Download to read offline



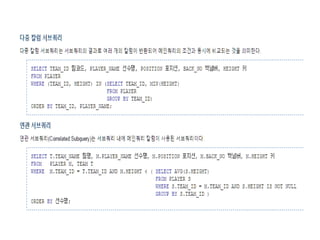







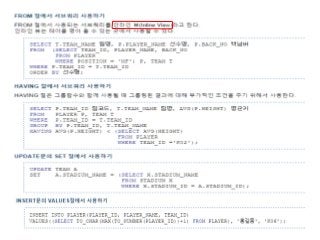








[캐글뽀개기] 캐툴즈툴(주말) 스터디 : 파트 1 - 8회차 (SQL) 9. 서브 쿼리: 쿼리 안의 쿼리 & 10. 외부 조인, 셀프 조인, 유니온: 새로운 조작법 Tae Young Lee 제가 금일 발표할 내역은 왜 서브 쿼리와 조인을 사용하는가?에 대해 생각해 보고 Query의 관점에서 서브 쿼리와 조인을 바라보기 위한 기초 지식들에 대해 살펴보겠습니다. 예를 들자면, Block I/O비용이라든지 Indexing관련 기반 지식과 Oracle Database구조도 설명을 통해 Query의 동작 방식에 대해 간략히 알아보겠습니다. 그 후 서브쿼리와 조인의 활용법에 대해 알아보는 시간을 갖도록 하겠습니다. 제가 이렇게 금일 세미나를 준비한 이유는 대부분의 사람들은 쿼리를 만들어 날려 자기가 원하는 데이터를 뽑아 쓸 수는 있어도 그 쿼리가 실제적으로 사용되는 화면단이라든지 DB부하와 서버 부하 이런 상식에 대해선 무지한 경우가 많이 결국 사용자 불편을 초래하는 경우가 많기 때문입니다. 그래서 금일 세미나를 통해 Query와 사용자 그리고 시스템 관점에서 바라볼 수 있는 기회를 제공하고자 준비해 보았습니다.
![[Pgday.Seoul 2017] 5. 테드폴허브(올챙이) PostgreSQL 확장하기 - 조현종](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql-171106044405-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[제3회 스포카콘] SQL 쿼리 최적화 맛보기](https://cdn.slidesharecdn.com/ss_thumbnails/spoqacon2021keynotejhuni-210222015014-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Pgday.Seoul 2020] SQL Tuning](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-201117134901-thumbnail.jpg?width=640&height=640&fit=bounds)






![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Foss4 g2013 korea]postgis와 geoserver를 이용한 대용량 공간데이터 기반 일기도 서비스 구축 사례](https://cdn.slidesharecdn.com/ss_thumbnails/foss4g2013koreapostgisgeoserver-140325221011-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















