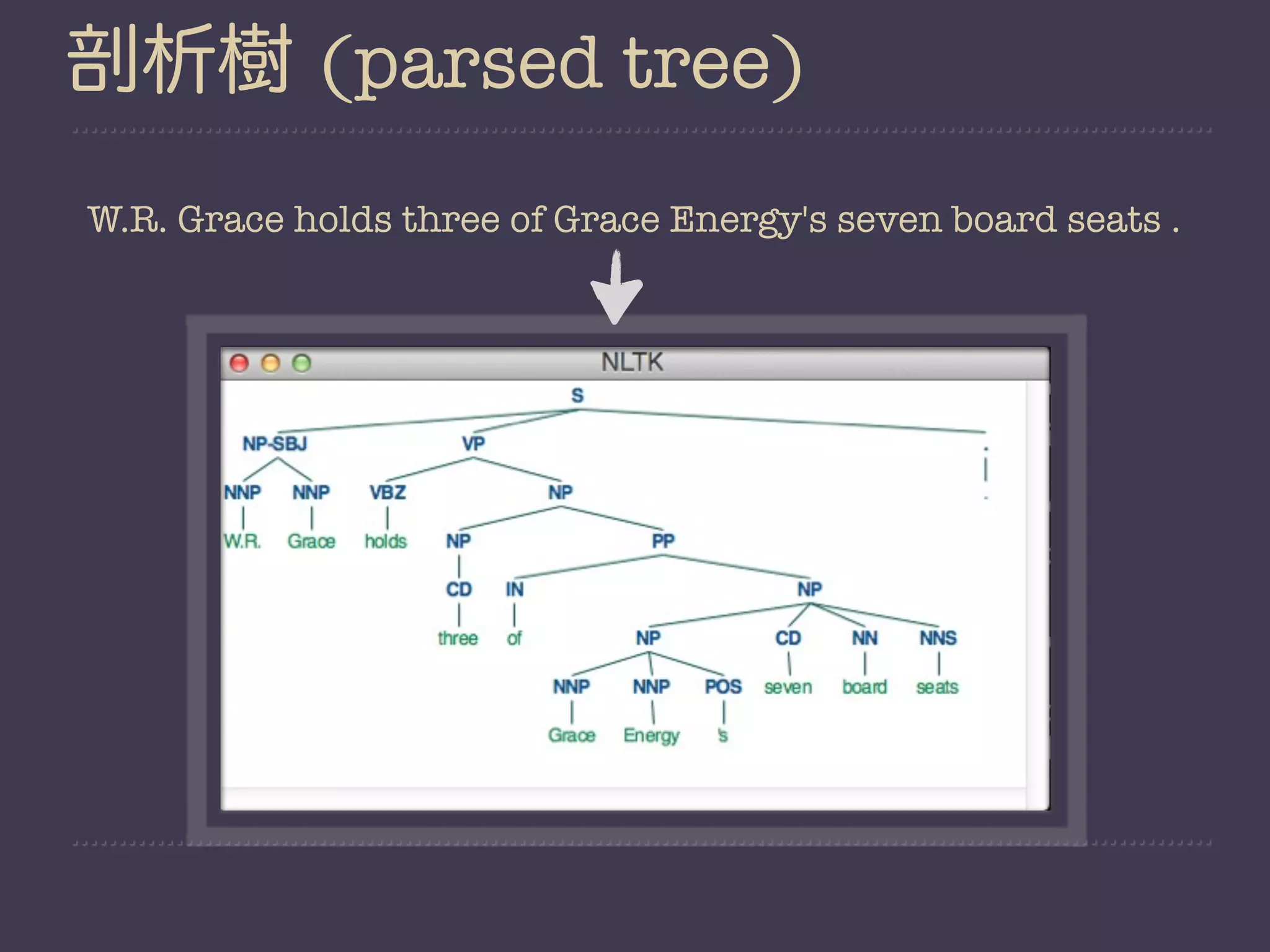
![Demo2
#!/usr/bin/env python
#nltk.download(‘treebank’)
import nltk
from nltk.corpus import treebank
from nltk.grammar import ContextFreeGrammar, Nonterminal
from nltk.parse import ChartParser
productions = set(
production for sent in treebank.parsed_sents()[0:9]
for production in sent.productions())
grammar = ContextFreeGrammar(Nonterminal('S'),productions)
parser = ChartParser(grammar)
parsed_tree = parser.parse(treebank.sents()[0])
# print parsed_tree](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-45-2048.jpg)
![Demo2
#!/usr/bin/env python
#nltk.download(‘treebank’)
import nltk
from nltk.corpus import treebank
from nltk.grammar import ContextFreeGrammar, Nonterminal
from nltk.parse import ChartParser
productions = set( treebank production
production for sent in treebank.parsed_sents()[0:9]
for production in sent.productions())
grammar = ContextFreeGrammar(Nonterminal('S'),productions)
parser = ChartParser(grammar)
