AWS – ElasticMapReduce
Hadoop ja Amazon Web Sercvices
2.
Mikä on ElasticMapReduce
Web-palvelu, joka mahdollistaa suurten datamäärien
tehokkaan käsittelyn
Käyttää Hadoop-ohjelmistoympäristöä (software framework)
Tarkoitettu yrityksille, tutkijoille ja sovelluskehittäjille
analyysien suorittamiseen
Soveltuu mm.:
Analyyseihin
Tutkimukseen
Simulointiin
Tiedonlouhintaan
3.
Mikä on Hadoop?
Hadoop on avoimen lähdekoodin
ohjelmistoympäristö, joka on valmiiksi
asennettuna Elastic MapReducen käyttäjille
Hadoop on käytössä lukuisissa suuryrityksissä
kuten eBay, IBM ja Yahoo!
4.
Mitä Hadoop tekee?
Hadoop jakaa käsiteltävän datan osiin, joka
puolestaan jaetaan EC2-instanssien
(virtuaalipalvelimia) käsiteltäväksi
Hadoop kokoaa käsitellyn datan taas yhteen ja
yhdistää ne lopputulokseksi
Hadoop huolehtii instanssien välisestä
kommunikaatiosta ja valvoo niiden toimintaa
Hadoopin käyttämää hajautetun laskennan
toimintamallia kutsutaan nimellä MapReduce
5.
Mitä on MapReduce?
Käsiteltävä data jaetaan siis osiin ja osat
jaetaan AWS:n tapauksessa EC2-instansseille
(slave-instansseille, joita master-instanssi
valvoo)
Jaetun datan mukana instanssit saavat
käsittelyohjeet
Käsiteltyään datan Hadoop yhdistää slave-
instanssien laskennan tulokset
6.
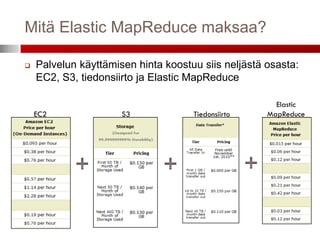
Mitä Elastic MapReducemaksaa?
Hinnat riippuvat käytettyjen instanssien
(virtuaalipalvelin) koosta ja käyttöalueesta (Aasia,
Yhdysvallat vai EU)
7.
Mitä Elastic MapReducemaksaa?
Palvelun käyttämisen hinta koostuu siis neljästä osasta:
EC2, S3, tiedonsiirto ja Elastic MapReduce
Elastic
EC2 S3 Tiedonsiirto MapReduce
8.
Osaamisvaatimukset
sovelluskehittäjälle
XML (extender markup language)
Ymmärrys web-palveluiden perusteista
Ohjelmointiosaaminen tarvittavien
komentojen (mapper, reducer) antamiseksi
Elastic MapReduce-palvelulle ja tulosten
hyödyntämiseksi
Käytössä myös Hive (versio 0.5) ja Pig (versio 0.6),
jotka mahdollistavat Hadoopin käytön SQL-tyyppisin
komennoin ilman tarvetta MapReduce-algoritmejä
esim. Javalla
9.
Käsiteltävän datan enimmäismäärä
Ilman yhteydenottoa Amazonin
(myynti)edustajaan voi ottaa käyttöön 20
instanssia
Käsiteltävän datan enimmäismäärä on 34
teratavua (34 TB)
20 ”extra large”-instanssia, joissa 1.69 teratavua
kovalevytilaa kussakin. Elastic MapReduce
käyttää instanssien kovalevytilaa datan
säilyttämiseen prosessoinnin aikana
10.
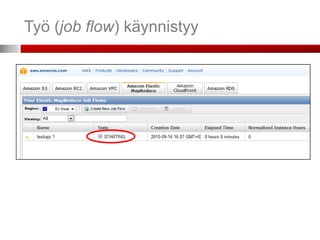
Elastic MapReducen käyttäminen
Kolme vaihtoehtoista tapaa: konsoli
(hallintapaneeli), komentorivi (command line
interface, CLI) ja API (ohjelmointirajapinta)
Konsoli helpoin ja suppein
API vaikein ja monipuolisin
Komentorivi (CLI, command line interface)
vaatii Rubyn asennettuna toimiakseen
11.
