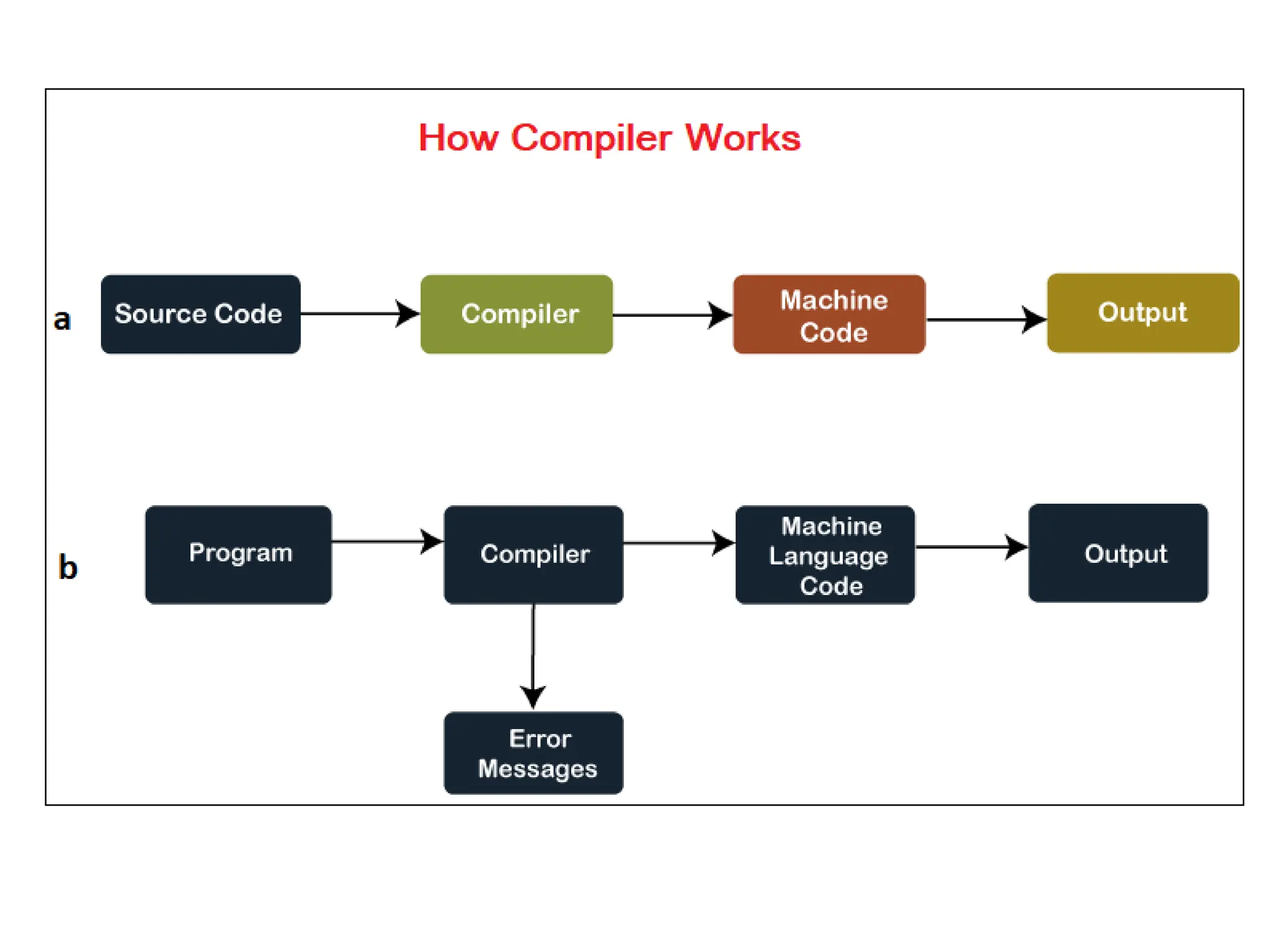
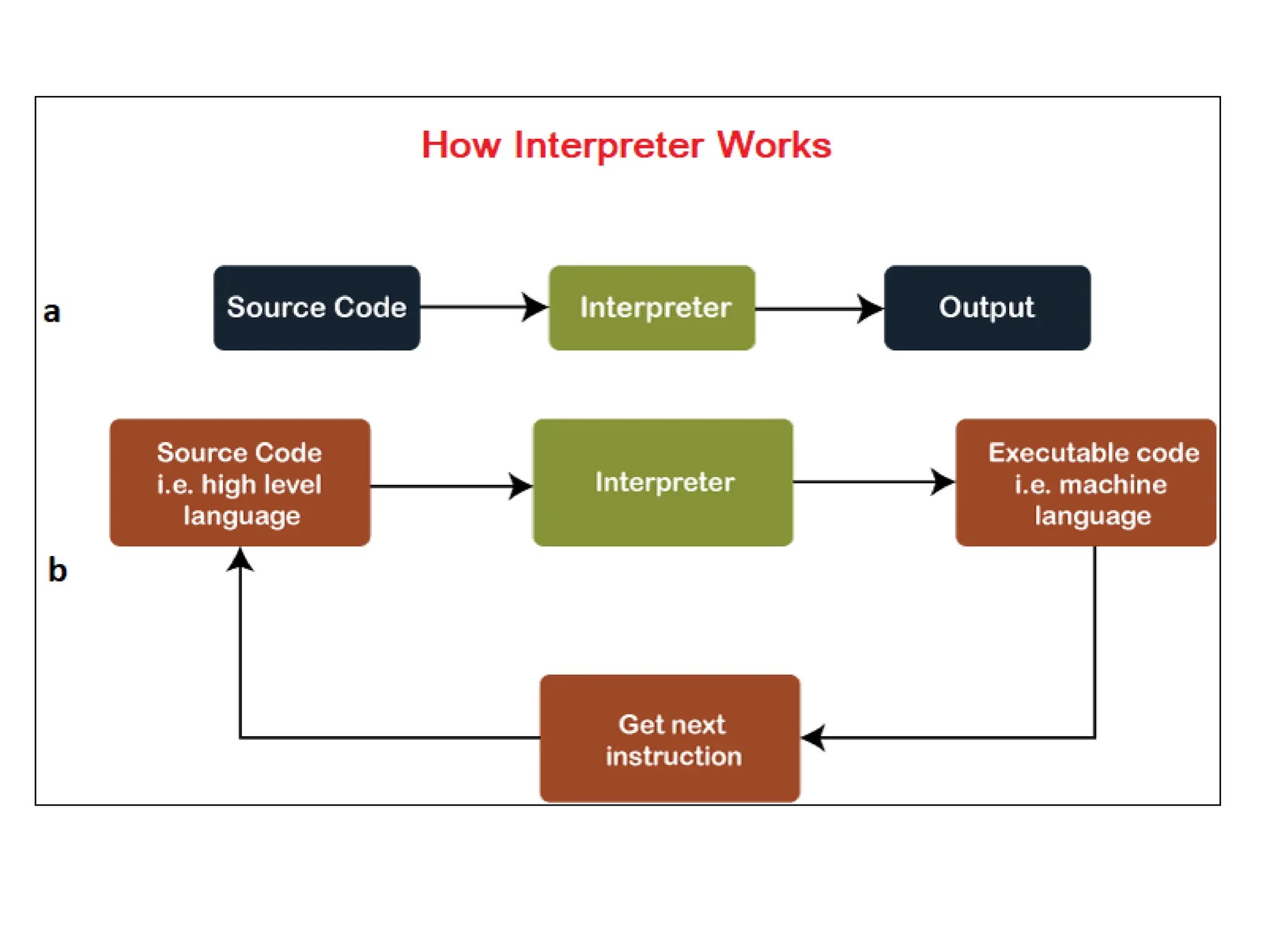
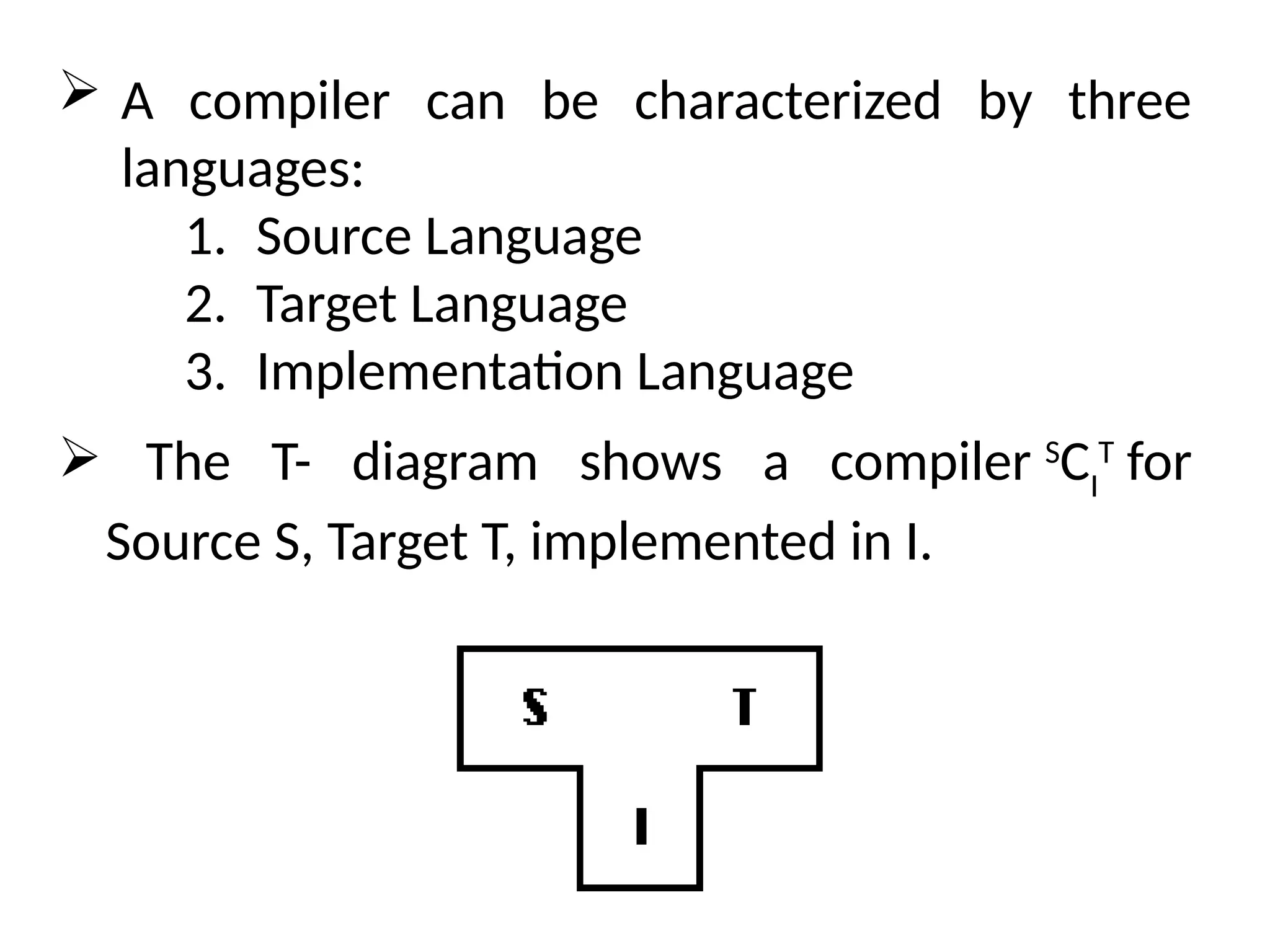
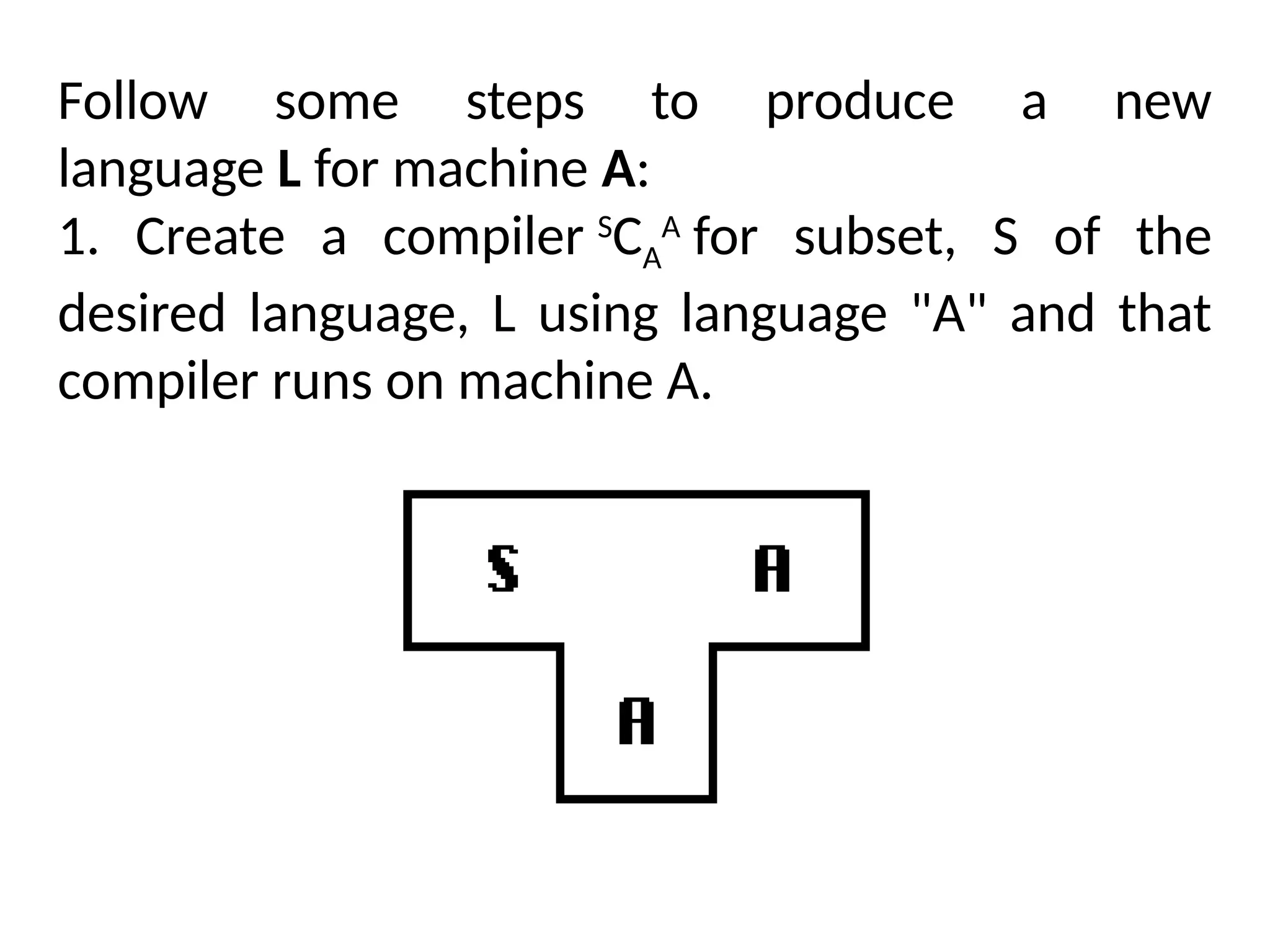
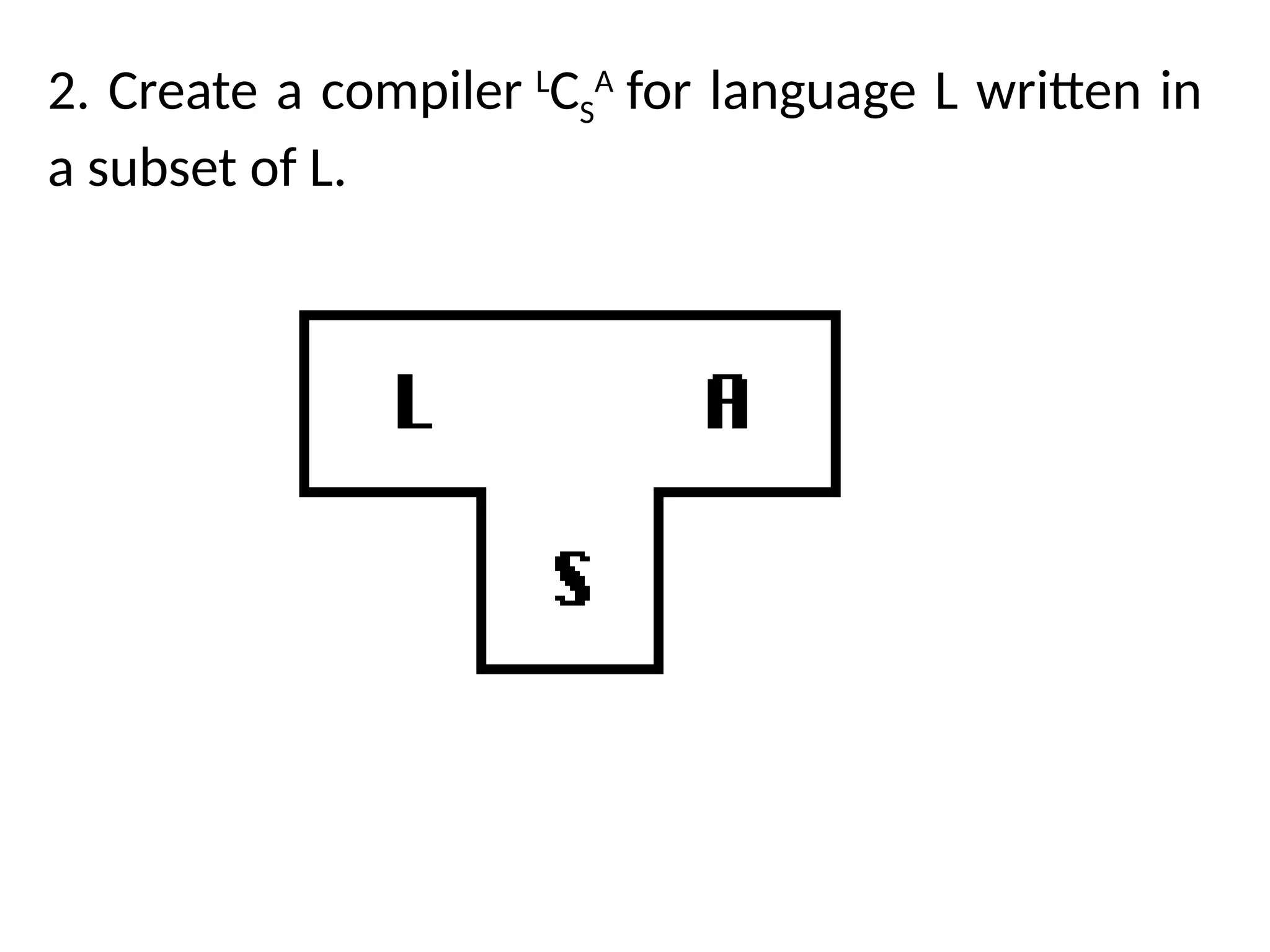