parsed_tree = parser.parse(treebank.sents()[0])
# print parsed_tree](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-46-2048.jpg)
![Demo2
#!/usr/bin/env python
#nltk.download(‘treebank’)
import nltk
from nltk.corpus import treebank
from nltk.grammar import ContextFreeGrammar, Nonterminal
from nltk.parse import ChartParser
productions = set(
production for sent in treebank.parsed_sents()[0:9]
for production in sent.productions())
encoder grammar
grammar = ContextFreeGrammar(Nonterminal('S'),productions)
parser = ChartParser(grammar)
parsed_tree = parser.parse(treebank.sents()[0])
# print parsed_tree](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-47-2048.jpg)
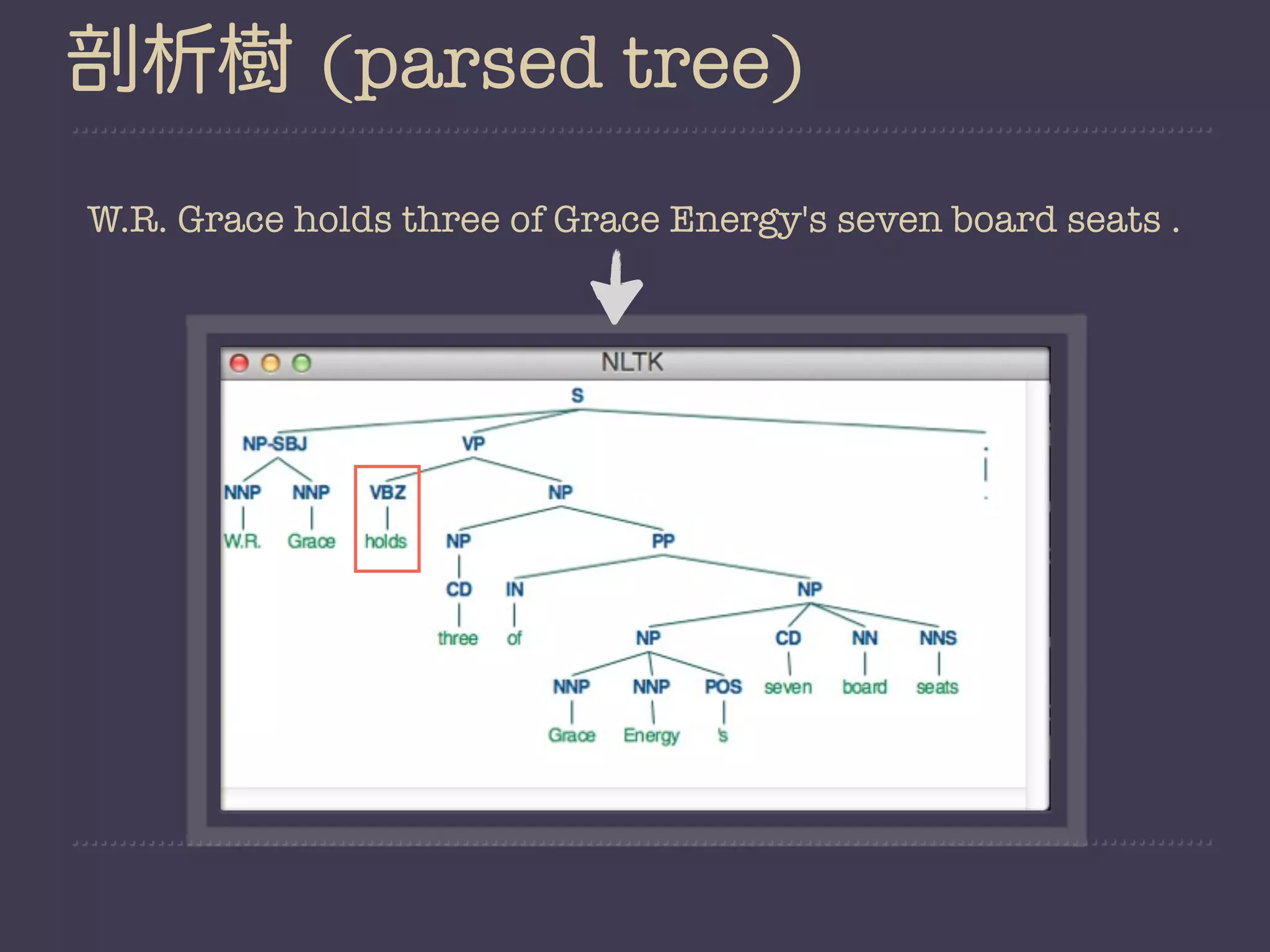
![Demo2
#!/usr/bin/env python
#nltk.download(‘treebank’)
import nltk
from nltk.corpus import treebank
from nltk.grammar import ContextFreeGrammar, Nonterminal
from nltk.parse import ChartParser
productions = set(
production for sent in treebank.parsed_sents()[0:9]
