Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yasuharu Nishi
757 views
Paradigm shifts in QA for AI products
This slide is for 3rd AI/IoT system safety symposium.
Software
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 47 times
1
/ 51
2
/ 51
Most read
3
/ 51
4
/ 51
Most read
5
/ 51
6
/ 51
Most read
7
/ 51
8
/ 51
9
/ 51
10
/ 51
11
/ 51
12
/ 51
13
/ 51
14
/ 51
15
/ 51
16
/ 51
17
/ 51
18
/ 51
19
/ 51
20
/ 51
21
/ 51
22
/ 51
23
/ 51
24
/ 51
25
/ 51
26
/ 51
27
/ 51
28
/ 51
29
/ 51
30
/ 51
31
/ 51
32
/ 51
33
/ 51
34
/ 51
35
/ 51
36
/ 51
37
/ 51
38
/ 51
39
/ 51
40
/ 51
41
/ 51
42
/ 51
43
/ 51
44
/ 51
45
/ 51
46
/ 51
47
/ 51
48
/ 51
49
/ 51
50
/ 51
51
/ 51
More Related Content
PDF
Software-company Transformation
by
Yasuharu Nishi
PDF
車載ソフトウェアの品質保証のこれから
by
Yasuharu Nishi
PDF
Software Frontloading and QA
by
Yasuharu Nishi
PDF
LINE Developer Meetup in Tokyo #39 Presentation (modified)
by
Yasuharu Nishi
PDF
Re-collection of embedded software qa in the last decade
by
Yasuharu Nishi
PDF
modern software qa - draft 1
by
Yasuharu Nishi
PDF
Agile Quality アジャイル品質パターン (QA2AQ)
by
Hironori Washizaki
PPTX
ソフトウェアの品質保証の基礎とこれから
by
Yasuharu Nishi
Software-company Transformation
by
Yasuharu Nishi
車載ソフトウェアの品質保証のこれから
by
Yasuharu Nishi
Software Frontloading and QA
by
Yasuharu Nishi
LINE Developer Meetup in Tokyo #39 Presentation (modified)
by
Yasuharu Nishi
Re-collection of embedded software qa in the last decade
by
Yasuharu Nishi
modern software qa - draft 1
by
Yasuharu Nishi
Agile Quality アジャイル品質パターン (QA2AQ)
by
Hironori Washizaki
ソフトウェアの品質保証の基礎とこれから
by
Yasuharu Nishi
What's hot
PPTX
QAアーキテクチャの設計による 説明責任の高いテスト・品質保証
by
Yasuharu Nishi
PDF
テスト観点に基づくテスト開発方法論 VSTePの概要
by
Yasuharu Nishi
PDF
LINE Developer Meetup in Tokyo #39 Presentation
by
Yasuharu Nishi
PDF
パターン QA to AQ: 伝統的品質保証(Quality Assurance)からアジャイル品質(Agile Quality)へ
by
Hironori Washizaki
PDF
Demystifying quality management for large scale manufacturing in modern context
by
Yasuharu Nishi
PDF
DeNA QA night #2 presentation
by
Yasuharu Nishi
PDF
品質を加速させるために、テスターを増やす前から考えるべきQMファンネルの話(3D版)
by
Yasuharu Nishi
PDF
What is quality engineer? Is it something tasty?
by
Yasuharu Nishi
PPTX
ISO/IEC DIS 20246 についての(ごく簡単な)説明
by
しょうご すずき
PDF
What should you shift left
by
Yasuharu Nishi
PDF
テストを分類してみよう!
by
Kenji Okumura
PDF
What is quality culture? Is it something tasty?
by
Yasuharu Nishi
PDF
開発もQAも自動テスト!「LOST JUDGMENT:裁かれざる記憶」のQAテスター参加で進化した「テスト自動化チーム(仮)」の取り組みについて
by
SEGADevTech
PPTX
ソフトハウスの品質保証のウソホント
by
Yasuharu Nishi
PDF
ユーザーストーリー駆動開発で行こう。
by
toshihiro ichitani
PPTX
テストの組み立て方
by
kauji0522
PDF
Is No More QA Idealist Practical and Something Tasty?
by
Yasuharu Nishi
PDF
テスト分析についての説明資料公開用
by
Tsuyoshi Yumoto
PDF
組み合わせテストの落とし穴〜有則と無則〜
by
yufu yufu
PDF
探索的テスト入門
by
H Iseri
QAアーキテクチャの設計による 説明責任の高いテスト・品質保証
by
Yasuharu Nishi
テスト観点に基づくテスト開発方法論 VSTePの概要
by
Yasuharu Nishi
LINE Developer Meetup in Tokyo #39 Presentation
by
Yasuharu Nishi
パターン QA to AQ: 伝統的品質保証(Quality Assurance)からアジャイル品質(Agile Quality)へ
by
Hironori Washizaki
Demystifying quality management for large scale manufacturing in modern context
by
Yasuharu Nishi
DeNA QA night #2 presentation
by
Yasuharu Nishi
品質を加速させるために、テスターを増やす前から考えるべきQMファンネルの話(3D版)
by
Yasuharu Nishi
What is quality engineer? Is it something tasty?
by
Yasuharu Nishi
ISO/IEC DIS 20246 についての(ごく簡単な)説明
by
しょうご すずき
What should you shift left
by
Yasuharu Nishi
テストを分類してみよう!
by
Kenji Okumura
What is quality culture? Is it something tasty?
by
Yasuharu Nishi
開発もQAも自動テスト!「LOST JUDGMENT:裁かれざる記憶」のQAテスター参加で進化した「テスト自動化チーム(仮)」の取り組みについて
by
SEGADevTech
ソフトハウスの品質保証のウソホント
by
Yasuharu Nishi
ユーザーストーリー駆動開発で行こう。
by
toshihiro ichitani
テストの組み立て方
by
kauji0522
Is No More QA Idealist Practical and Something Tasty?
by
Yasuharu Nishi
テスト分析についての説明資料公開用
by
Tsuyoshi Yumoto
組み合わせテストの落とし穴〜有則と無則〜
by
yufu yufu
探索的テスト入門
by
H Iseri
Similar to Paradigm shifts in QA for AI products
PDF
機械学習品質管理・保証の動向と取り組み
by
Shintaro Fukushima
PDF
機械学習品質マネジメントプロジェクトのご紹介
by
Yutaka OIWA
PDF
Ques12「AIのテスト~誤検知と検出漏れ~」
by
hirokazuoishi
PDF
『生成AIによるソフトウェア開発』(鷲崎弘宜, 鵜林尚靖, 中川尊雄, 増田航太, 徳本晋, 近藤将成, 石川冬樹, 竹之内啓太, 小川秀人, スマートエ...
by
Hironori Washizaki
PDF
次世代AI時代のトレンドと高信頼AIソフトウェアシステム開発に向けたフレームワーク&パターン
by
Hironori Washizaki
PPTX
AIシステムの要求とプロジェクトマネジメント-後半:機械学習応用システムのための 要求工学と安全性
by
Nobukazu Yoshioka
PDF
超スマート社会時代のシステム&ソフトウェア品質知識体系 - SQuBOK 2020 における AI、IoT、クラウド、オープンソース、アジャイル、DevO...
by
Hironori Washizaki
PDF
Iot algyan jhirono 20190111
by
Hirono Jumpei
PDF
人工知能学会大会2020ーAI倫理とガバナンス
by
Hiroshi Nakagawa
PDF
鷲崎弘宜, "高品質なAIシステムの開発・運用のための"フレームワーク", eAIシンポジウム 2025年1月16日
by
Hironori Washizaki
PDF
コンピューティングおよびソフトウェア工学の潮流: IEEE-CS技術予測&SWEBOK Guideに基づくAI・アジャイル・サステナビリティの展望
by
Hironori Washizaki
PDF
QA4AI JaSST Tokyo 2019
by
Yasuharu Nishi
PDF
AIルールとガバナンス
by
Toshiya Jitsuzumi
PPTX
AIを活用した交通事故削減支援サービスでのテスト自動化
by
Shota Suzuki
PDF
自動車システムの安全性保証へのソフトウェア科学的アプローチ――論理的アカウンタビリティと適用コスト軽減の両立
by
Ichiro Hasuo
PPTX
企業でのAI開発でAIエンジニアに求められるもの
by
Hirohito Okuda
PDF
MLシステム品質強化のススメ
by
Kazutoshi Nakano
PPTX
ICLR'19 読み会 in 京都 [LT枠] AIプロダクト品質保証ガイドラインの紹介
by
Takahiro Toku
PDF
機械学習システムの品質保証に向けた課題とコンソーシアム活動
by
Hideto Ogawa
PDF
TERAS Conference
by
Keiju Anada
機械学習品質管理・保証の動向と取り組み
by
Shintaro Fukushima
機械学習品質マネジメントプロジェクトのご紹介
by
Yutaka OIWA
Ques12「AIのテスト~誤検知と検出漏れ~」
by
hirokazuoishi
『生成AIによるソフトウェア開発』(鷲崎弘宜, 鵜林尚靖, 中川尊雄, 増田航太, 徳本晋, 近藤将成, 石川冬樹, 竹之内啓太, 小川秀人, スマートエ...
by
Hironori Washizaki
次世代AI時代のトレンドと高信頼AIソフトウェアシステム開発に向けたフレームワーク&パターン
by
Hironori Washizaki
AIシステムの要求とプロジェクトマネジメント-後半:機械学習応用システムのための 要求工学と安全性
by
Nobukazu Yoshioka
超スマート社会時代のシステム&ソフトウェア品質知識体系 - SQuBOK 2020 における AI、IoT、クラウド、オープンソース、アジャイル、DevO...
by
Hironori Washizaki
Iot algyan jhirono 20190111
by
Hirono Jumpei
人工知能学会大会2020ーAI倫理とガバナンス
by
Hiroshi Nakagawa
鷲崎弘宜, "高品質なAIシステムの開発・運用のための"フレームワーク", eAIシンポジウム 2025年1月16日
by
Hironori Washizaki
コンピューティングおよびソフトウェア工学の潮流: IEEE-CS技術予測&SWEBOK Guideに基づくAI・アジャイル・サステナビリティの展望
by
Hironori Washizaki
QA4AI JaSST Tokyo 2019
by
Yasuharu Nishi
AIルールとガバナンス
by
Toshiya Jitsuzumi
AIを活用した交通事故削減支援サービスでのテスト自動化
by
Shota Suzuki
自動車システムの安全性保証へのソフトウェア科学的アプローチ――論理的アカウンタビリティと適用コスト軽減の両立
by
Ichiro Hasuo
企業でのAI開発でAIエンジニアに求められるもの
by
Hirohito Okuda
MLシステム品質強化のススメ
by
Kazutoshi Nakano
ICLR'19 読み会 in 京都 [LT枠] AIプロダクト品質保証ガイドラインの紹介
by
Takahiro Toku
機械学習システムの品質保証に向けた課題とコンソーシアム活動
by
Hideto Ogawa
TERAS Conference
by
Keiju Anada
More from Yasuharu Nishi
PDF
日本のテスト産業の国際競争力 ~日本をソフトウェアテスト立国にしよう~
by
Yasuharu Nishi
PDF
ちょっと明日のテストの話をしよう
by
Yasuharu Nishi
PDF
同値分割ってなんだろう?
by
Yasuharu Nishi
PPT
Viewpoint-based Test Requirement Analysis Modeling and Test Architectural D...
by
Yasuharu Nishi
PDF
Tomorrow's software testing for embedded systems
by
Yasuharu Nishi
PPTX
IoT時代と第3者検証
by
Yasuharu Nishi
PDF
CommentScreeen is good
by
Yasuharu Nishi
PDF
Tomorrow's software testing for embedded systems ~明日にでも訪れてしまう組込みシステムのテストの姿~
by
Yasuharu Nishi
PDF
Demystifying quality management for large scale manufacturing in modern context
by
Yasuharu Nishi
PDF
Teaser - Re-collection of embedded software QA in the last decade
by
Yasuharu Nishi
PDF
LINE Developer Meetup in Tokyo #39 Trailer
by
Yasuharu Nishi
日本のテスト産業の国際競争力 ~日本をソフトウェアテスト立国にしよう~
by
Yasuharu Nishi
ちょっと明日のテストの話をしよう
by
Yasuharu Nishi
同値分割ってなんだろう?
by
Yasuharu Nishi
Viewpoint-based Test Requirement Analysis Modeling and Test Architectural D...
by
Yasuharu Nishi
Tomorrow's software testing for embedded systems
by
Yasuharu Nishi
IoT時代と第3者検証
by
Yasuharu Nishi
CommentScreeen is good
by
Yasuharu Nishi
Tomorrow's software testing for embedded systems ~明日にでも訪れてしまう組込みシステムのテストの姿~
by
Yasuharu Nishi
Demystifying quality management for large scale manufacturing in modern context
by
Yasuharu Nishi
Teaser - Re-collection of embedded software QA in the last decade
by
Yasuharu Nishi
LINE Developer Meetup in Tokyo #39 Trailer
by
Yasuharu Nishi
Paradigm shifts in QA for AI products
1.
AI・機械学習製品の品質保証に関する 課題とパラダイムシフト 2021/11/29(月) 第3回 AI/IoTシステム安全性シンポジウム 西 康晴(電気通信大学)
2.