Tietoturva (data security)
Ainoastaan AWS-tilin omistaja pääsee käsiksi
Elastic MapReducen S3-palveluun tallentamiin
tietoihin, ellei toisin määritetä
S3-palveluun tiedot ladataan HTTPS-protokollalla
Elastic MapReduce käyttää HTTPS-protokollaa
siirtäessään tietoja S3:n ja EC2:n välillä
Tiedot voi myös siirtää S3-palveluun salattuina
(crypted), kunhan Elastic MapReduce-ajossa
huolehditaan salauksen purusta ennen datan
käsittelyä (ylimääräinen työvaihe ennen data
käsittelyä)
12.
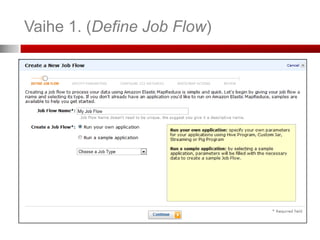
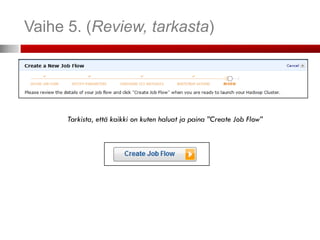
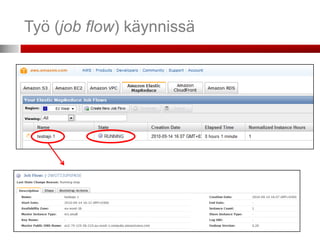
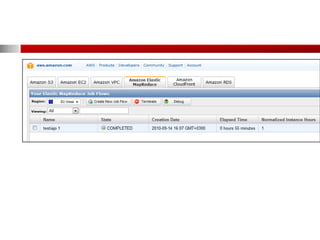
Toimintamalli vaiheittain
1. Lataa data ja ohjaustiedostot (mapper, reducer
executable:t) S3-palveluun ja pyydä Elastic
MapReducea (EMR) aloittamaan työ
2. EMR käynnistää EC2-klusterin, joka lataa ja ajaa
Hadoopin
3. Hadoop tekee työn lataamalla datan S3:sta EC2-
klusterilla. Dataa voidaan myös ladata
dynaamisesti.
4. Hadoop käsittelee datan ja tallentaa tulokset
klusterista S3:en
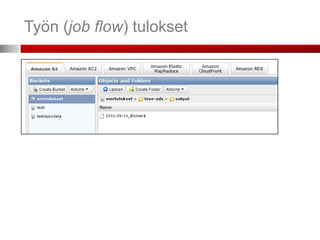
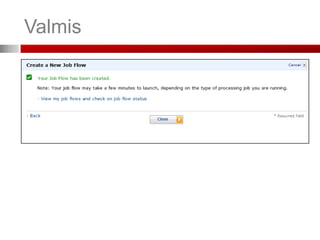
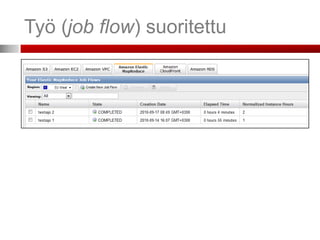
5. Työ on valmis ja tulokset ladattavissa S3-sta
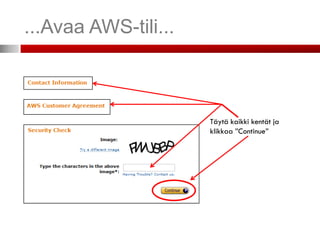
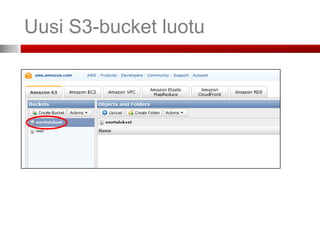
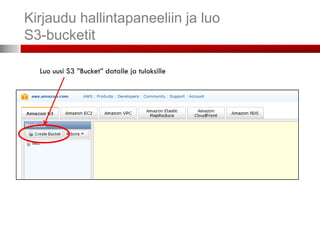
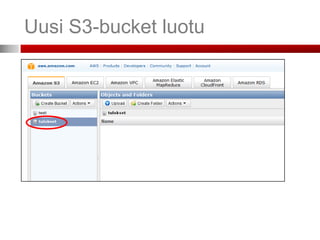
...Avaa AWS-tili...
