Downloaded 51 times








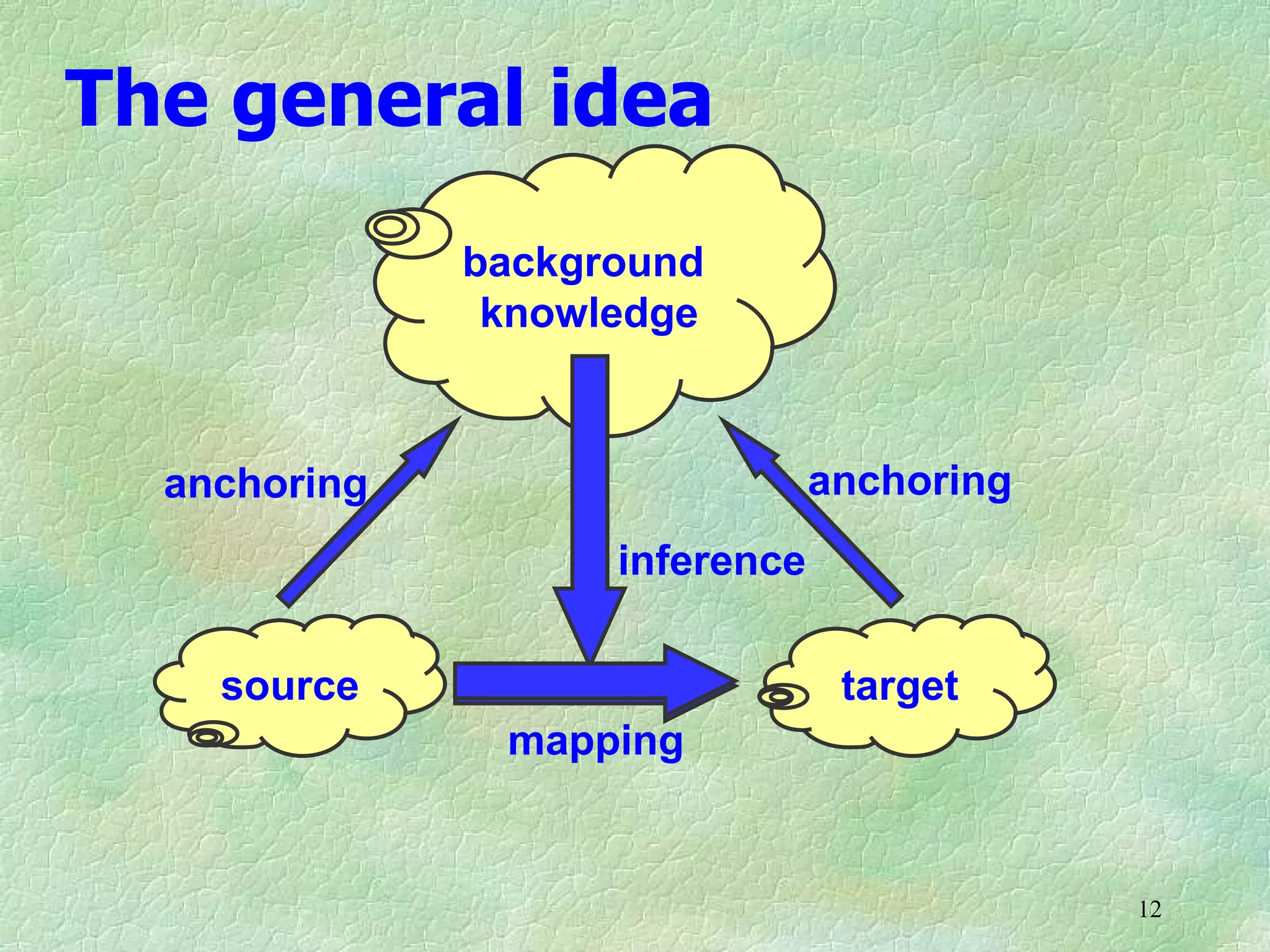



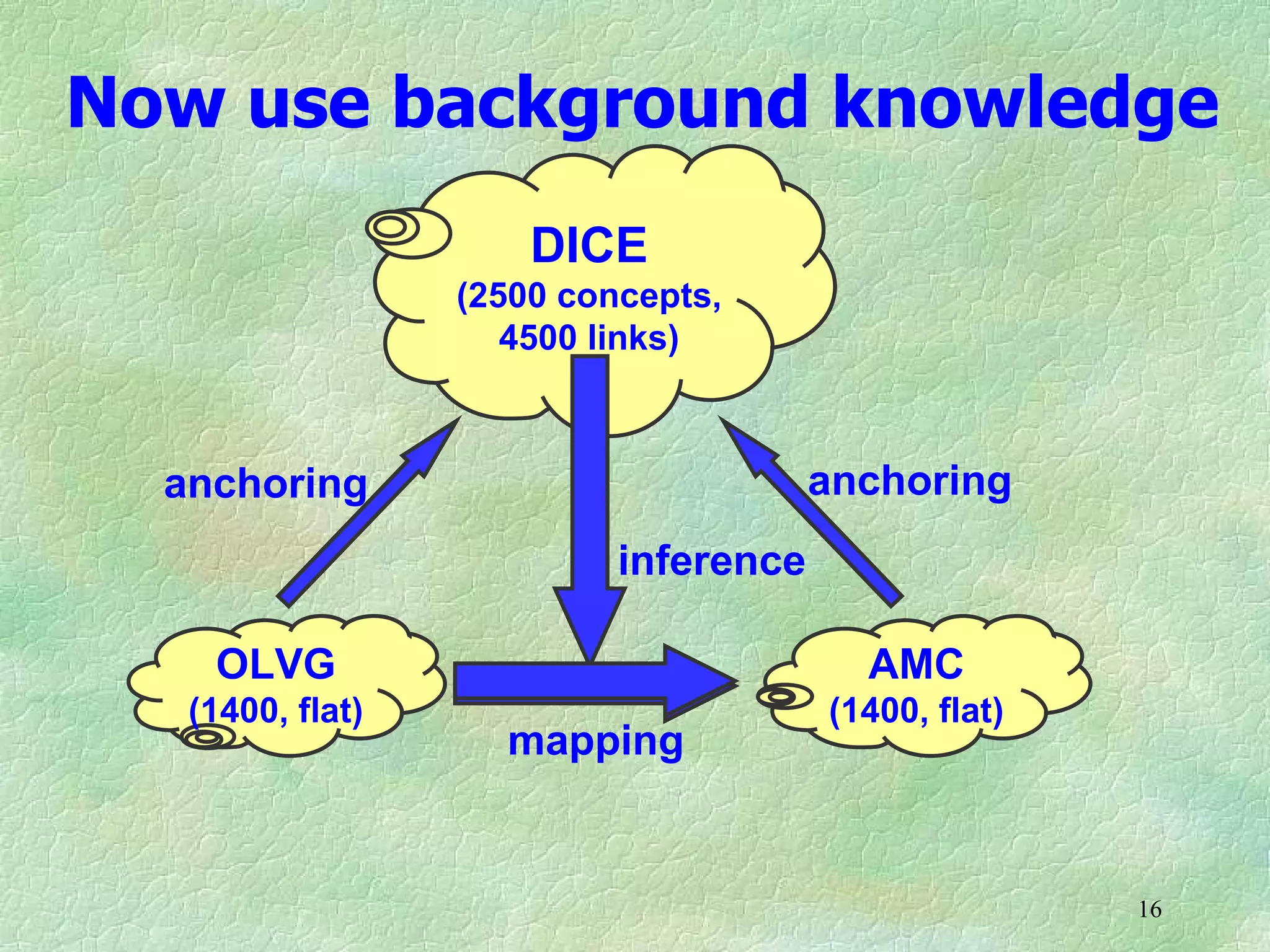
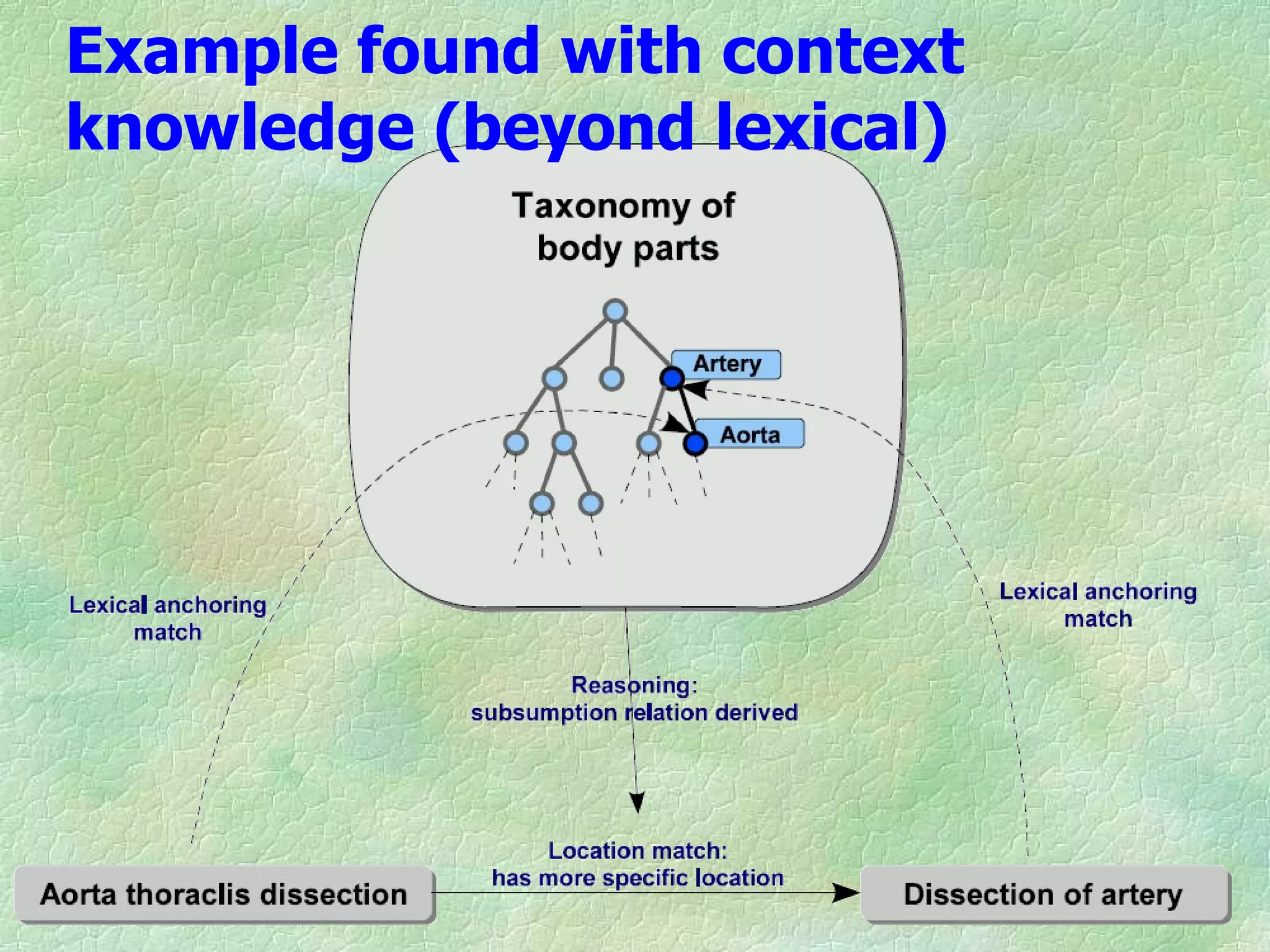
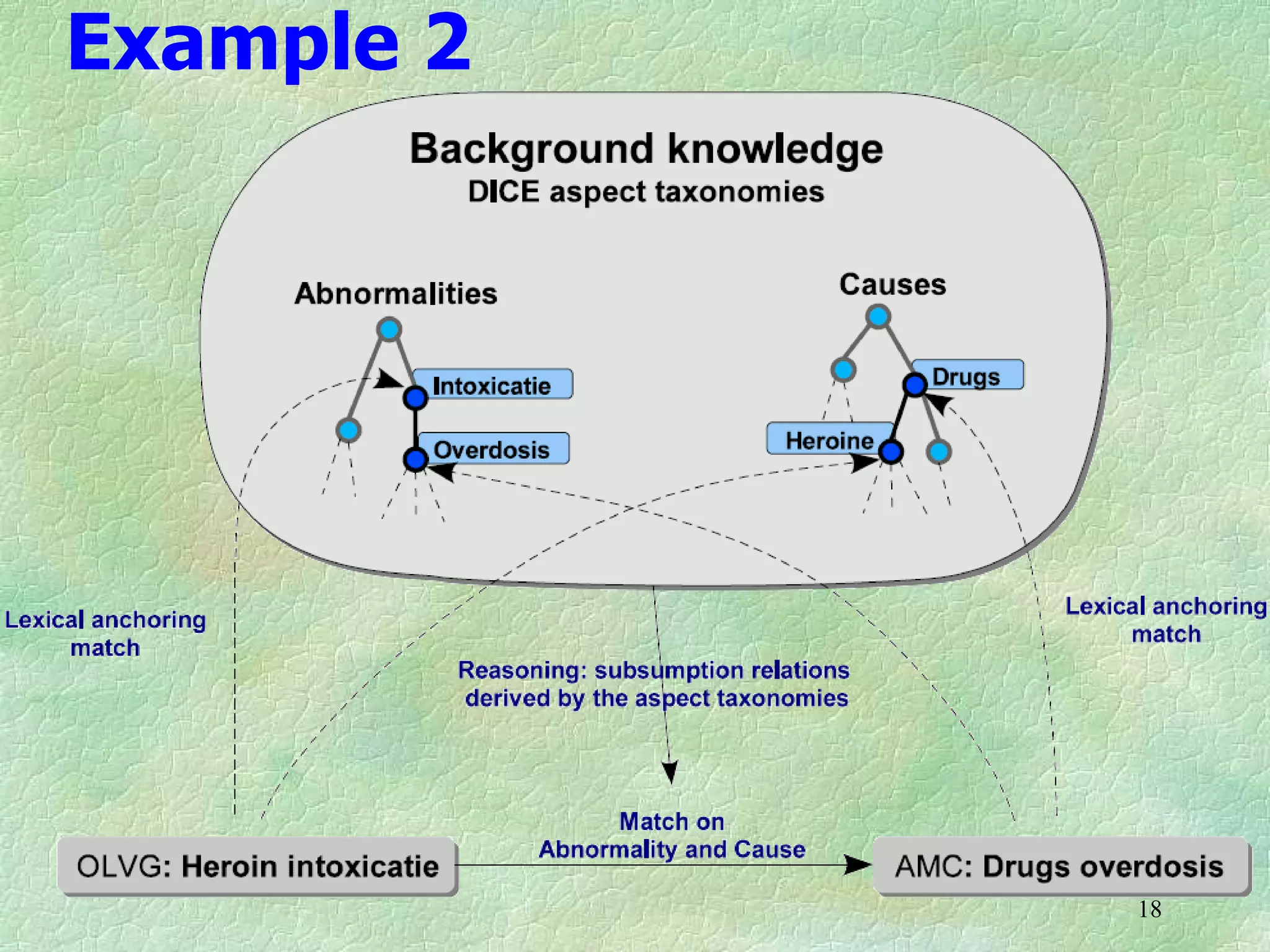
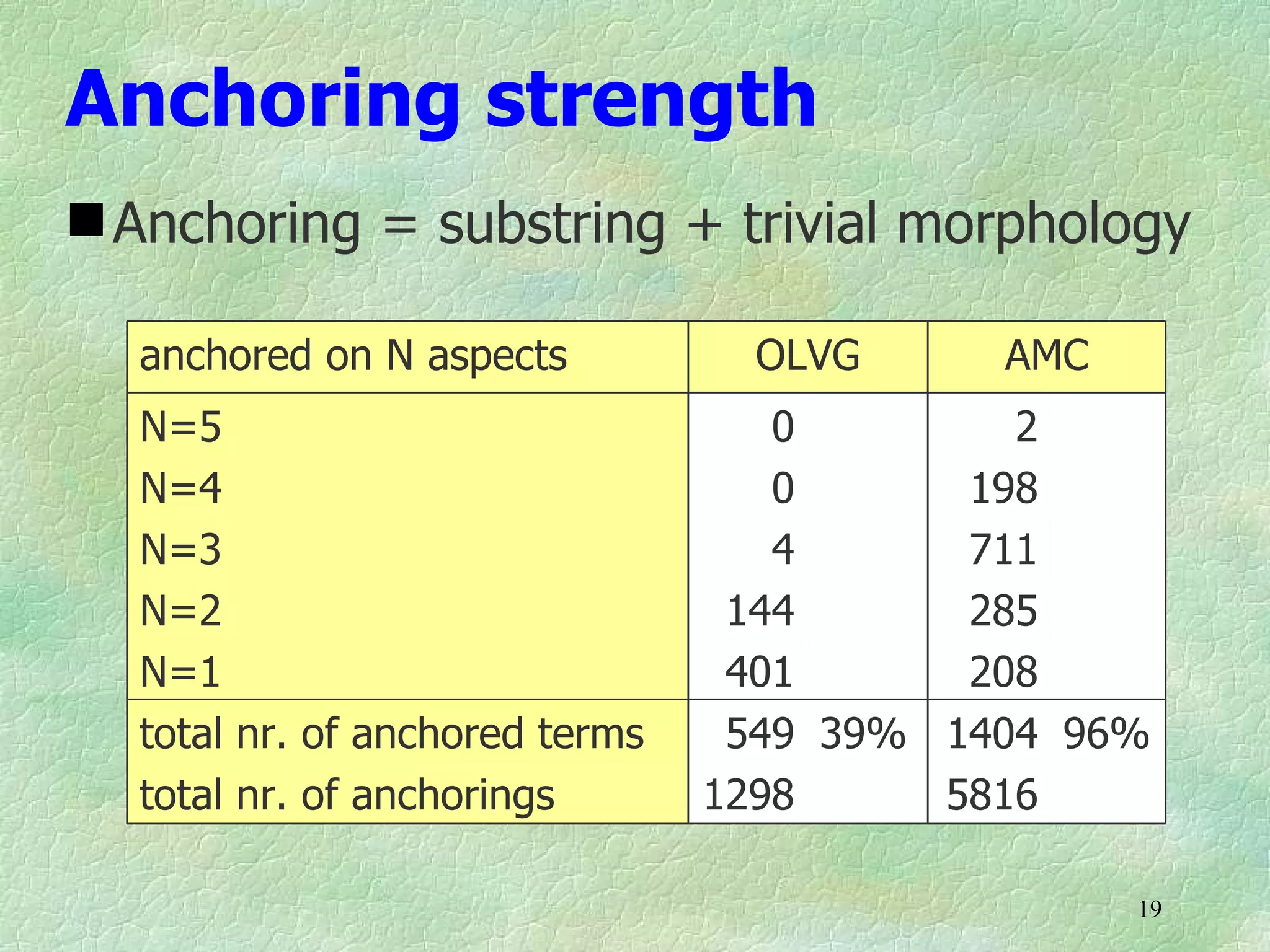
