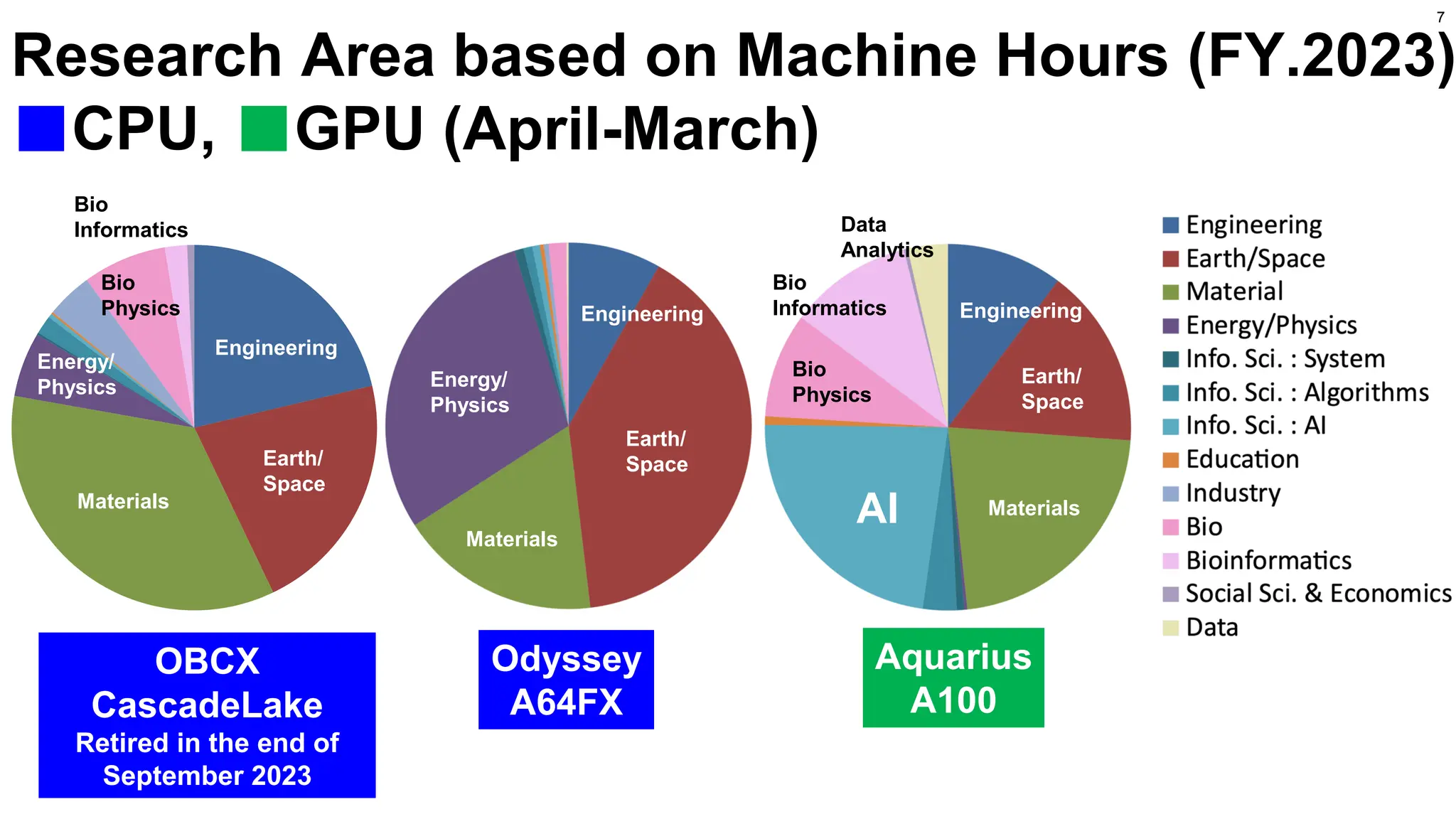
Engineering
Earth/Space
Material
Energy/Physics
Info. Sci. :System
Info. Sci. : Algorithms
Info. Sci. : AI
Education
Industry
Bio
Bioinformatics
Social Sci. & Economics
Data
Research Area based on Machine Hours (FY.2023)
■CPU, ■GPU (April-March)
7
Engineering
Earth/
Space
Materials
Energy/
Physics
Bio
Physics
Energy/
Physics
Earth/
Space
Bio
Informatics
Engineering
Materials
AI
Bio
Informatics
Data
Analytics
Bio
Physics
Materials
OBCX
CascadeLake
Retired in the end of
September 2023
Odyssey
A64FX
Aquarius
A100
Earth/
Space
Engineering
17
API of h3-Open-SYS/WaitIO-Socket/-File
PB(Parallel Block): Each Application
WaitIO API Description
waitio_isend Non-Blocking Send
waitio_irecv Non-Blocking Receive
waitio_wait Termination of waitio_isend/irecv
waitio_init Initialization of WaitIO
waitio_get_nprocs Process # for each PB (Parallel Block)
waitio_create_group
waitio_create_group_wranks
Creating communication groups
among PB’s
waitio_group_rank Rank ID in the Group
waitio_group_size Size of Each Group
waitio_pb_size Size of the Entire PB
waitio_pb_rank Rank ID of the Entire PB
[Sumimoto et al. 2021]
18.
Replacing
this part
with AI
Motivation of this experiment
Tow types of Atmospheric models: Cloud resolving VS Cloud
parameterizing
Could resolving model is difficult to use for climate simulation
Parameterized model has many assumptions
Replacing low-resolution cloud processes calculation with ML!