• Kunolet kirjautunut sisään, etusivulla aws.amazon.com mene
hallintapaneeliin (management console)
• Päästäksesi käyttämään palveluita (EC2, S3 jne.) täytyy sinun antaa
myös maksutietosi
• Palvelut maksetaan luottokortilla, maksutiedot ovat luottokortin numero,
voimassaoloaika ja turvaluku
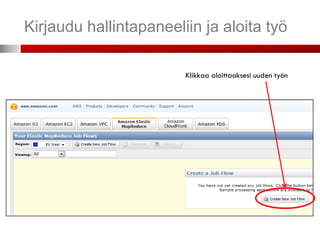
19.
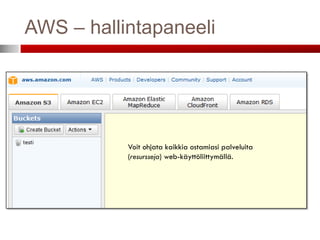
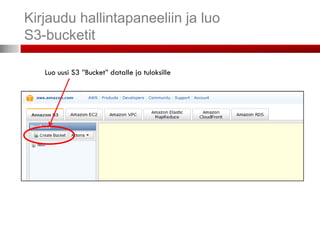
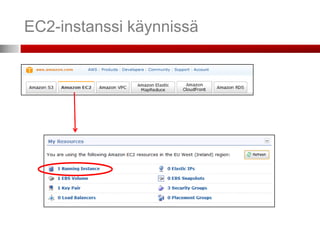
AWS – hallintapaneeli
Voit ohjata kaikkia ostamiasi palveluita
(resursseja) web-käyttöliittymällä.
20.
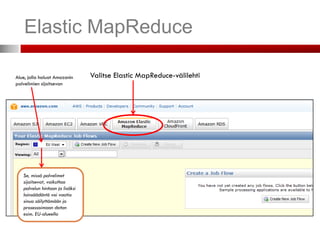
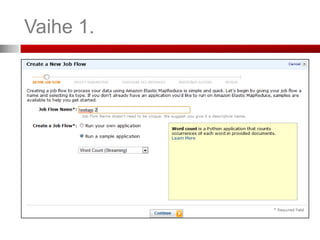
Elastic MapReduce
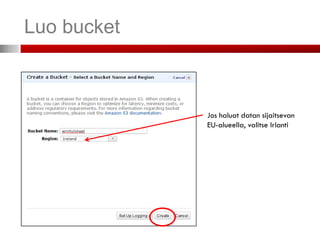
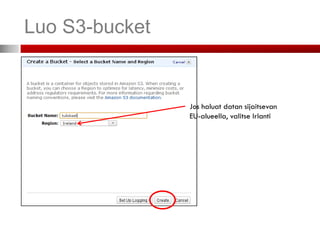
Alue, jollahaluat Amazonin Valitse Elastic MapReduce-välilehti
palvelimien sijaitsevan
Se, missä palvelimet
sijaitsevat, vaikuttaa
palvelun hintaan ja lisäksi
lainsäädäntö voi vaatia
sinua säilyttämään ja
prosessoimaan datan
esim. EU-alueella
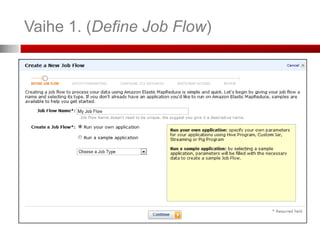
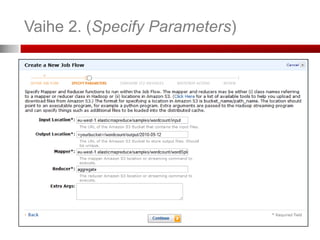
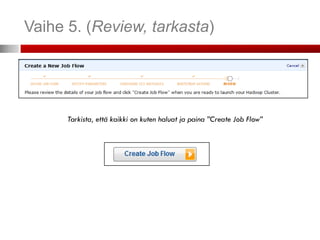
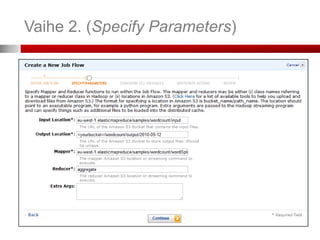
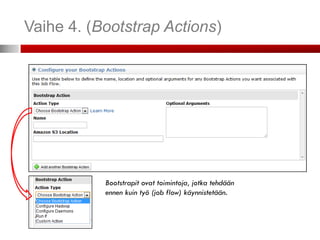
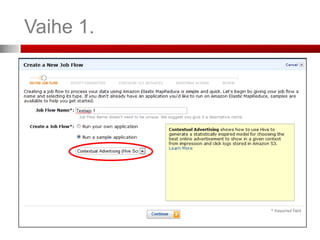
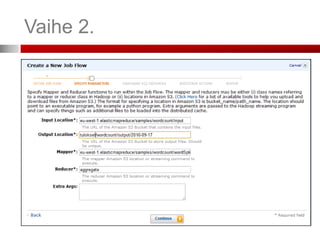
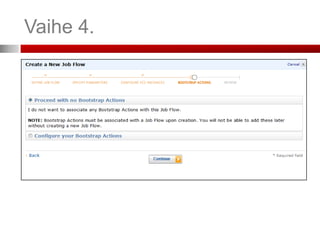