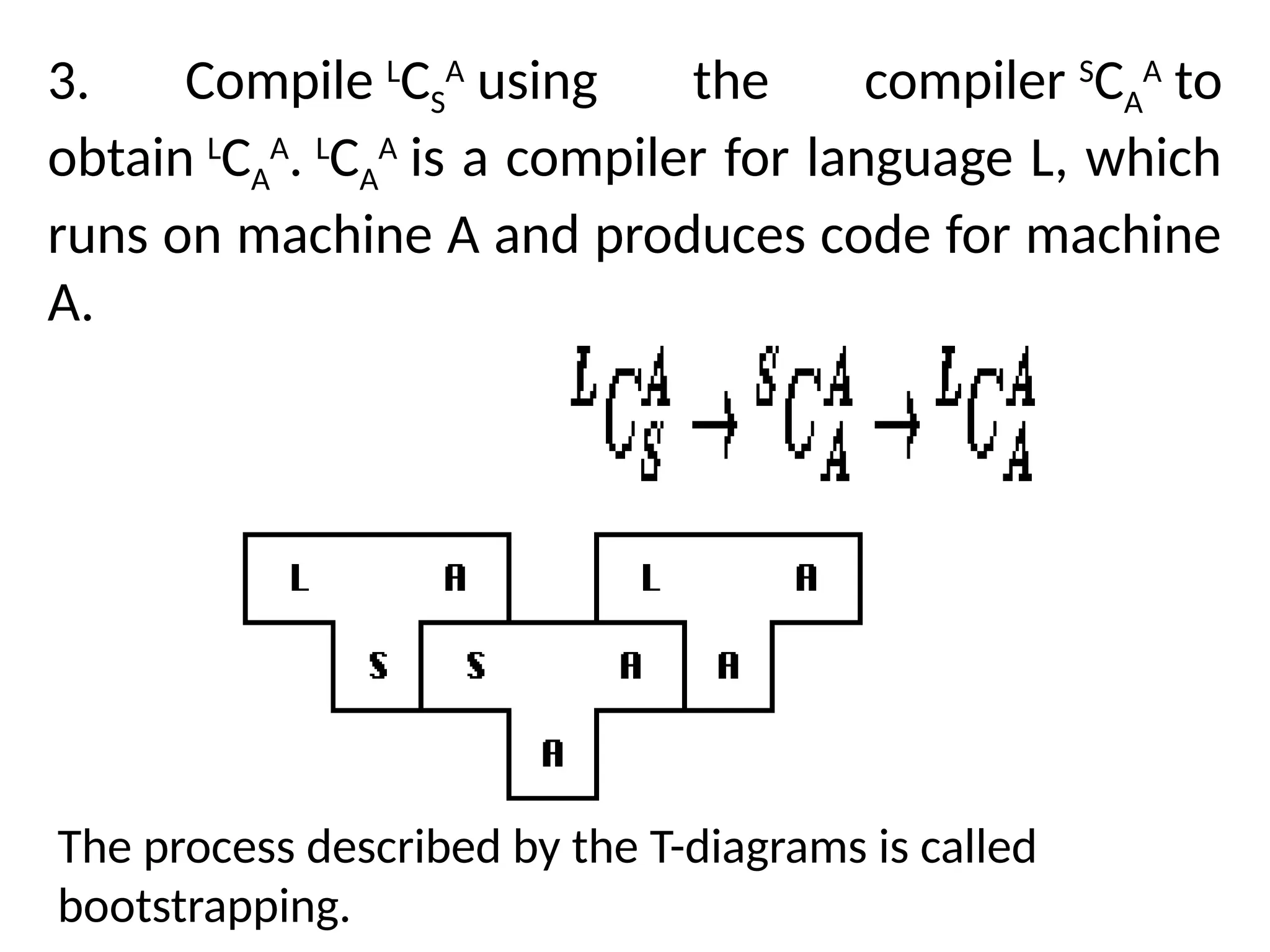
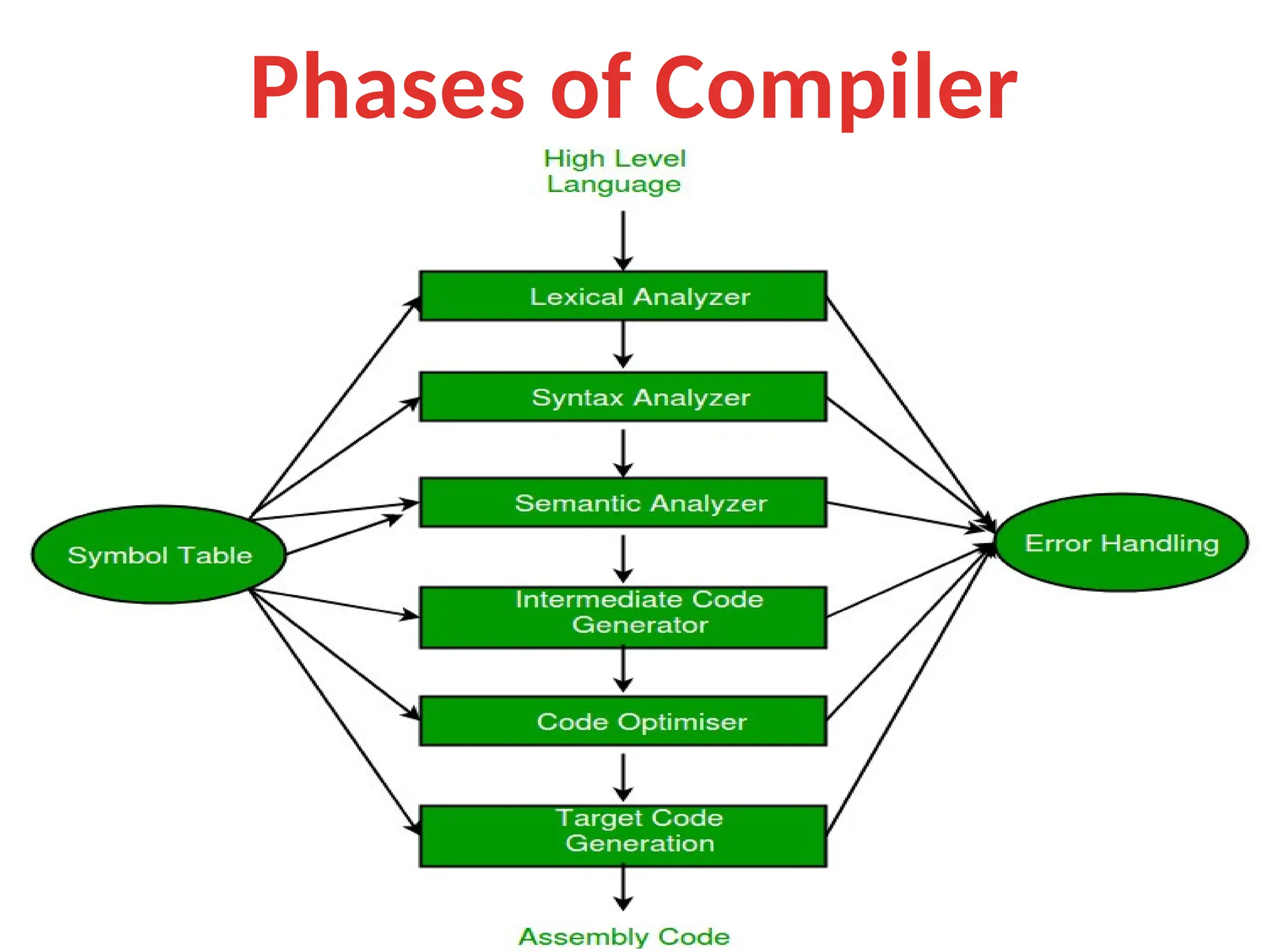
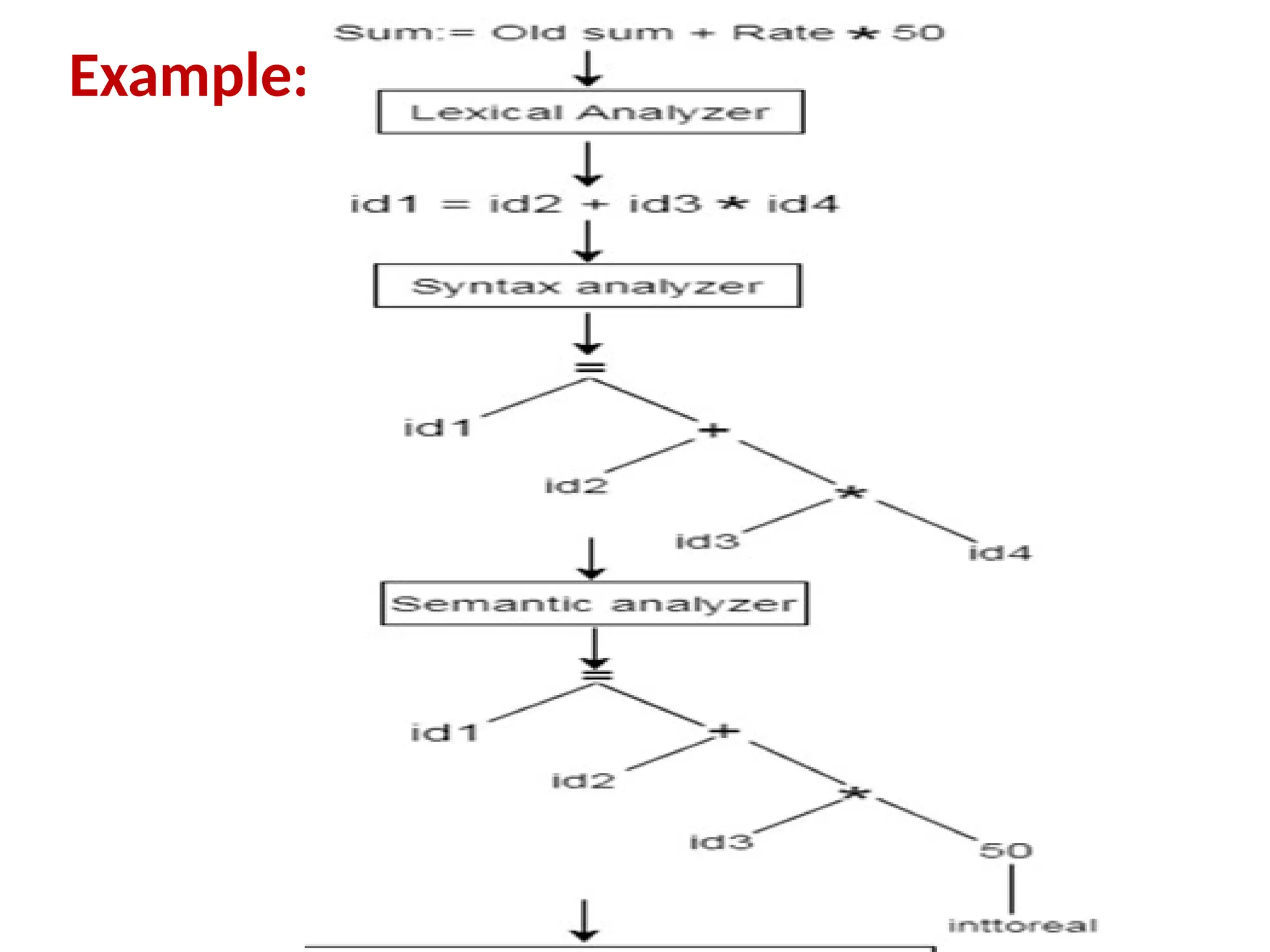
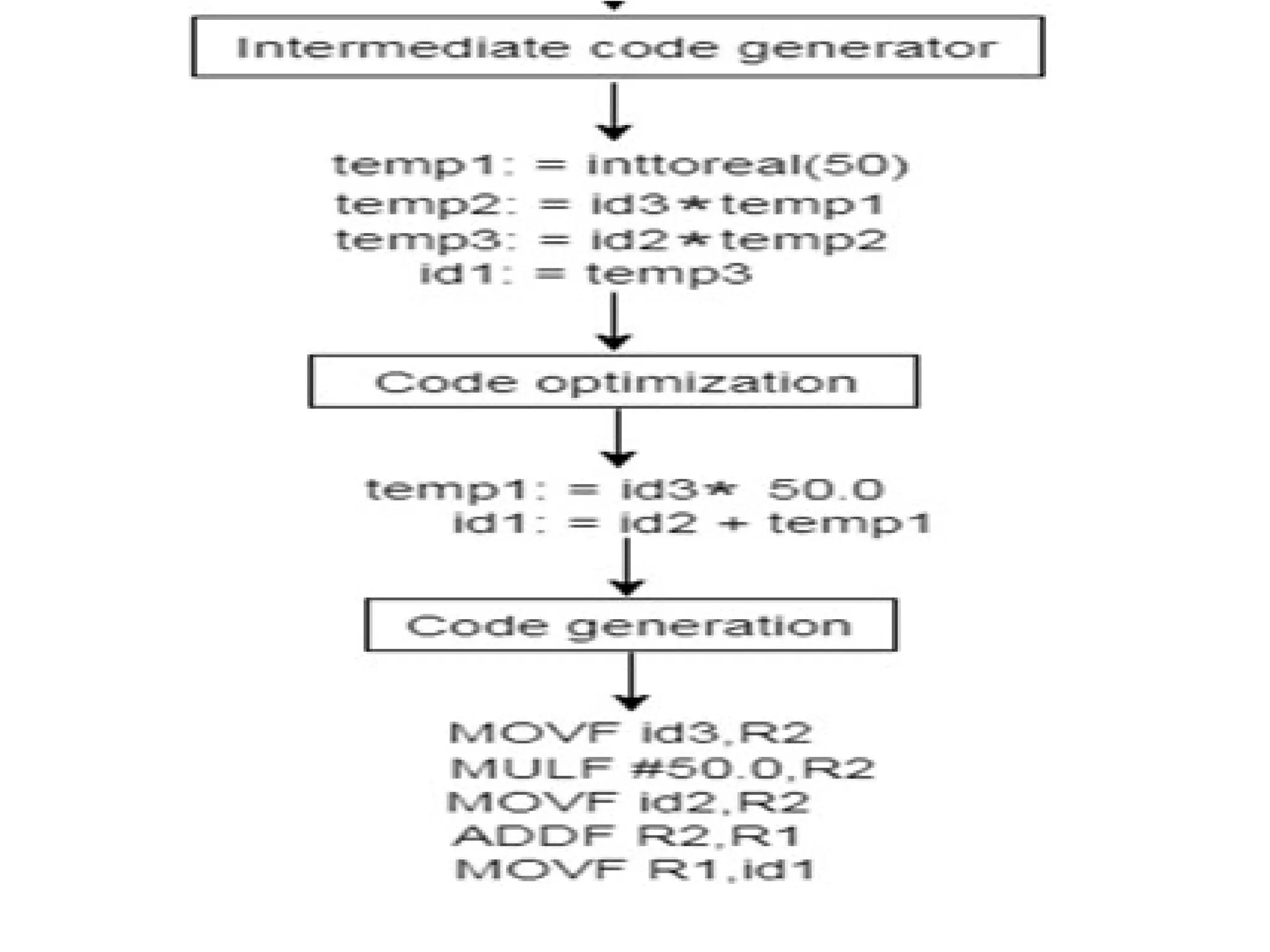