Profile • Assistant professor: –
The University of Electro-Communications, Tokyo, Japan • President: – Association of Software Test Engineering, Japan - Nonprofit organization (ASTER) • President: – Japan Software Testing Qualifications Board (JSTQB) • National delegate: – ISO/IEC JTC1/SC7/WG26 Software testing (ISO/IEC(/IEEE) 29119, 33063, 20246) • Chair: – JIS Drafting Committee on Software Review Process (based on ISO/IEC 20246) • Founder: – Japan Symposium on Software Testing (JaSST) • Founder: – Testing Engineers’ Forum (TEF: Japanese community on software testing) • Judgement Panel Chair / member: – Test Design Contest Japan, Test Design Competition Malaysia (TDC) • Vice chair: – Software Quality Committee of JUSE (SQiP) • Vice chair: – Society of Embedded Software Skill Acquisition for Managers and Engineers (SESSAME) • Steering Committee Chair – QA4AI Consortium • Advisor: – Software Testing Automation Research group (STAR) © NISHI, Yasuharu p.2
3.
AIの品質保証はまだ発展途上であり、体系化されておらず、各社で四苦八苦している © NISHI, Yasuharu p.3 https://twitter.com/_gyochan_/status/938240168078622720 "Why
Should I Trust You?": Explaining the Predictions of Any Classifier, Ribeiro et al, KDD2016 arXiv:1707.08945 [cs.CR]
4.
AIプロダクトの課題 • 帰納的開発である – 今までの(演繹的)開発経験に基づいたレビュー、メトリクス、プロセスQAが無力となる –
「探索的開発」が必要となる • データの質とモデルの質がまず大事になる • 自動化やアジリティの高い開発スタイルが必要になる – 技術力のあるエンジニアやチームが技術的にきちんと納得感を共感しながら進める必要がある • データサイエンス方面と機械学習方面とソフトウェア開発方面のエンジニアは文化が異なることがある • CACE性を持ち、精度は100%にならない – 非線形で、分布が仮定できないことが多く、構造が複雑である • CACE: Changing Anything Changes Everything – ほんの少しでも変えたら全体がガラッと変わるかもしれない • 分割統治もグループ化(ex. 同値分割)もできない – コンポーネントやシステム全体に対して自動化によるFEETが必要となる • FEET: Frequent, Entire and Exhaustive Testing - 全体全数高頻度検証 – 顧客の期待を適切にコントロールすることが重要になる • 性能や不具合などの因果関係の説明や理解が極めて困難である – 説明可能性に関する技術はeXplainable AI(XAI – 説明可能AI)として現在盛んに研究されており、 本ガイドラインでも解説されている • しかしそもそも演繹的開発においても、 「それで保証したとみなせるかどうか」をきちんと検討し理解している組織は極めて少ないと思われる © NISHI, Yasuharu p.4
5.
そこで… • 2018年4月に「AIプロダクト品質保証コンソーシアム(QA4AIコンソーシアム)」を設立した – 2021年11月現在77+αの専門家・組織が参画している •
http://www.qa4ai.jp/ – 産学連携でオープンに議論するコンソーシアムである • 議論し(て成果物を作り)たい人だけが集まる場となっている – 月1回の(オンライン)会合とSlackによる議論・情報交換 – 会費などは不要である • 類似の活動をしている全ての組織とハーモナイズしようとしている – サブドメインや技術グループに分かれて議論している • コンテンツ生成系、VoiceUI、産業用プロセス、自動運転、AI-OCR、説明可能AI(XAI)など – 横断的に法的側面についても議論している – 2021年6月18日(金)に「Open QA4AI Conference 2021」を開催した • オンラインかつ無料で、QA4AI・産総研・ISO/IEC JTC1/SC42・JAXA・名大・NIIがそれぞれの最新動向を紹介した – https://qa4ai.connpass.com/ • 「AIプロダクト品質保証ガイドライン」の最新版(280ページ!)を2021年9月に発行した – AIプロダクトの品質保証を行う際の基本となる考え方が示されている • 開発組織にも顧客にも(相応の)安心をして欲しい • QAがジャマをしてはいけない、過度の期待を防ぎたい – 現時点の世の中の技術水準では、万能なガイドラインは作成しえない • 本ガイドラインを活用する場合は、自ドメインや自社、自組織の状況などを 熟慮、反映し、自組織の責任の下において活用する必要がある – 網羅性や完全性を企図したものではないし、そのまま品質マニュアルにもならない • 年次程度で更新していく予定である © NISHI, Yasuharu p.5
6.
QA4AIのメンバ(74名+3組織+α) • 青木 利晃 (北陸先端科学技術大学院大学)* •
秋場 良太(有限責任あずさ監査法人) • 池田 裕則(東芝インフラシステムズ) • 石川 冬樹(国立情報学研究所)* • 伊藤 潤平(ウイングアーク1st) • 伊藤 浩朗 (日立オートモティブシステムズ) • 猪又 憲治(三菱電機)* • 今井 健男(Idein)* • 今谷 恵理(日立製作所) • 上田 英介(FastLabel) • 宇治田 康浩(オムロン) • 秋場 良太(有限責任あずさ監査法人) • 梅津 良昭(リコー)* • 遠藤 征樹 (日立産業制御ソリューションズ)* • 大西 秀一(ヴィッツ) • 大野 敦寛 (日立オートモティブシステムズ) • 小川 秀人(日立製作所)* • 荻野 恒太郎(楽天)* • 長田 健一 (日立オートモティブシステムズ)* • 小原 勇揮(ウイングアーク1st) • 柏 良輔(横河電機)* • 岸 知二(早稲田大学)* • 鬼頭 正広(アイシン・ソフトウェア) • 衣簱 宏和 (三菱電機マイコン機器ソフトウエア) • 窪田 邦夫(マレリ)* • 栗田 太郎(ソニー) • 久連石 圭(東芝) • 黒田 園子(パナソニック)* • 小宮山 英明(コニカミノルタ) • 榊原 彰(日本マイクロソフト)* • 佐藤 孝司(京都情報大学院大学) • 島田 さつき(富士通クォリティラボ) • 清水 真(アライズイノベーション) • 柴山 吉報 (ABEJA/阿部・井窪・片山法律事務所) • 鈴木 万治 (DENSO International America Inc.)* • 須原 秀敏(株式会社ベリサーブ) • 妹尾 義樹(国立産業技術総合研究所) • 田口 研治(シーエーブイテクノロジーズ) • 千田 伸男(三菱電機) • 土屋 知典(富士通)* • 徳 隆宏(ダイキン工業)* • 徳本 晋(富士通研究所) • 中江 俊博(デンソー) • 中川 純貴(日立製作所) • 中澤 克仁(富士通) • 中野 宏昭 (富士フイルムビジネスイノベーション) • 西 康晴(電気通信大学)* • 野原 優己(LINE Fukuoka) • 濱田 晃一(ディー・エヌ・エー)* • 日置 智之(シナモン) • 深井 寛修(明電舎) • 藤井 岳(シナモン) • 誉田 直美(イデソン)* • 増田 聡(東京都市大学)* • 町田 欣史(エヌ・ティ・ティ・データ)* • 松原 修(富士通北陸システムズ) • 松谷 峰生(LIFULL)* • 真鍋 誠一(センスタイムジャパン) • 三浦 真樹(富士通) • 三島 浩一(三菱電機) • 光本 直樹(デンソー)* • 宮坂 隆之(本田技術研究所) • 明神 智之(日立製作所) • 向山 輝(日本電気) • 武藤 裕之(アイシン・ソフトウェア) • 森川 聡久(ヴィッツ) • 森田 知宏(三菱電機) • 山下 直人(ウイングアーク1st) • 山口 晋一(慶應義塾大学SDM研究所) • 山元 浩平(コーピー) • 吉岡 信和(早稲田大学) • 吉田 啓太(三菱電機) • 鷲崎 弘宜(早稲田大学)* • 渡部 和也(アライズイノベーション) • 宇宙航空研究開発機構(JAXA) 研究開発部門第三研究ユニット • ソフトウェアテスト技術振興協会 (ASTER) • 日本科学技術連盟(JUSE) (以上五十音順、敬称略、 2021年11月28日現在) © NISHI, Yasuharu p.6
7.
AIプロダクト品質保証ガイドラインの構造 • AIプロダクトの品質保証に対して共通の指針を与える – 280ページに及ぶ充実した内容 –
ML/AIの技術はいまだ発展途上のため、 本ガイドラインは網羅性や完全性を企図したものではない • 本ガイドラインを活用する場合は、 自ドメインや自社、自組織の状況などを熟慮、反映し、 自組織の責任の下において活用する必要がある – 結果として、伝統的(非AI)プロダクトの品質保証にも役立つガイドラインとなった – 全体的な考え方と技術と、各WGごとの解説・ガイドラインとで構成される • 各WGごとの解説・ガイドラインは、全体的な考え方と技術の単純なインスタンスではない • How toよりもコンセプトや解釈の記述が中心となっている – ドメインの技術の成熟度やリリース済みプロダクト数、背景などによって 「書きっぷり」が異なる © NISHI, Yasuharu p.7
8.
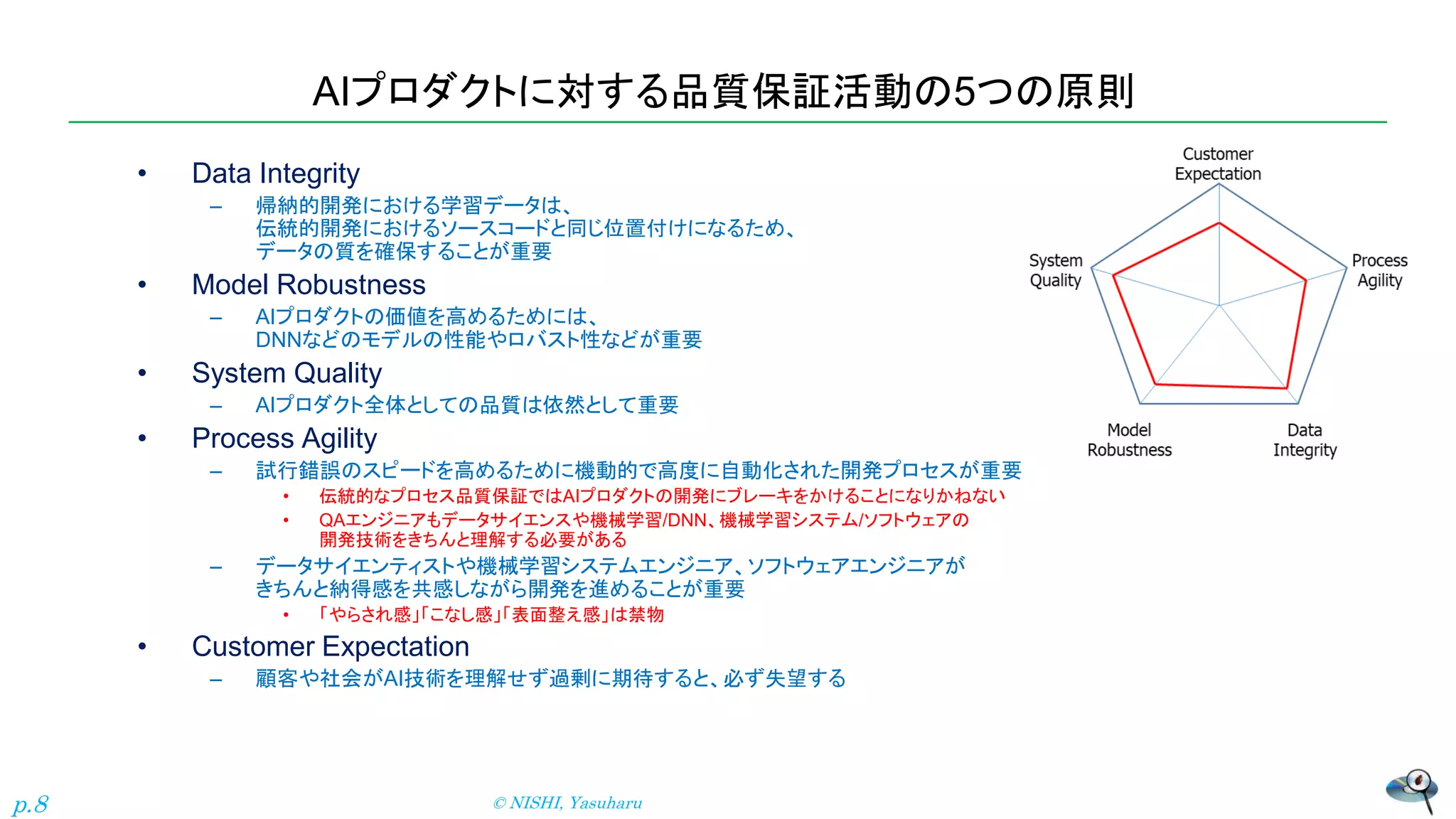
AIプロダクトに対する品質保証活動の5つの原則 • Data Integrity –
帰納的開発における学習データは、 伝統的開発におけるソースコードと同じ位置付けになるため、 データの質を確保することが重要 • Model Robustness – AIプロダクトの価値を高めるためには、 DNNなどのモデルの性能やロバスト性などが重要 • System Quality – AIプロダクト全体としての品質は依然として重要 • Process Agility – 試行錯誤のスピードを高めるために機動的で高度に自動化された開発プロセスが重要 • 伝統的なプロセス品質保証ではAIプロダクトの開発にブレーキをかけることになりかねない • QAエンジニアもデータサイエンスや機械学習/DNN、機械学習システム/ソフトウェアの 開発技術をきちんと理解する必要がある – データサイエンティストや機械学習システムエンジニア、ソフトウェアエンジニアが きちんと納得感を共感しながら開発を進めることが重要 • 「やらされ感」「こなし感」「表面整え感」は禁物 • Customer Expectation – 顧客や社会がAI技術を理解せず過剰に期待すると、必ず失望する © NISHI, Yasuharu p.8
9.