Diagram of applying ML to an atmospheric model
High Resolution Atmospheric Model
(Convection-Resolving Mode)
Low Resolution Atmospheric Model
(Convection-Parameterization Mode)
Physical process
Input
Output
Coupling with
Grid Remapping
ML App
(Python)
Coupling without
Grid Remapping
Coupling Phase 1
Training with high-resolution
NICAM data
Coupling Phase 2
Replacing Physical Process
in Low-Resolution NICAM
with Machine Learning
Atmosphere-ML Coupling
[Yashiro (NIES), Arakawa (ClimTech/U.Tokyo)]
75% 25%
Odyssey Aquarius
h3-Open-UTIL/MP
(Coupler)
+
h3-Open-SYS/WaitIO-
Socket
~0%
19.
Experimental Design
Atmosphericmodel on Odyssey
NICAM : global non-hydrostatic model with an icosahedral grid
Resolution : horizontal : 10240, vertical : 78
ML on Aquarius
Framework : PyTorch
Method : Three-Layer MLP
Resolution : horizontal : 10240, vertical : 78
Experimental design
Phase1: PyTorch is trained to reproduce output variables from
input variables of cloud physics subroutine.
Phase2:Reproduce the output variables from Input variables
and training results
Training data
Input : total air density (rho), internal energy (ein), density of
water vapor (rho_q)
Output : tendencies of input variables computed within the
cloud physics subroutine
Atmospheric Model
(Convection-Scheme ON)
Cloud physics
subroutine
Input
Output
ML App
(Python)
Output
