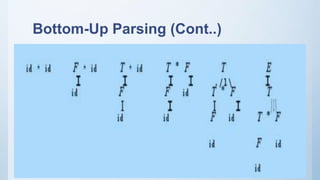
Bottom-up parsing starts with the input symbols and constructs the parse tree from the bottom up by applying grammar rules. It uses shift-reduce parsing with two main steps: shift, which advances the input pointer and pushes the symbol onto the stack; and reduce, which replaces completed grammar rules on the stack with their left-hand side symbols. Shift-reduce parsing can result in conflicts when the parser cannot unambiguously decide whether to shift or reduce, or which reduction to make. LR parsers are a common method for resolving such conflicts during bottom-up parsing.