Data Integrity –
データはきちんとしているか □ 量は充分か、意味のある量か、「かさ増し」しても大丈夫か □ 求める母集団のサンプルか、実際のデータもしくは そうみなせるデータを利用しているか、想定とそぐわないデータが 含まれていないか、費用対効果は適切か □ データに関するステークホルダーの要求事項を満たしているか、 整合性や公平性、個人情報の有無などデータの制約に反していないか □ 偏りやバイアス、汚染の可能性を多様な観点から検討し、 適切であることを確認したか □ データは複雑すぎないか、単純すぎないか、 □ データ内の性質(多重共線性など)は適切に考慮されているか □ それぞれのデータは常識的な値か、外れ値は本当に外れているデータか、 欠損に意味はないか、外れ値や欠損値の扱いは適切か □ 所有権や著作権・知的財産権、機密性、プライバシーは契約も含め適切に考慮されているか □ 学習用データと検証用データは独立しているか □ オンライン学習を行う場合、その影響を適切に考慮しているか □ 学習用プログラムやデータ生成プログラムの不具合によってデータの意味が毀損されないか © NISHI, Yasuharu p.9 Customer Expectation System Quality Process Agility Model Robustness Data Integrity
10.
Model Robustness –
モデルはきちんとしているか □ 正答率、適合率、再現率、F値といった精度は妥当か □ 汎化性能は確保されているか □ (AUROCといった)モデルのよさを表す指標は充分か □ 学習は適切に進行したか、局所最適に陥っていないか □ 適切なアルゴリズムやハイパーパラメータかどうかの検討は行ったか、 □ 十分に交差検証などを行ったか □ ノイズに対して頑健か □ 数理的多様性、意味的多様性、社会的文化的多様性などを考慮し、 十分に多様なデータで検証を行ったか □ デグレードは許容可能な範囲か、デグレードの影響範囲を把握できているか、 学習は再現可能か、モデル更新時の自動化された検証内容は十分であるか □ モデルが陳腐化していないか、実データに対する予測品質が劣化していかないか、 運用における監視などの対策をとっているか □ 学習アルゴリズムの特性、ライブラリやそれを呼び出すプログラムの不具合や 誤った利用により、不適切なモデルとなっていないか © NISHI, Yasuharu p.10 「精度が高ければ品質がよい」 ではない! Customer Expectation System Quality Process Agility Model Robustness Data Integrity
11.
System Quality –
システム全体として価値が高く、何かが起きても何とかなるか □ 価値は適切に提供されているか、提供価値は計測できているか、 価値の計測が難しい場合、代替メトリクスとの関連は妥当か □ 性能などシステム全体のふるまいが劣化していかないか □ システムを全体として、および意味のある単位で評価を行ったか □ 発生しうる品質事故の致命度は許容できる程度に低く抑えられているか □ 品質事故を引き起こしうる事象の発生頻度は低いと見積もることができるか、 事象の発生頻度や事象の網羅性、環境の制御可能性の検討は充分か □ システムの事故到達度・安全機能・耐攻撃性は充分か □ システムの様々な要素のAIへの設計上の依存度や結合度を抑えられているか、 システムが依存する他の(AIの、もしくは非AIの)システムの変更は迅速かつ適切に 反映できるか、不具合の影響を充分低く抑えられる設計や設計変更は可能か □ ステークホルダーに対する保証性、説明可能性、納得性は充分か □ 第三者への知的財産権を侵害しないか □ 継続的な運用に伴う品質低下の可能性やそれを検知する仕組みを検討したか © NISHI, Yasuharu p.11 ※Quality、Reliability、 Dependability、 Safety、Securityなどを ここでは厳密に区別していない Customer Expectation System Quality Process Agility Model Robustness Data Integrity
12.
Process Agility –
プロセスは機動的か □ データ収集の速度とスケーラビリティは充分か □ 充分短い反復単位で反復型開発は行っているか、 モデル・システムの品質向上の周期は充分短いか、 運用状況の継続的なフィードバックは頻繁か □ 問題発生時の原因解析のために、問題発生時の状況を 記録し取得できる仕組みを備えているか、事象を再現できるか □ リリースロールバックは簡便で迅速に行えるか □ 新しい特徴量を迅速に追加したりモデルを迅速に改善したりできるなど、 よりよくなっていく見込みはあるか □ 段階的リリースやカナリアリリースの度合は適切か、 リリース直前にシステム全体やモデルの評価を行っているか □ 開発・探索・検証・リリースなどの自動化は充分か □ データ、モデル、環境、コード、出力などの構成管理が適切に行われているか □ 開発者やチームは技術的に充分納得し共感しているか □ 開発チームは適切な能力を持った人財を備えているか、経験を技術に反映させられているか □ 開発チーム外のステークホルダーは充分納得しているか © NISHI, Yasuharu p.12 Customer Expectation System Quality Process Agility Model Robustness Data Integrity
13.
Customer Expectation –
(良くも悪くも)顧客の期待は高いか □ 顧客の期待は高いか □ 狙っているのが「人間並み」か □ 顧客は確率的動作という考え方を受容していないか、 リスク・副作用を理解していなかったり受容したりしていないか、 安易に受容して必要な対策を怠っていないか □ データの量や質に対する認識は甘いか □ “合理的”説明を求める傾向や、“外挿”や“予測”をしたがる傾向、 “原因”や“責任(者)”を求めたがる傾向はあるか □ 継続的実運用にどのくらい近いか □ AIプロダクトに法令上、倫理上の問題はあるか、第三者のプライバシー等への 配慮が必要か、AIプロダクトの利用が社会的に受容されているか □ 納得感を共感する風土や雰囲気、仕事の進め方は少ないか □ 顧客担当者・チームで意思決定できる権限や範囲は少ない・狭いか © NISHI, Yasuharu p.13 System Quality Process Agility Model Robustness Data Integrity Customer Expectation
14.
バランスがよい・バランスが悪いとは? • バランスがよい: 顧客の期待に沿っていると保証できることが期待できる状況 – DI/MR/SQ/PAに不足がないという条件 •
DI/MR/SQ/PAのどれか一つが欠けていても品質が確保できたとは言えません – (DI/MR/SQ/PAに対して)顧客の期待が適切であるという条件 • 顧客の期待を適切に把握し、可能ならば期待を適切な程度に収め、 DI/MR/SQ/PAが総合的に期待を満たすようにします • バランスが悪い: 顧客の期待に対してDI/MR/SQ/PAが不足している状況 – DI/MR/SQ/PAが不足している状況 • 品質は「最弱リンク」で作用することが多いので、最も劣っているものに左右されます – 顧客の期待が高すぎる状況 • 可能な限り期待値コントロールをすべきです – 短期的で個別的な期待値コントロールと、 中長期的で社会的な期待値コントロールの両方が本来必要です © NISHI, Yasuharu p.14 Customer Expectation System Quality Process Agility Model Robustness Data Integrity Customer Expectation System Quality Process Agility Model Robustness Data Integrity
15.
開発の段階と面積 • 開発の段階(PoC、βリリース、 継続的実運用など)ごとに面積は異なるが バランスは取れている必要がある © NISHI,
Yasuharu p.15 Customer Expectation System Quality Process Agility Model Robustness Data Integrity PoC βリリース 継続的実運用
16.
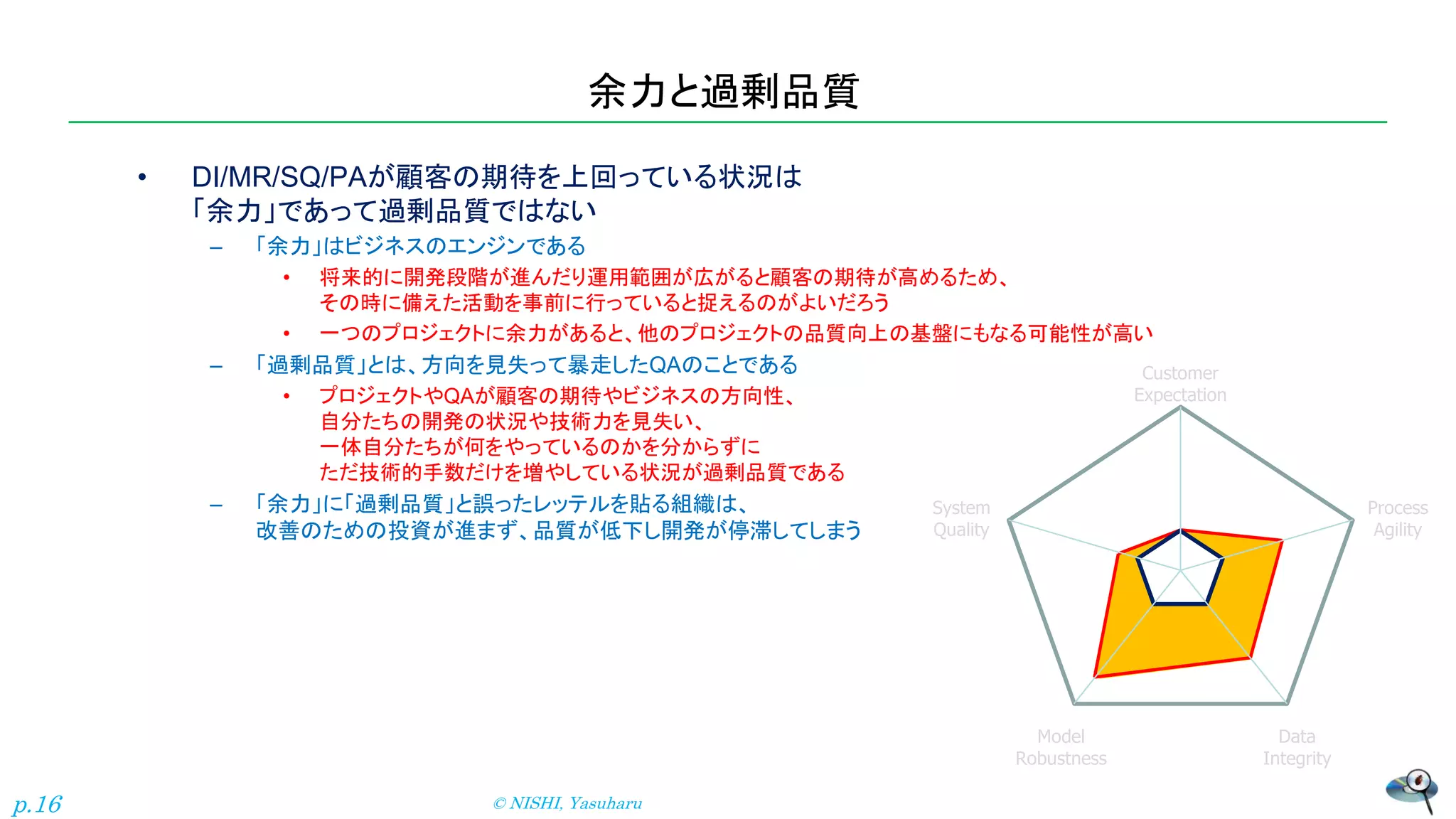
余力と過剰品質 • DI/MR/SQ/PAが顧客の期待を上回っている状況は 「余力」であって過剰品質ではない – 「余力」はビジネスのエンジンである •
将来的に開発段階が進んだり運用範囲が広がると顧客の期待が高めるため、 その時に備えた活動を事前に行っていると捉えるのがよいだろう • 一つのプロジェクトに余力があると、他のプロジェクトの品質向上の基盤にもなる可能性が高い – 「過剰品質」とは、方向を見失って暴走したQAのことである • プロジェクトやQAが顧客の期待やビジネスの方向性、 自分たちの開発の状況や技術力を見失い、 一体自分たちが何をやっているのかを分からずに ただ技術的手数だけを増やしている状況が過剰品質である – 「余力」に「過剰品質」と誤ったレッテルを貼る組織は、 改善のための投資が進まず、品質が低下し開発が停滞してしまう © NISHI, Yasuharu p.16 Customer Expectation System Quality Process Agility Model Robustness Data Integrity
17.
品質保証技術のカタログ • AIプロダクト固有の品質特性 – 教師あり学習のモデルに対する性能指標 •
適合率・精度、再現率、F値、ROC曲線におけるAUC、平均二乗誤差、決定係数 • 汎化性能、過学習・未学習 • 交差検証 – データに対する評価 • 規則性(傾向、分布)、訓練データと運用データの違い • ISO/IEC 25012 (JIS X 25012)データ品質モデル – 頑健性 – 説明可能性 – 機械学習を用いたシステム全体における品質 • AIプロダクトにおける品質管理上の留意点 – 試験的・探索的なプロセスの理解・協力の必要性と、顧客を始めとしたステークホルダーの理解・協力の必要性 • 要求やユースケースを調節して 「適合率が低くても再現率が高ければ受け入れる」といった判断が必要となることがある – データの分布の違いや実世界の劣化に起因する性能劣化の考慮 • 開発時に実世界のデータについての想定を尽くすことは困難である • 実世界の物体は変化・劣化するし、カメラやセンサーも変更されたり劣化する – オンライン学習における学習・訓練データの選別・性能評価やテストなどの自動化の必要性 – 訓練データ、学習アルゴリズム、ハイパーパラメータの記録の必要性 • Ex) コマンドラインで学習アルゴリズムに関するオプションを設定する場合、その情報は失われやすい © NISHI, Yasuharu p.17
18.