Phase1: Training phase Phase2: Test phase
Simulation Node
Odyssey
Data/Learning Node
Aquarius
Δ𝑟ℎ𝑜
Δ𝑇
Δ𝑒𝑖𝑛
Δ𝑇
Δ𝑟ℎ𝑜_𝑞
Δ𝑇
20.
Test calculation
Total airdensity
Internal energy
Density of
water vapor
Input Simulation Output
Compute output variables from input variables and PyTorch
The rough distribution of all variables is well reproduced
The reproduction of extreme values is no good
ML output
Simulations Prediction by ML/NN
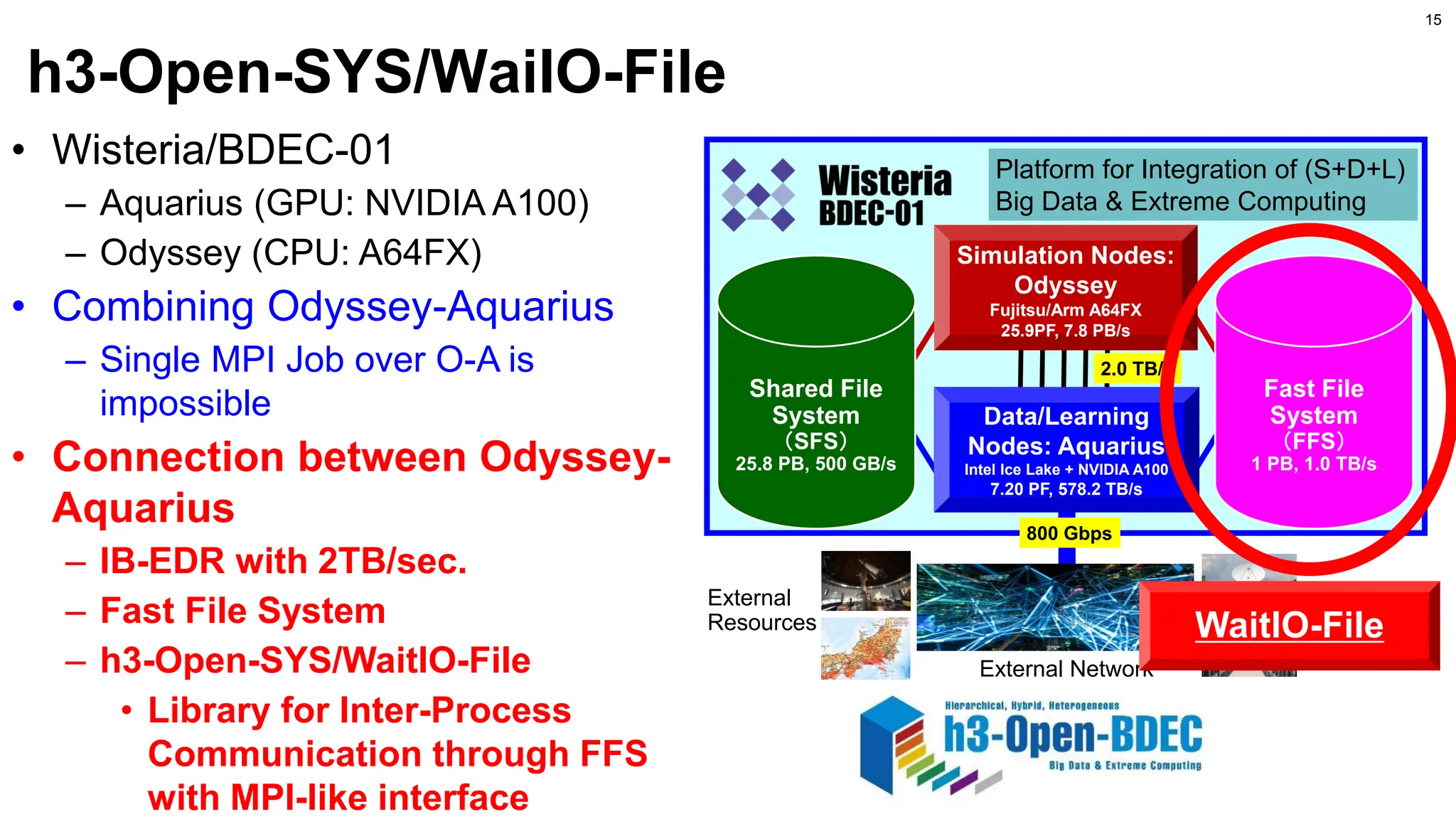
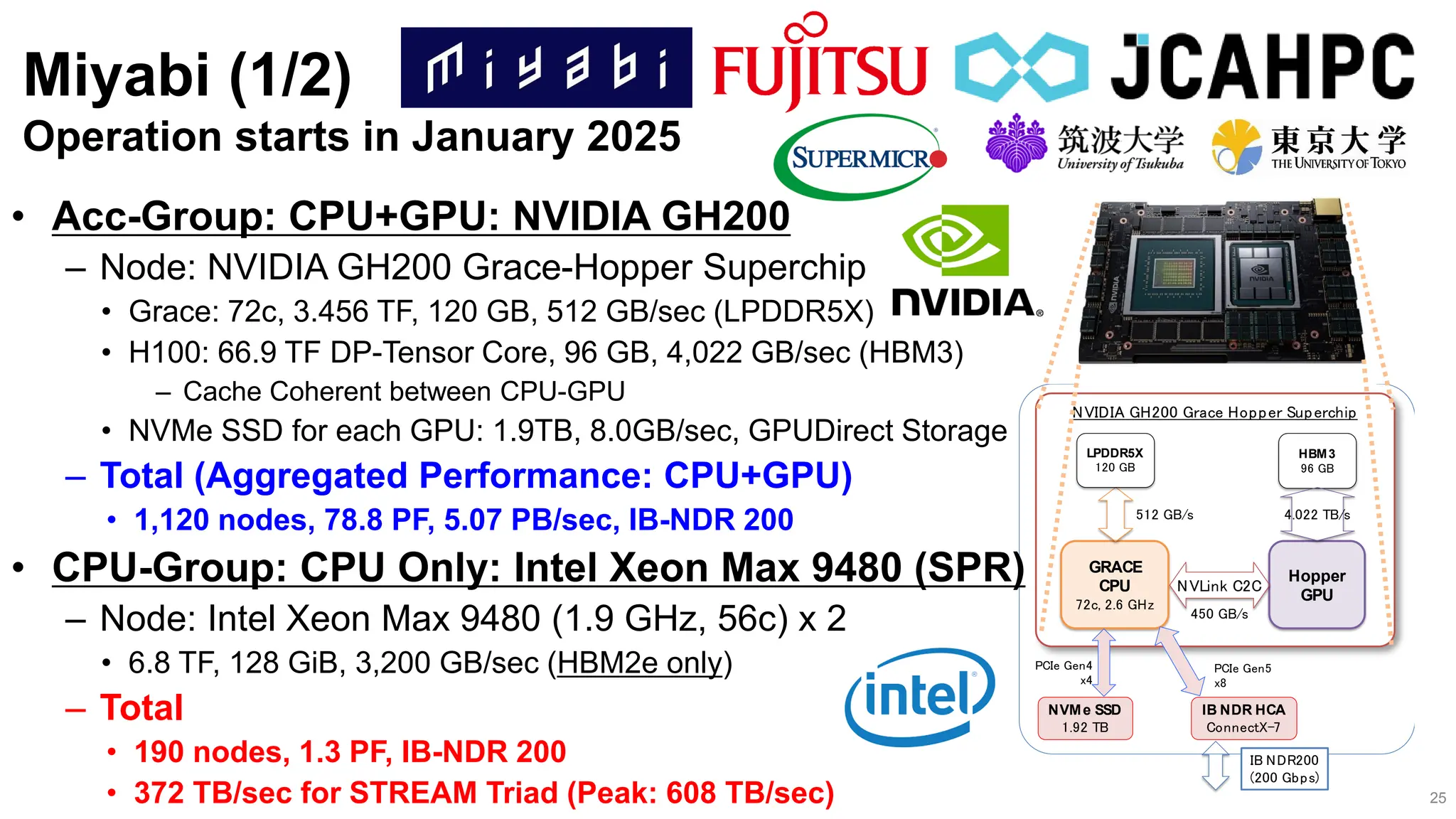
• File System:DDN EXA Scalar, Lustre FS
– 11.3 PB (NVMe SSD) 1.0TB/sec, “Ipomoea-01” with 26 PB is also available
• All nodes are connected with Full Bisection Bandwidth
– (400Gbps/8)×(32×20+16×1) = 32.8 TB/sec
• Operation starts in January 2025, h3-Open-SYS/WaitoIO will be
adopted for communication between Acc-Group and CPU-Group
Miyabi (2/2)
Operation starts in January 2025
26
IB-NDR(400Gbps)
IB-NDR200(200) IB-HDR(200)
File System
DDN EXA Scaler
11.3 PB, 1.0TB/sec
CPU-Group
Intel Xeon Max
(HBM2e) 2 x 190
1.3 PF, 608 TB/sec
Acc-Group
NVIDIA GH200 1,120
78.2 PF, 5.07 PB/sec
Ipomoea-01
Common Shared Storage
26 PB
Detailed Plan forPorting
• Strong supports by NVIDIA, Japan
• 3,000+ OFP users: Two categories of support
• Self Porting: Various Options
– 1-week Hackathon (online/hybrid): Every 3-months, utliziing Slack for comm.
