Download as PDF, PPTX






















![αβ = α.β = abaxy [concatenation]](https://image.slidesharecdn.com/language-processors-160727045258/75/Language-processors-32-2048.jpg)












The document discusses language processors that bridge gaps between software design descriptions and their implementation in computer systems. It outlines the concepts of semantic, specification, and execution gaps, as well as various types of language processors, such as translators, preprocessors, and interpreters. Additionally, it covers fundamental phases of language processing, including analysis and synthesis of source and target programs, alongside the structure and classification of programming language grammars.
Introduction to language processors highlights the definition, differences between application and execution domains, and how software ideas are interpreted.
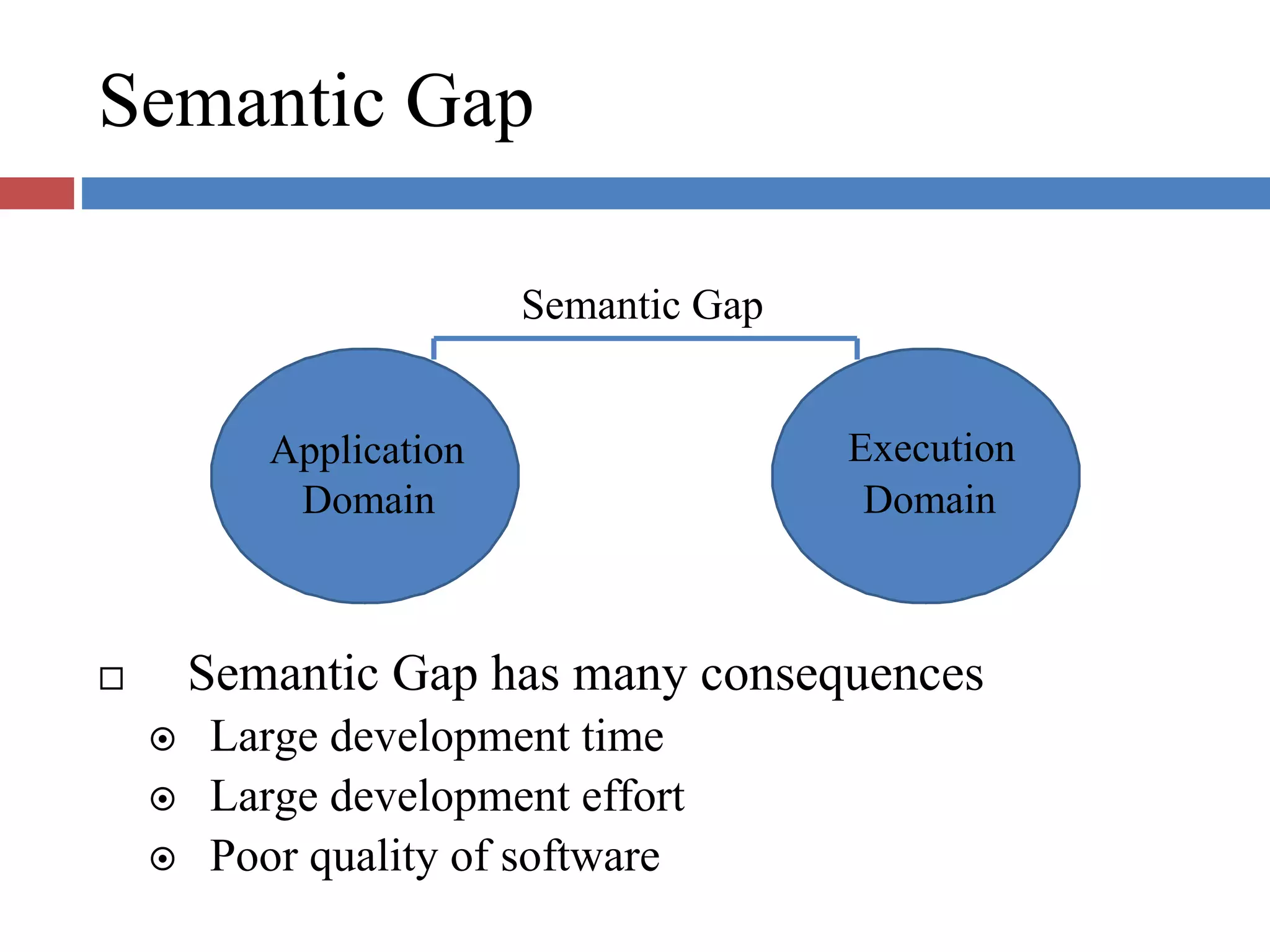
Discusses the semantic gap causing large development time and effort, resulting in poor software quality, and defines specification and execution gaps.
