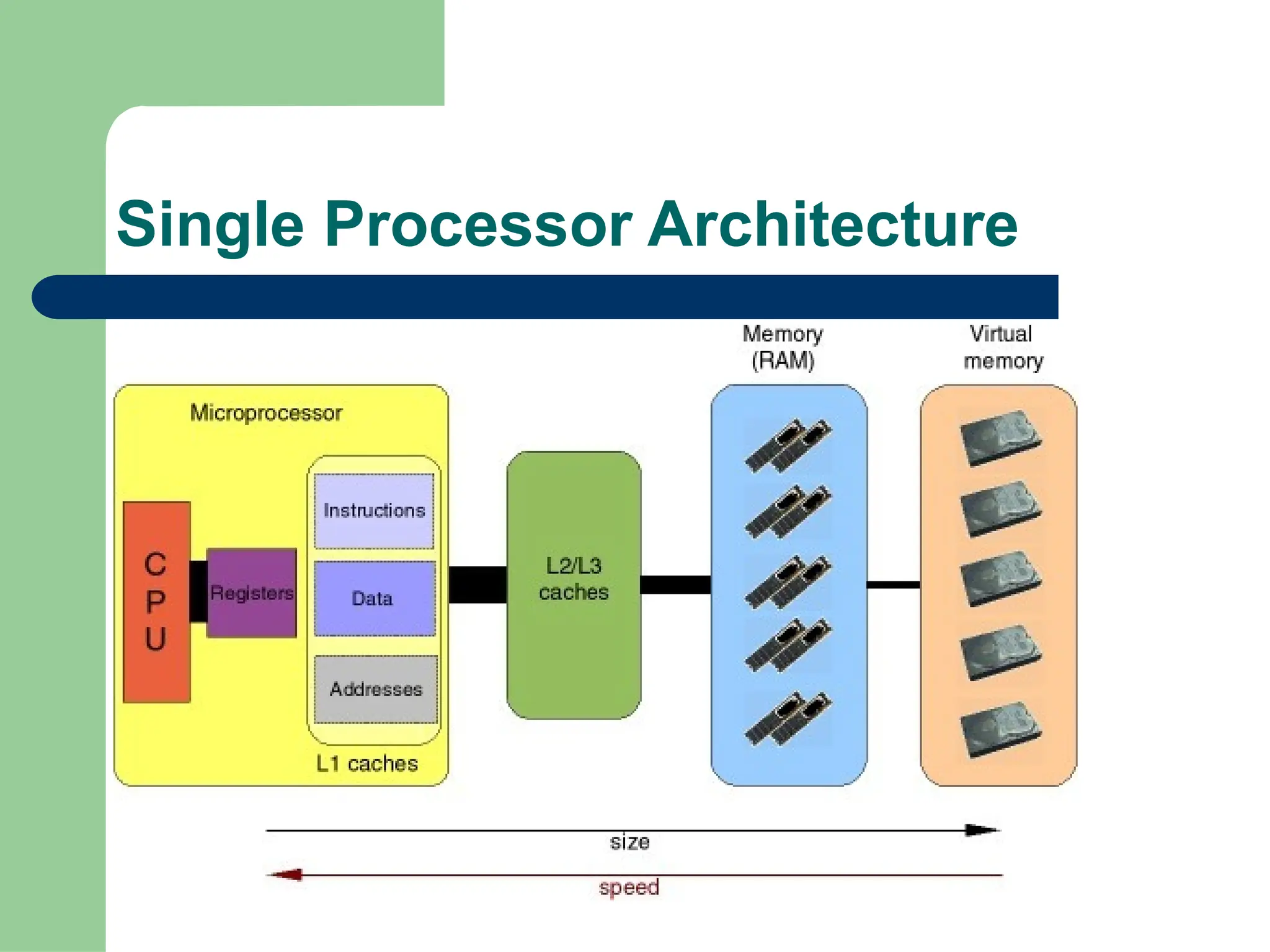