品質保証技術のカタログ • AIプロダクトの品質保証技術 – 疑似オラクル •
Nバージョン開発や古いバージョンとの比較 • 出力が完全に一致しなくても、誤差・距離の大きいケースを調べると問題に気付いたり知見が得られたりする – 誤差・距離の大きいケースをサーチベースドテスティング技術で探索することもできる – メタモルフィックテスティング • 「入力に対してある一定の変化を与えると、出力の変化が理論上予想できる」という関係 (メタモルフィック関係)を用いることで、正否判断が可能なテストケースを(自動的に)生成する – データ点の属性に一定値を加える/乗算する、データ点を追加する・削除する、データ点を入れ替える、など – 頑健性検査 • 入力となるテストデータに変化を加えて出力が変化しないかを評価する – 例えば入力が画像である場合、照度の変化や、雨や霧の画像合成による追加、一部欠損やゆがみなどを考える – ニューラルネットワークにおけるカバレッジ • プログラムコードのカバレッジは意味をなさない • ニューラルネットワークのニューロンに着目してカバレッジを測定・評価する – カバレッジでテストスイートの質を評価したり、カバレッジを向上するようにテストケースを生成する、 という意味では従来と用法は同じである • 必ずしも求められる品質と強い相関があるわけではないことも報告されているので、盲目的に信じてはならない – 説明可能性・解釈性のための技術 • 入力データのうちどの部分がある出力の決定に影響を大きく与えたのか、といった情報を提示する • モデル全体がどのような規則性・判断基準を身につけているかを、人が解釈できるようにする • など © NISHI, Yasuharu p.18
19.
生成系システム • どのような品質をどうやって品質保証しますか? © NISHI,
Yasuharu p.19
20.
生成系システム • 対象となる生成系システムとユースケースを定め、品質特性を検討した – 「新しい画像や動画をつくり出す」といった創造的かつ高度な機能に対して、 「自然である」「多様である」「入力画像のテイスト(画風等)が維持されている」など 非常に抽象的に表現される品質を評価しなければならない –
以下のような品質特性を例示した • 自然さ、鮮明さ、多様さ、社会的適切さ • 指定構造との合致、指定属性との合致 • 動画としての自然さ、動画のなめらかさ、構造系列としての自然さ © NISHI, Yasuharu p.20
21.
生成系システム • 対象となる生成系システムの品質特性を評価する技術アプローチを検討した – 例:自然さ、鮮明さ、多様さ •
生成対象の画像・動画での学習済識別モデルを用い、識別結果分布・特徴量分布を用いて評価する – Inception Score、Fréchet/Kernel Inception Distance、Learned Perceptual Image Patch Similarity – 例:動画のなめらかさ • 画像間のOptical Flowの統計値を評価する – 例:構造系列としての自然さ • 身体構造上接続している器官点間の相対距離の変化量を数値化し評価する – 例:自然さ、鮮明さ • GANs学習により、本物のデータであるかを判別する識別器を構築できる • Webからイラストを収集し、崩れやノイズを付加することにより不自然な画像や動画のデータを作ることで、 品質評価AIを構築することができる。 – 例:社会的適切さ • 検索エンジンで用いられている社会的に不適切なデータを識別するAIを用いることができる – 例:指定構造との合致、指定属性との合致 • 画像や動画に写る人物の姿勢を推定するAIの技術を用いて、 指定された姿勢との合致度を評価することができる © NISHI, Yasuharu p.21
22.
生成系システム • 対象となる生成系システムの品質保証レベルを定めた – レベル1:システム内部挙動を知っている人の利用のために保証すべき水準 •
動画作成を請け負うサービスを運営し、 コンテンツ生成システムの開発チームも交えた組織にて動画を作成する場合など – 複数出力からの選出可能性を考慮して評価する – レベル2:システム内部挙動を知らない、外部の人による利用のために保証すべき水準 • コンテンツ生成システムをアニメーション制作会社に納品して利用させるような場合など – 安定性を重視して評価する – レベル3:悪意のある人も含めて多種多様なユーザーに利用させるときに保証すべき水準 • コンテンツ生成システムを不特定多数のユーザーが利用できるサービスとして Web上にて公開し、利用させるような場合など – 多様な入力を想定して評価する • SPADEをテスト対象としたテスト設計事例を示した – SPADEはラベルマップとスタイルガイド画像を入力され、その入力に応じた画像を生成する • Semantic Image Synthesis with Spatially-Adaptive Normalization – 品質特性として以下を選定した • 自然さ、鮮明さ、指定ラベルマップとの合致、指定スタイルガイド画像との合致 – テストアーキテクチャの設計例を示した – 実際にテスト実施をしてみた • SPADE ver.1a687baをテスト対象とした – NIIトップエスイープログラムにご協力頂いた • ラベルマップに関する頑健性を確認できた • スタイルガイドに関して生成画像の崩れを検出できた © NISHI, Yasuharu p.22
23.
Voice User Interface
(VUI) • どのような品質をどうやって品質保証しますか? © NISHI, Yasuharu p.23
24.
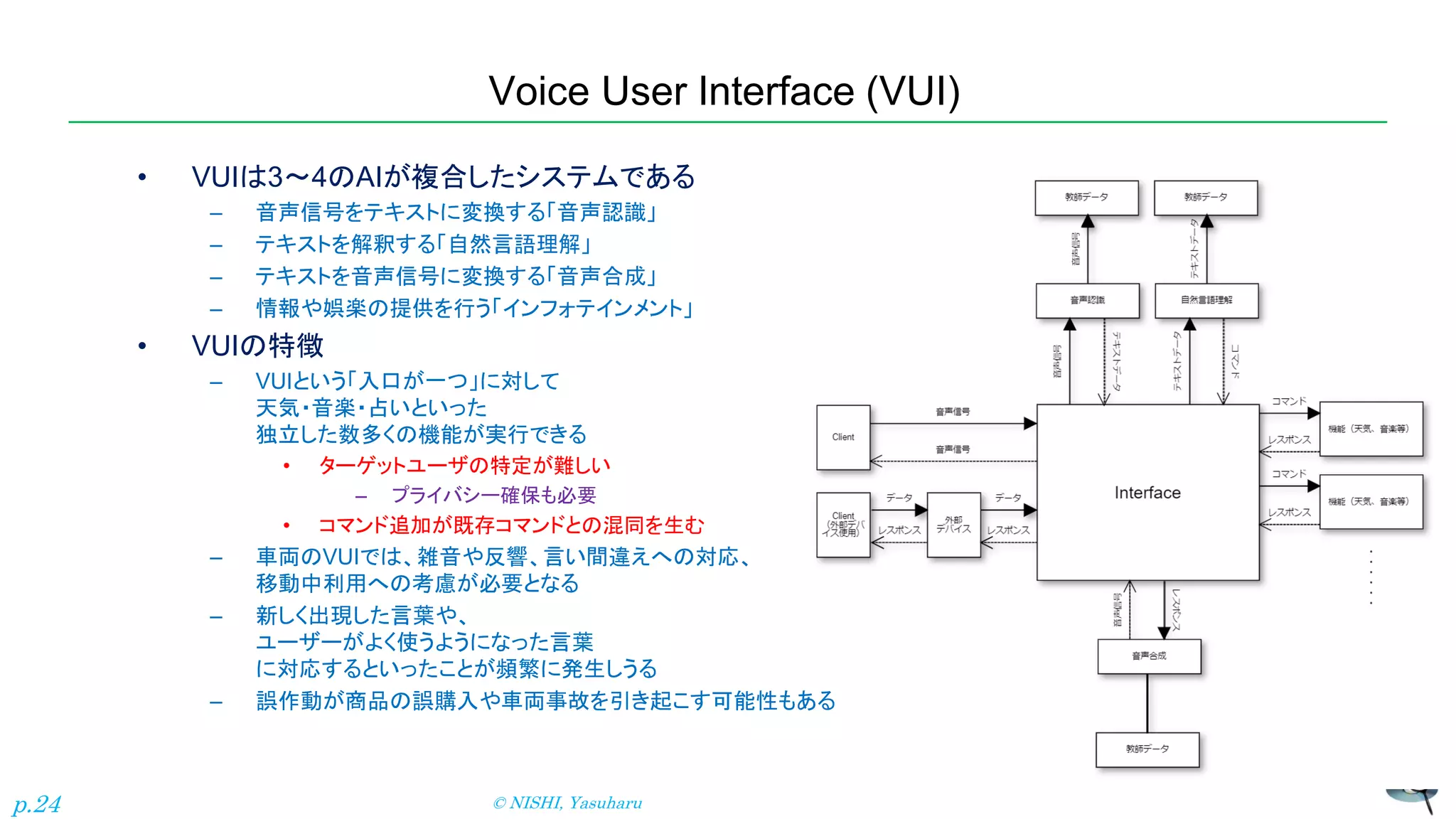
Voice User Interface
(VUI) • VUIは3~4のAIが複合したシステムである – 音声信号をテキストに変換する「音声認識」 – テキストを解釈する「自然言語理解」 – テキストを音声信号に変換する「音声合成」 – 情報や娯楽の提供を行う「インフォテインメント」 • VUIの特徴 – VUIという「入口が一つ」に対して 天気・音楽・占いといった 独立した数多くの機能が実行できる • ターゲットユーザの特定が難しい – プライバシー確保も必要 • コマンド追加が既存コマンドとの混同を生む – 車両のVUIでは、雑音や反響、言い間違えへの対応、 移動中利用への考慮が必要となる – 新しく出現した言葉や、 ユーザーがよく使うようになった言葉 に対応するといったことが頻繁に発生しうる – 誤作動が商品の誤購入や車両事故を引き起こす可能性もある © NISHI, Yasuharu p.24
25.
Voice User Interface
(VUI) • テストアーキテクチャについて例示し、留意すべき観点を挙げた © NISHI, Yasuharu p.25
26.
Voice User Interface
(VUI) • 学習に必要なパターンの例を挙げた – 同一の音声入力文字列であっても、正しく文字列として解釈できること • 性別(男女など)、年齢(高低)、トーン(アクセント、早口、声色)、言葉の区切り位置(「天気は?/天気、は?」など)、 感情(「優しい/厳しい」など)、言語初心者(母音記号誤差 - L/Rの区別など、母国語依存 - 濁音など) – 異なる標準でも、標準的な文章として理解できること • 口調(敬語、命令系、若者言葉)、助詞(「の」「は」のばらつき)、文法(語順の変化、体言止め)、 略語(「こいばな」といった略語、歌手名の略称など)、同音異義語(表現「雨/飴」など、曖昧表現「みたい/見たい」など、 同音の地名など)、多言語(和製英語「ナイーブ、テンション」)、流行語(ばえる、モヤるなど) – システムの利用者環境が製品保証範囲であれば正しく動作すること • 設置環境(音声ノイズ - テレビ・近所のおしゃべり、雑音ノイズ - 生活音・ドア開閉・扇風機の音など)、 設置場所(振動 - 足場が悪い、壁面 – 反響など) – システムの利用者が理解できる音声メッセージを伝えること • 発音(漢字の読み方「ついたち/いちにち」、慣用句、有名人)、 トーン(アクセント、早口・区切り、感情、声色)、情報量(重要度・緊急度) – システム購入者の音声入力を正確に理解できること • 個別化(話者認識 - 音声の分離・個人の特定) • テストアーキテクチャ全体に渡って留意すべき観点の例を挙げた – コマンドレスポンス、サービス保証 • 通信、インターフェース互換、音質 – 不適切なサービスアクセス、不適切なサービスレスポンス • ペアレンタルコントロール、卑猥、宗教、報道におけるタブー、資産、プライバシー – 外部デバイス呼び出し時の安全性 © NISHI, Yasuharu p.26
27.