– Monthly Open Meeting for Consultation via Zoom (Non-users can join)
– Portal Site for Useful Information (in Japanese)
• https://jcahpc.github.io/gpu_porting/
• Surpported Porting
– Community Codes with Many Users (17, next page) + OpenFOAM (by NVIDIA)
– Budget for Outsourcing
– Started in October 2022: Meetings every 3-4 months
– Many members of “Supported Porting” groups are joining Hackathons.
• Mostly, our users’ codes are parallelized by MPI+OpenMP
– OpenACC is recommended 29
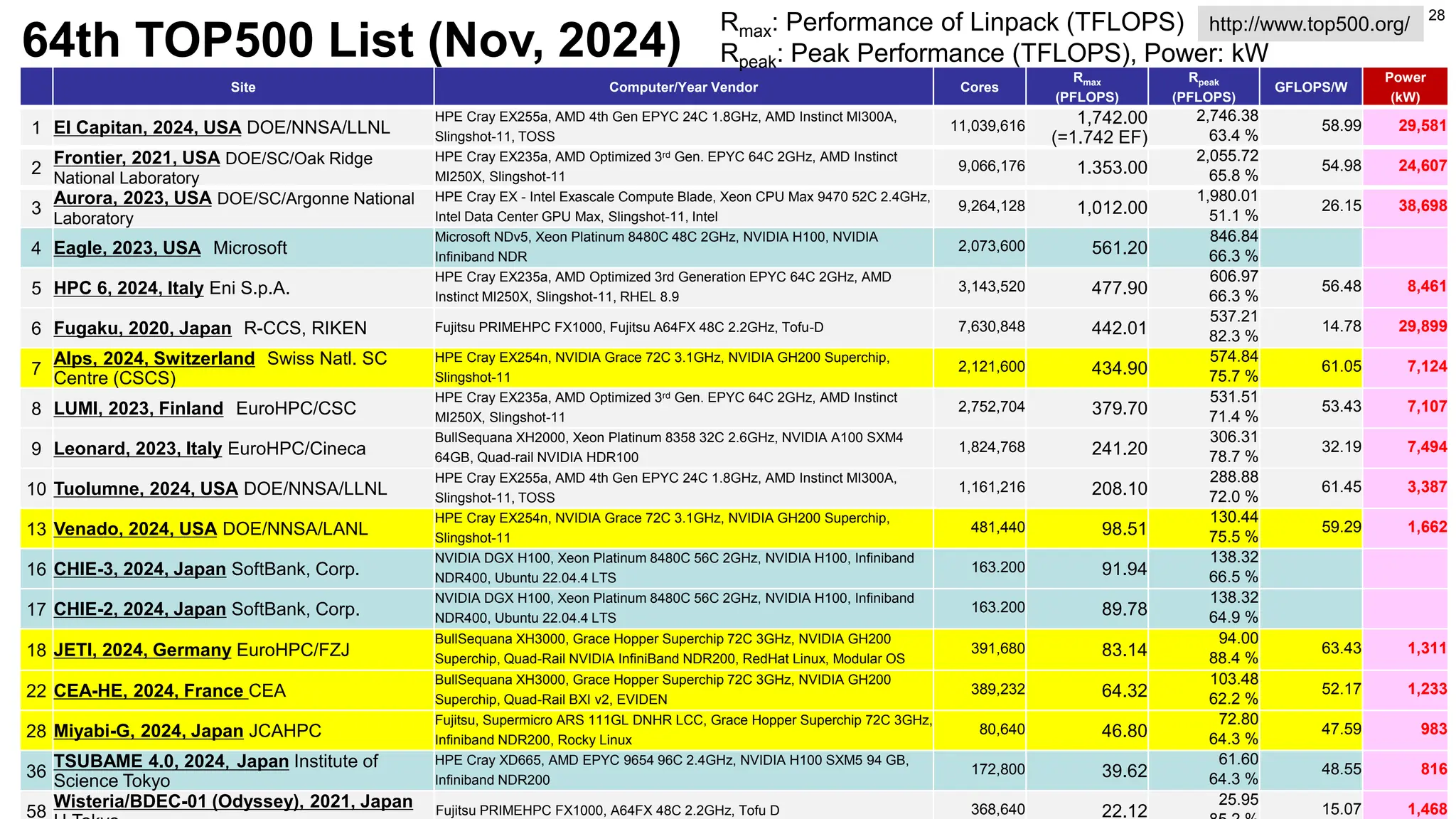
30.
30
Category Name (Organizations)Target, Method etc. Language
Engineering
(5)
FrontISTR (U.Tokyo) Solid Mechanics, FEM Fortran
FrontFlow/blue (FFB) (U.Tokyo) CFD, FEM Fortran
FrontFlow/red (AFFr) (Advanced Soft) CFD, FVM Fortran
FFX (U.Tokyo) CFD, Lattice Boltzmann Method (LBM) Fortran
CUBE (Kobe U./RIKEN) CFD, Hierarchical Cartesian Grid Fortran
Biophysics
(3)
ABINIT-MP (Rikkyo U.) Drug Discovery etc., FMO Fortran
UT-Heart (UT Heart, U.Tokyo) Heart Simulation, FEM etc. Fortran, C
Lynx (Simula, U.Tokyo) Cardiac Electrophysiology, FVM C
Physics
(3)
MUTSU/iHallMHD3D (NIFS) Turbulent MHD, FFT Fortran
Nucl_TDDFT (Tokyo Tech) Nuclear Physics, Time Dependent DFT Fortran
Athena++ (Tohoku U. etc.) Astrophysics/MHD, FVM/AMR C++
Climate/
Weather/
Ocean
(4)
SCALE (RIKEN) Climate/Weather, FVM Fortran
NICAM (U.Tokyo, RIKEN, NIES) Global Climate, FVM Fortran
MIROC-GCM (AORI/U.Tokyo) Atmospheric Science, FFT etc. Fortran77
Kinaco (AORI/U.Tokyo) Ocean Science, FDM Fortran
Earthquake
(4)
OpenSWPC (ERI/U.Tokyo) Earthquake Wave Propagation, FDM Fortran
SPECFEM3D (Kyoto U.) Earthquake Simulations, Spectral FEM Fortran
hbi_hacapk (JAMSTEC, U.Tokyo) Earthquake Simulations, H-Matrix Fortran
sse_3d (NIED) Earthquake Science, BEM (CUDA Fortran) Fortran
QC-HPC Hybrid Computing
•JHPC-quantum (FY.2023-FY.2028)
– https://jhpc-quantum.org/
– RIKEN, Softbank, U.Tokyo, Osaka U.