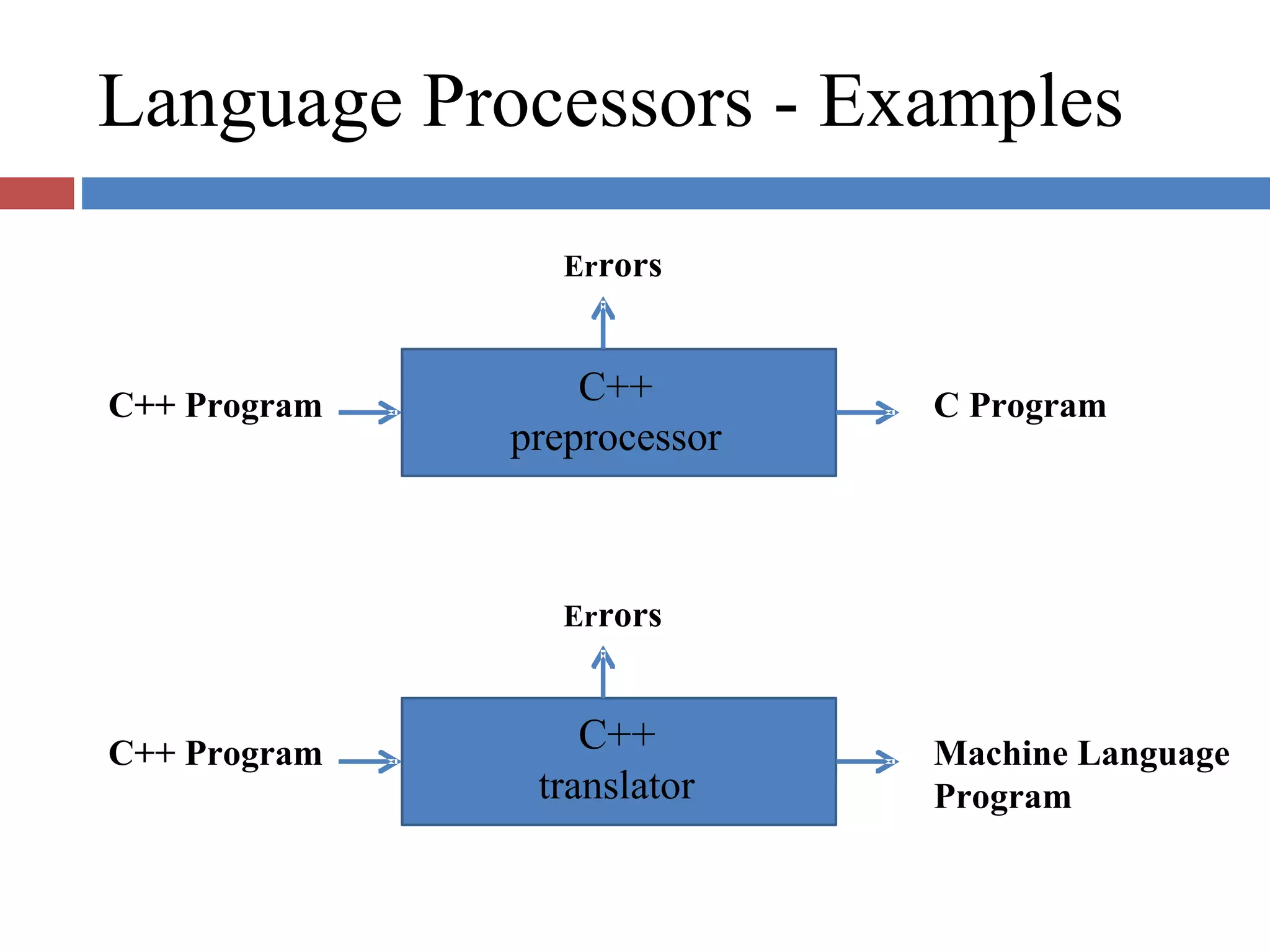
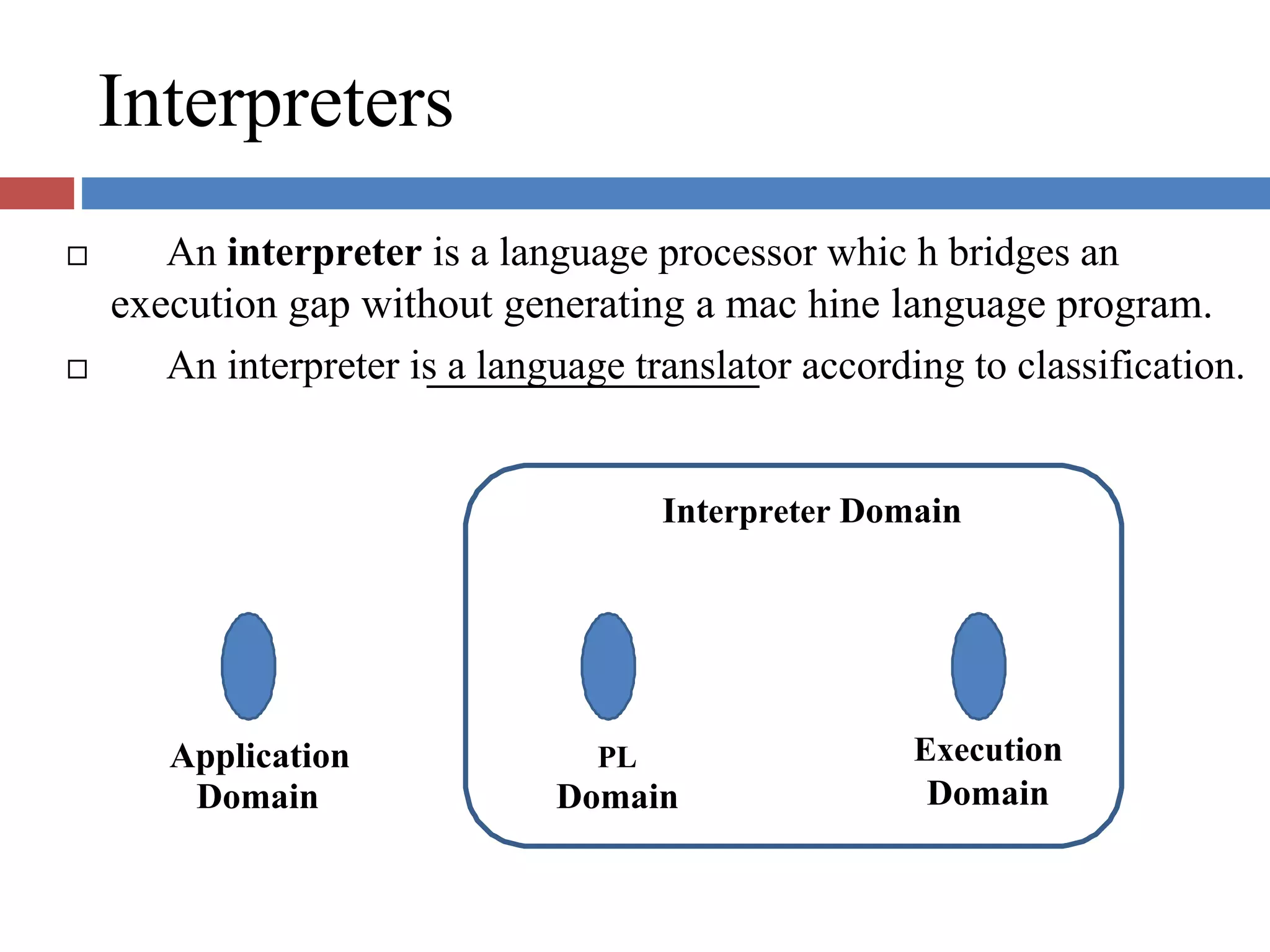
Defines language processors including translators, detranslators, preprocessors, and interpreters that bridge execution and specification gaps.