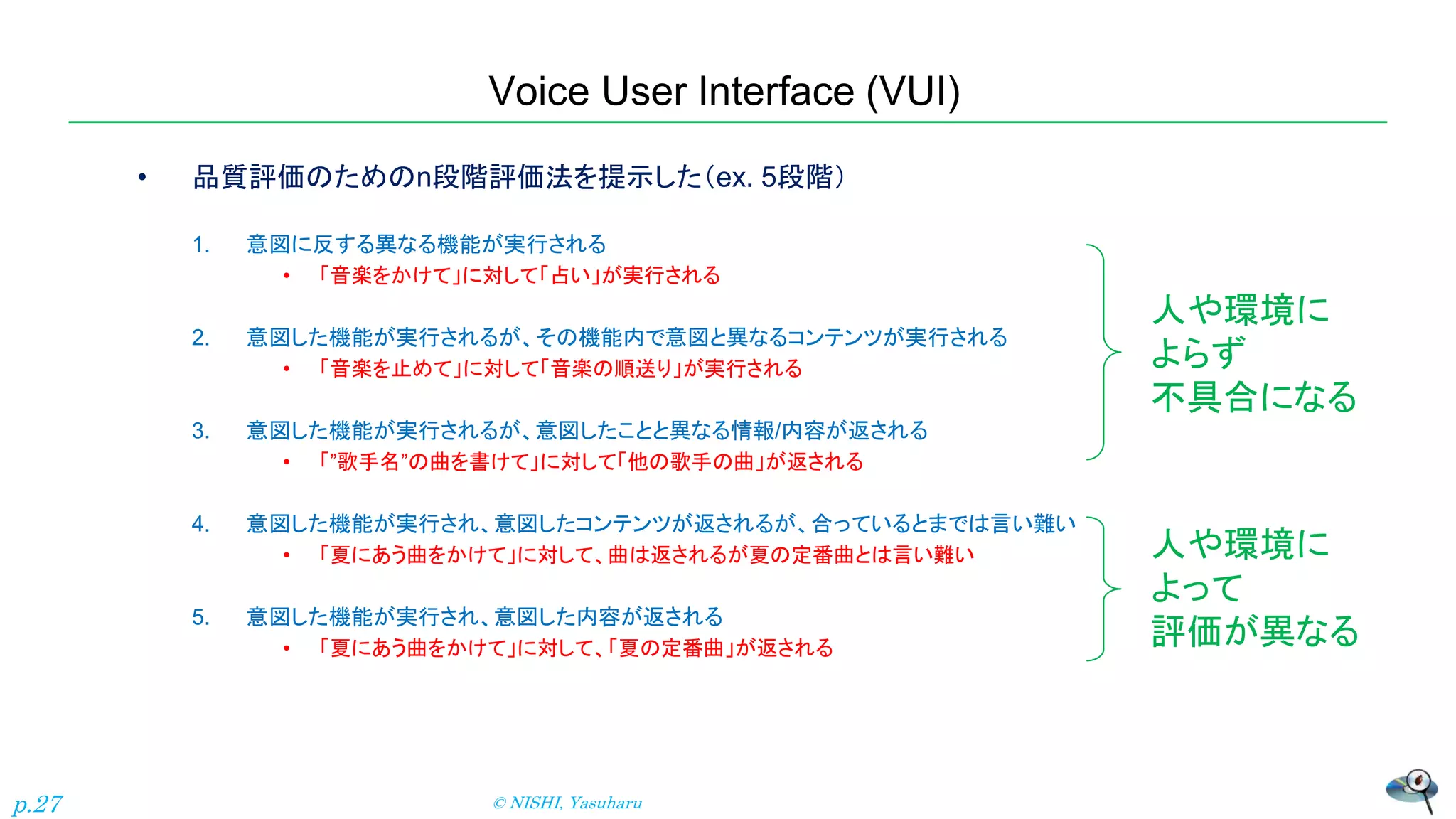
Voice User Interface
(VUI) • 品質評価のためのn段階評価法を提示した(ex. 5段階) 1. 意図に反する異なる機能が実行される • 「音楽をかけて」に対して「占い」が実行される 2. 意図した機能が実行されるが、その機能内で意図と異なるコンテンツが実行される • 「音楽を止めて」に対して「音楽の順送り」が実行される 3. 意図した機能が実行されるが、意図したことと異なる情報/内容が返される • 「”歌手名”の曲を書けて」に対して「他の歌手の曲」が返される 4. 意図した機能が実行され、意図したコンテンツが返されるが、合っているとまでは言い難い • 「夏にあう曲をかけて」に対して、曲は返されるが夏の定番曲とは言い難い 5. 意図した機能が実行され、意図した内容が返される • 「夏にあう曲をかけて」に対して、「夏の定番曲」が返される 人や環境に よらず 不具合になる 人や環境に よって 評価が異なる © NISHI, Yasuharu p.27
28.
Voice User Interface
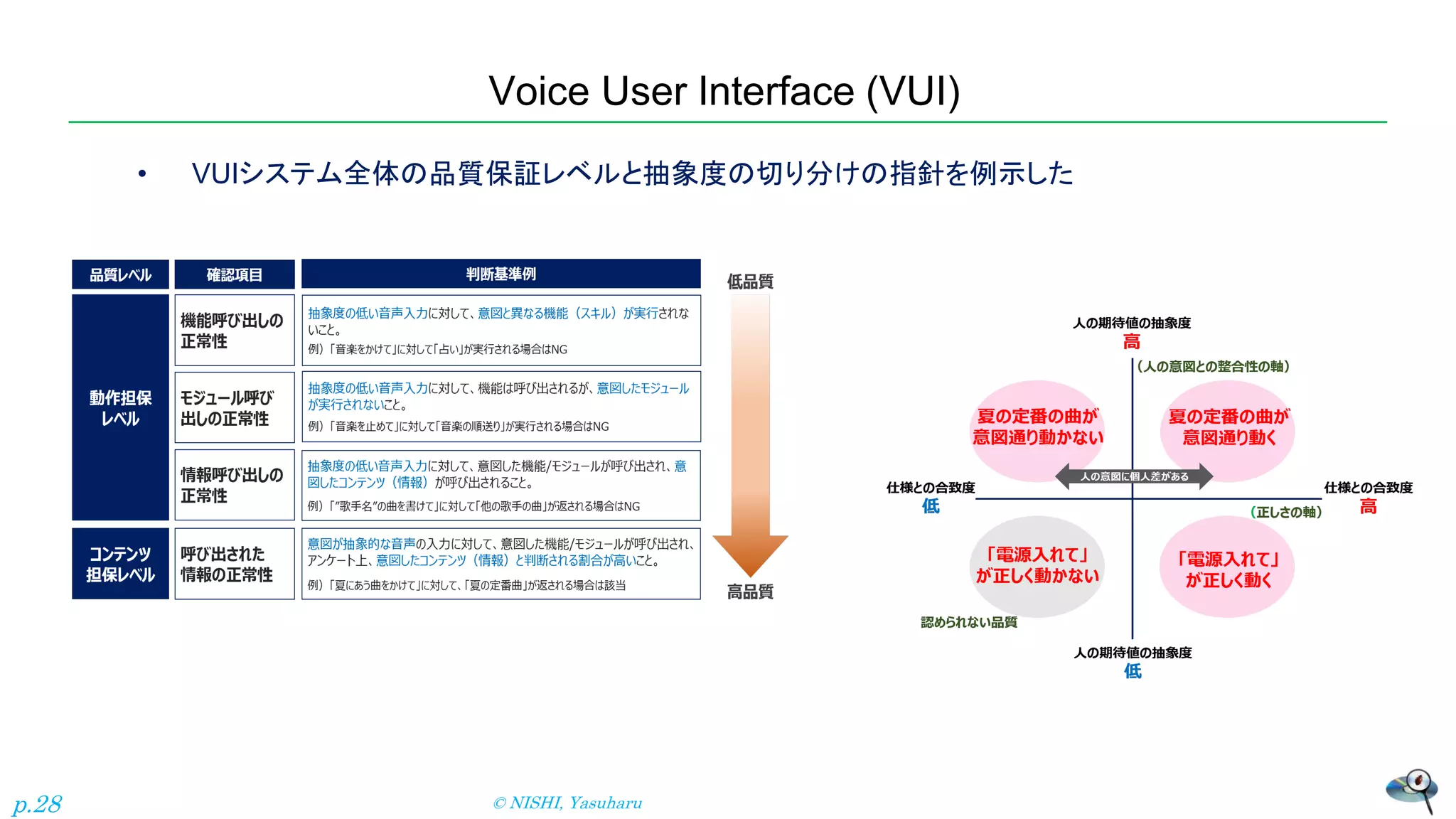
(VUI) • VUIシステム全体の品質保証レベルと抽象度の切り分けの指針を例示した © NISHI, Yasuharu p.28
29.
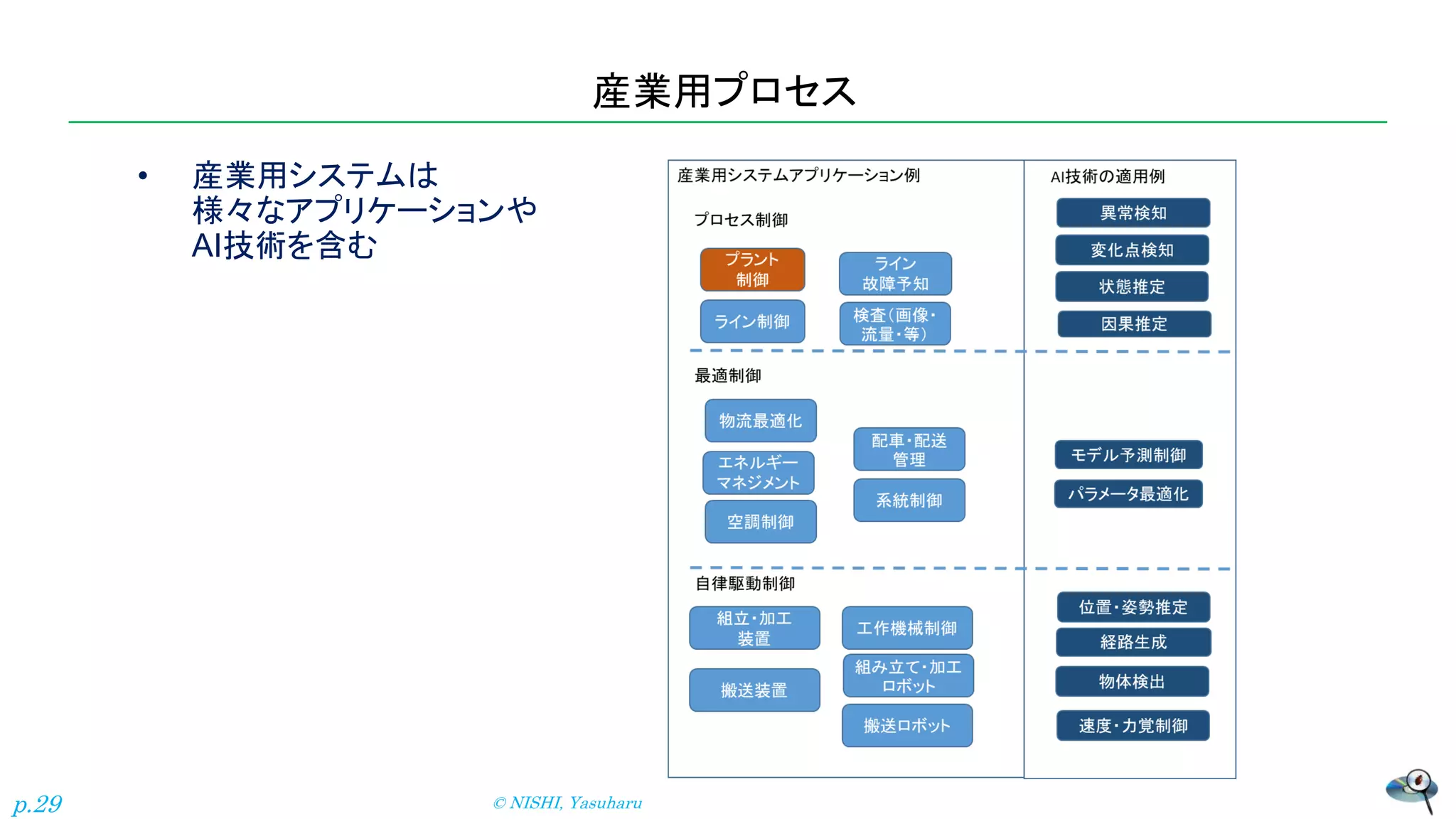
産業用プロセス • 産業用システムは 様々なアプリケーションや AI技術を含む © NISHI,
Yasuharu p.29
30.
産業用プロセス • 品質保証上の重点課題を検討した – ステークホルダー多様性 •
大規模・複雑なシステムであり 複数事業者が契約に基づいてサブシステムの構築・運用がなされる形態が多いため、 個々のデータの整合性や、権利保護、システム全体を検証する必要がある – 環境依存性 • システムは5M+E(Man、Machine、Material、Measurement、Method、Environment) の変化に晒されており、多様なデータや再現性の異なるデータを前提とした保証が必要である – 説明容易性 • システムが妥当であることを保証するプロセス・規格が複数存在し、 エンドユーザーへの説明責任と納得を引き出す必要がある © NISHI, Yasuharu p.30
31.
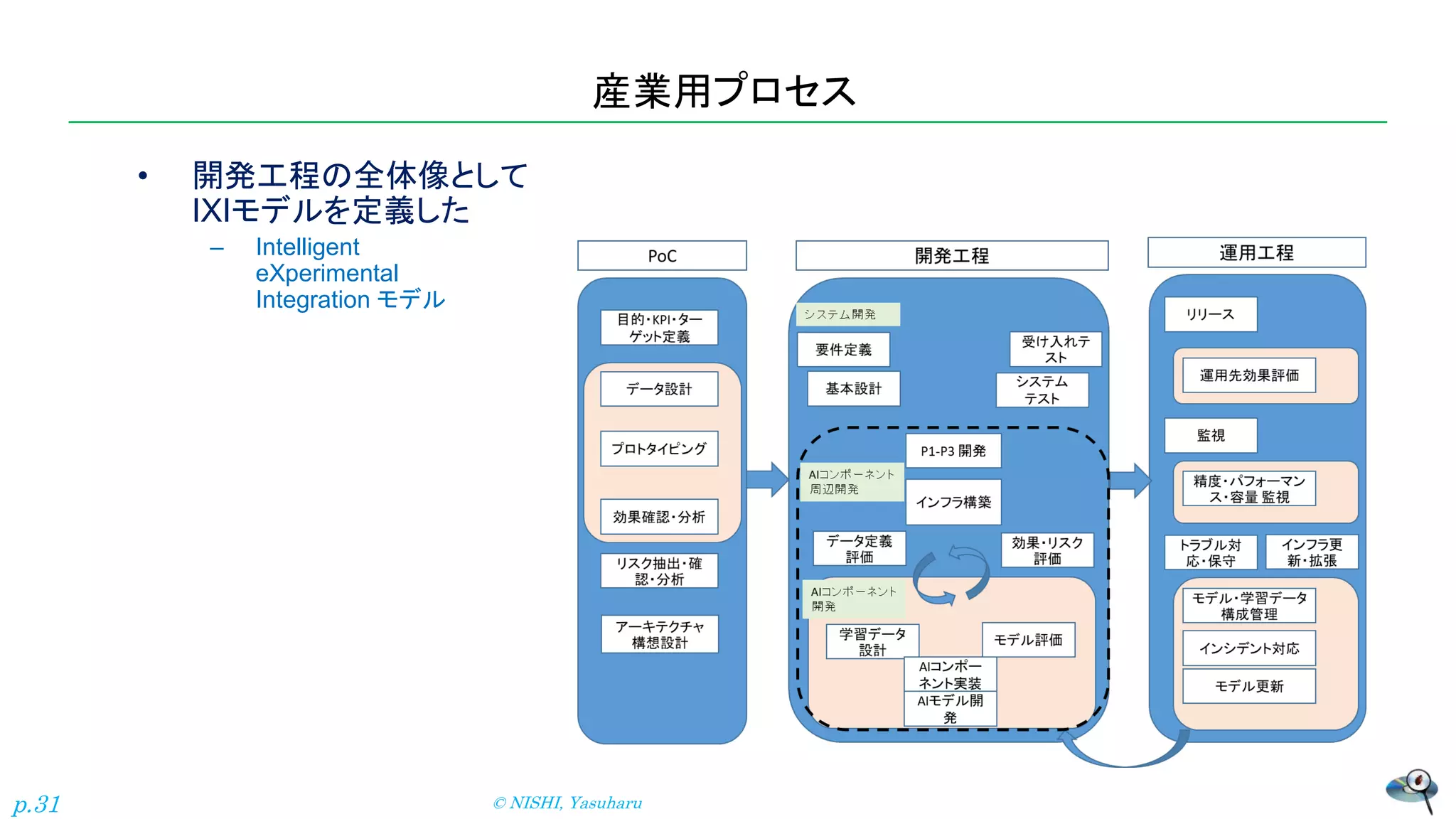
産業用プロセス • 開発工程の全体像として IXIモデルを定義した – Intelligent eXperimental Integration
モデル © NISHI, Yasuharu p.31
32.