Vaihe 2. (SpecifyParameters)
Mistä tieto haetaan (S3 bucket)
Mihin tulokset ladataan (S3 bucket)
Mistä Mapper ladataan (S3 bucket)
Mistä Reducer ladataan (S3 bucket)
Lisäargumentit työlle (job)
Voit lisätä tiedostoja tai kirjastoja Mapper:n
tai Reducer:n käyttöön
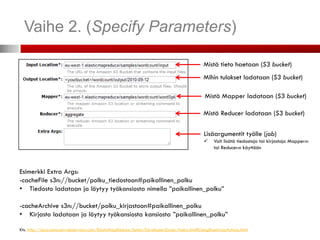
Esimerkki Extra Args:
-cacheFile s3n://bucket/polku_tiedostoon#paikallinen_polku
• Tiedosto ladataan ja löytyy työkansiosta nimella ”paikallinen_polku”
-cacheArchive s3n://bucket/polku_kirjastoon#paikallinen_polku
• Kirjasto ladataan ja löytyy työkansiosta kansiosta ”paikallinen_polku”
Kts. http://docs.amazonwebservices.com/ElasticMapReduce/latest/DeveloperGuide/index.html?UsingBootstrapActions.html
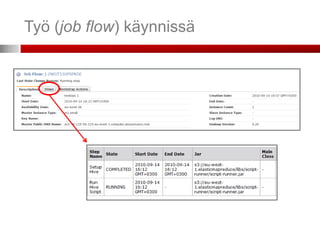
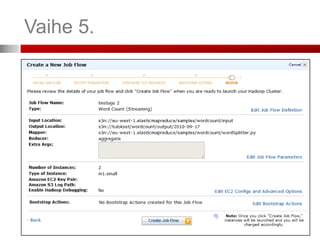
Instanssien määrä jalaatu
Oletuksena instanssien maksimimäärä on 20
Jos tarvitset enemmän, voi lisäinstansseja pyytää Amazonilta web-lomakkeella
Instansseista yksi on master- ja muut slave-instansseja
Jos käytössä vain yksi instanssi, se on molempia
Master-instanssi jakaa ja valvoo työtä, slave-instanssit
suorittavat sen
Käyttäjä voi ottaa suoran yhteyden ainoastaan master-
instanssiin
Tarkastellakseen esim. Hadoopin loki-tiedostoja (log files) tai Hadoopin tarjoamaa
käyttöliittymää
34.