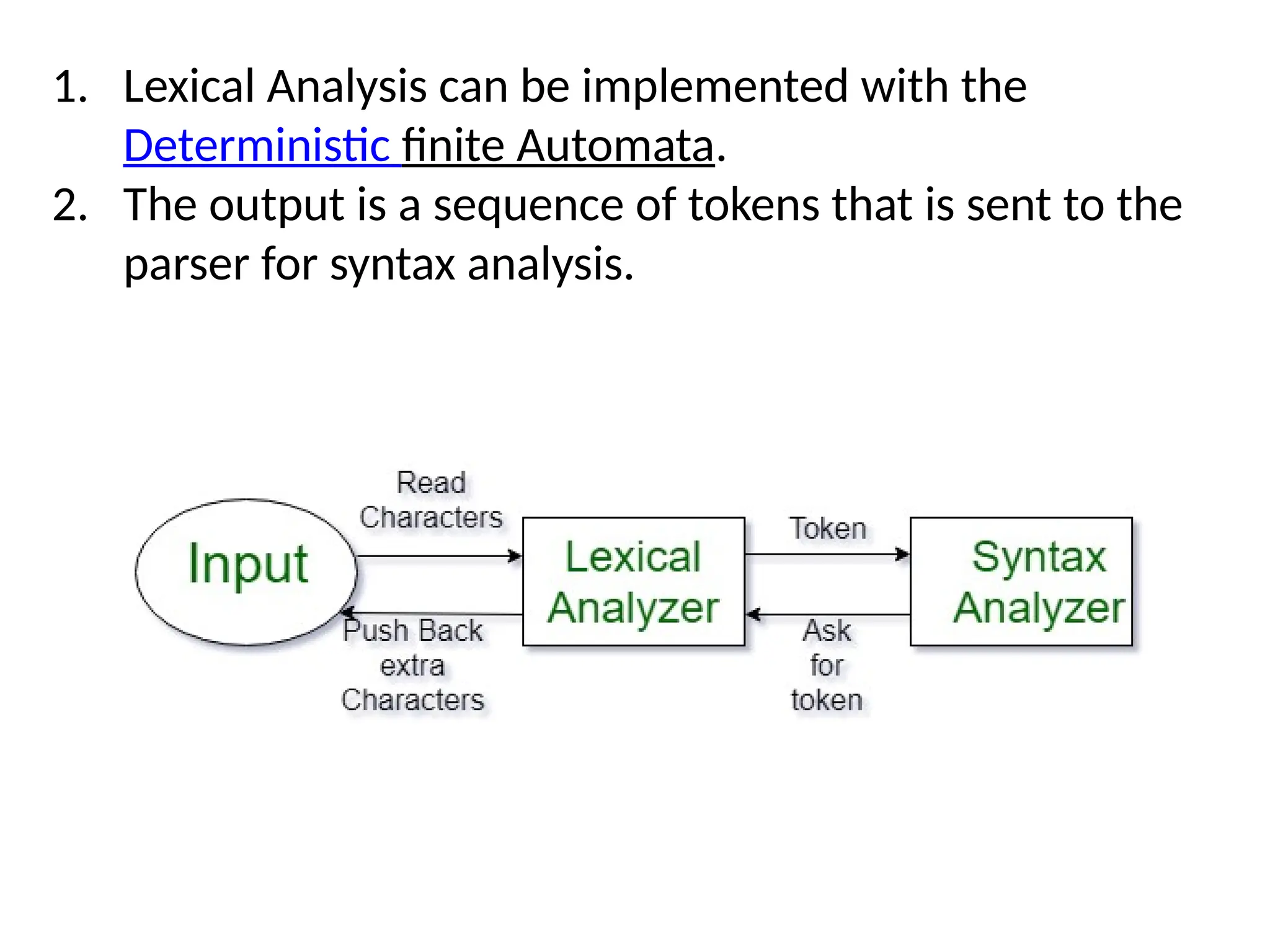
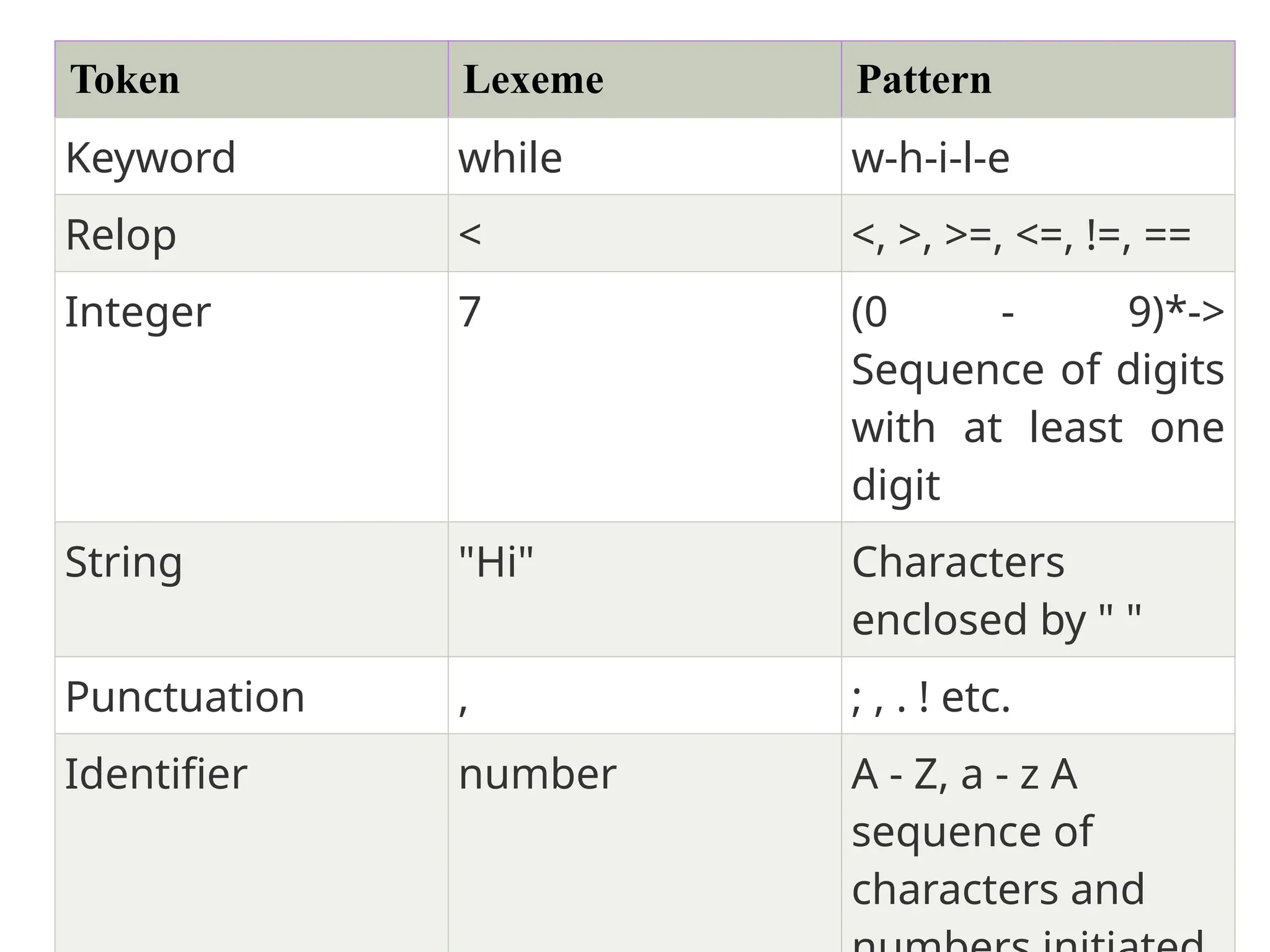
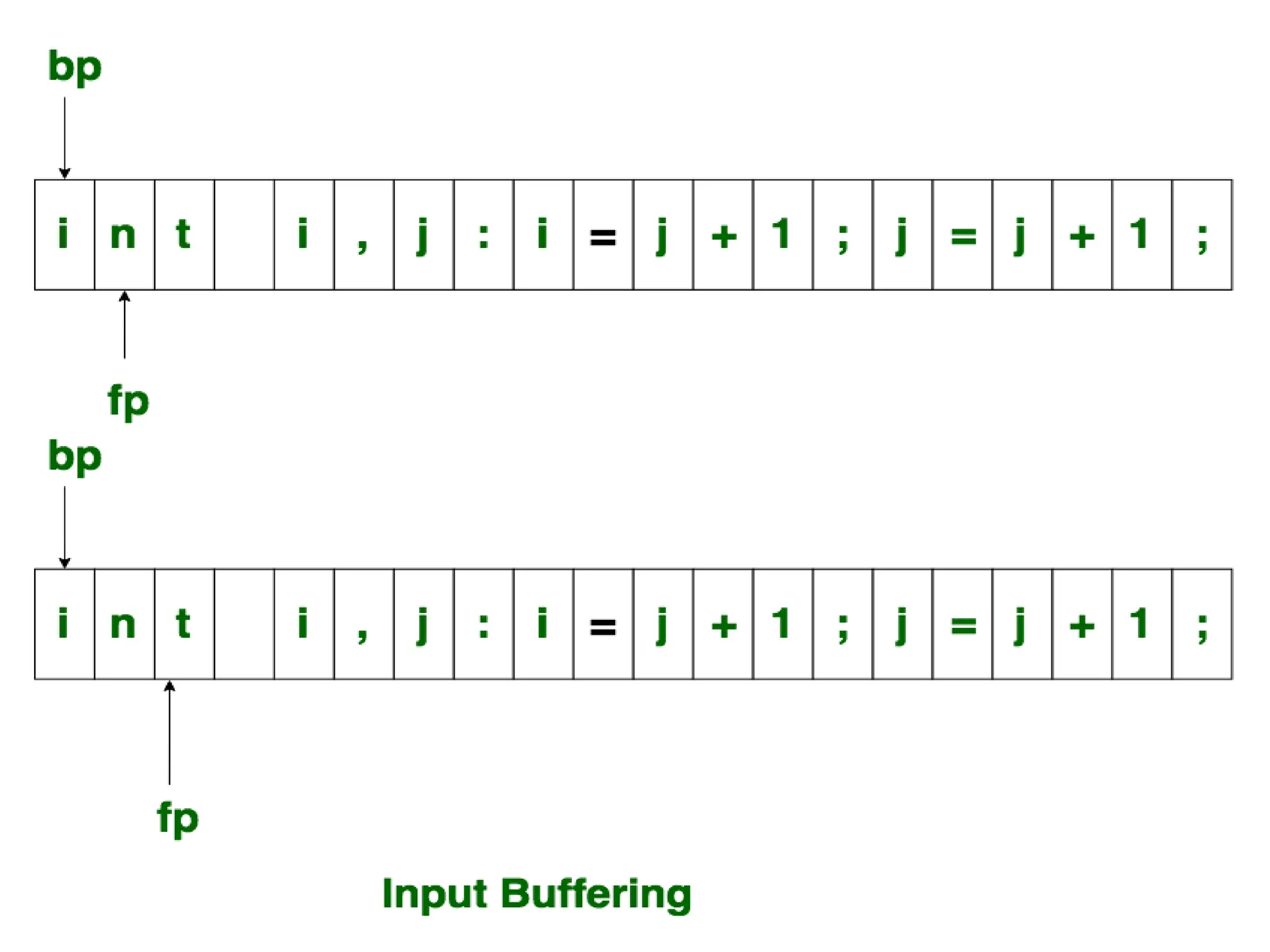
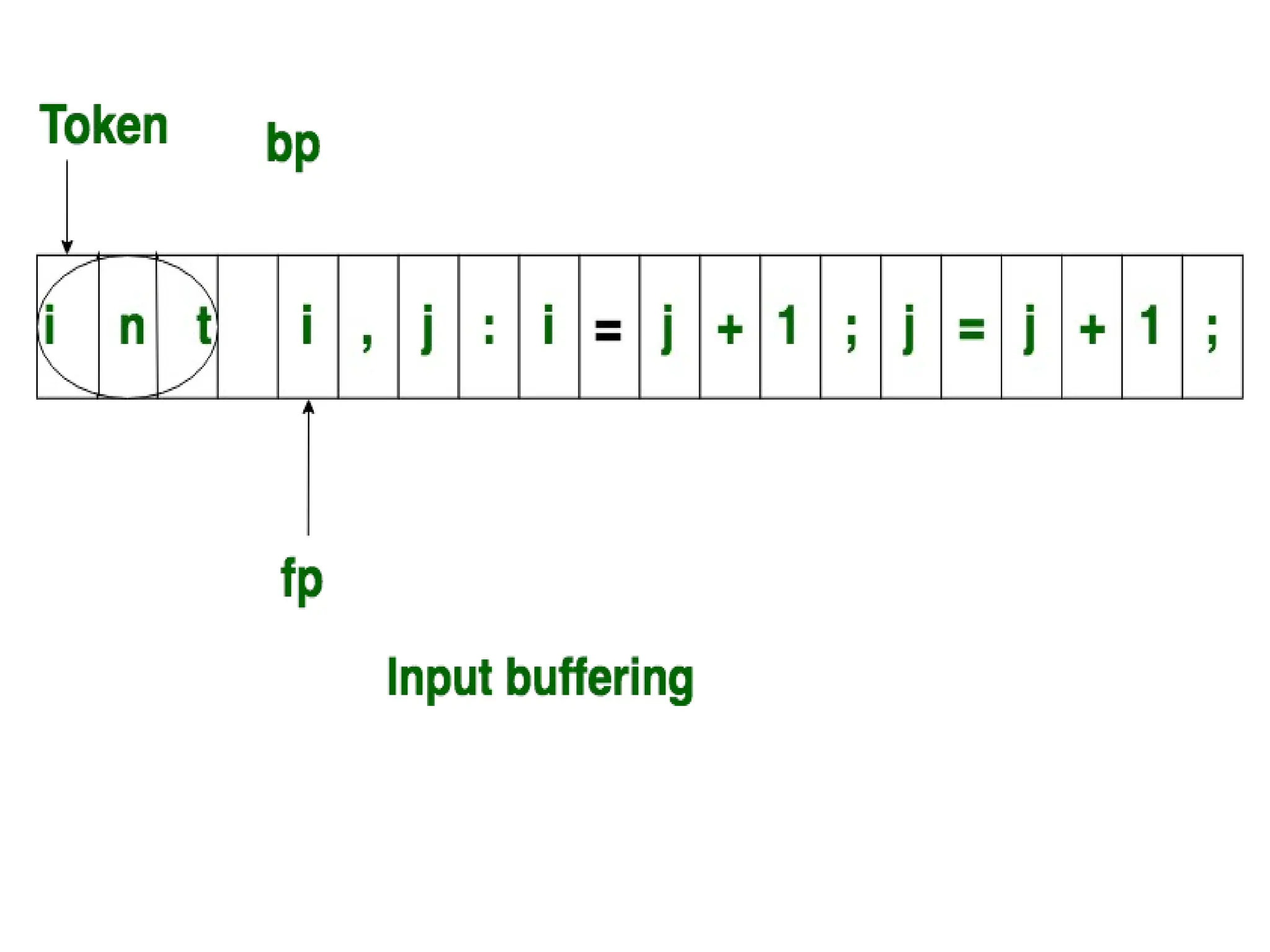
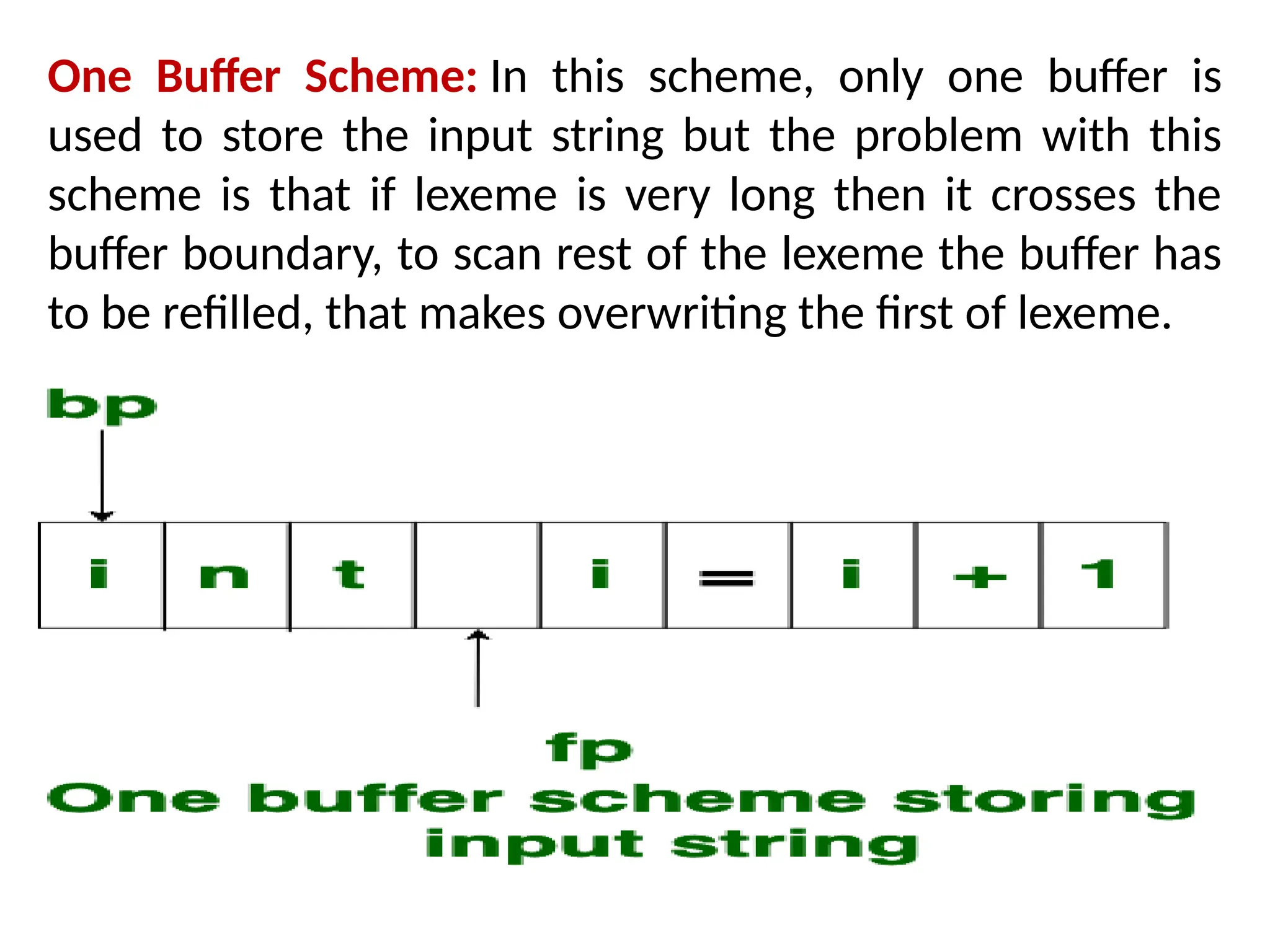