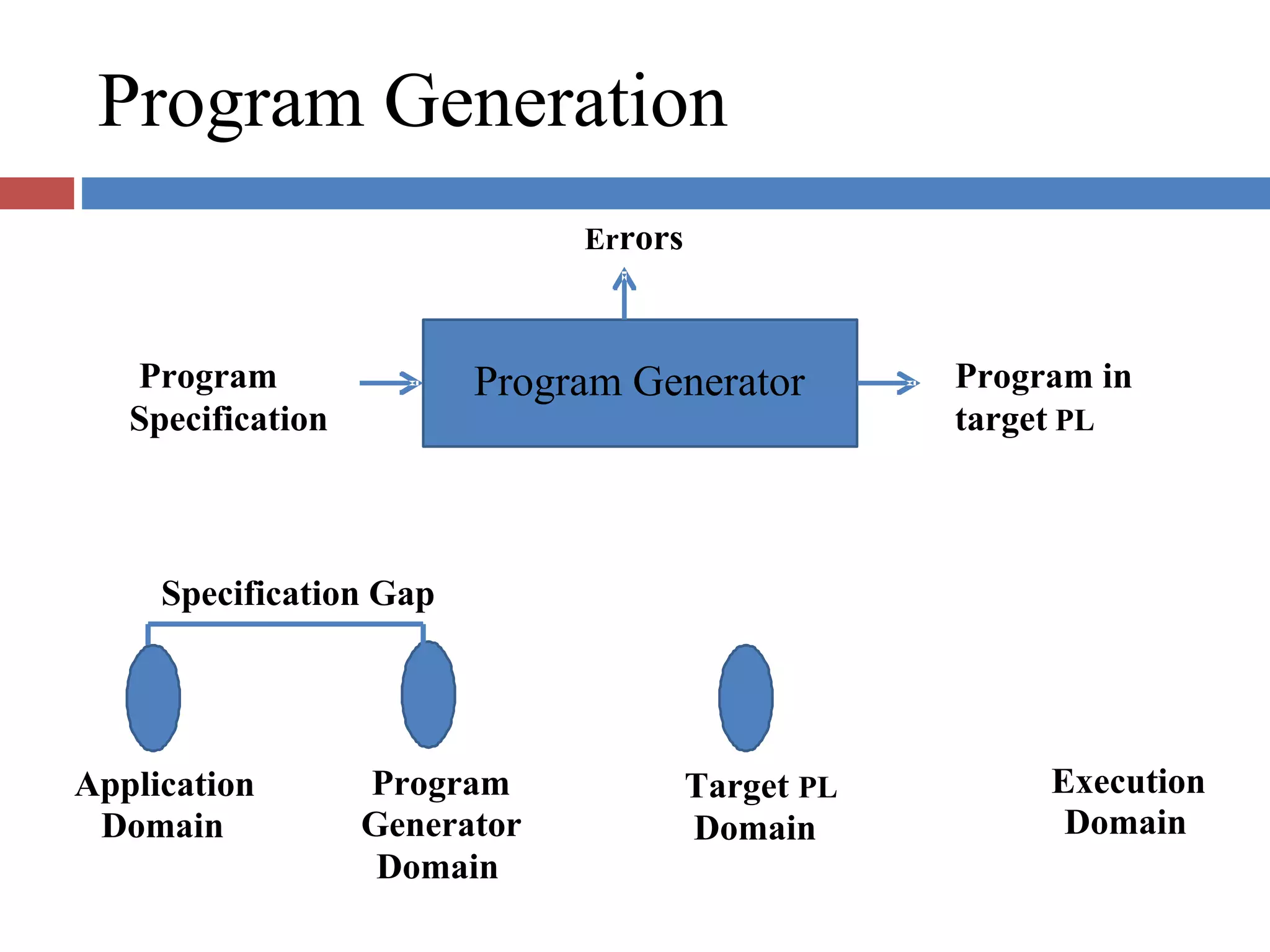
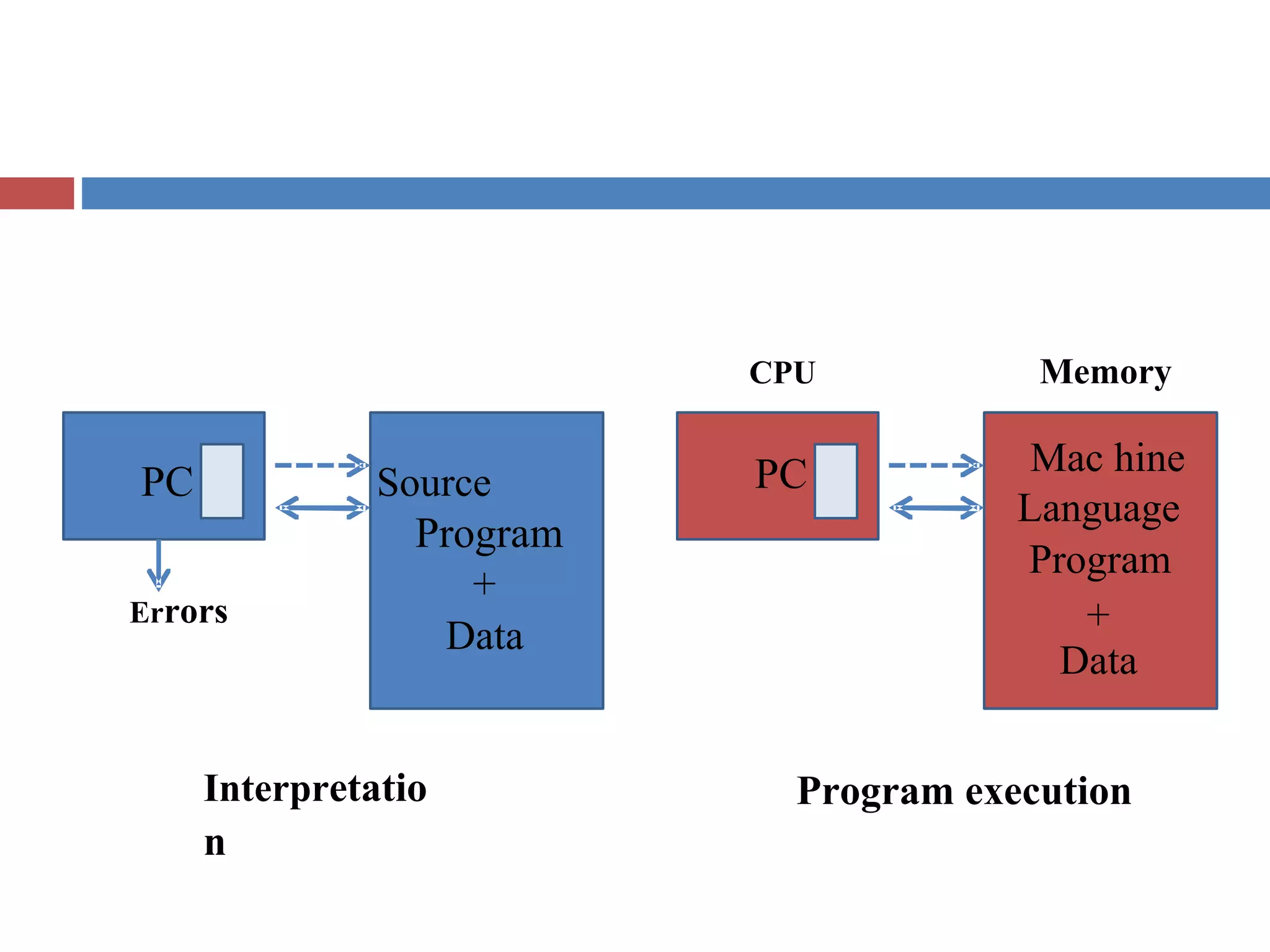
Describes program generation and execution activities, detailing the necessity for translation before execution.
