
















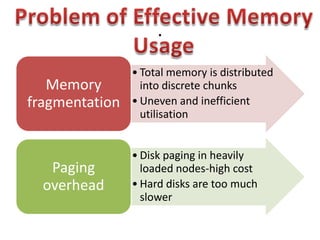
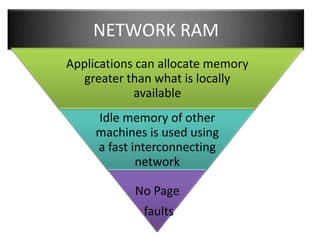
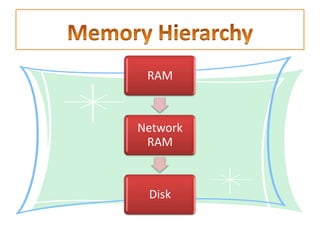

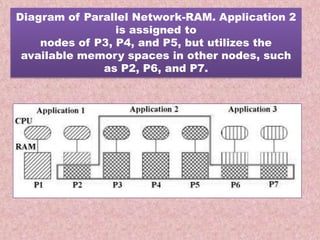

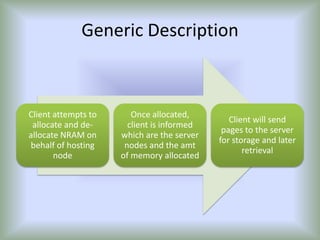
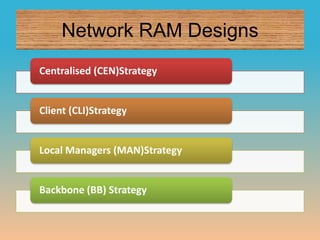
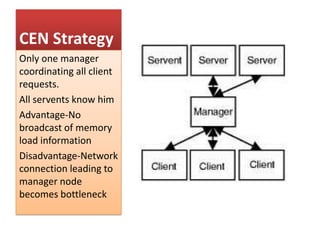
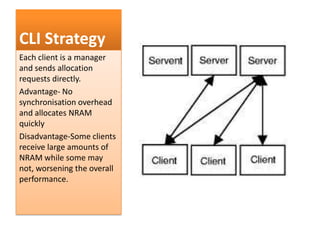
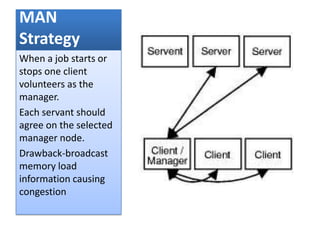
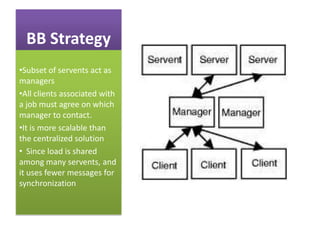



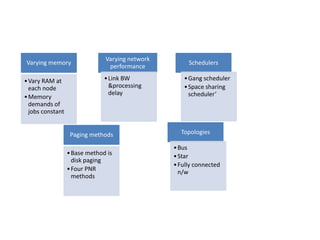







This document summarizes a seminar on parallel computing. It defines parallel computing as performing multiple calculations simultaneously rather than consecutively. A parallel computer is described as a large collection of processing elements that can communicate and cooperate to solve problems fast. The document then discusses parallel architectures like shared memory, distributed memory, and shared distributed memory. It compares parallel computing to distributed computing and cluster computing. Finally, it discusses challenges in parallel computing like power constraints and programmability and provides examples of parallel applications like GPU processing and remote sensing.























































![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