• supported by Japanese Government (METI/NEDO)
– Two Real Quantum Computers will be installed
• IBM’s Superconducting QC at RIKEN-Kobe (100+Qubit)
• Quantinuum’s Ion-Trap QC at RIKEN-Wako (20+Qubit)
– Target Applications
• Quantum Sciences, Quantum Machine Learning etc.
33
A64FX
Arm
X86
NVIDIA
Intel
AMD
Arm
AMD Intel
Sambanova
Cerebras
Graphcore
etc.
Quantum
h3-Open-SYS/WaitIO
CPU GPU Others
• Role of U.Tokyo
– R&D on System SW for QC-HPC Hybrid Environment (QC as Accelerators)
• Extension of h3-Open-BDEC
• Fugaku & Miyabi will be connected to QCs in March 2026 (or before)
34.
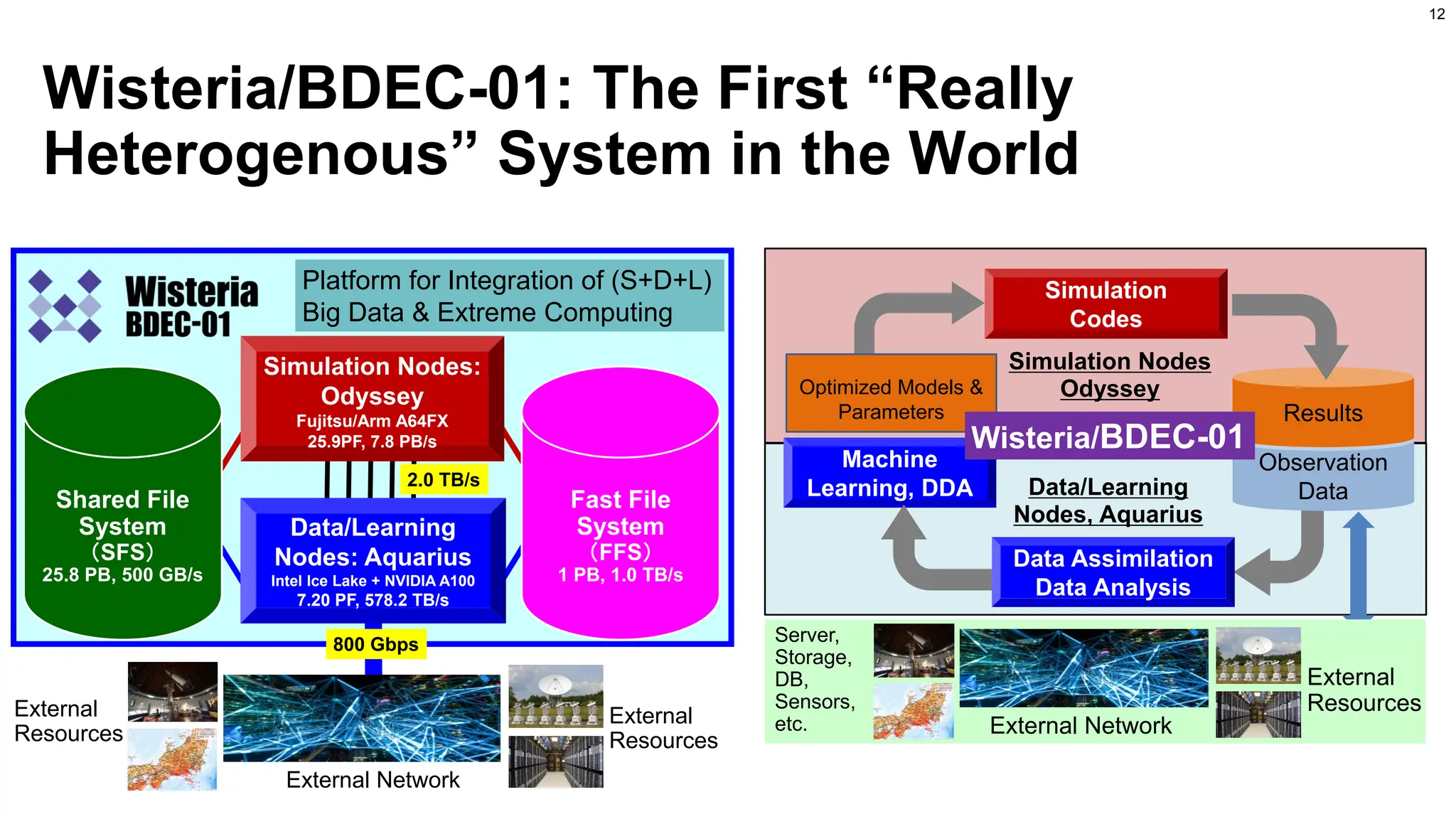
Wisteria/BDEC-01 with Odyssey-Aquarius
Simulatorof (QC-HPC) Hybrid Environment
34
Fast File
System
(FFS)
1 PB, 1.0 TB/s
External
Resources
External Network
Simulation Nodes:
Odyssey
Fujitsu/Arm A64FX
25.9PF, 7.8 PB/s
2.0 TB/s
800 Gbps
Shared File
System
(SFS)
25.8 PB, 500 GB/s
Data/Learning
Nodes: Aquarius
Intel Ice Lake + NVIDIA A100
7.20 PF, 578.2 TB/s
External
Resources
Platform for Integration of (S+D+L)
Big Data & Extreme Computing
35.