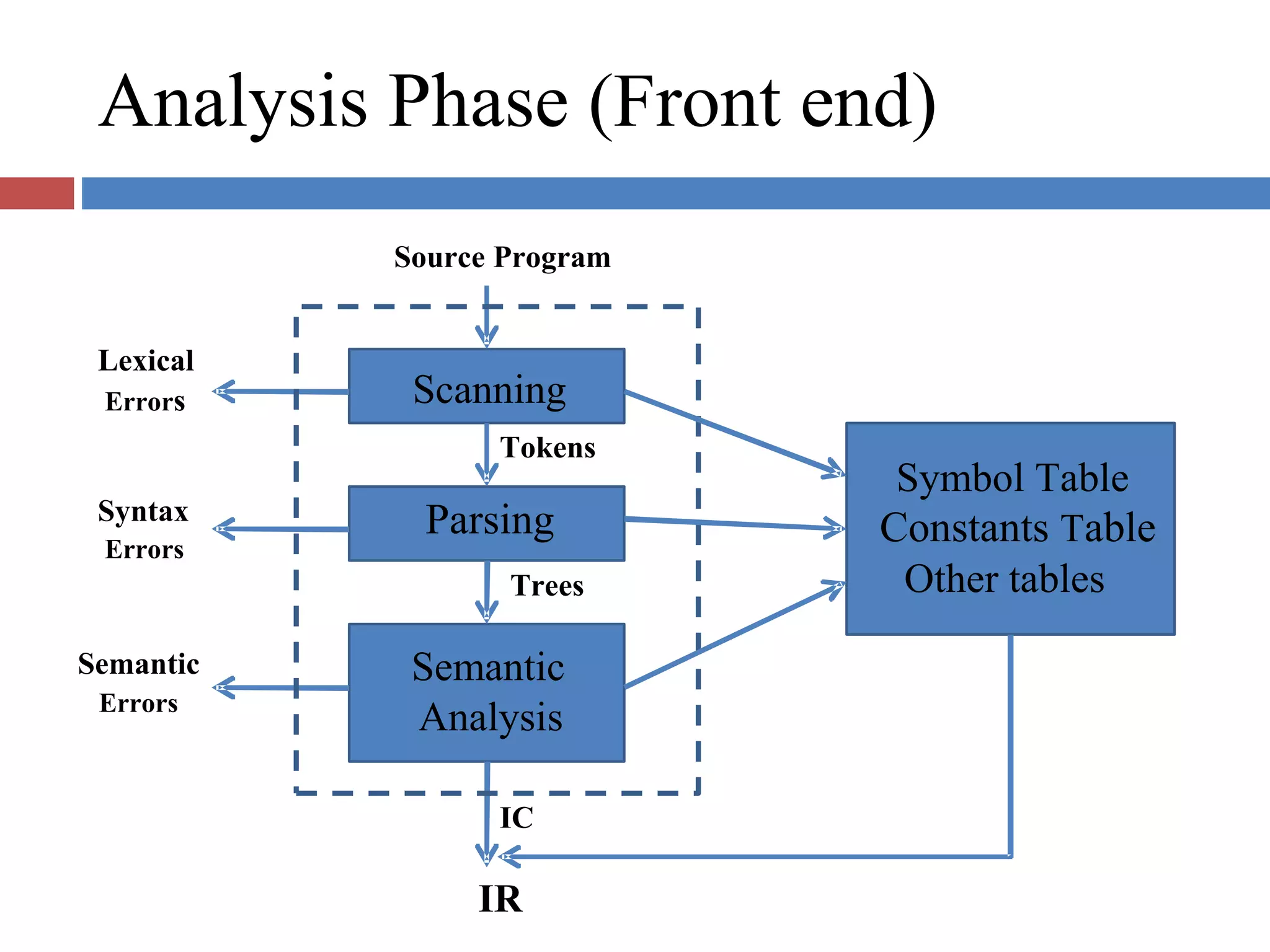
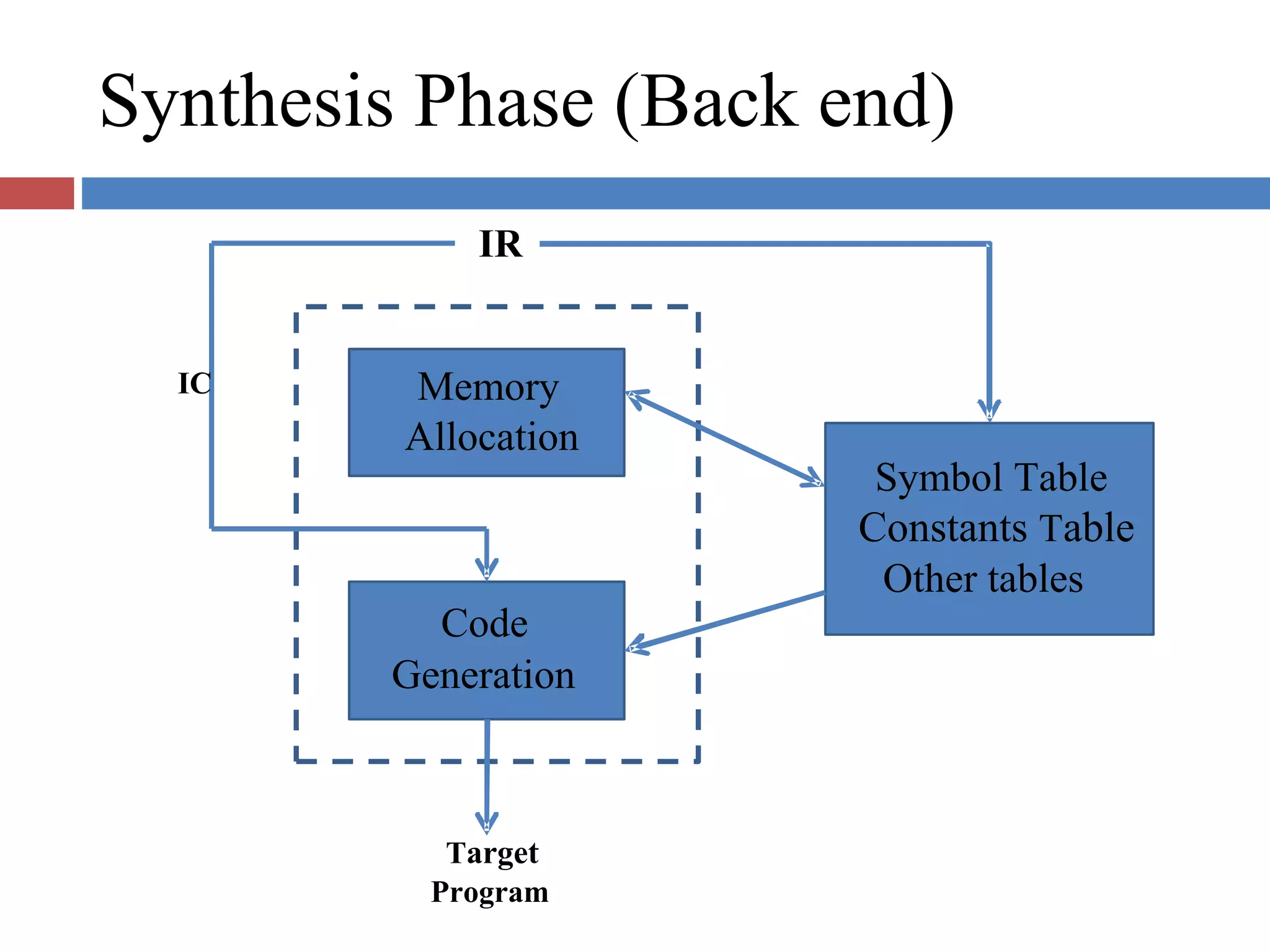
Highlights language processing phases: analysis (lexical, syntax, semantic) and synthesis phases (memory allocation, code generation).