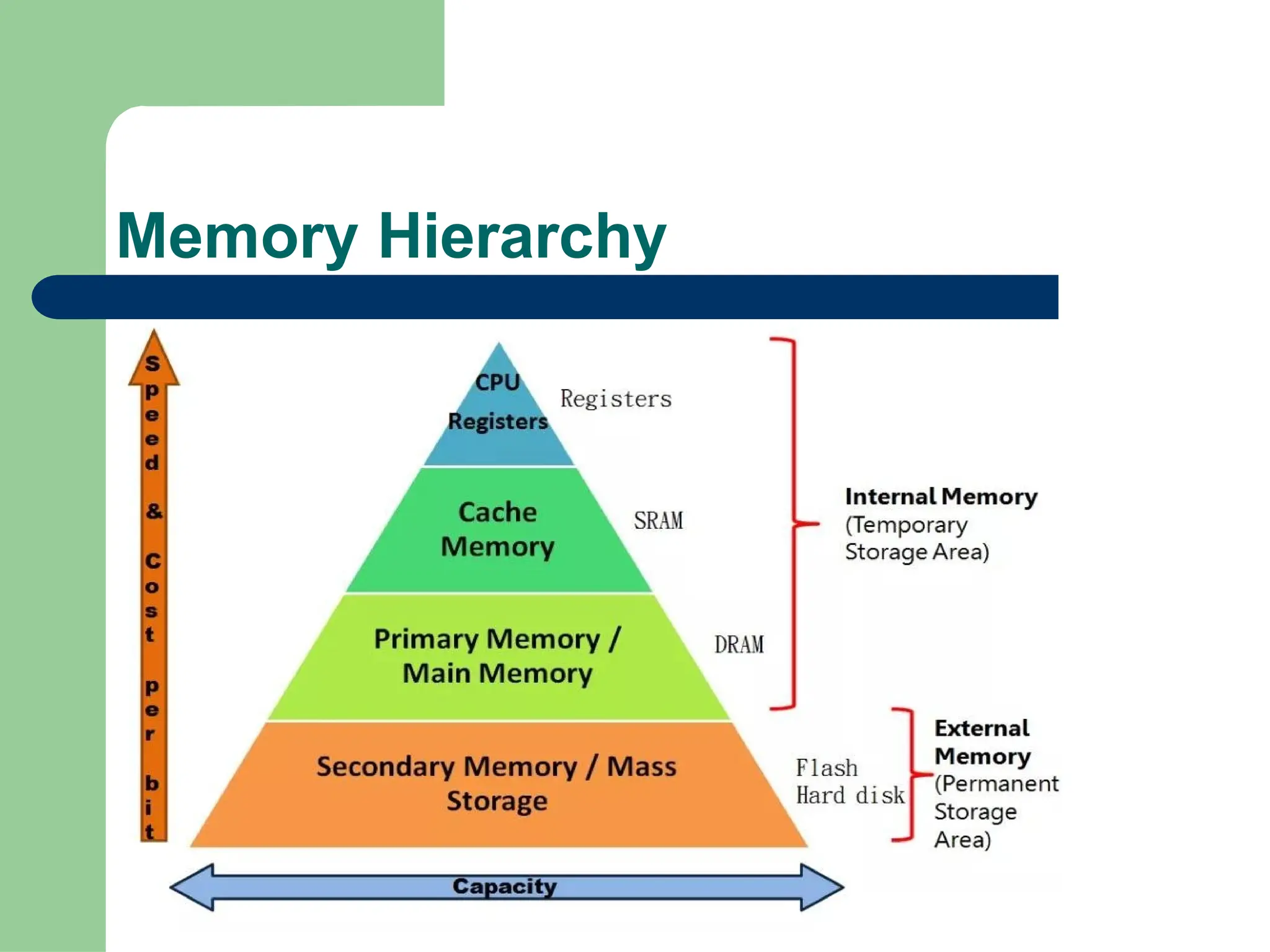