for production in sent.productions())
grammar = ContextFreeGrammar(Nonterminal('S'),productions)
parser = ChartParser(grammar) 產生parser
parsed_tree = parser.parse(treebank.sents()[0])
# print parsed_tree](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-48-2048.jpg)
![Demo3
#!/usr/bin/env python
#nltk.download(‘reuters’)
import nltk
from nltk.probability import FreqDist
from nltk.probability import ConditionalFreqDist
from nltk.corpus import reuters
from nltk.corpus import brown
fd = FreqDist(map(lambda w : w.lower(), brown.words()[0:50]))
#fd.tabulate(10)
#fd.plot()
cdf = ConditionalFreqDist((corpus, word)
for corpus in ['reuters', 'brown']
for word in eval(corpus).words()
if word in map(str,range(1900,1950,5)))
#cdf.conditions()
#cdf['brown']['1910']
#cdf.tabulate()
#cdf.plot()](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-49-2048.jpg)
![Demo3
#!/usr/bin/env python
#nltk.download(‘reuters’)
import nltk
from nltk.probability import FreqDist
from nltk.probability import ConditionalFreqDist
from nltk.corpus import reuters
from nltk.corpus import brown
詞頻統計
fd = FreqDist(map(lambda w : w.lower(), brown.words()[0:50]))
#fd.tabulate(10)
#fd.plot()
cdf = ConditionalFreqDist((corpus, word)
for corpus in ['reuters', 'brown']
for word in eval(corpus).words()
if word in map(str,range(1900,1950,5)))
#cdf.conditions()
#cdf['brown']['1910']
#cdf.tabulate()
#cdf.plot()](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-50-2048.jpg)
![Demo3
#!/usr/bin/env python
#nltk.download(‘reuters’)
import nltk
from nltk.probability import FreqDist
from nltk.probability import ConditionalFreqDist
from nltk.corpus import reuters
from nltk.corpus import brown
fd = FreqDist(map(lambda w : w.lower(), brown.words()[0:50]))
#fd.tabulate(10)
#fd.plot() 不同條件的詞頻統計
cdf = ConditionalFreqDist((corpus, word) (Conditions and Events)
for corpus in ['reuters', 'brown']
for word in eval(corpus).words()
if word in map(str,range(1900,1950,5)))