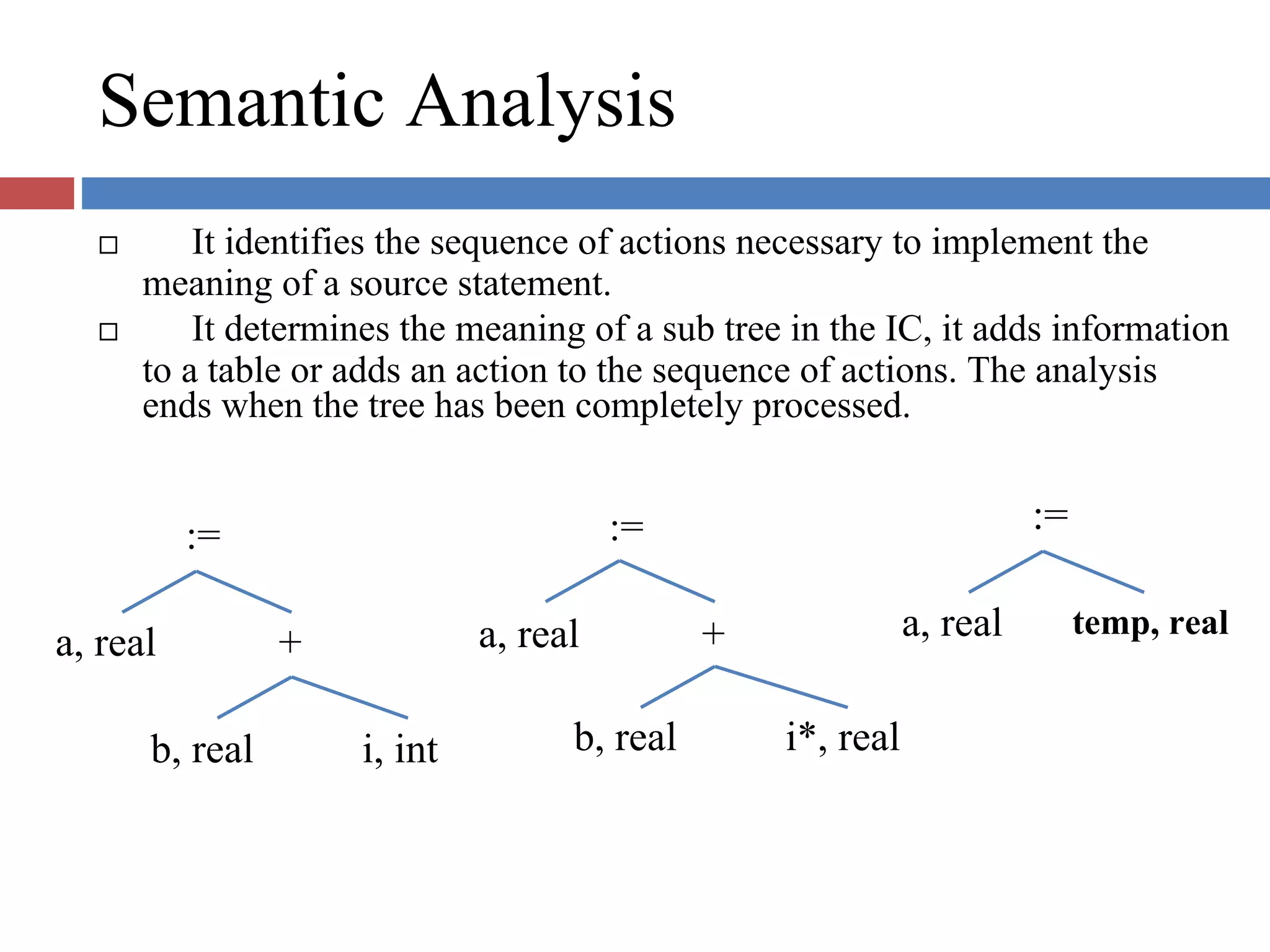
Explains lexical analysis, syntax analysis, and semantic analysis, detailing how source code is interpreted and validated.
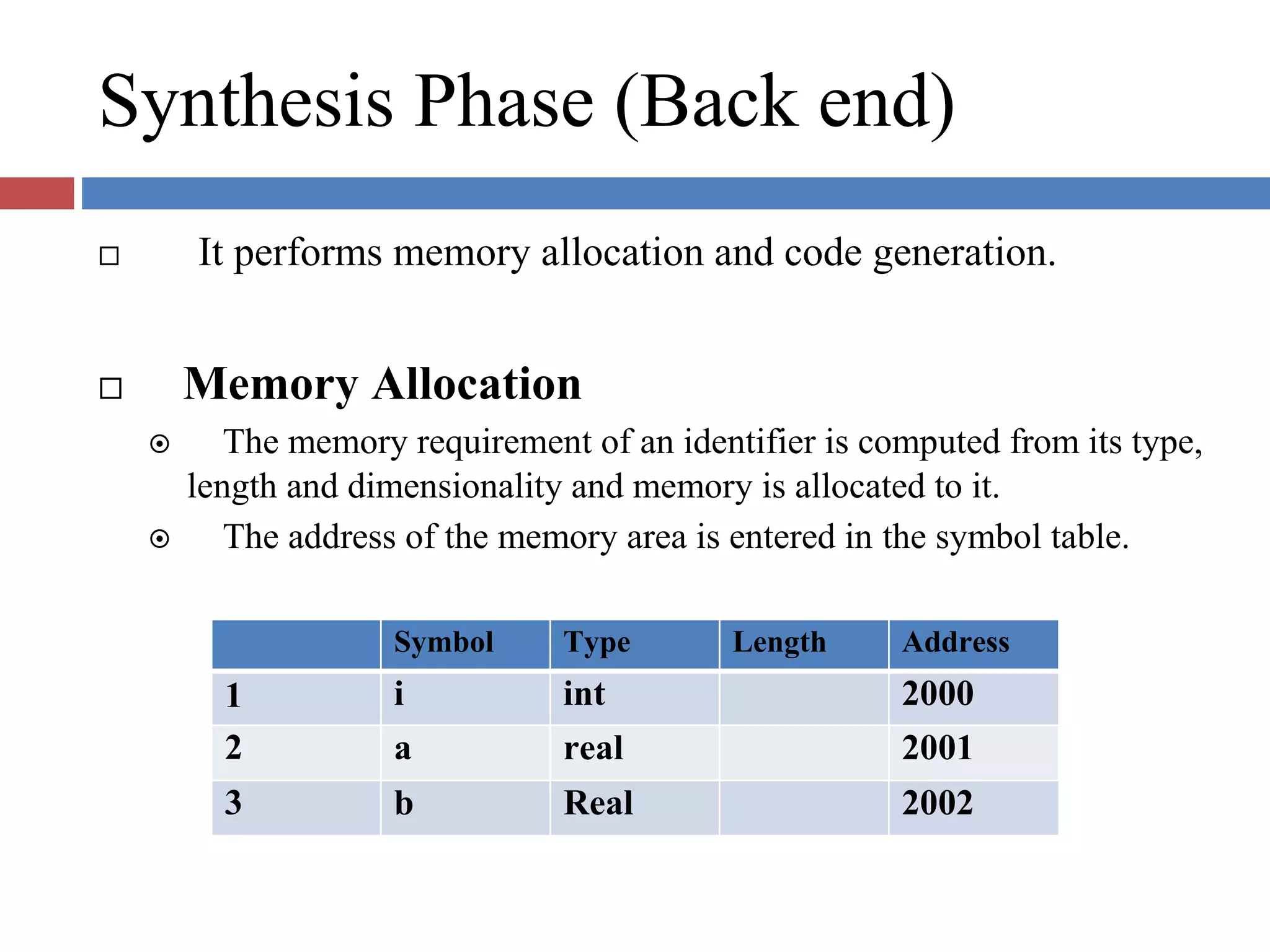
Details the synthesis phase focusing on memory allocation and code generation, leading to the formation of target programs.
Introduces programming language grammars, alphabets, terminal symbols, and their formal definitions.