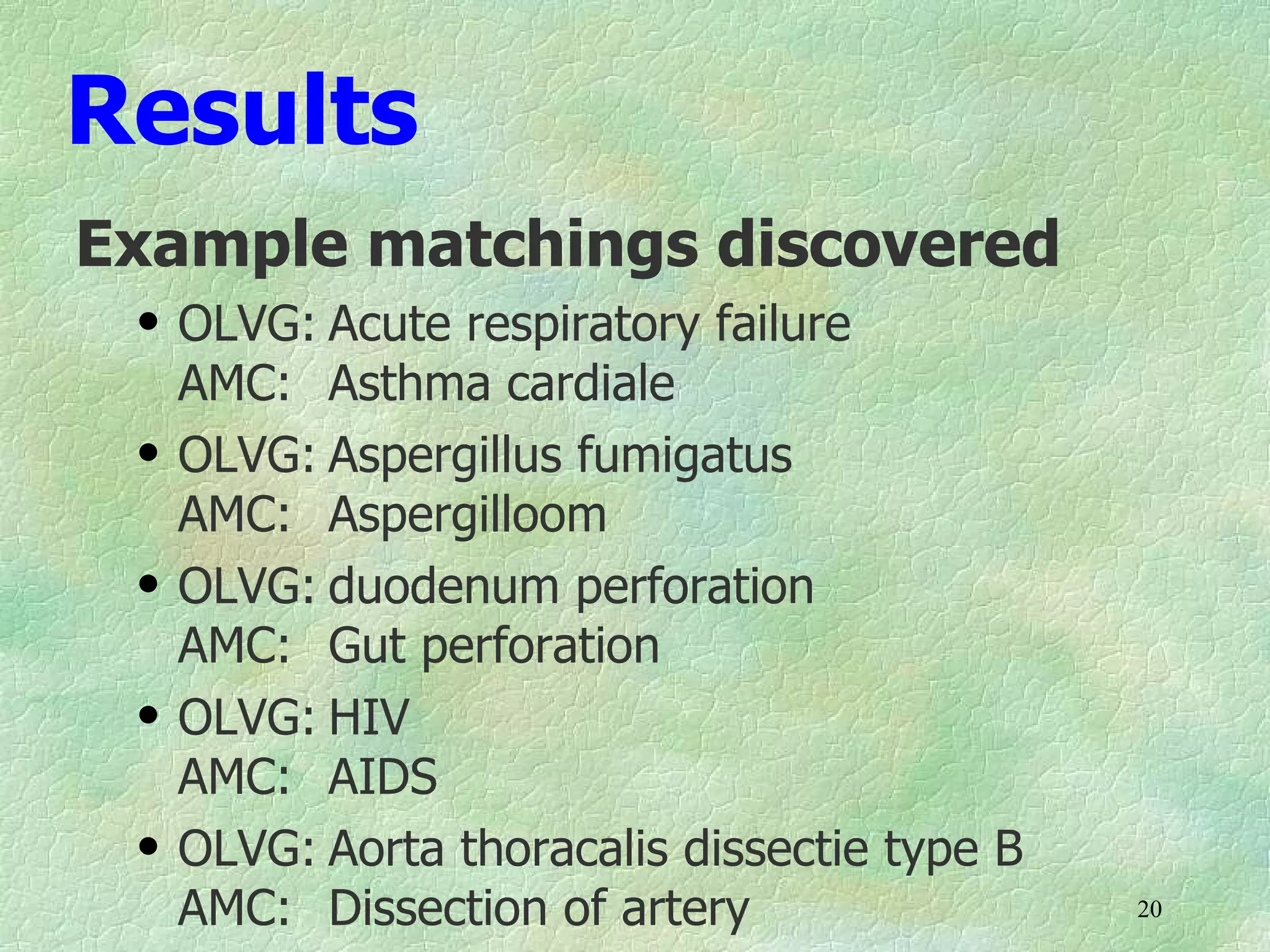
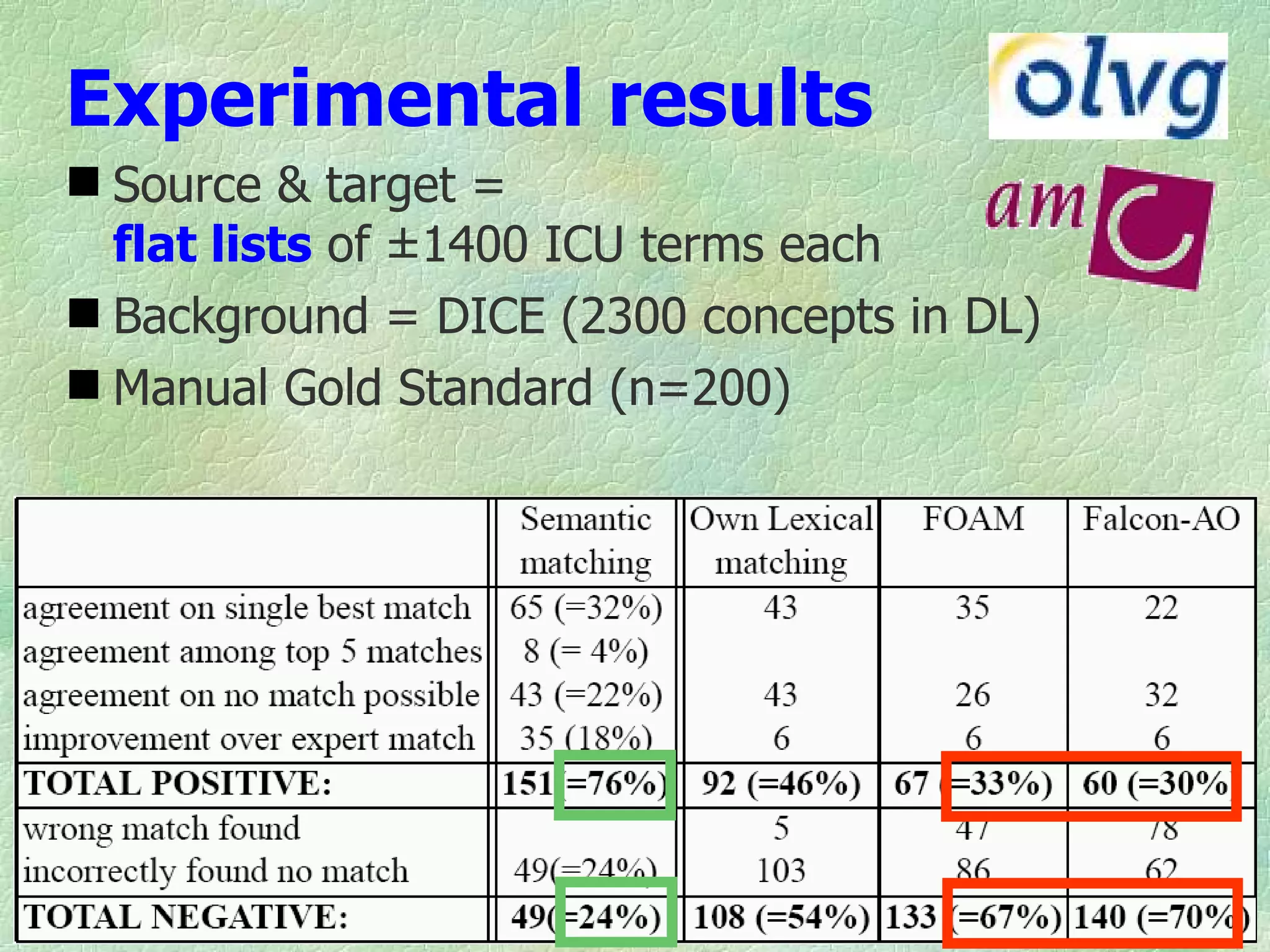

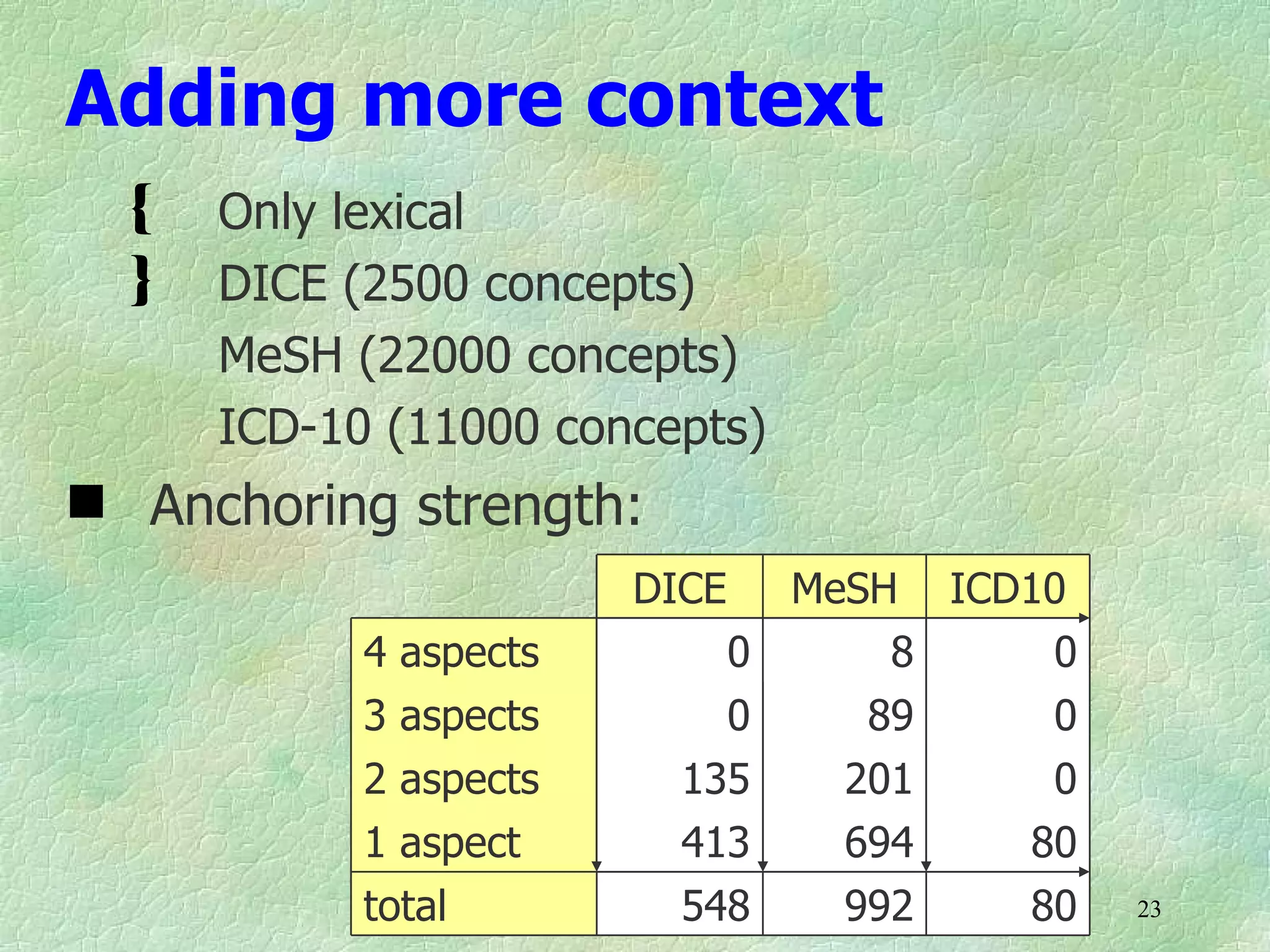
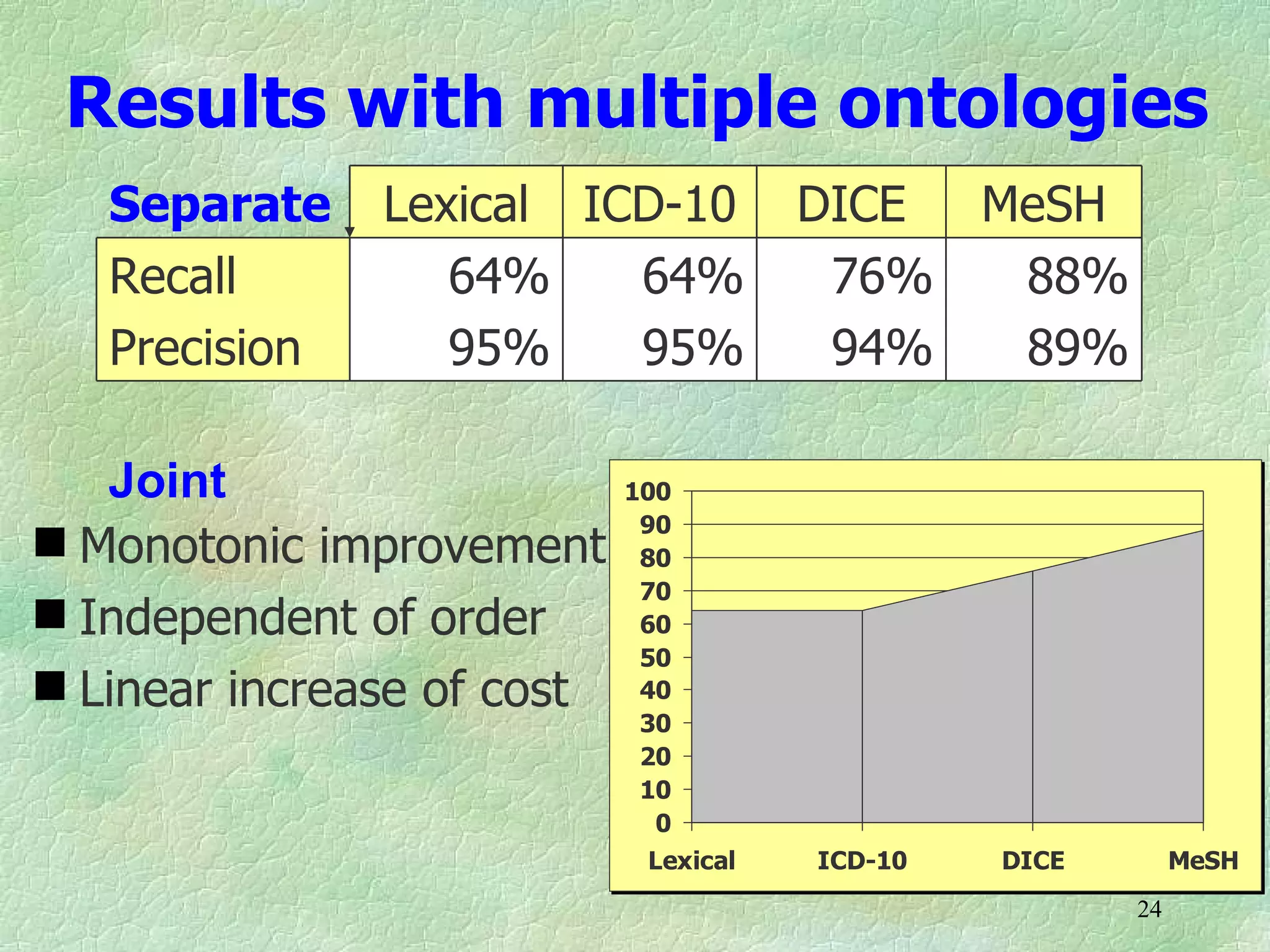

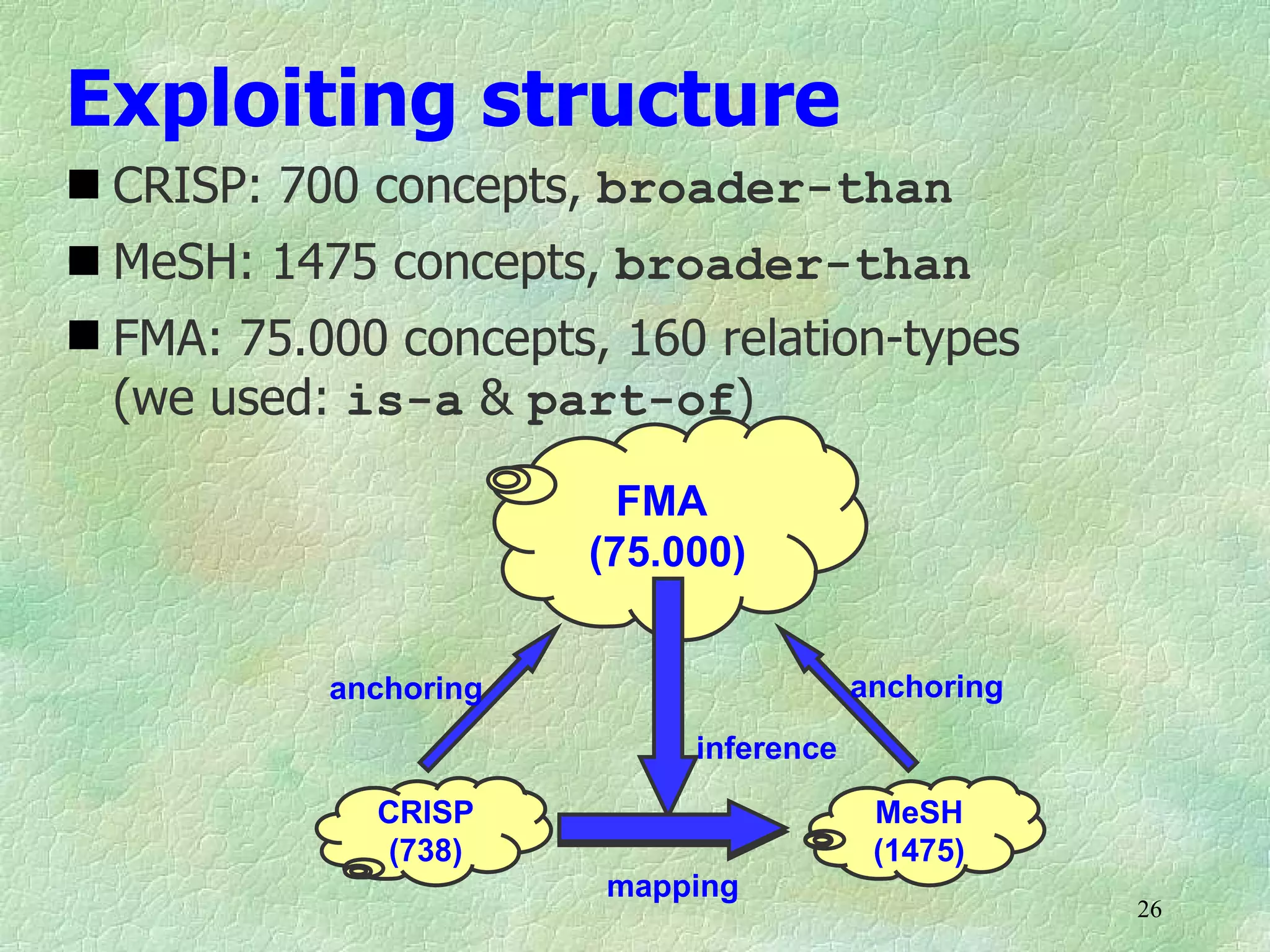