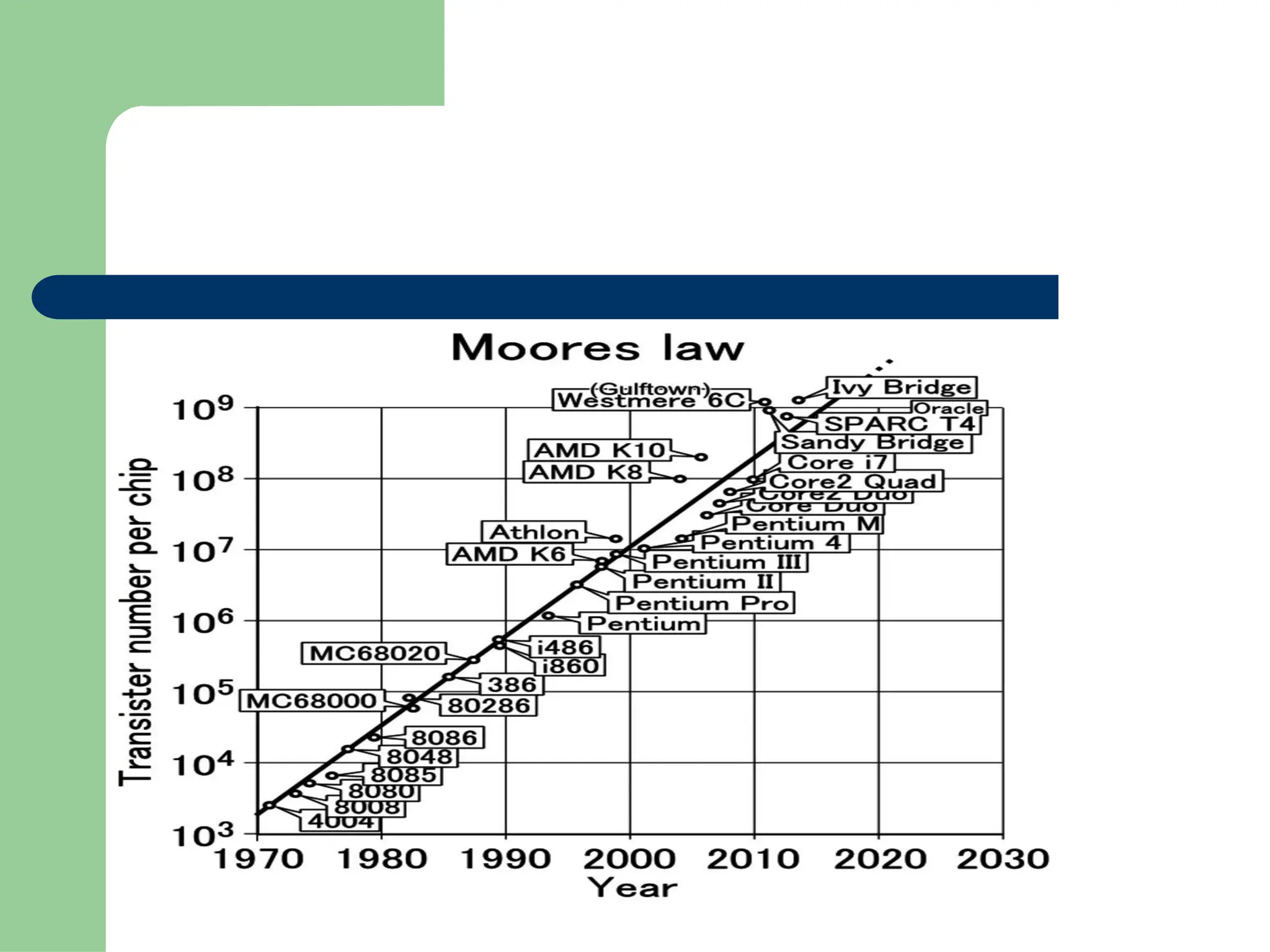