#cdf.conditions()
#cdf['brown']['1910']
#cdf.tabulate()
#cdf.plot()](https://image.slidesharecdn.com/nltk-130129042817-phpapp01/75/Playing-with-Natural-Language-in-a-friendly-way-51-2048.jpg)


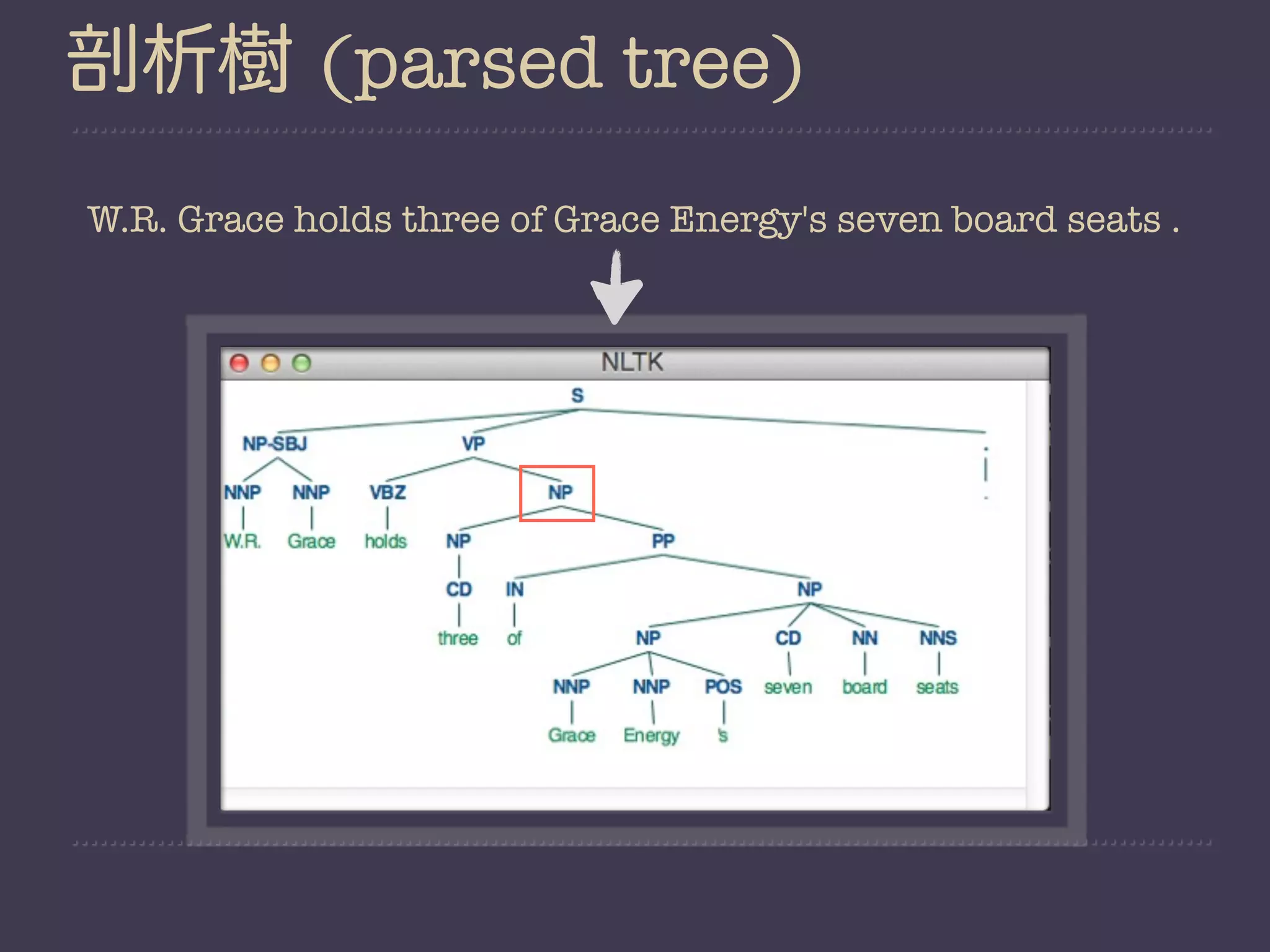
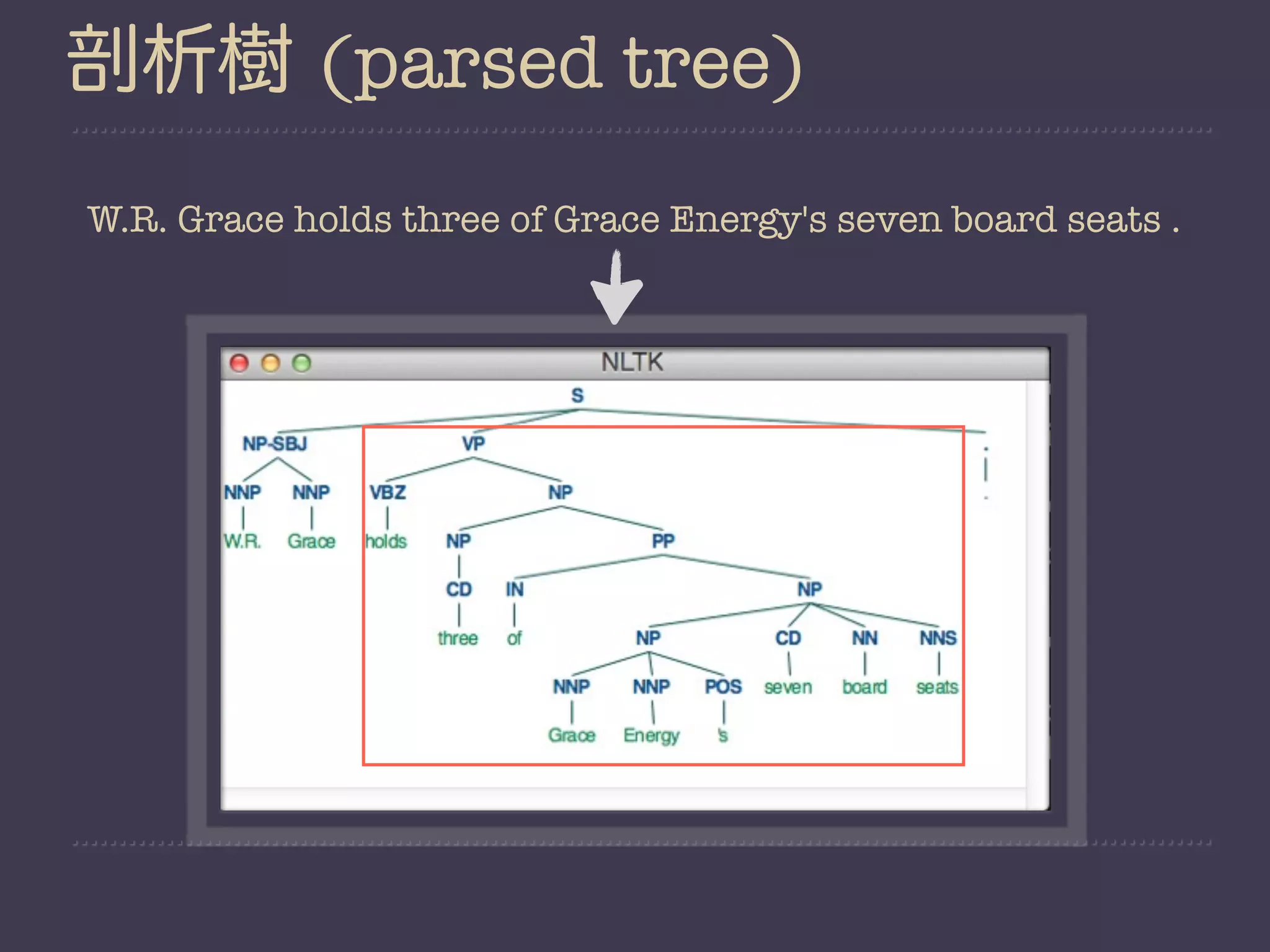
This document provides an overview of natural language processing (NLP) and the Natural Language Toolkit (NLTK) Python library. It discusses key NLP tasks like sentence segmentation, tokenization, part-of-speech tagging, and parsing. It also demonstrates examples of using NLTK to perform these tasks on text from corpora. Finally, it shows how NLTK can be used to analyze word frequencies and calculate conditional frequency distributions.










![[系列活動] 無所不在的自然語言處理—基礎概念、技術與工具介紹](https://cdn.slidesharecdn.com/ss_thumbnails/nlptutorial-0828-170830062001-thumbnail.jpg?width=640&height=640&fit=bounds)












![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