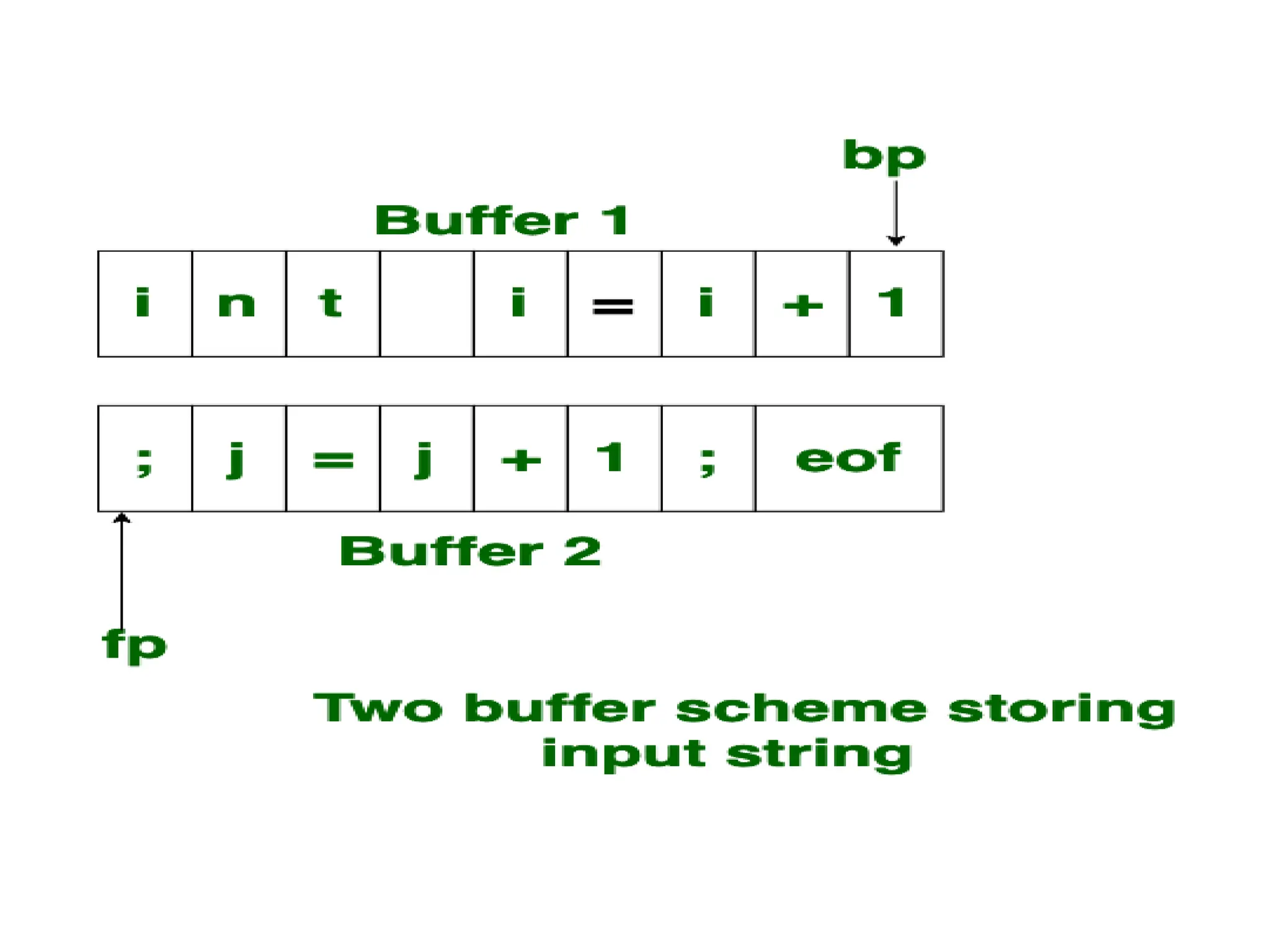
The document provides a comprehensive overview of compiler design, detailing the functions and phases of a compiler, including lexical analysis, syntax analysis, semantic analysis, and code generation. It also highlights the differences between compilers and interpreters, discussing aspects such as error detection, execution time, and the advantages of using compilers for high-level programming languages. Furthermore, concepts like bootstrapping and input buffering are explained, along with the specifications of tokens and their operations.





