Defines strings, nonterminal symbols, and grammar productions which form the basis of grammar in programming languages.
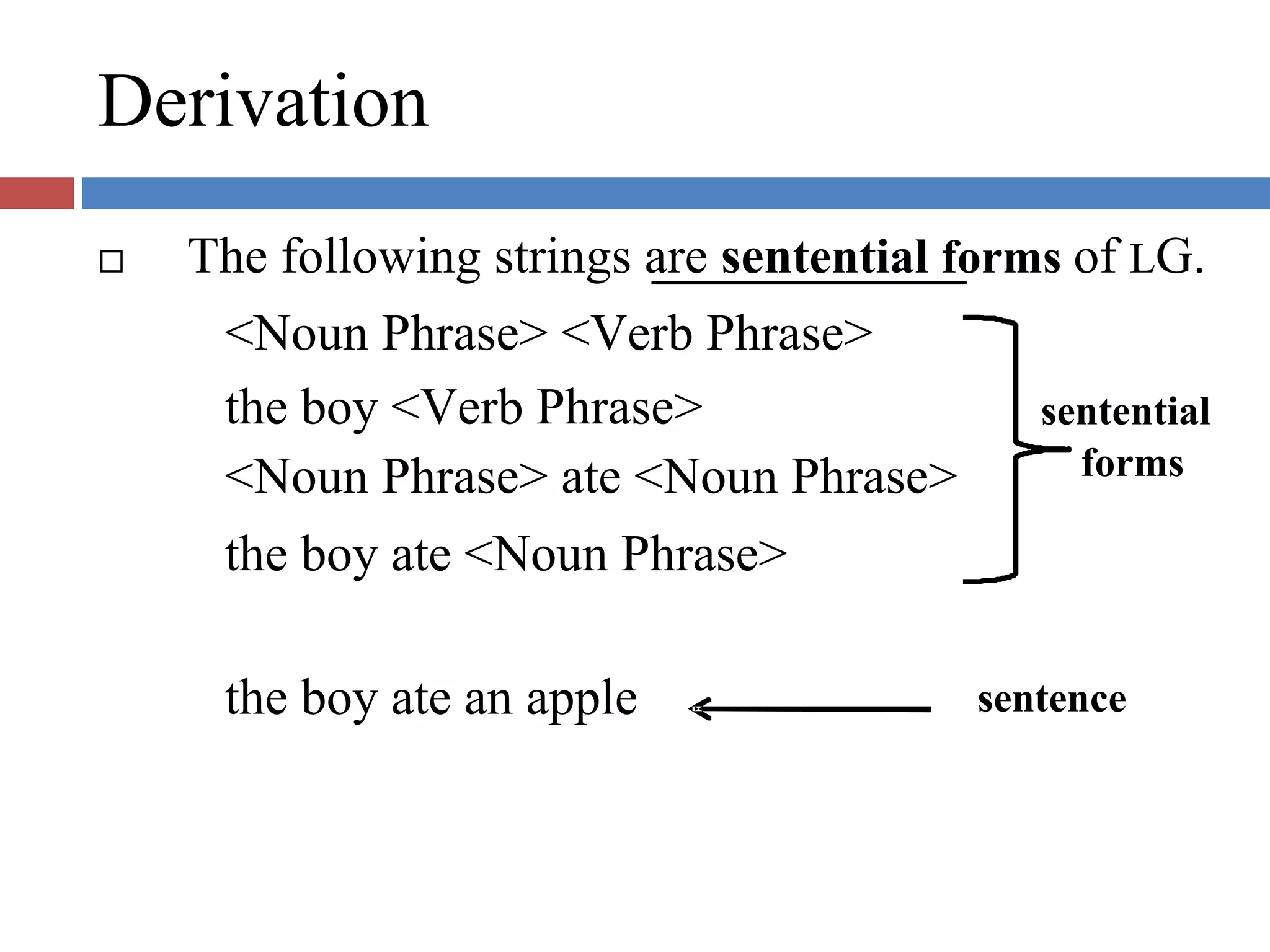
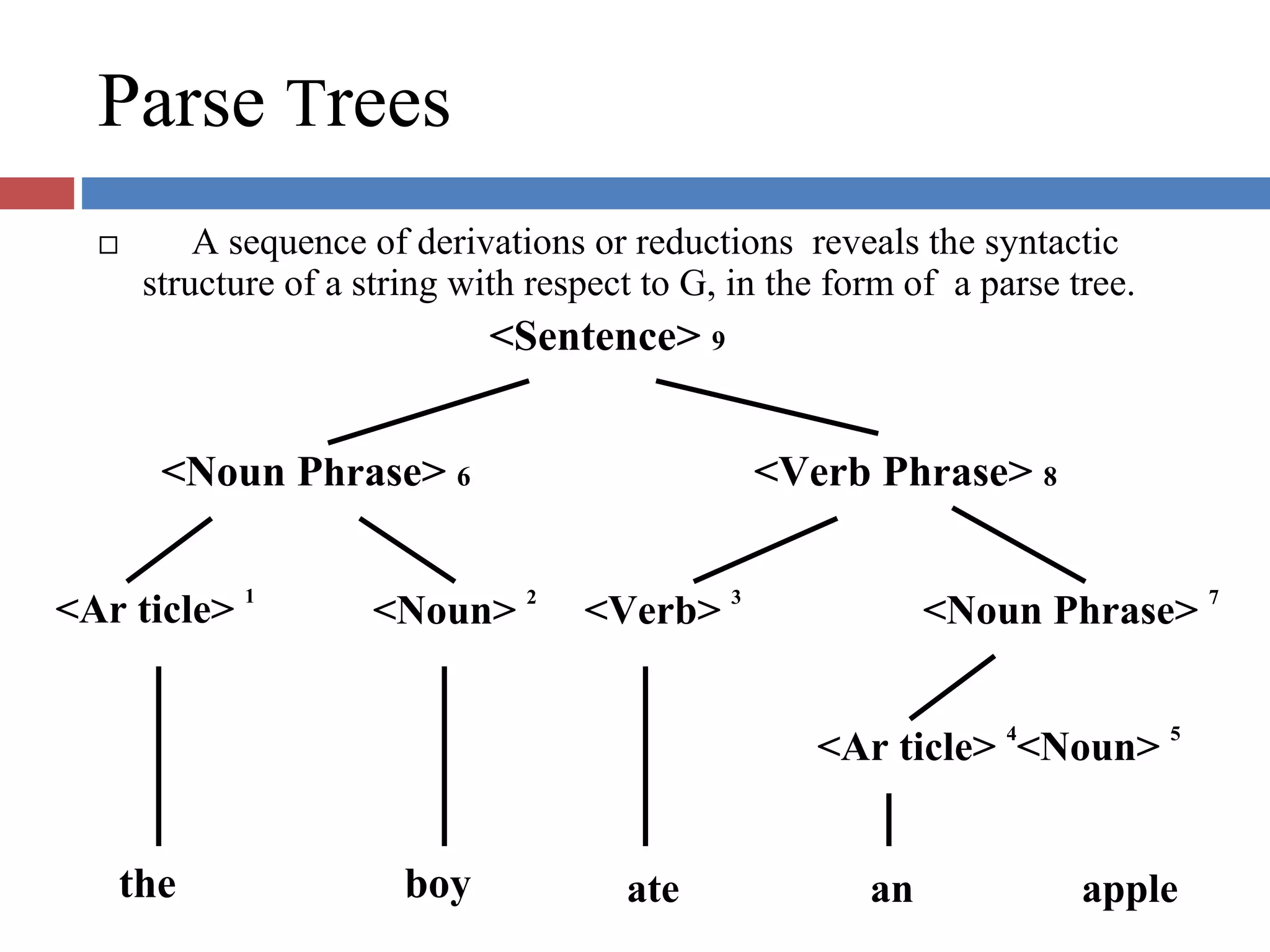
Describes the processes of derivation and reduction, including the function and structure of parse trees in syntax.