産業用プロセス • IXIモデルに沿って課題を整理し、 工程ごとのバランスの違いを例示した 工程 PoC
開発 運用 目的 達成可能性、実現可能性を 確認し、多様なステークホル ダーと開発合意に至る PoC結果や開発中の結果に基 づき、環境依存性への保証事 項・方法を確立し、運用合意に 至る AIシステムを現場で動作し、性能 や発生事象を評価・対応し運用を 安定させる ス テ ー ク ホ ル ダー多様性 関係者との目標・リスク等の 合意とプロトタイプによる実証 インターフェース・API設計や、 データ一貫性への対応 現場運用要件・変更管理要件等 への対応 環境依存性 一部の環境条件に基づく目 標・リスク評価 システムが対象とする環境条 件の明確化と、システムの開 発・検証 仕様外の環境の監視とデータ収 集・評価 説明容易性 説明要件の洗い出しとシステ ム要件への反映 構成管理された環境依存デー タによるモデル評価やコード品 質の説明 事象発生時、性能変化時のデー タ・モデル・構成に基づく理由と対 応策の説明 © NISHI, Yasuharu p.32
33.
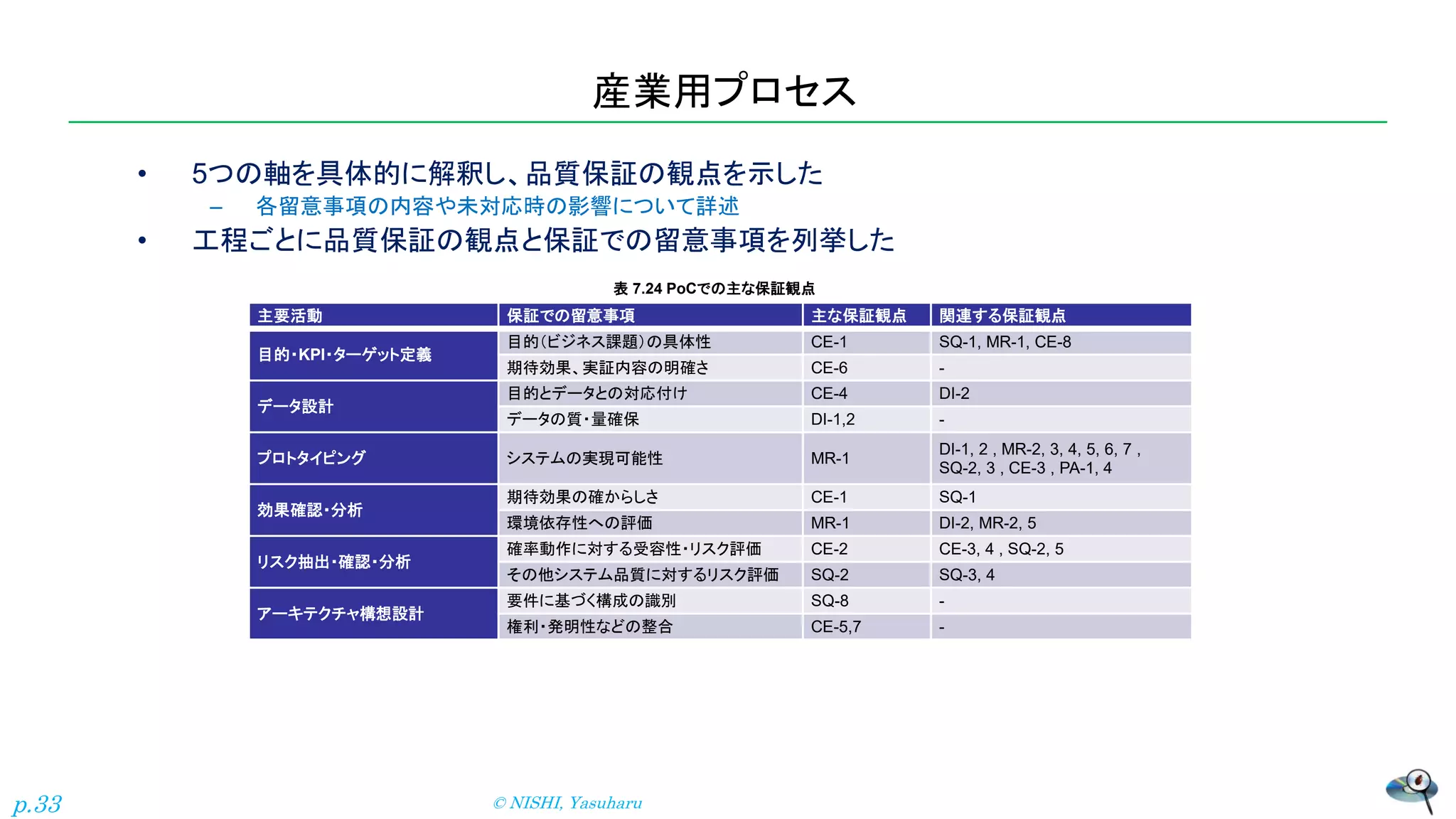
産業用プロセス • 5つの軸を具体的に解釈し、品質保証の観点を示した – 各留意事項の内容や未対応時の影響について詳述 •
工程ごとに品質保証の観点と保証での留意事項を列挙した 主要活動 保証での留意事項 主な保証観点 関連する保証観点 目的・KPI・ターゲット定義 目的(ビジネス課題)の具体性 CE-1 SQ-1, MR-1, CE-8 期待効果、実証内容の明確さ CE-6 - データ設計 目的とデータとの対応付け CE-4 DI-2 データの質・量確保 DI-1,2 - プロトタイピング システムの実現可能性 MR-1 DI-1, 2 , MR-2, 3, 4, 5, 6, 7 , SQ-2, 3 , CE-3 , PA-1, 4 効果確認・分析 期待効果の確からしさ CE-1 SQ-1 環境依存性への評価 MR-1 DI-2, MR-2, 5 リスク抽出・確認・分析 確率動作に対する受容性・リスク評価 CE-2 CE-3, 4 , SQ-2, 5 その他システム品質に対するリスク評価 SQ-2 SQ-3, 4 アーキテクチャ構想設計 要件に基づく構成の識別 SQ-8 - 権利・発明性などの整合 CE-5,7 - 表 7.24 PoCでの主な保証観点 © NISHI, Yasuharu p.33
34.
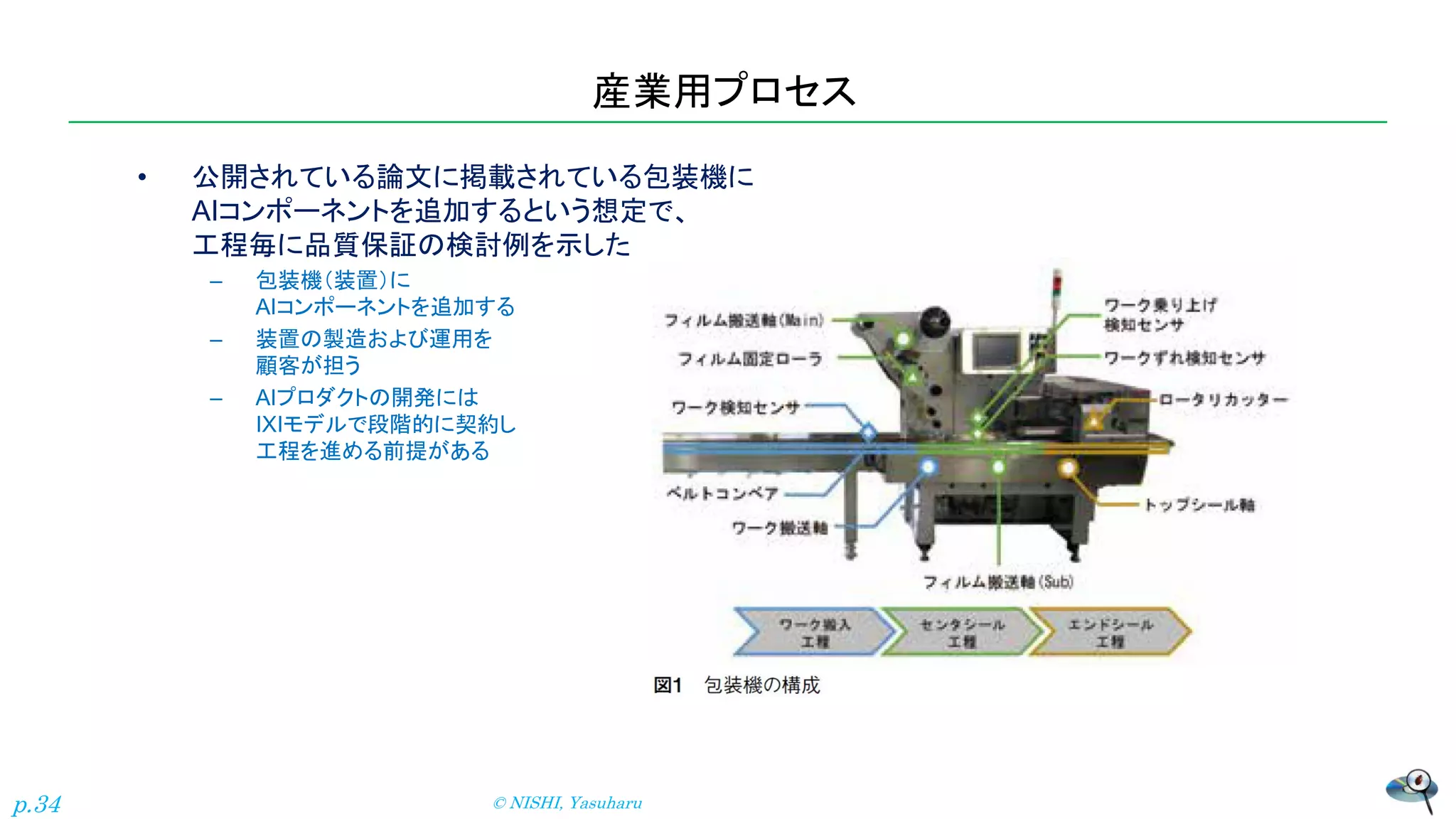
産業用プロセス • 公開されている論文に掲載されている包装機に AIコンポーネントを追加するという想定で、 工程毎に品質保証の検討例を示した – 包装機(装置)に AIコンポーネントを追加する –
装置の製造および運用を 顧客が担う – AIプロダクトの開発には IXIモデルで段階的に契約し 工程を進める前提がある © NISHI, Yasuharu p.34
35.