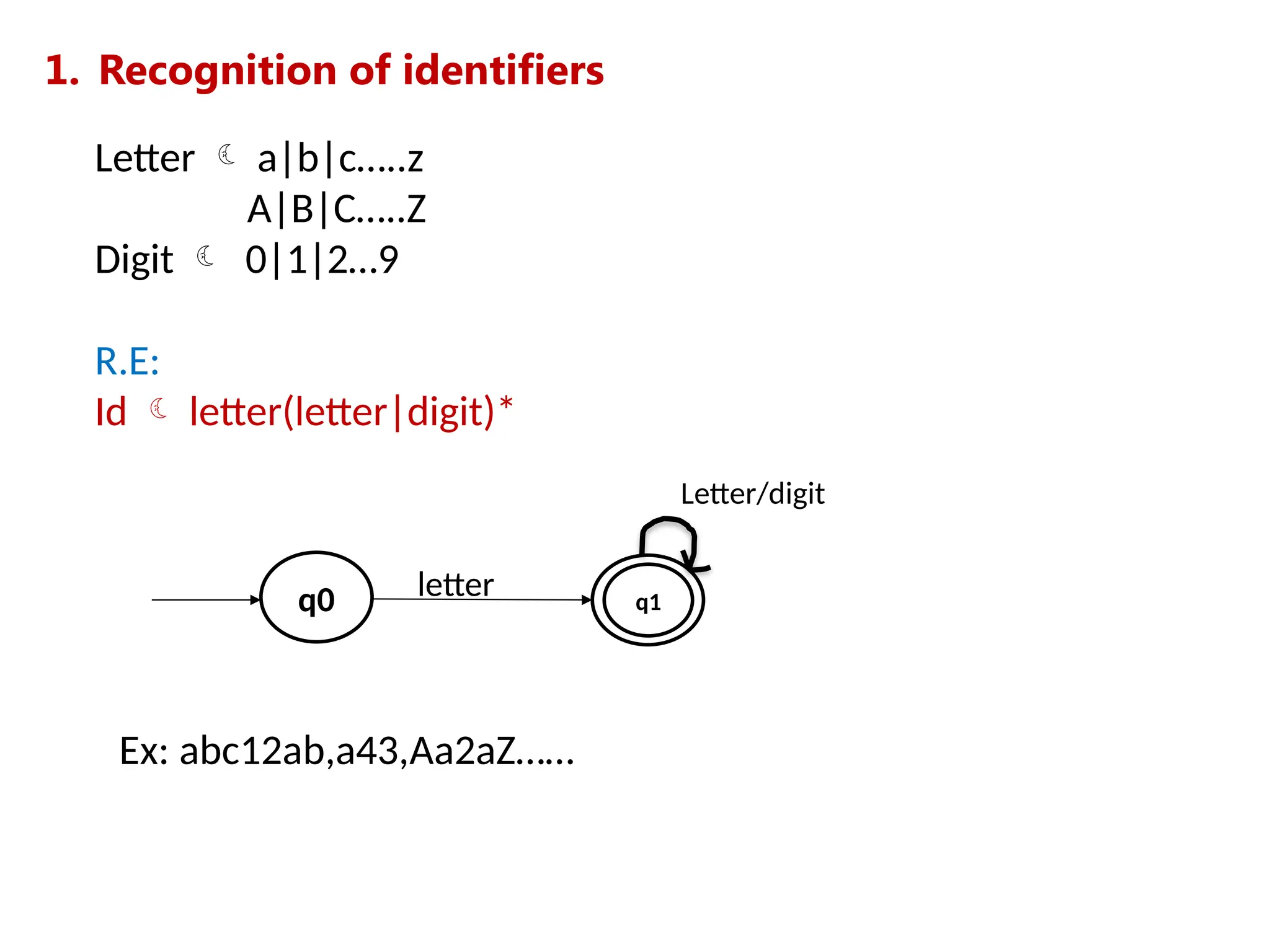
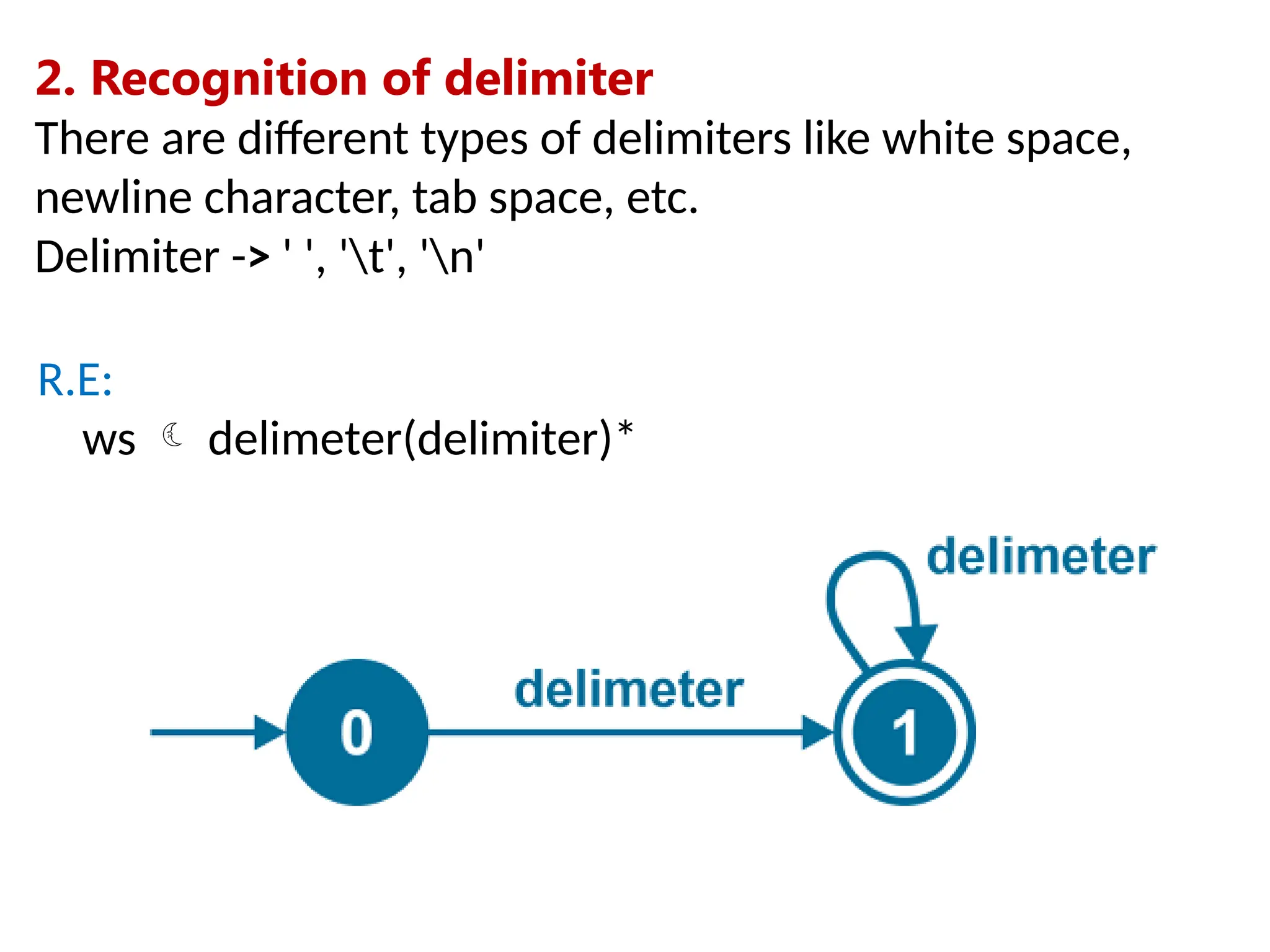
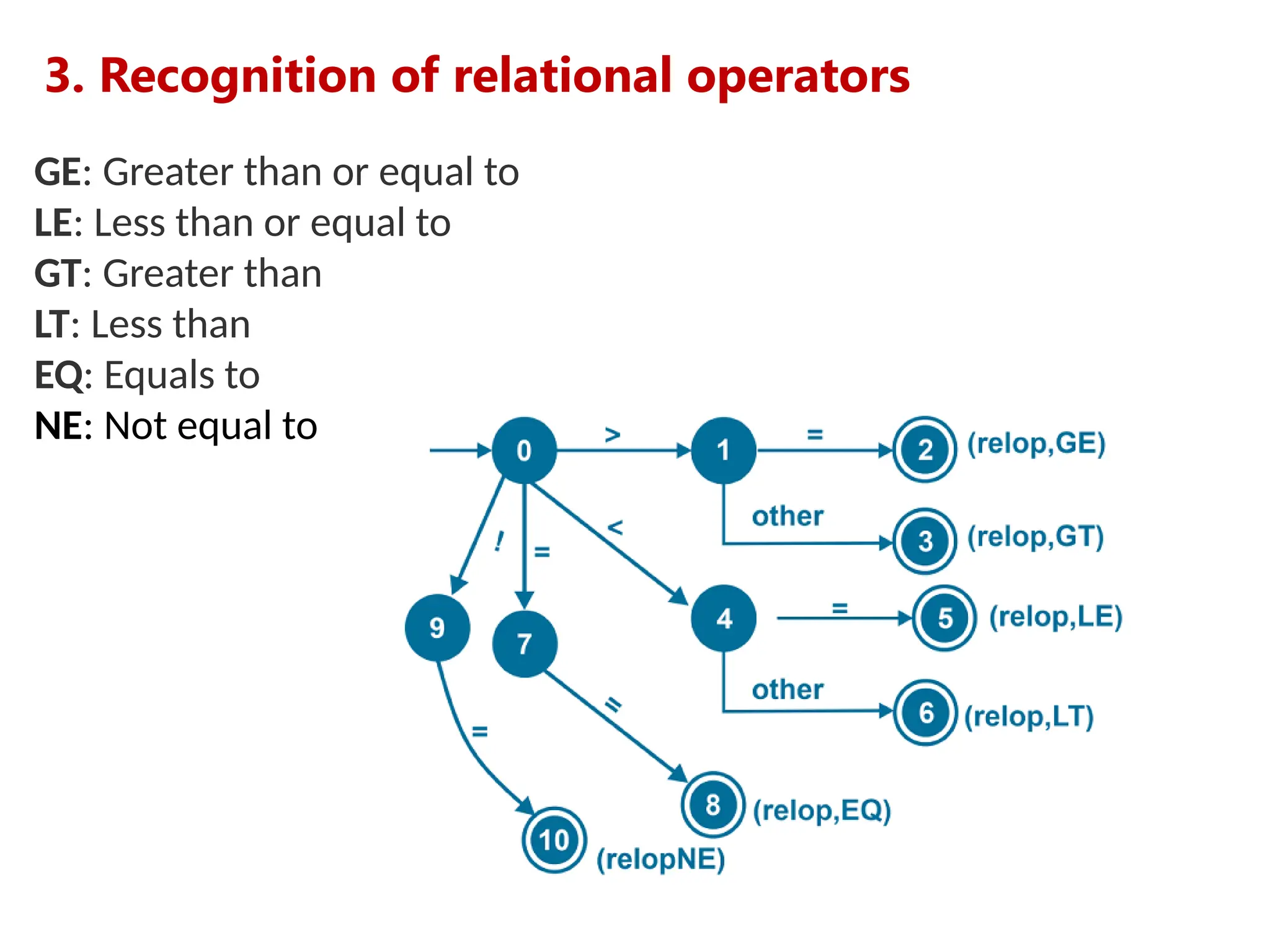
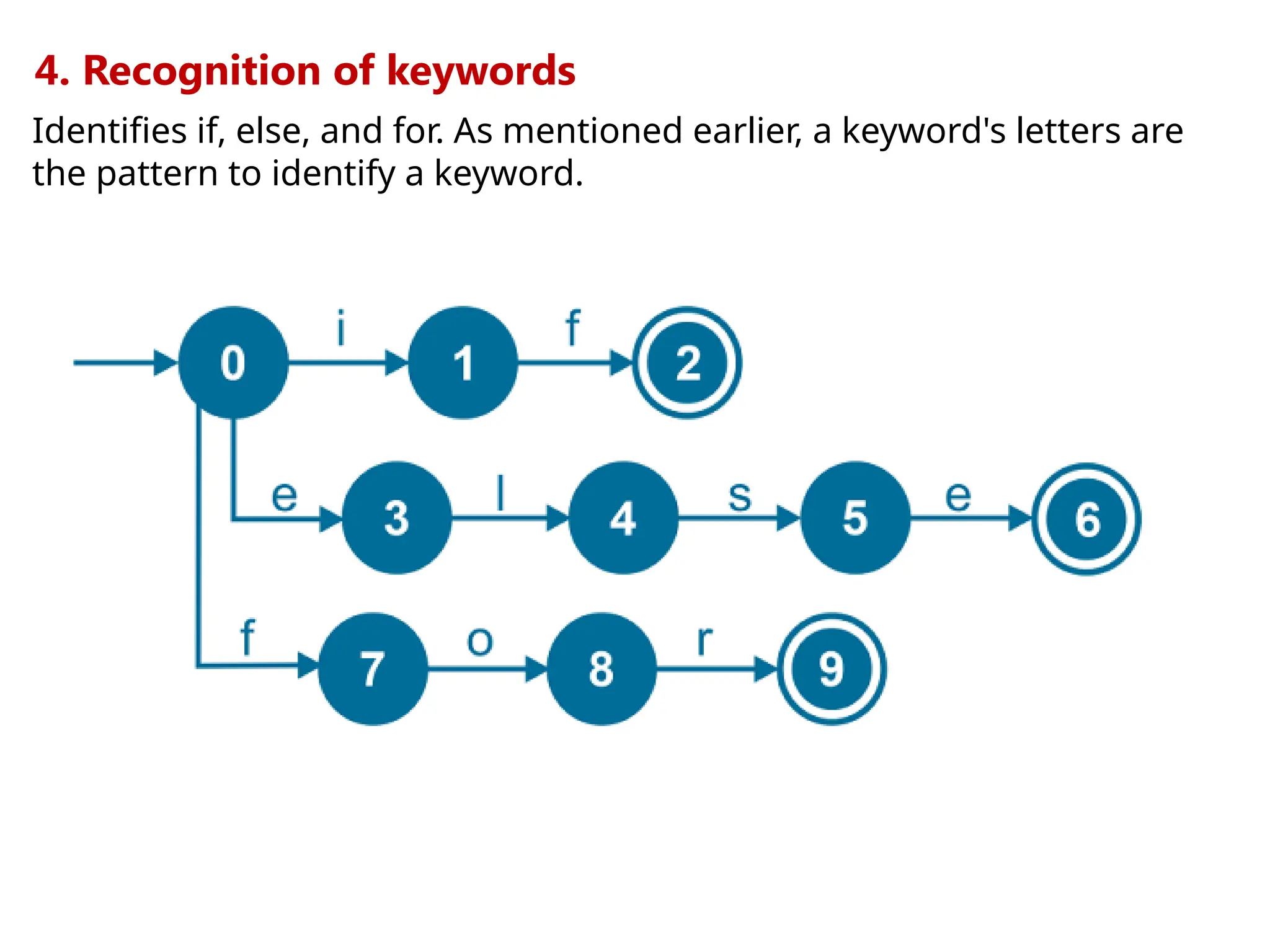
![5. Recognition of numbers
A number can be in the form of:
1.A whole number (0, 1, 2...)
2.A decimal number (0.1, 0.2...)
3.Scientific notation(1.25E), (1.25E23)
Regular grammar:
1.Digit -> 0|1|....9
2.Digits -> Digit (Digit)*
3.Number -> Digits (.Digits)? (E[+ -] ? Digits)?](https://image.slidesharecdn.com/unit2cd-241029123333-2226a495/75/Unit2_CD-pptx-more-about-compilation-of-the-day-57-2048.jpg)