• Quantum Computer= Accelerator of Supercomputers: QC-HPC Hybrid
• System SW for Efficient & Smooth Operation of QC (Quantum Computer,
including simulators on supercomputers)-HPC Hybrid Environment
– QHscheduler: A job scheduler that can simultaneously use multiple computer
resources distributed in remote locations
– h3-Open-BDEC/QH: Coupling to efficiently implement and integrate communication
and data transfer between QC-HPC on-line and in real time
– Collaboration with RIKEN R-CCS, funded by Japanese Government
• Target Application
– AI for HPC, combined workload
• Simulations in Computational Science
• Quantum Machine Learning
– Quantum Simulations, Error Correction
System SW for QC-HPC Hybrid Environment (1/2)
35
HPC
(1)
HPC
(2)
HPC
(3)
QC
(a)
QC
(b)
QC
On
HPC
QHscheduler
h3-Open-BDEC/QH
36.
• Innovations
– Thisis the world's first attempt
to link multiple
supercomputers and quantum
computers installed at
different sites in real time.
– In particular, by using multiple
QCs simultaneously, it is
possible to form a virtual QC
with higher processing
capacity.
• Many people are thinking about
same thing all over the world
– This idea can be extended to
any types of systems
System SW for QC-HPC Hybrid Environment (2/2)
36
HPC
(1)
HPC
(2)
HPC
(3)
QC
(a)
QC
(b)
QC
On
HPC
QHscheduler
h3-Open-BDEC/QH
AI
37.
• CUDA-Q hasbeen already installed to Aquarius
• QC-HPC Hybrid Environment is now under
construction using h3-Open-BDEC
• 1-Day Tutorial on December 18 (Wed)
– Let's experience "Quantum/HPC Hybrid" with "CUDA-
Q+Wisteria/BDEC-01+h3-Open-BDEC"!
– World’s 1st Tutorial on “QC-HPC” with hands-on
• VQE (Variational Quantum Eigensolver): Toy
Wisteria/BDEC-01 with Odyssey-Aquarius
Simulator of (QC-HPC) Hybrid Environment
37
mdx I &II: Current Systems
• IaaS-based High-Performance Academic Cloud
• mdx I @ UTokyo (2023 April ~ now)
• VM hosting (on 368 CPU Nodes + 40 GPU Nodes Cluster)
• Peta-Scale Storage (Lustre + s3, around 25PB in total)
• Global IPs for web service
• mdx II @ OsakaU (2025)
• 60 CPU nodes + 1PB Storage (+ GPU Nodes under preparation)
• https://mdx.jp
• Targeting Data Science and Cross-Disciplinary Research
• Around 120 research projects undergoing (2023 April ~ now):
Computer Science, LLM, ML, Social Science, Life Science, Physics, Chemistry,