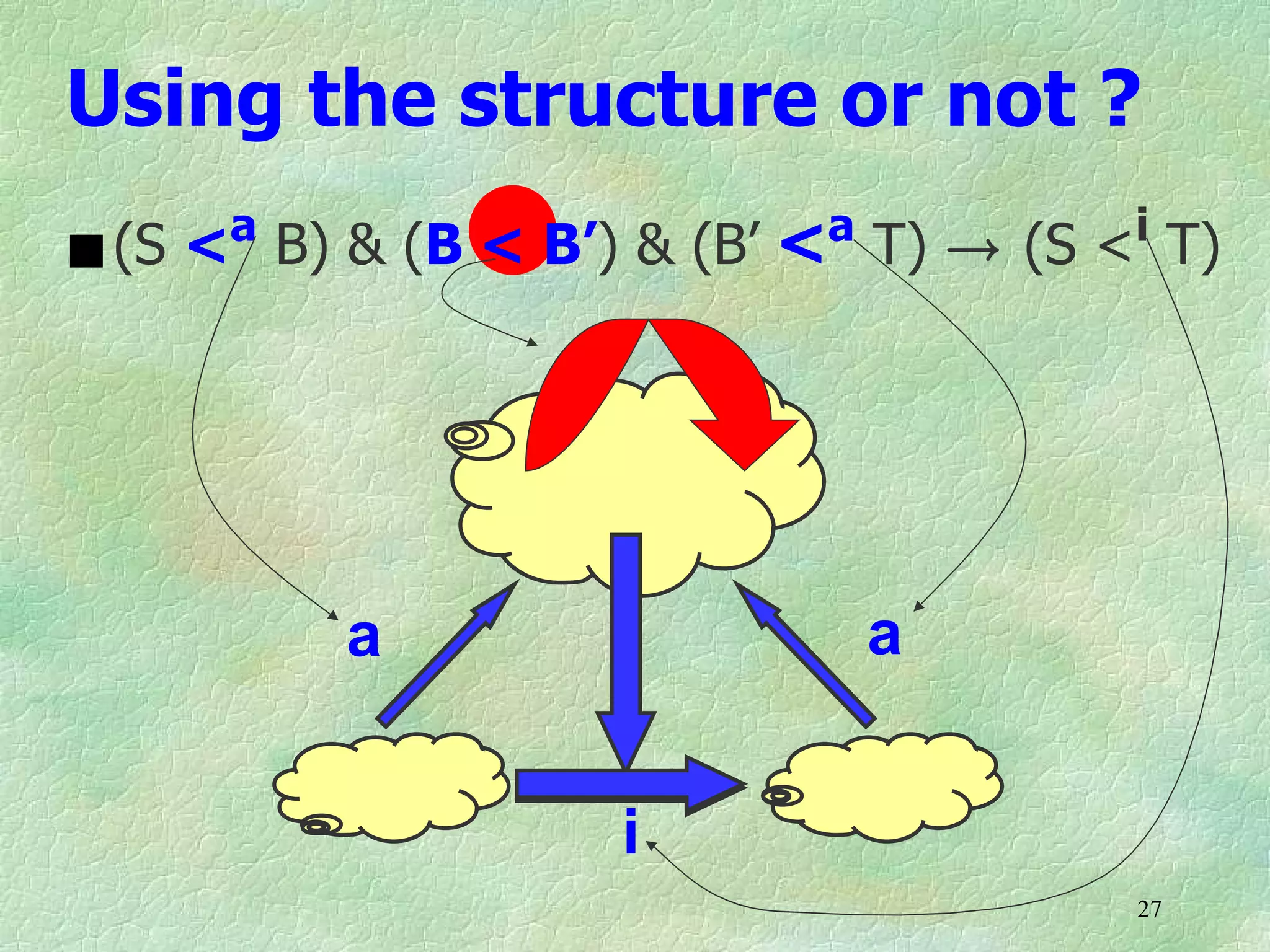

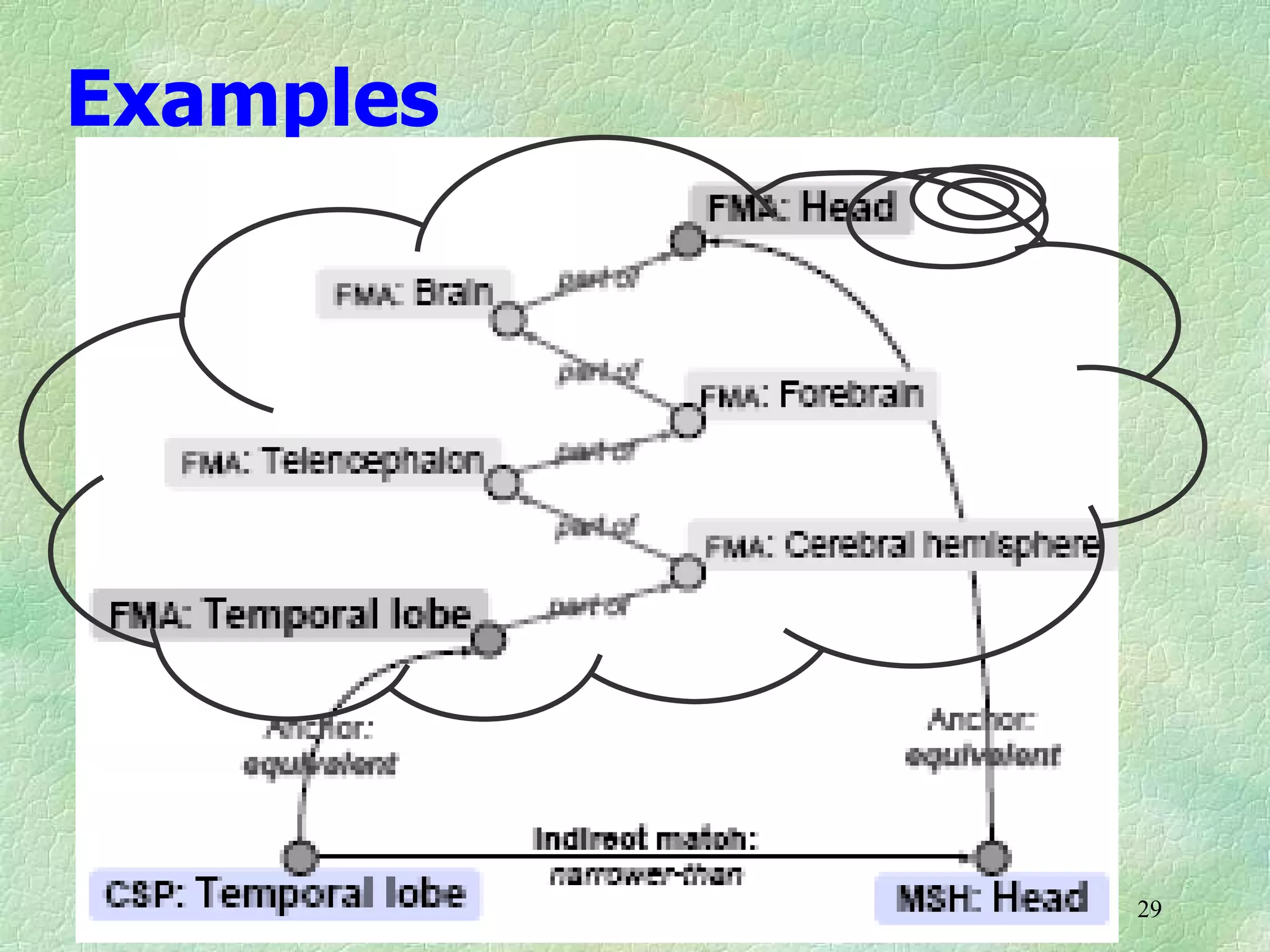
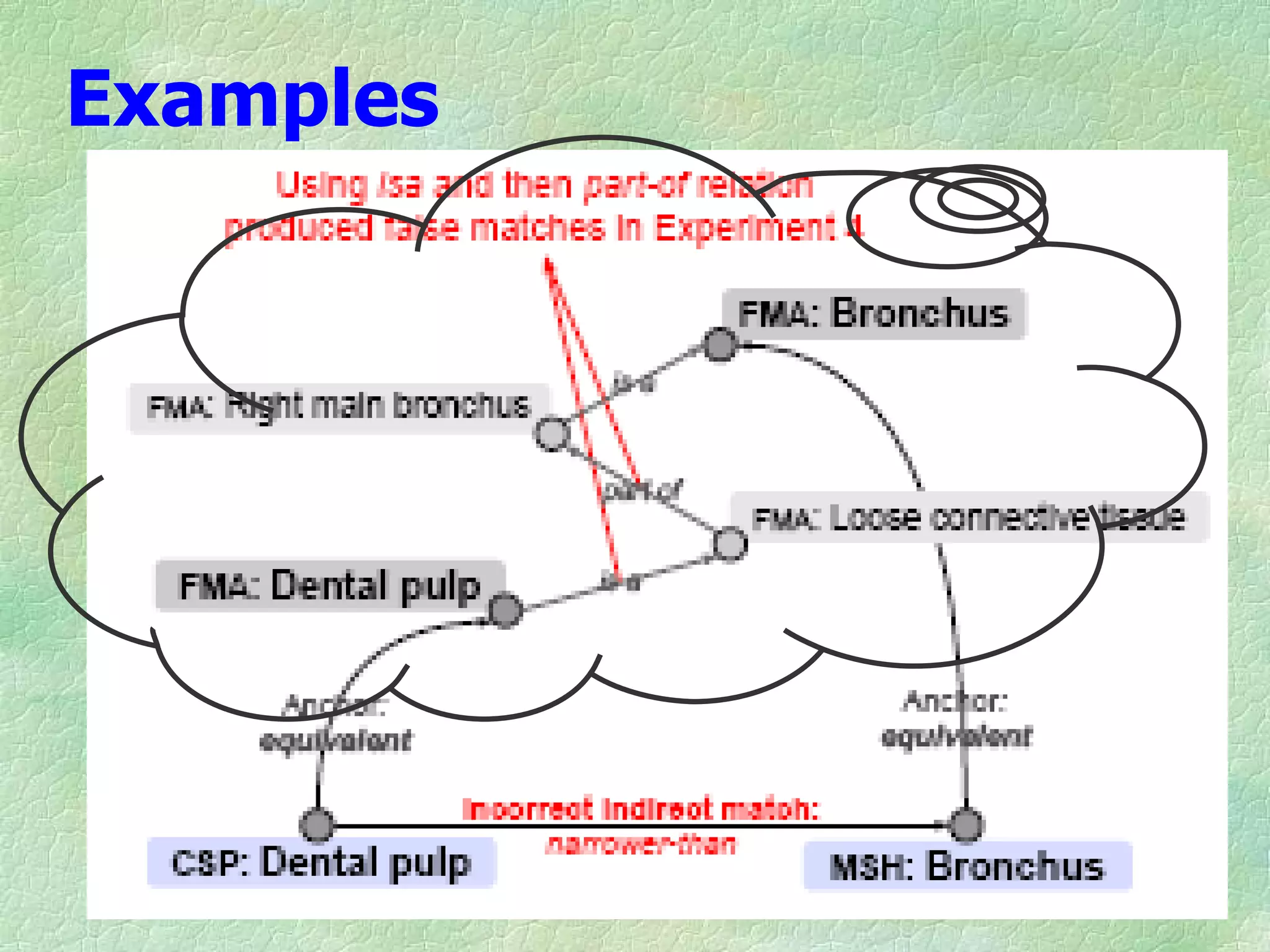
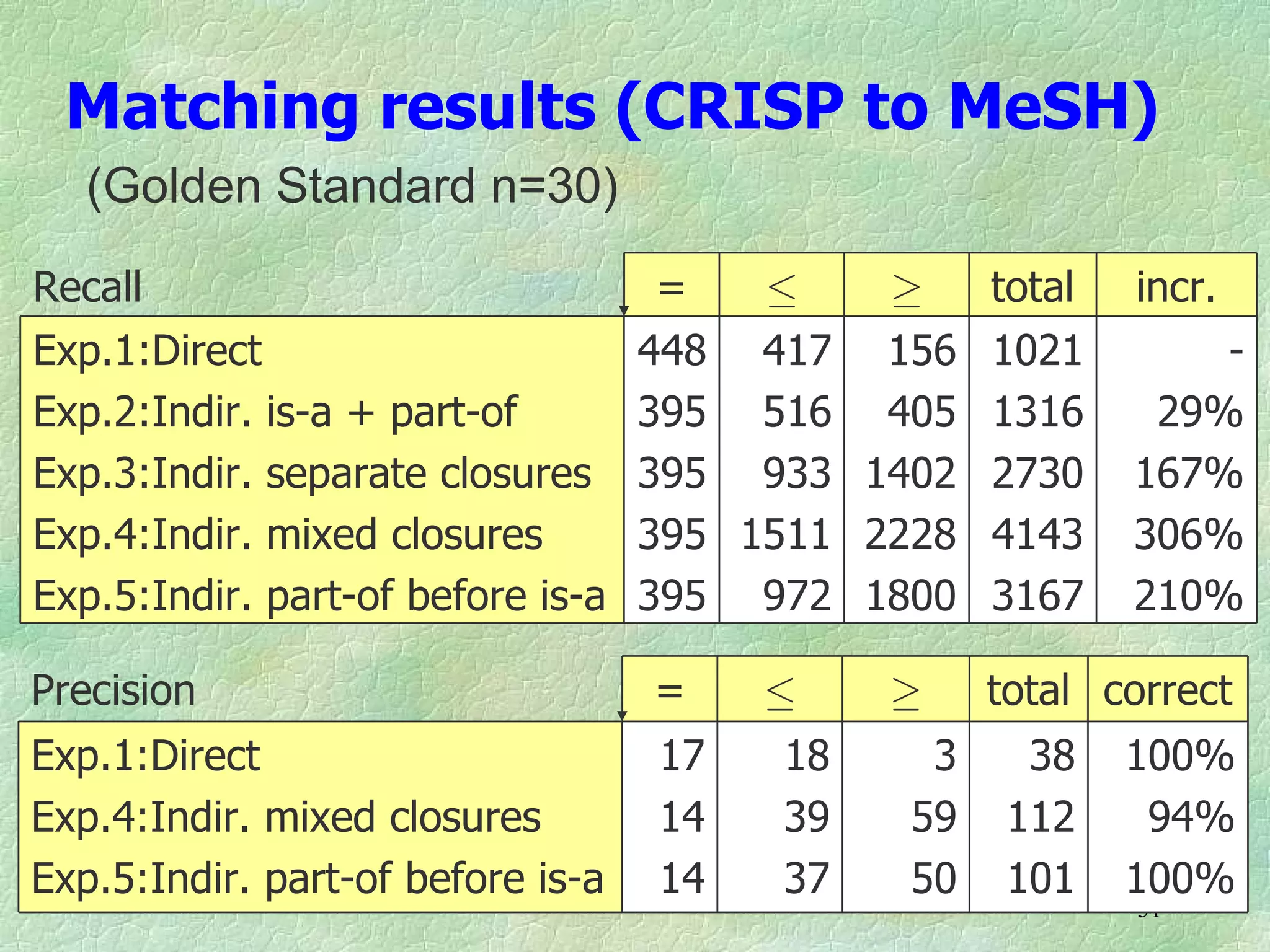

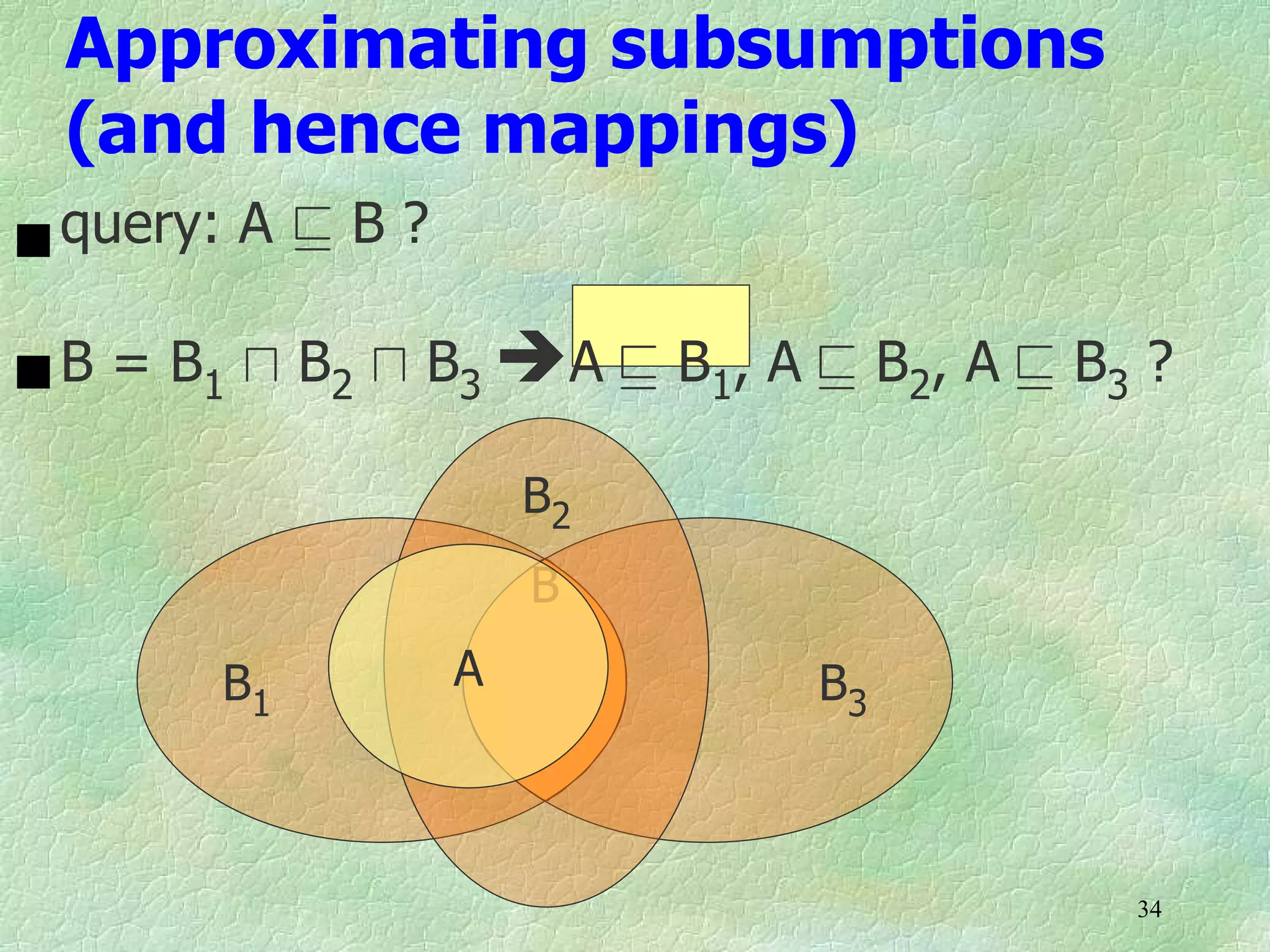

