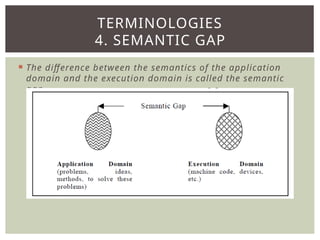
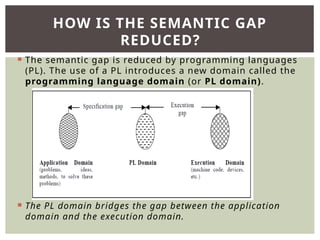
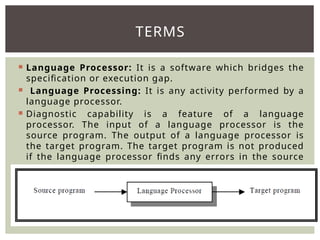
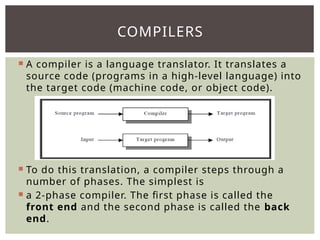
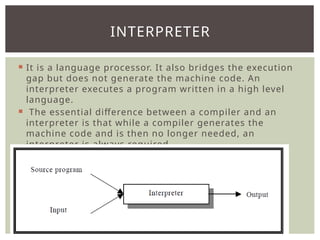
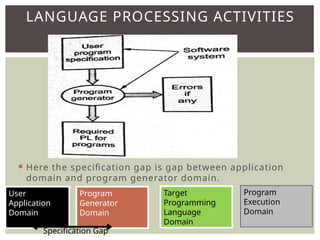
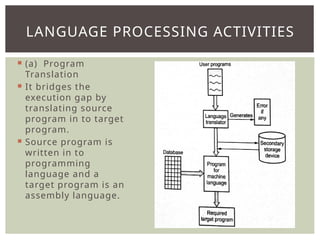
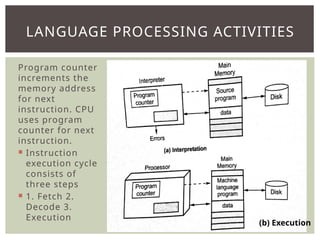
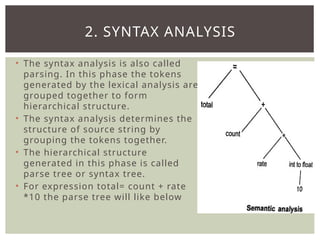
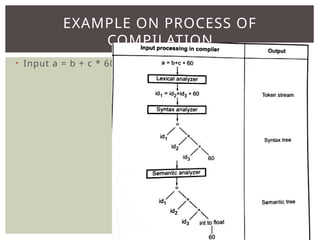
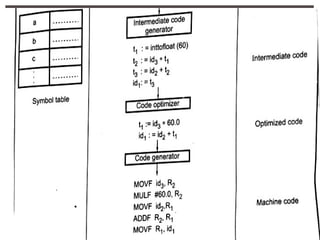
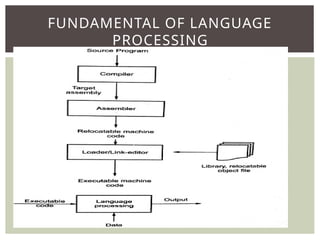
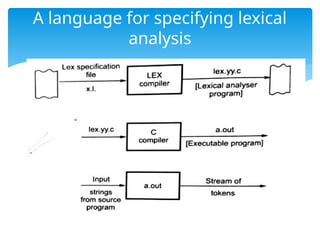
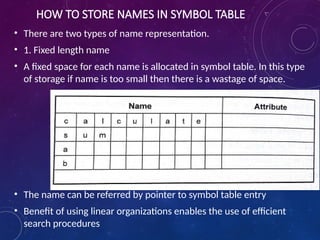
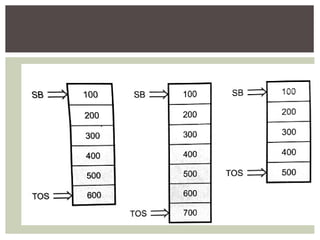
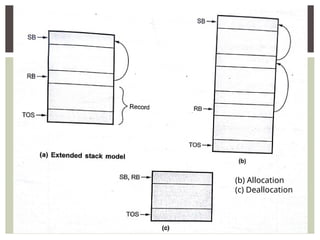
The document provides an overview of language processors, including the roles of compilers, assemblers, and interpreters in translating programming languages into machine-level instructions. It discusses the concepts of application and execution domains, semantics, and the semantic gap, emphasizing how programming languages help bridge these gaps to improve software quality and development efficiency. Additionally, it outlines the phases of language processing, including lexical analysis, syntax analysis, semantic analysis, and code generation, along with the importance of a symbol table for managing identifiers and their attributes.




















































![LEX specification and features
REGULAR
EXPRESSION
MEANING
* Matching with zero or more occurrences of
preceding expression. For example, 1*
occurrence of 1 for any number of times
. Matches any single character other than new
line
[ ] A character class which matches with any
character within the bracket.
For example: [a-z] matches with any alphabet
in lower case.
( ) Group of regular expressions together put in
to a new regular expression
r[m,n] m to n occurrence of r example : a[3,5]](https://image.slidesharecdn.com/chapter2sp-1-250105184546-5cbe3c11/85/Overview-of-language-processor-course-d-a-66-320.jpg)
![LEX specification and features
REGULAR
EXPRESSION
MEANING
$ Matches with the end of line as last character.
+ Matches with one or more occurrence of
preceding expression.
Example: [0-9]+ any number but not empty
string
? Matches zero or one occurrence of preceding
regular expression. For example [+-]? [0-9]+ a
number with unary operator
^ Matching the beginning of a line as first
character.
[ ^S ] Used as for negation. Any character except S.
For example [^verb] means except verb match
with anything else
Used as escape meta character](https://image.slidesharecdn.com/chapter2sp-1-250105184546-5cbe3c11/85/Overview-of-language-processor-course-d-a-67-320.jpg)











































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)

![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)



![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