Materials Science, etc.
• Not only on traditional HPC workload but also on Data collection, Web service, etc.
• Example
• ARIM-mdx Data System:
Nextcloud + Jupyter Service for materials science
• Data collection / analysis from experimental facilities & HPCs
• https://arim.mdx.jp/
39
40.
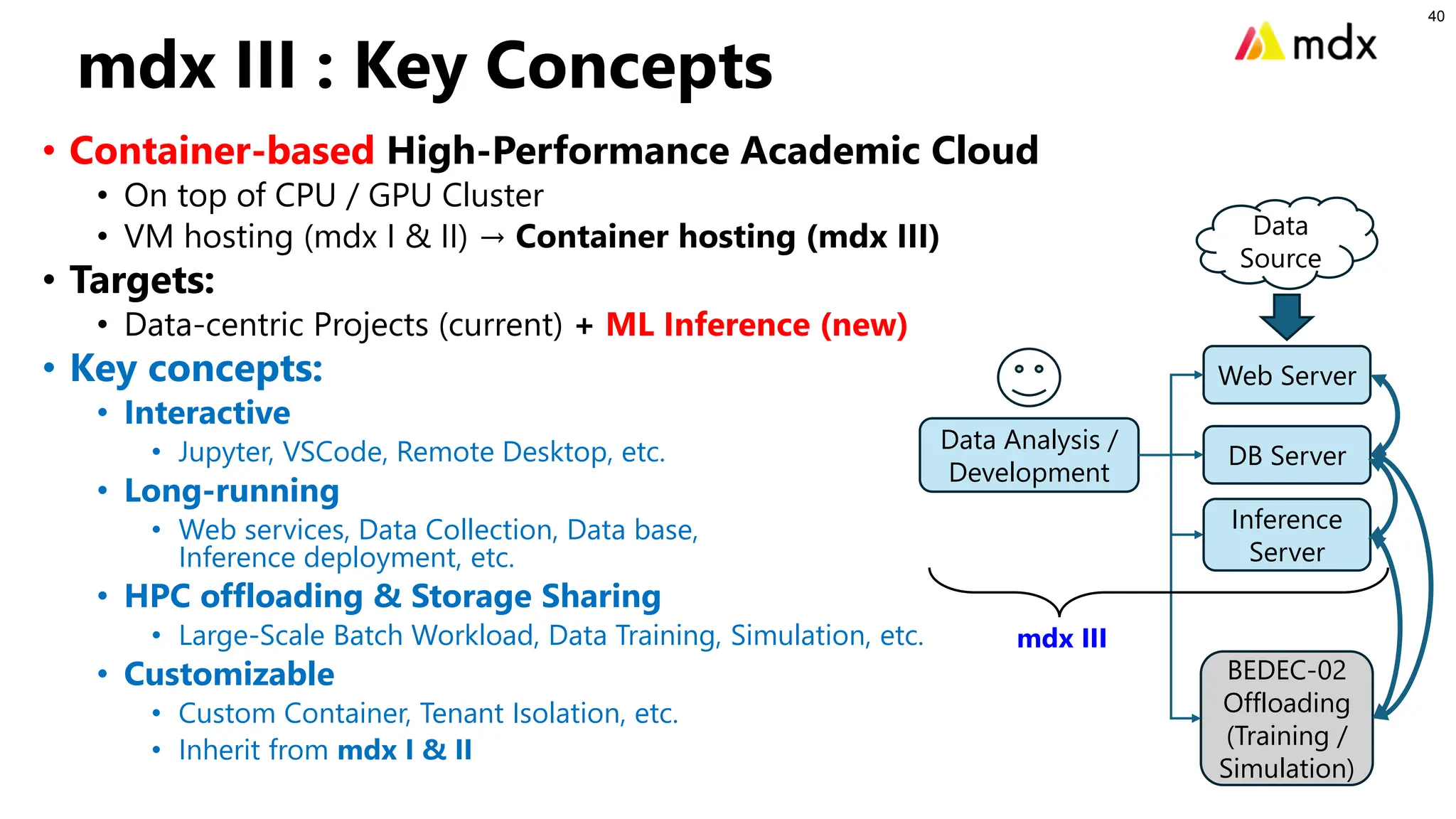
mdx III :Key Concepts
• Container-based High-Performance Academic Cloud
• On top of CPU / GPU Cluster
• VM hosting (mdx I & II) → Container hosting (mdx III)
• Targets:
• Data-centric Projects (current) + ML Inference (new)
• Key concepts:
• Interactive
• Jupyter, VSCode, Remote Desktop, etc.
• Long-running
• Web services, Data Collection, Data base,
Inference deployment, etc.
• HPC offloading & Storage Sharing
• Large-Scale Batch Workload, Data Training, Simulation, etc.
• Customizable
• Custom Container, Tenant Isolation, etc.
• Inherit from mdx I & II
40
Data Analysis /
Development
Web Server
DB Server
Inference
Server
Data
Source
BEDEC-02
Offloading
(Training /
Simulation)
mdx III
41.
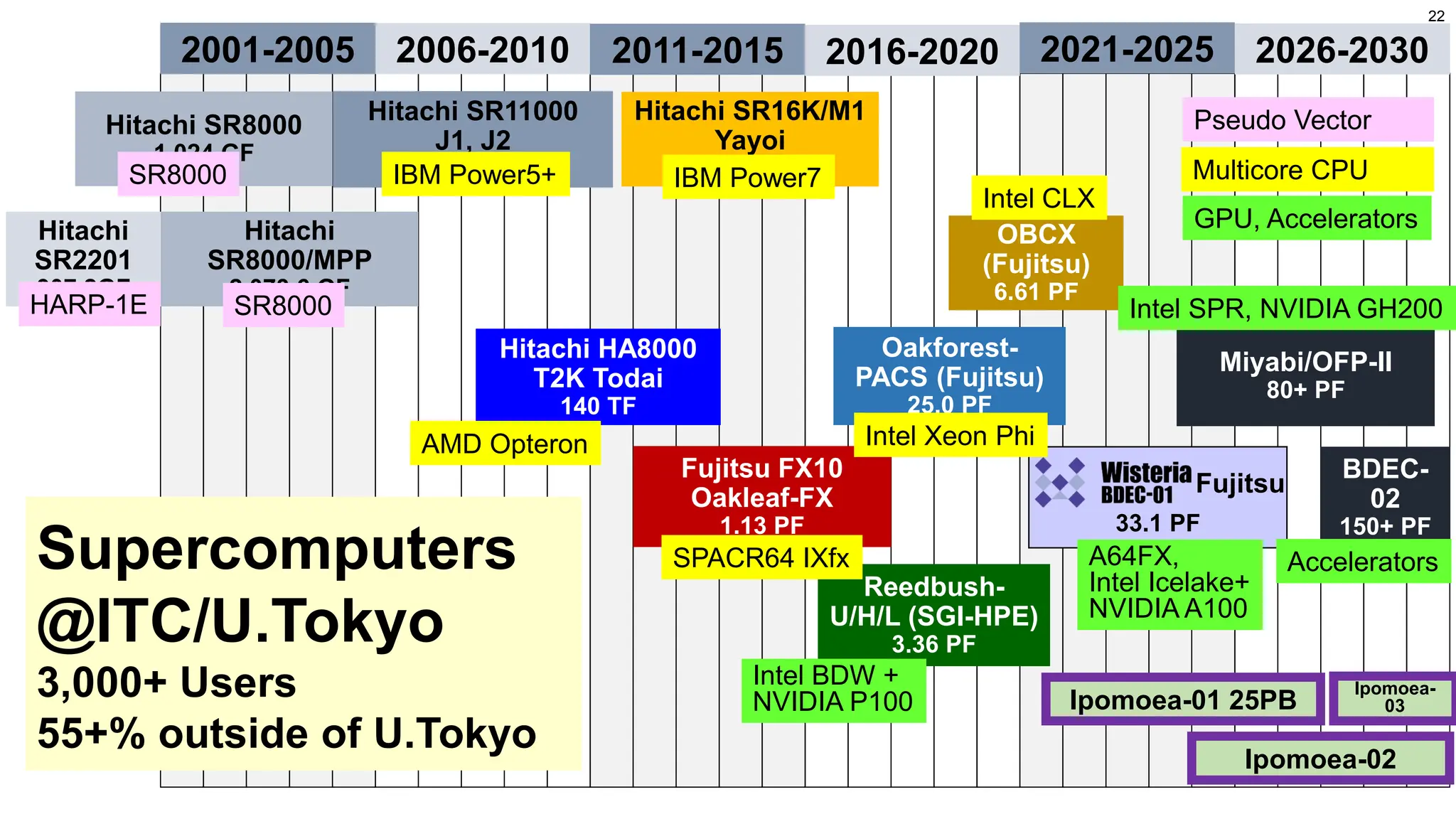
BDEC-02: 2nd Systemof the BDEC Project
• Operation starts in Fall 2027- Spring 2028, hopefully
• Wisteria/BDEC-01 retires at the end of April 2027
• University of Tokyo’s System with 200-250 PF (150 PF is realistic)
• HPL performance is not a big issue
• “Real-Time” Integration of (S+D+L) towards “AI for Science”
• NVIDIA’s GPUs, or ones based on compatible programming
environments with OpenACC/StdPar
• Fortran is still very important
• Connection to Special Devices/Systems
• Quantum Computers etc.
• h3-Open-BDEC, h3-Open-BDEC/QH
• Integration with mdx-Next (mdx3)
• Cloud-like Data Platform
• (at least) (part of) storage to be shared
41
42.
Internet
BDEC-02+mdx3 Concept
• Theconcept of the BDEC-02/mdx3 is to save costs by sharing computer
resources as much as possible and avoiding redundant configurations.
• Currently, Wisteria/BDEC-01 and mdx are separate systems in the same room
42
Wisteria/BDEC-01
Odyssey
Aquarius
mdx
Router
Node
Router
Internet
Wisteria/BDEC-02
Node A
Node B
mdx3
Node
Router
Ipomoea-01
(Ipomoea-02)










![h3-Open-UTIL/MP (h3o-U/MP)
(HPC+AI) Coupling
[Dr. H. Yashiro, NIES]
13
h3o-U/MP
HPC App
(Fortran)
Analysis/ML
App
(Python)
h3o-U/MP
F<->P adapter
Coupling
Surrogate