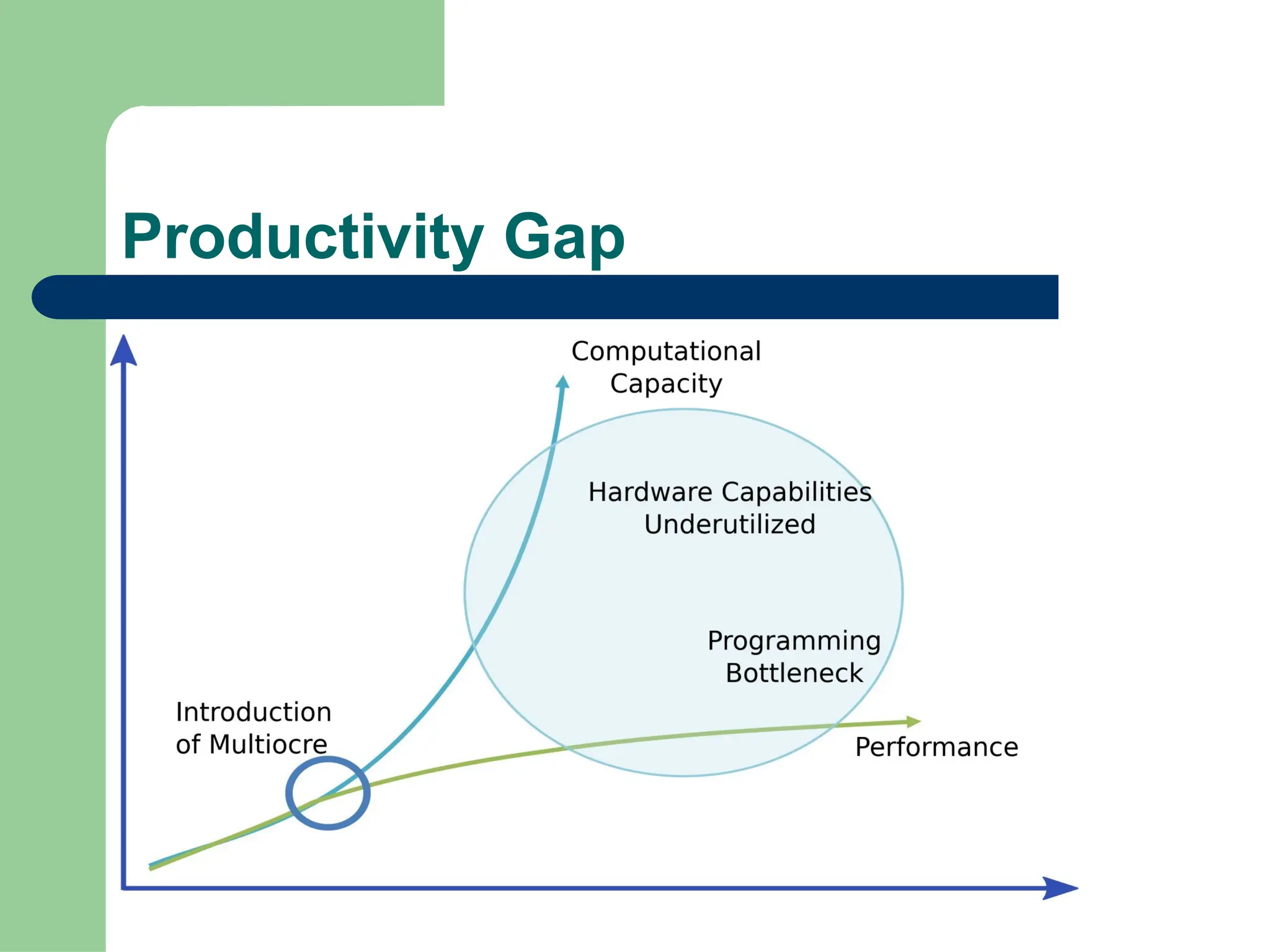