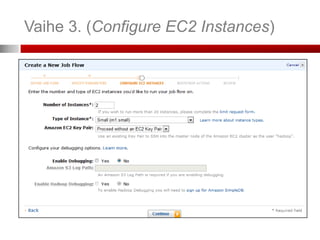
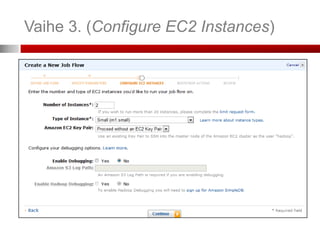
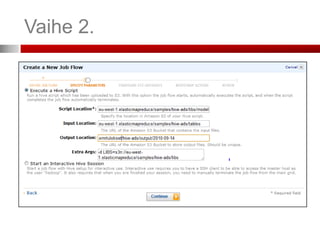
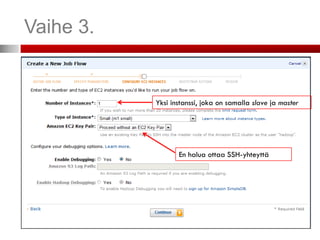
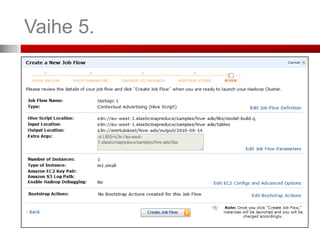
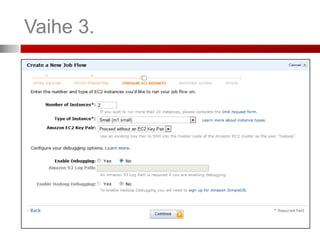
Vaihe 3. (ConfigureEC2 Instances)
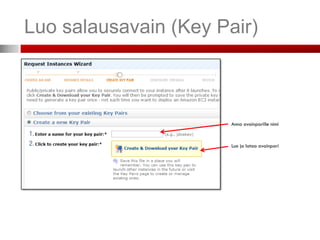
Jos haluat ottaa SSH-salatun yhteyden slave-instanssiin, valitse
avainpari (Key Pair). Jos et ole luonut sellaista, kts. seuraava dia.
36.
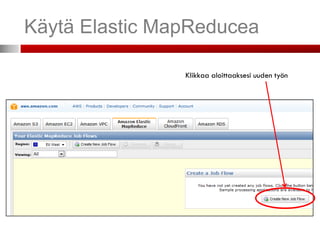
AWS – hallintapaneeli
Voit ohjata kaikkia ostamiasi palveluita
(resursseja) web-käyttöliittymällä.
Vaihe 3. (ConfigureEC2 Instances)
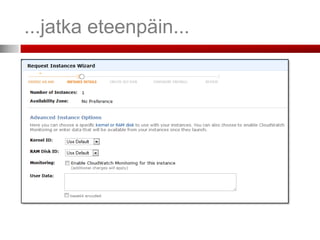
Valitse intanssi-tyyppi ja instanssien lukumäärä
Instanssityyppejä – tehokkaammat
ovat kalliimpia
45.
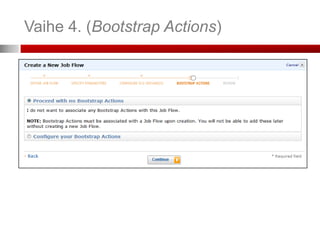
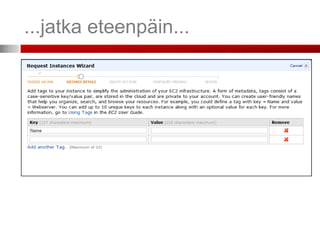
Vaihe 3. (ConfigureEC2 Instances)
S3-kori (bucket), johon yleiset virhetiedot
(debugging) tallennetaan
Jos valitset tämän, tarvitsen
SimpleDB-tilit tietojen
tallentamiseen
(SimpleDB:tä ei käsitellä tässä)