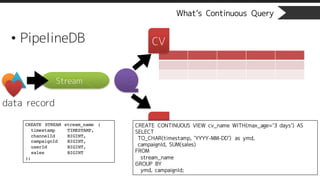
What’s PipelineDB
• OSSDatabase (+Enterprise Edition)
– GPLv3
• Support Continuous Query
• on PostgreSQL as extension
– 0.8.x on 9.4, 0.9.x on 9.5
– No special client libraries
• Support probabilistic data structure & algorithm
– Bloom-filter, hyperloglog, Count-Min sketch,
– FSS Top-K, T-Digest
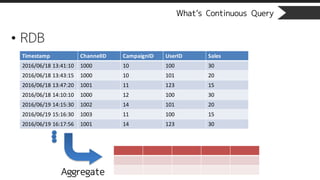
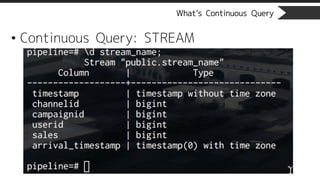
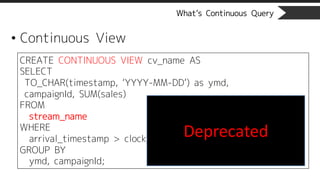
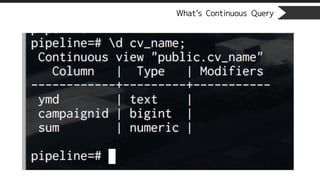
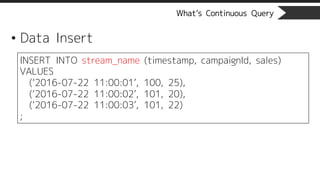
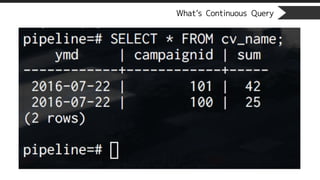
What’s Continuous Query
•Continuous View
CREATE CONTINUOUS VIEW cv_name AS
SELECT
TO_CHAR(timestamp, ‘YYYY-MM-DD’) as ymd,
campaignId, SUM(sales)
FROM
stream_name
WHERE
arrival_timestamp > clock_timestamp() - interval ‘3 days’
GROUP BY
ymd, campaignId;
Deprecated
16.
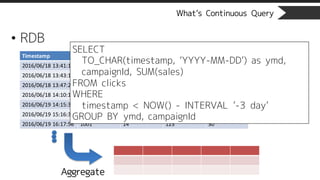
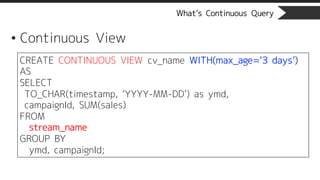
What’s Continuous Query
•Continuous View
CREATE CONTINUOUS VIEW cv_name WITH(max_age=‘3 days’)
AS
SELECT
TO_CHAR(timestamp, ‘YYYY-MM-DD’) as ymd,
campaignId, SUM(sales)
FROM
stream_name
GROUP BY
ymd, campaignId;
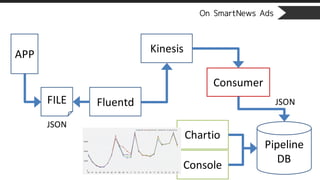
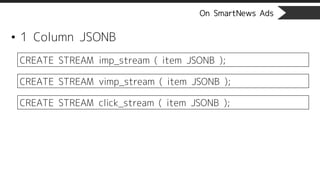
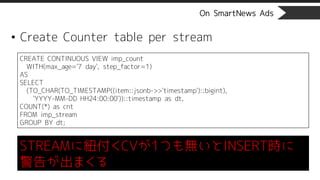
On SmartNews Ads
•Create Counter table per stream
CREATE CONTINUOUS VIEW imp_count
WITH(max_age='7 day', step_factor=1)
AS
SELECT
(TO_CHAR(TO_TIMESTAMP((item::jsonb->>'timestamp')::bigint),
'YYYY-MM-DD HH24:00:00'))::timestamp as dt,
COUNT(*) as cnt
FROM imp_stream
GROUP BY dt;
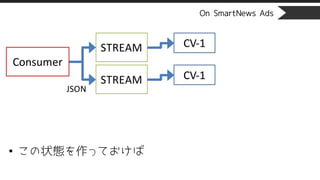
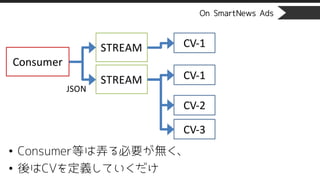
STREAMに紐付くCVが1つも無いとINSERT時に
警告が出まくる
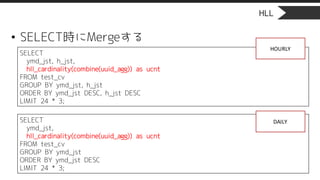
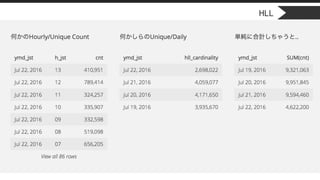
HLL
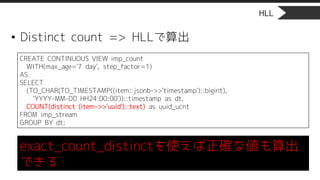
• Distinct count=> HLLで算出
CREATE CONTINUOUS VIEW imp_count
WITH(max_age='7 day', step_factor=1)
AS
SELECT
(TO_CHAR(TO_TIMESTAMP((item::jsonb->>'timestamp')::bigint),
'YYYY-MM-DD HH24:00:00'))::timestamp as dt,
COUNT(distinct (item->>'uuid')::text) as uuid_ucnt
FROM imp_stream
GROUP BY dt;
exact_count_distinctを使えば正確な値も算出
できる
HLL
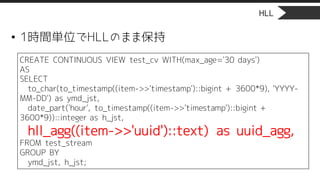
• 1時間単位でHLLのまま保持
CREATE CONTINUOUSVIEW test_cv WITH(max_age='30 days')
AS
SELECT
to_char(to_timestamp((item->>'timestamp')::bigint + 3600*9), 'YYYY-
MM-DD') as ymd_jst,
date_part('hour', to_timestamp((item->>'timestamp')::bigint +
3600*9))::integer as h_jst,
hll_agg((item->>'uuid')::text) as uuid_agg,
FROM test_stream
GROUP BY
ymd_jst, h_jst;
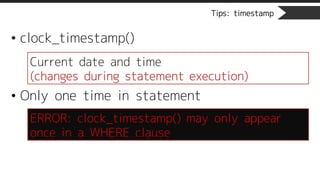
Tips: timestamp
• clock_timestamp()
•Only one time in statement
Current date and time
(changes during statement execution)
ERROR: clock_timestamp() may only appear
once in a WHERE clause






































































![[Livesence Tech Night] グリーにおけるHiveの運用](https://cdn.slidesharecdn.com/ss_thumbnails/livesencetechnight-150602053505-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