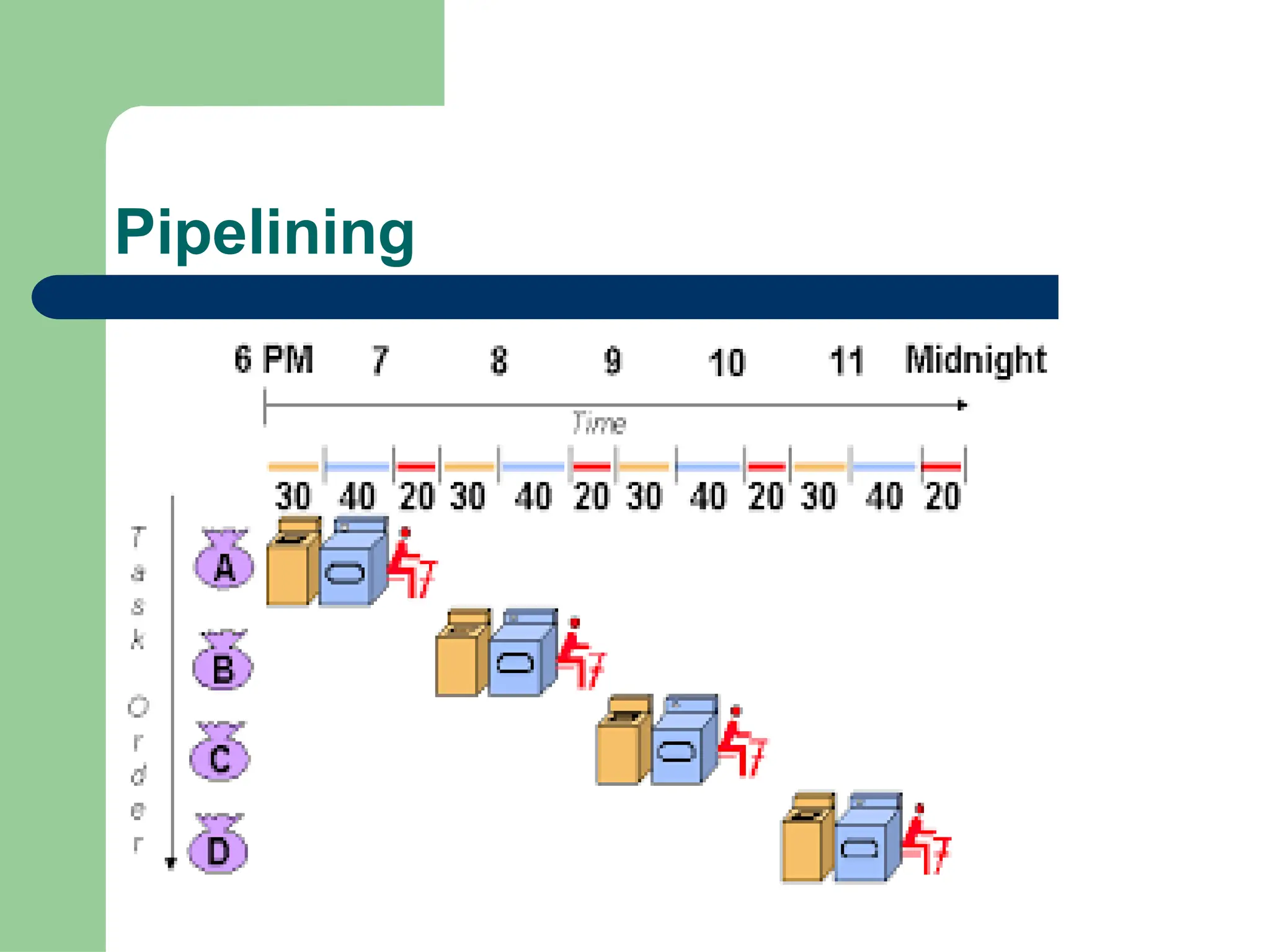