![Number -> Digits (.Digits)? (E[+ -] ? Digits)?](https://image.slidesharecdn.com/unit2cd-241029123333-2226a495/75/Unit2_CD-pptx-more-about-compilation-of-the-day-58-2048.jpg)

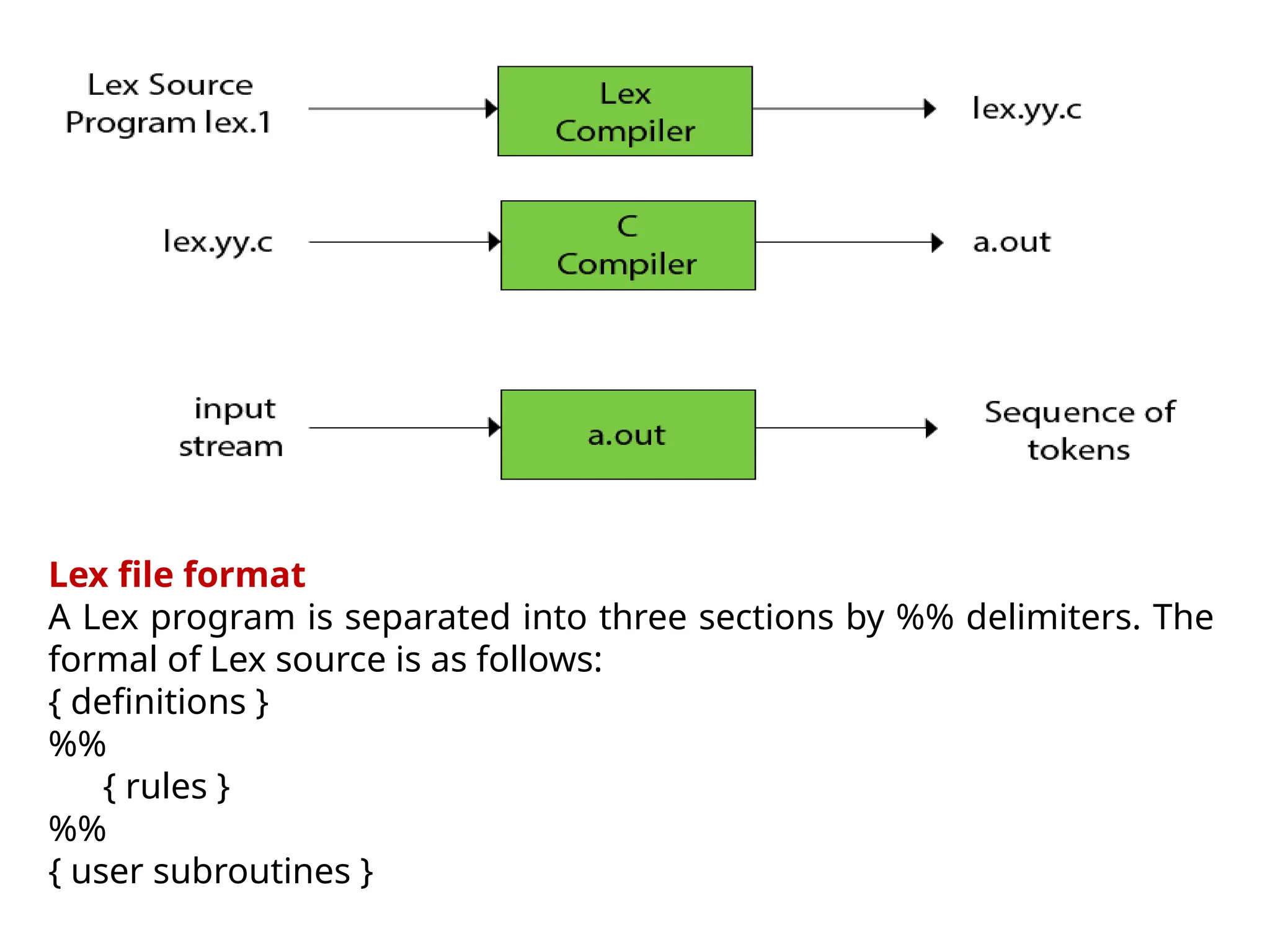

![The following Lex Program counts the number of words-
%{
#include<stdio.h>
#include<string.h>
int count = 0;
%}
/* Rules Section*/
%%
([a-zA-Z0-9])* {count++;}
"n"{printf("Total Number of Words : %dn", count); count = 0;}
%%
int yywrap(void){}
int main()
{
yylex();
return 0;
}
How to execute
Type lex lexfile.l
Type gcc lex.yy.c.
Type ./a.exe](https://image.slidesharecdn.com/unit2cd-241029123333-2226a495/75/Unit2_CD-pptx-more-about-compilation-of-the-day-62-2048.jpg)















