Differentiates between types of grammars and explores ambiguity within grammatical specifications and its implications.
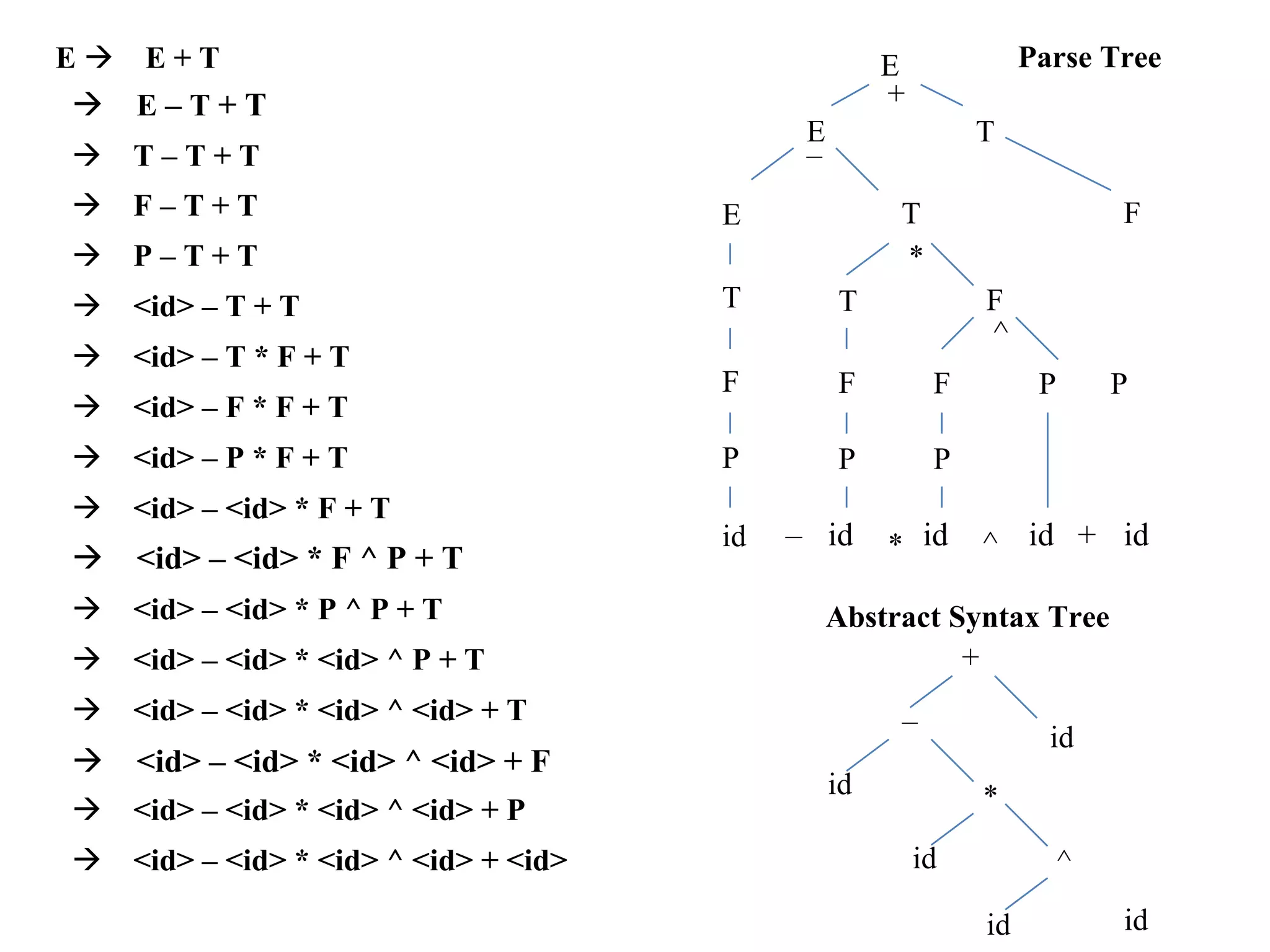
Provides examples of unambiguous production rules and practical grammar applications through derivations and parse trees.



































