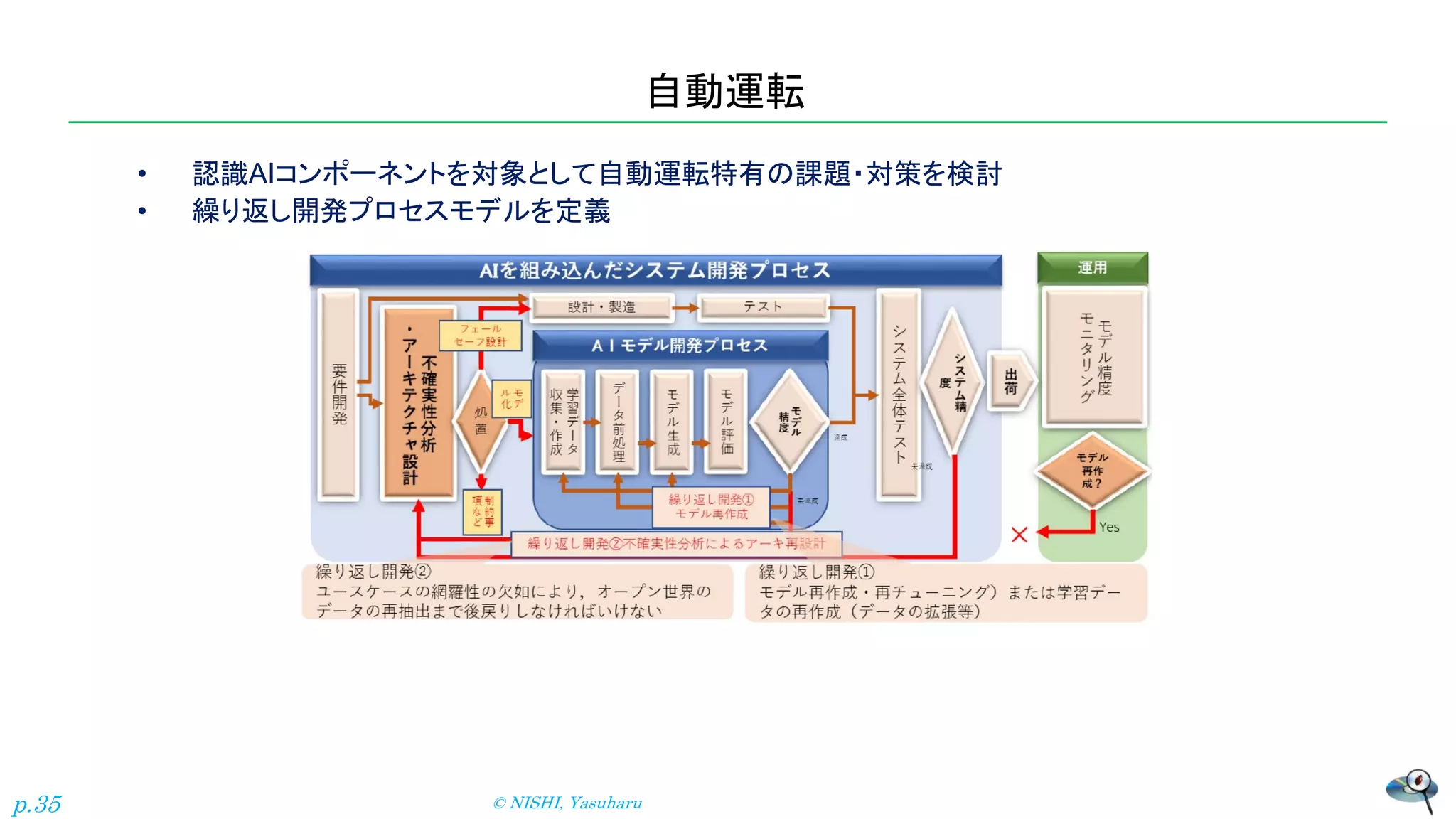
自動運転 • 認識AIコンポーネントを対象として自動運転特有の課題・対策を検討 • 繰り返し開発プロセスモデルを定義 ©
NISHI, Yasuharu p.35
36.
自動運転 © NISHI, Yasuharu p.36 •
自動ブレーキのシナリオを7つの不確実性に従って分類 – “Towards a Framework to Manage Perceptual Uncertainty for Safe Automated Driving” (K. Czarnecki and R. Salay, WAISE2018)より • F1: コンセプトに関する不確実性 – 自転車を押している人間は「歩行者」に含めるか? • F2: シナリオのカバレッジに関する不確実性 – 「歩行者」のパターン(特にUnknown unknowns)を 網羅できるか? • F3: シーンの不確実性 – 歩行者の重なりは考慮できるか? • F4: センサの特性による不確実性 • F5: ラベルの不確実性 • F6: (機械学習)モデルの不確実性 • F7: 運行領域における不確実性 – 開発時から変化すること、 開発時には想定・存在しないをどう考慮するか?
37.
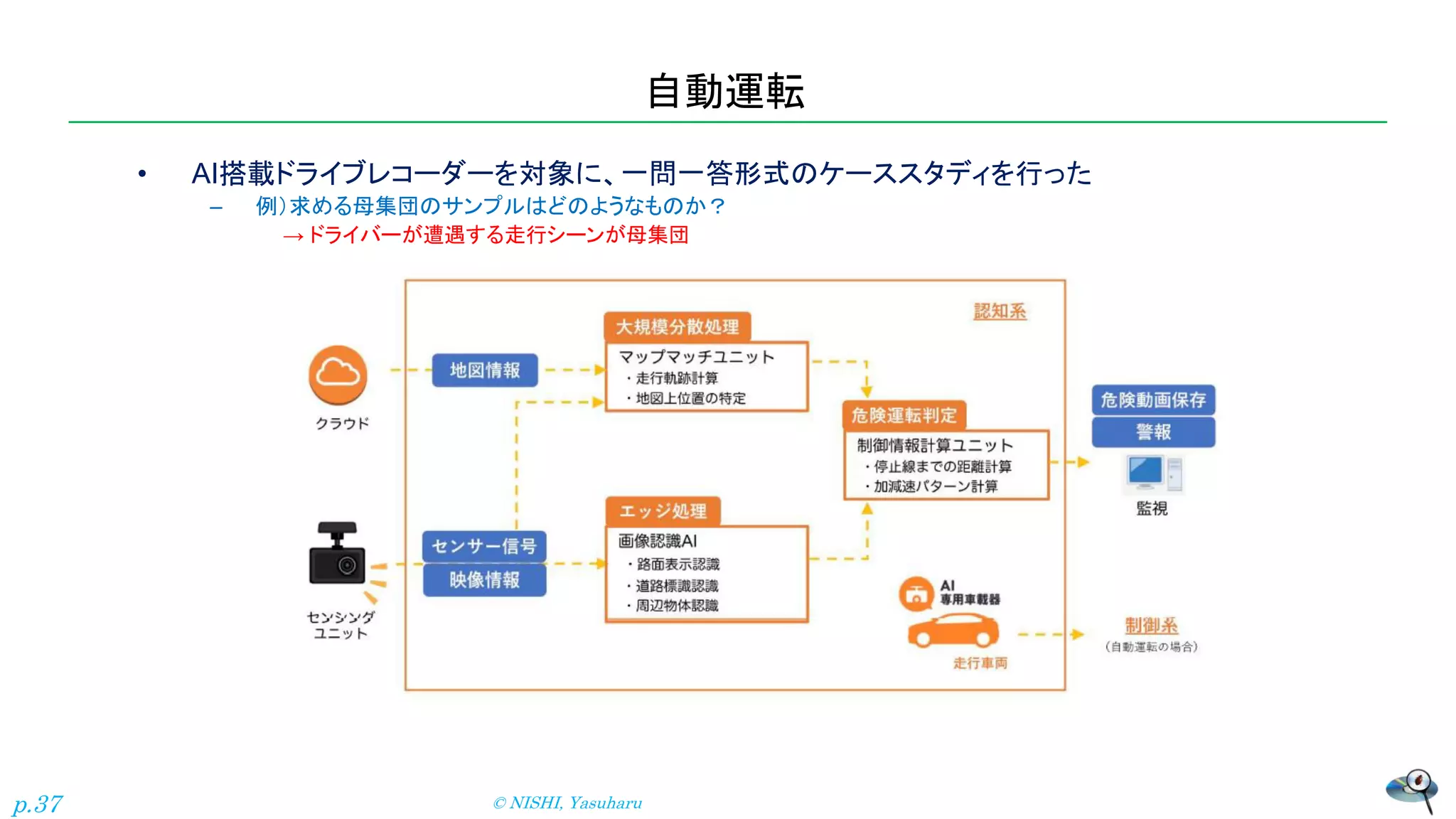
自動運転 • AI搭載ドライブレコーダーを対象に、一問一答形式のケーススタディを行った – 例)求める母集団のサンプルはどのようなものか? →
ドライバーが遭遇する走行シーンが母集団 © NISHI, Yasuharu p.37
38.
AI-OCR • AI-OCRとは – 機械学習を利用した光学文字認識技術である •
画像から文字を認識し、文字毎に文字コードへ変換する – 4つのモジュールから構成されることを想定している © NISHI, Yasuharu p.38
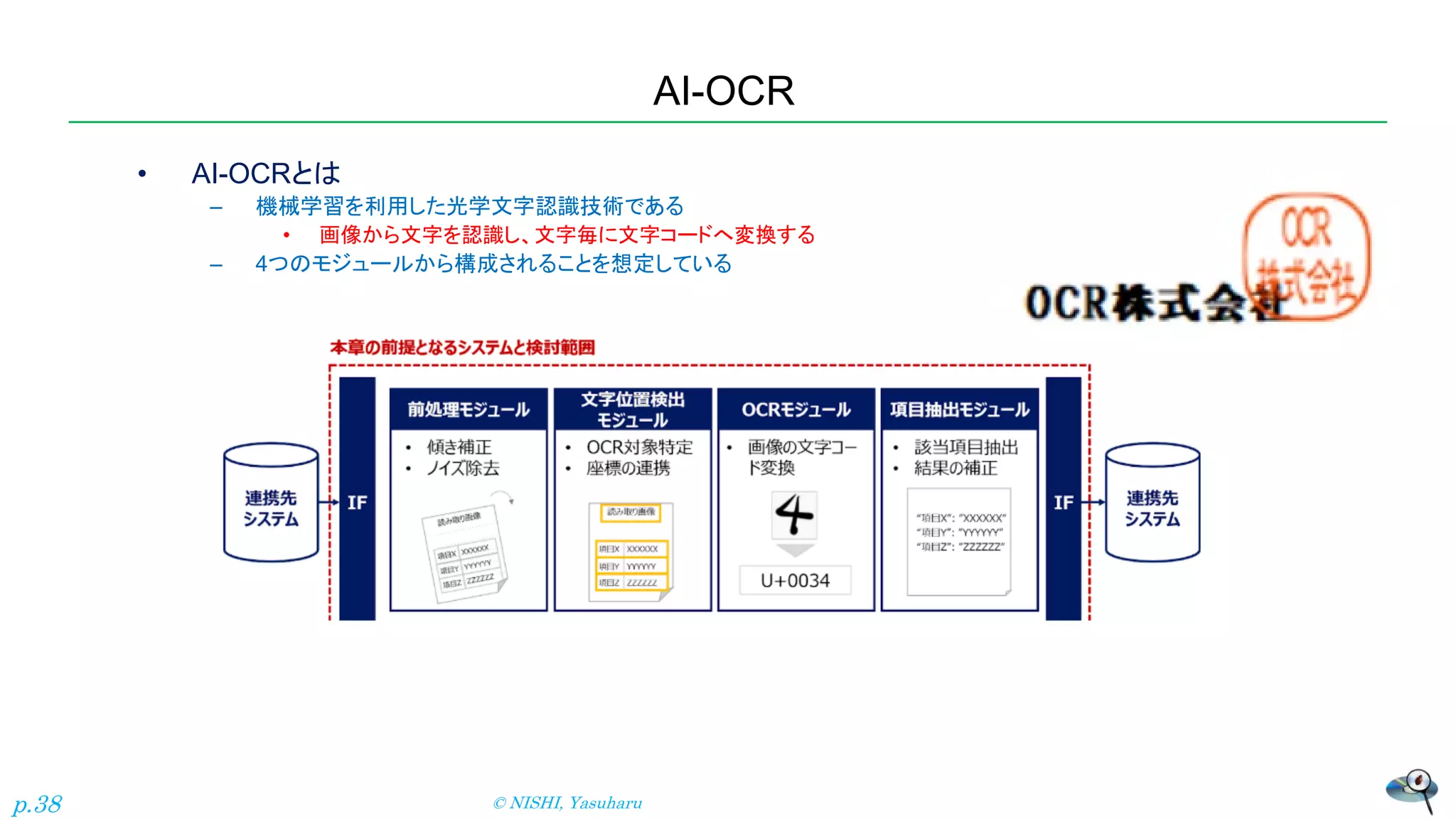
39.
AI-OCR • AI-OCR特有の課題と考慮すべき点を、5つの軸に沿ってまとめた – 例)Data
Integrity • レイアウト特性 – 定型/非定型、1画像に対する文字の量、表構造の有無、縦書き・横書きの構造、改ページの有無、 1up/2up 等の文書レイアウト • 文字特性 – 印字/手書き、文字の修飾(太字/イタリック/下線)、全角/半角、文字種(ひらがな/カタカナ/英字等)、 記号/環境依存文字、フォント(明朝体/ゴシック体等)、ロゴ、 林など複数の漢字で1つの漢字を構成しているもの • ノイズ特性 – 文字の滲み/レ点、光の反射、判子被り、二重取り消し線、背景の写りこみ、影の写り込み、画像の傾き、 複写禁止等の背景ノイズ • 画像特性 – 解像度(DPI)、画像サイズ、モノクロ/カラー、画像の明度/彩度 • メタモルフィックテスティングを適用したテスト設計を例示した – 例)AI 未搭載の従来OCR が不得意としていた認識パターンで誤認識が起きないかのテストを設計する • 項目欄の罫線と文字が重なったケースの認識精度が低いという認識パターンを抽出する • 罫線と文字が重なっていない帳票の認識結果と、罫線と文字を意図的に重ねた帳票の認識結果を比較する © NISHI, Yasuharu p.39
40.