Model
Visualiztion
Statistics
A huge amount of
simulation data
output
Simulations
Odyssey
AI/ML
Aquarius](https://image.slidesharecdn.com/pccc24itctheme-01-241127072241-60cfd5d2/75/PCCC24-24-PC-Miyabi-13-2048.jpg)


![17
API of h3-Open-SYS/WaitIO-Socket/-File
PB (Parallel Block): Each Application
WaitIO API Description
waitio_isend Non-Blocking Send
waitio_irecv Non-Blocking Receive
waitio_wait Termination of waitio_isend/irecv
waitio_init Initialization of WaitIO
waitio_get_nprocs Process # for each PB (Parallel Block)
waitio_create_group
waitio_create_group_wranks
Creating communication groups
among PB’s
waitio_group_rank Rank ID in the Group
waitio_group_size Size of Each Group
waitio_pb_size Size of the Entire PB
waitio_pb_rank Rank ID of the Entire PB
[Sumimoto et al. 2021]](https://image.slidesharecdn.com/pccc24itctheme-01-241127072241-60cfd5d2/75/PCCC24-24-PC-Miyabi-17-2048.jpg)
![Replacing
this part
with AI
Motivation of this experiment
Tow types of Atmospheric models: Cloud resolving VS Cloud
parameterizing
Could resolving model is difficult to use for climate simulation
Parameterized model has many assumptions
Replacing low-resolution cloud processes calculation with ML!
Diagram of applying ML to an atmospheric model
High Resolution Atmospheric Model
(Convection-Resolving Mode)
Low Resolution Atmospheric Model
(Convection-Parameterization Mode)
Physical process
Input
Output
Coupling with
Grid Remapping
ML App
(Python)
Coupling without
Grid Remapping
Coupling Phase 1
Training with high-resolution
NICAM data
Coupling Phase 2
Replacing Physical Process
in Low-Resolution NICAM
with Machine Learning
Atmosphere-ML Coupling
[Yashiro (NIES), Arakawa (ClimTech/U.Tokyo)]
75% 25%
Odyssey Aquarius
h3-Open-UTIL/MP
(Coupler)
+
h3-Open-SYS/WaitIO-
Socket
~0%](https://image.slidesharecdn.com/pccc24itctheme-01-241127072241-60cfd5d2/75/PCCC24-24-PC-Miyabi-18-2048.jpg)




























![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する](https://cdn.slidesharecdn.com/ss_thumbnails/31ddbjingohta-150626022623-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)







![[基調講演] DLL_RealtimeAI](https://cdn.slidesharecdn.com/ss_thumbnails/dllabdaykeynotesakakibara-180710072423-thumbnail.jpg?width=640&height=640&fit=bounds)




