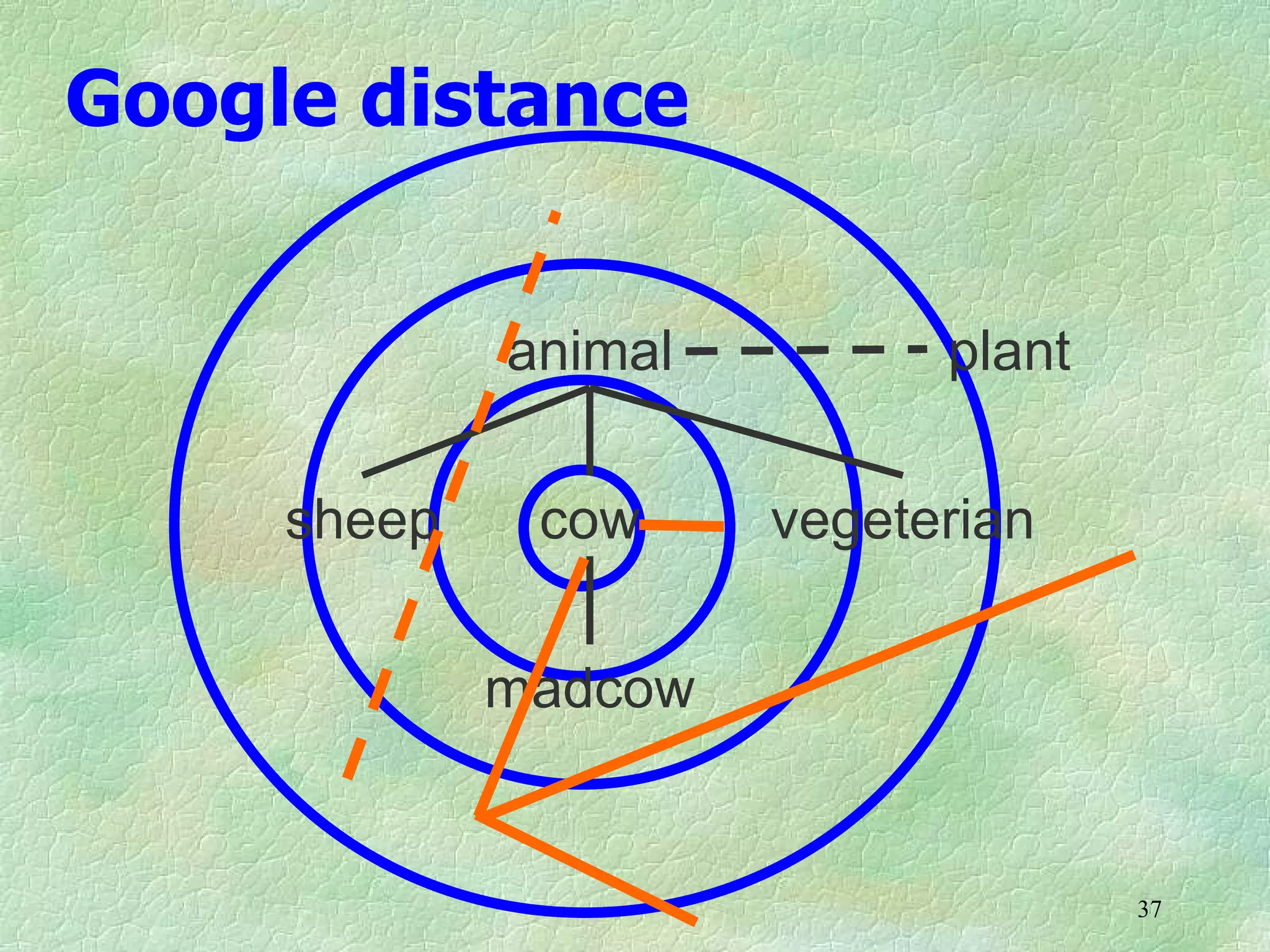


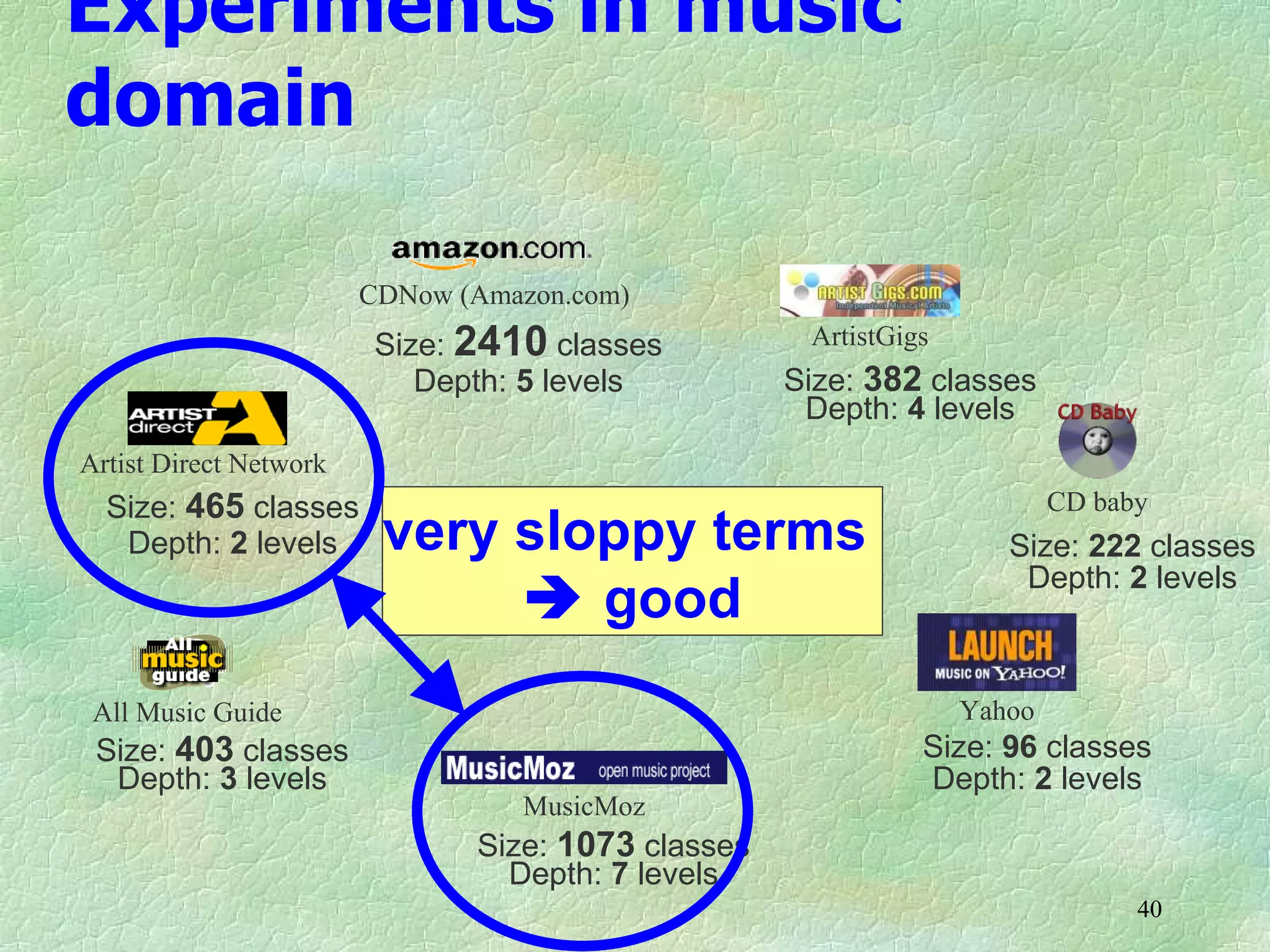
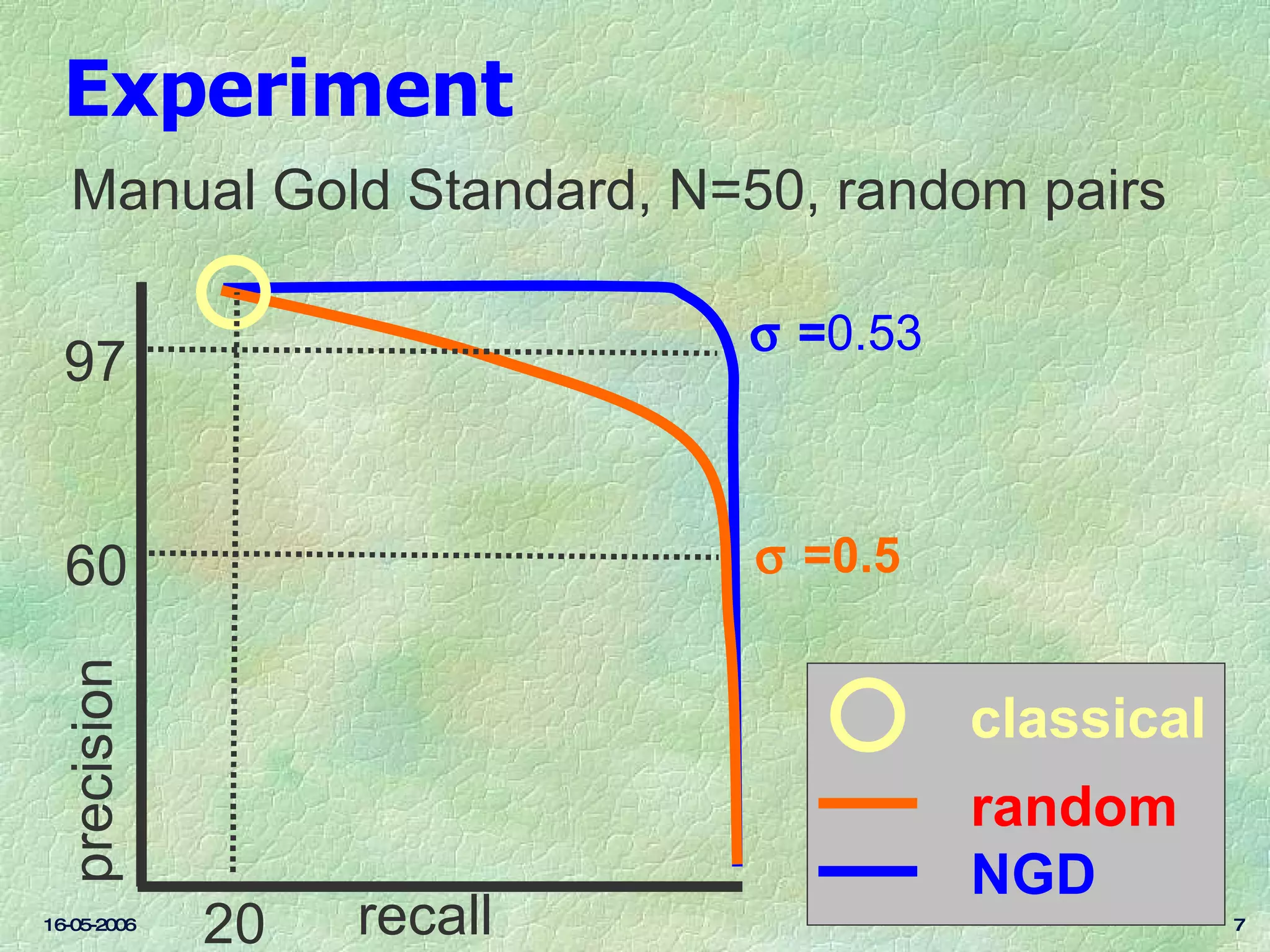



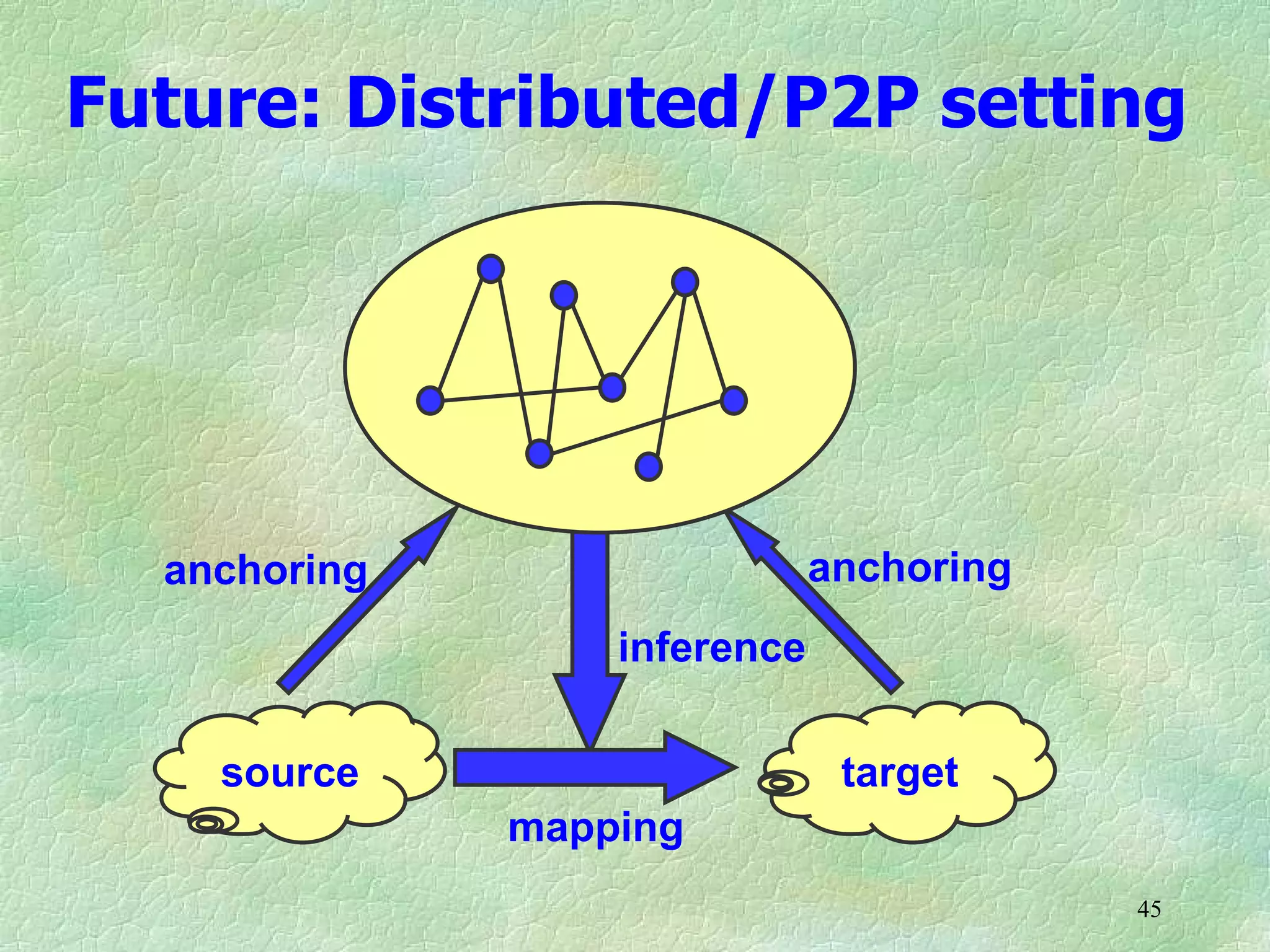


Ontology mapping requires context, background knowledge, and approximation. Using background knowledge from multiple large ontologies can improve ontology mapping results between two target ontologies by discovering more matches. Exploiting the hierarchical structure in background ontologies through indirect subsumption reasoning can significantly increase the number of matches found. Allowing for approximate matches by introducing a "sloppiness" threshold based on the semantic distance between concepts can further improve results by discovering desirable matches while avoiding undesirable ones except at high sloppiness levels.























![Matching Domain Ontologies A Comparative Study [Mode De Compatibilité]](https://cdn.slidesharecdn.com/ss_thumbnails/matchingdomainontologiesacomparativestudymodedecompatibilit-090412044904-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