AI-OCR • 項目抽出の対象となることが多い項目を「標準項目特性」として定義し、 帳票ごとに考慮すべき項目を「帳票特化項目特性」と定義した – 標準項目特性 •
合計金額(¥マークの有無、¥マークと金額間のスペース、金額背後の表記、カンマ区切り、ボックス区切り、 マイナス記号表記、ドル・ユーロなどの外貨表記、税抜き・税込みの記載、「百」「千」などのプレ印字、漢字記載) • 日付(西暦/和暦・ゼロ埋めあり/なし、年月日埋めの西暦、元号省略・英字省略和暦、元年表記和暦、 元号選択式、「元号」などのプレ印字) • 会社名(株式会社の表記、前株/後株表記、印鑑被り、支店名・店舗名) • 電話番号(TELの記載、10桁以上の連番、ハイフンあり、括弧あり、FAXの記載、代表番号、市外局番省略など8桁番号) – 帳票特化特性 • 請求書(FAXの利用による歪み/ノイズ、明細への情報の記載 - 明細行に合計の記載など、 複数ページ - 2ページ目以降のフォーマット違い、文字間隔の有無、文字の囲い、網掛けの有無) • アンケート(丸囲い式選択 – 対象全体か数値のみか、丸囲い項目に対してのチェック印、点線での囲い、チェックボックス、 フリー記述 - 複数行・はみ出し記載) • マイナンバー帳票(線による数値の区切り、4文字毎の太文字短径区切り、1文字ずつのボックス区切り、グレー背景、 氏名記入欄への「氏」「名」の記載) • 振込依頼書(振込金受領書の取り扱い、振込先金融機関名 – 選択式/同一枠内直列記載/並列記載/カンマ区切り、 預金種別 – 丸囲い/チェックボックス、口座番号 – 記号番号/5~6桁の古い番号、 住所 - 〒マークのプレ印字有無/電話番号のセット記入) • 帳票における明細行(枠線との被り、枠線の誤読、グループサプレス、線無し帳票、1セルに複数項目記載、値同士の接近、 キーブレイクごとの明細出力、明細の高さが可変) © NISHI, Yasuharu p.40
41.
AI-OCR • 推奨する品質評価レベルを示した © NISHI,
Yasuharu p.41
42.
XAI • 説明可能性・解釈性を付与する手法の分類を示した – 原(大阪大学)による分類 •
大域的な説明 – 複雑なブラックボックスモデルを、 可読性の高い説明可能なモデルで表現することで説明とする方法 • 局所的な説明 – 特定の入力に対するブラックボックスモデルの予測の 根拠を提示することで説明とする方法 • 説明可能なモデルの設計 – そもそも最初から可読性の高い説明可能なモデルを 作ってしまう方法 – 三菱電機による分類 • 説明可能性・解釈性を与える対象 – モデル自体に付与する(Global)か、個々の議論結果に対して付与する(Local)か • 説明可能性・解釈性を与えるタイミング – モデルの学習時にモデルの内部的な特性や仕組みに対して付与する(Intrinsic)か、 モデルの学習後に学習済みのモデルに対して付与する(Post-hoc)か • 説明可能性・解釈性を与える方法 – ルールベースか、特徴ベースか、インスタンスベースか • 説明可能性・解釈性を付与する代表的手法を紹介した – GLM/GAM、DT(決定木)、Surrogate、TCAV、Attention、Sensitivity Analysis、CAM、LIME © NISHI, Yasuharu p.42
43.
QA4AIガイドラインとAIQMガイドライン(産総研)の関係 • どちらもAI/機械学習の品質保証の考え方を産学で議論して得られた知見を まとめたものであり、それぞれに特徴があり、相互補完的な関係にある © NISHI,
Yasuharu p.43 QA4AIガイドライン AIQMガイドライン 正式名称 AIプロダクト品質保証ガイドライン 機械学習品質マネジメントガイドライン 作成主体 AIプロダクト品質保証コンソーシアム(QA4AI) 産総研、機械学習品質マネジメント検討委員会(AIQM) メンバー 大学/公的研究機関、企業研究者、企業実務者 大学/公的研究機関、企業研究者、企業実務者 特徴 プロダクトドメインの実務を想定した事例検討と 「5つの軸」による品質保証の考え方の整理 利用時品質、外部品質、内部品質の体系的な整理と 内部特性の要求レベルごとの要求事項の定義 整理体系 5つの軸ごとのチェックリスト 要求レベルごとの要求事項 内容 エンジニアリング観点で抽象的に記載 品質概念を包括的に示し必要とされるアクティビティを整理 事例 自動運転、産業用プロセス、コンテンツ生成、 Voice UI、AIOCR なし 代表的な 利用方法 実務的な品質確保ノウハウの獲得 体系的な品質マネジメントシステムの構築 今後 CCで公開、年1回のバージョンアップ 国際標準への提案 関連成果 なし 「機械学習システムの品質評価テストベッドα版」を公開
44.
QA4AIガイドラインとAIQMガイドライン(産総研)の関係 © NISHI, Yasuharu p.44 5つの軸 チェックリスト 外部品質特性
レベル リスク回避性 AI安全レベル (AISL) AIパフォーマン ス AIパフォーマン スレベル (AIPL) 公平性 AI公平性レベ ル (AIFL) 内部品質ごとの要求レベル 要求レベルごとの要求事項 一部対応 QA4AIガイドライン AIQMガイドライン
45.
代表的なテストの技術 – メタモルフィックテスティングとGANベーステスト •
AIに対するテストの代表的な目的は、 誤判別を引き起こしそうなデータを自動生成することである – 期待結果: – メタモルフィックテスティング:同じような期待結果を持つデータを(自動)生成する技術 – GANベーステスト:GAN(敵対的生成ネットワーク)によってデータを自動生成する技術 (テスト対象のAI vs. テスト用のAI) © NISHI, Yasuharu p.45 = ラーメン = ラーメン? = ラーメン? = ラーメン? = 全部ラーメン? http://img.cs.uec.ac.jp/pub/conf18/180715shimok2_0.pdf
46.
技術的な留意点 • 世の中には色んな専門家がいましてね... – 「メタモルフィックテスティングとニューロンカバレッジで大丈夫!」と言う専門家 →
銀の弾丸はありませんよ – ニューロンカバレッジやGANベーステストはまだ研究レベルである – メタモルフィックテスティングやGANベーステストは多様なテストを設計するには力不足な技術である – 自動化を駆使して実行系の工数を減らし、テストの全体像の設計に頭を使う時間を増やし、 テスト設計やテスト実行結果をビッグデータとして分析することで、 納得感の高いQAができるようになっていく – 「ミッションクリティカル系のAIはやはり厳密なプロセスこそ本質だ!」と言う専門家 → 時代は変わりました – そもそも帰納的開発だということを理解していない – 厳密なプロセスはしばしば思考停止と納得感の欠如、開発速度の低下を生んでしまう – 高度に自動化すると、エビデンス作成などプロセス監査のための作業も自動化できる – 銀の弾丸はありませんので、データサイエンスやML/DNNだけでなく QAもアーキテクチャ設計も要求分析も(自動化前提の)プロセスもすべて 「機械学習システム工学」として技術開発する必要がある – 開発もプロセスの意図を納得し、 QAも開発技術を理解し開発の中身をきちんと納得するようにならないといけない © NISHI, Yasuharu p.46
47.
技術的な留意点 • 世の中には色んな専門家がいましてね... – 「ML/DNNは100%なんて保証できないのに、顧客が分かってくれない!」と言う専門家 →
技術のせいにしないでください – もちろんML/DNNは原理的に100%にならない技術であるし、 伝統的ソフトウェアの顧客には理解しにくいのは事実である – でも本質的な原因は、 あなた方の話を聞いてもらえない関係性しかお客様と構築できない御用聞き体質なのですよ… – 「AIの品質保証 “だけ” を教えてくれればいいんです」と言う専門家 → 伝統的なソフトウェア開発における品質保証も数段レベルアップする必要があります – 高度に自動化された開発のQA(devOpsにおけるQA)や 機動的開発のQA(アジャイル開発におけるQA)、 きちんとした開発方法論によるQA(テスト観点モデルによる設計やテストアーキテクチャ設計)といった 演繹的開発におけるQAですら手が着いていない現場がとても多いのが、残念ながら現実である » 製造業では、伝統的開発(ファーム系や機能系)、アジャイル開発/devOps(Webアプリ系)、AI(研究開発)が バラバラで全く連携が取れていないどころか情報交換すらおぼつかないことがほとんどである – 演繹的開発においてプロセスやメトリクスといった間接指標を取り上げられた時に、 現場に感謝される「QAとしての技術」を持っている 品質保証組織やエンジニアはいったいどれくらいいるのだろうか? © NISHI, Yasuharu p.47
48.
技術的な留意点 • 世の中には色んな専門家がいましてね... – 「XAI(説明可能AI)があれば品質保証できるようになります」と言う専門家 →
「品質を保証するとは一体どういうことなのか?」という根源的な問いに真摯に向き合う必要があります – XAIはそれなりにAIの判断根拠を可視化するが、 何をどこまで可視化すれば品質を保証したことになるのか、までは教えてくれない – ML/DNNの特性により、これまでの実績による統計指標やプロセスを用いたQAはできなくなる – これからソフトウェアやSystem of Systems、AI、サービスなど一点ものがどんどん増えていく » ハードウェアでも一点ものの品質保証(ex. 機構設計のSystematic failureに関する品質保証)は実はとても難しい – 「AIとかソフトとか難しいことはともかく、我々の品質保証は足腰はものづくりだ」と言う専門家 → “生産だけに強く、分野や組織ごとにバラバラで丸投げな、自分たちの得意なことしかやらない全社QA” から脱する必要がある – 生産だけでなくメカエレケミオプトなどの設計、ソフト、AI、サービスなども 全て対象とする全社QMSを構築する必要があるだろう – これから製造業はソフトウェア化やサービス化が進んでいき、AIのような新しい技術がどんどん採り入れられ、 ハードウェア開発ですらアジャイルになっていく可能性があるので、 QAとしての技術開発をガンガンしなくてはならない時代に突入した » DX、IoT、Industrie4.0、AI、devOps、アジャイル開発などは個別の技術のカタログではなく 「次世代の製品開発」という技術パッケージなので、 「次世代の品質保証」を自分たちで創造していかなくてはならない © NISHI, Yasuharu p.48
49.
AIプロダクトの品質管理/品質保証の要点 • AIプロダクトの品質保証のための5つの原則をそれぞれ高めていく – データの質と(DNN/統計)モデルの質に関する知識や技術は絶対に必要である –
AIプロダクトの開発全体で品質の作り込みと保証を行っていく必要がある – 自動化を駆使し機動的で、納得感を共感できる開発や品質保証を行う必要がある – お客様に心から尊敬されるパートナーになり、お客様のビジネスを一緒に進めていけるようになろう • AIプロダクトの品質管理/品質保証をきちんと行おうとするなら、 (ソフトウェアの)伝統的な品質管理/品質保証活動もイマドキ化していく必要がある – AIプロダクトの品質管理/品質保証をきちんと行っていくためには、 アジャイル開発/DevOpsの品質管理/品質保証がきちんとできることが必要で、 それらは伝統的なソフトウェア開発の品質管理/品質保証がきちんとできることが必要である • 今までないがしろにされてきた「品質を保証するとは一体どういうことなのか?」という 根源的な問いに真摯に向き合う必要がある – アジャイル開発における品質管理/品質保証、品質管理/品質保証の高度な自動化、 ソフトウェア開発や品質管理/品質保証のデジタルエンジニアリング、ハードソフトAIサービスの統合TQMが必要になる © NISHI, Yasuharu p.49 品質管理/品質保証に携わる組織や専門家は どんどん研究開発・技術開発を進めていかなくてはならない
50.
AI・機械学習製品の品質保証におけるパラダイムシフト 【(悪い)演繹的開発】 シンプルなチェックリストやテスト条件の列挙と網羅 開発と品質保証に分離を伴う段階的保証 マネジメント指向による石橋を叩く予防行為 スナップショット的なユーザに焦点を合わせた品質保証 QAは研究開発しないという常識 伝統的な品質基準を盲信する姿勢 【(よい)帰納的開発】 膨大で複雑なドメインや人間心理・行動のモデリング 開発と品質保証の全員参加による高速な反復的保証 エンジニアリング指向によるスケールできるレジリエンス ダイナミックなユーザーや社会と協働する品質保証 QAも先端技術を研究開発するという常識 「品質とは何か」「保証とは何か」をずっと問い続ける姿勢 p.50 © NISHI,
Yasuharu → → → → → → →
51.
ぜひQA4AIコンソーシアムにご参画頂き、 一緒に議論していきましょう お問い合わせなどはこちらにお願いします qa4ai-query@qualab.jp http://www.qa4ai.jp/ p.51 © NISHI,
Yasuharu
Download


![AIの品質保証はまだ発展途上であり、体系化されておらず、各社で四苦八苦している
© NISHI, Yasuharu
p.3
https://twitter.com/_gyochan_/status/938240168078622720
"Why Should I Trust You?": Explaining the Predictions of Any Classifier, Ribeiro et al, KDD2016
arXiv:1707.08945 [cs.CR]](https://image.slidesharecdn.com/paradigmshiftsinqaforaiproducts-211129080533/75/Paradigm-shifts-in-QA-for-AI-products-3-2048.jpg)


















































































![ICLR'19 読み会 in 京都 [LT枠] AIプロダクト品質保証ガイドラインの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/ltqa4ai20190602up-190530083654-thumbnail.jpg?width=640&height=640&fit=bounds)