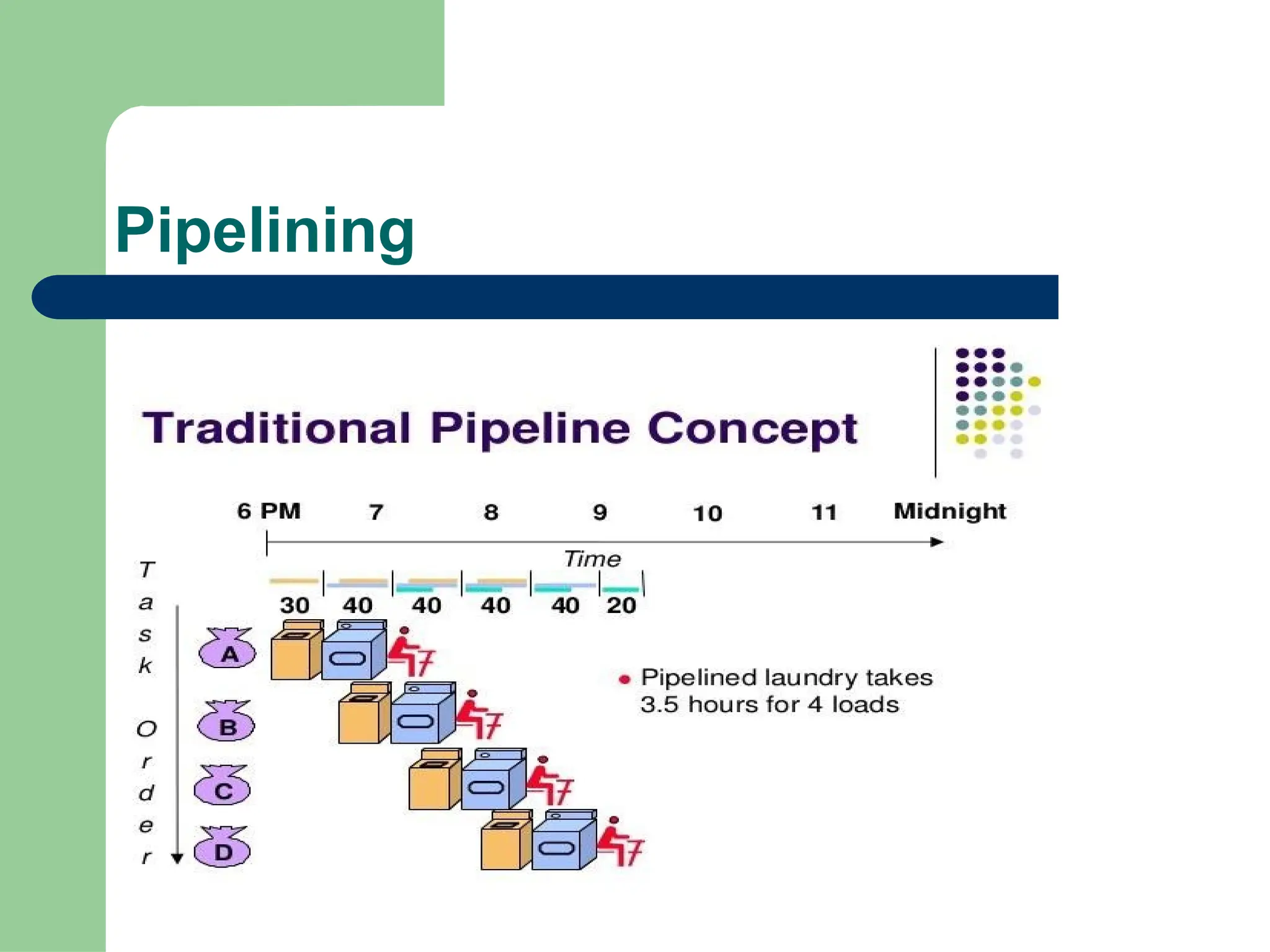
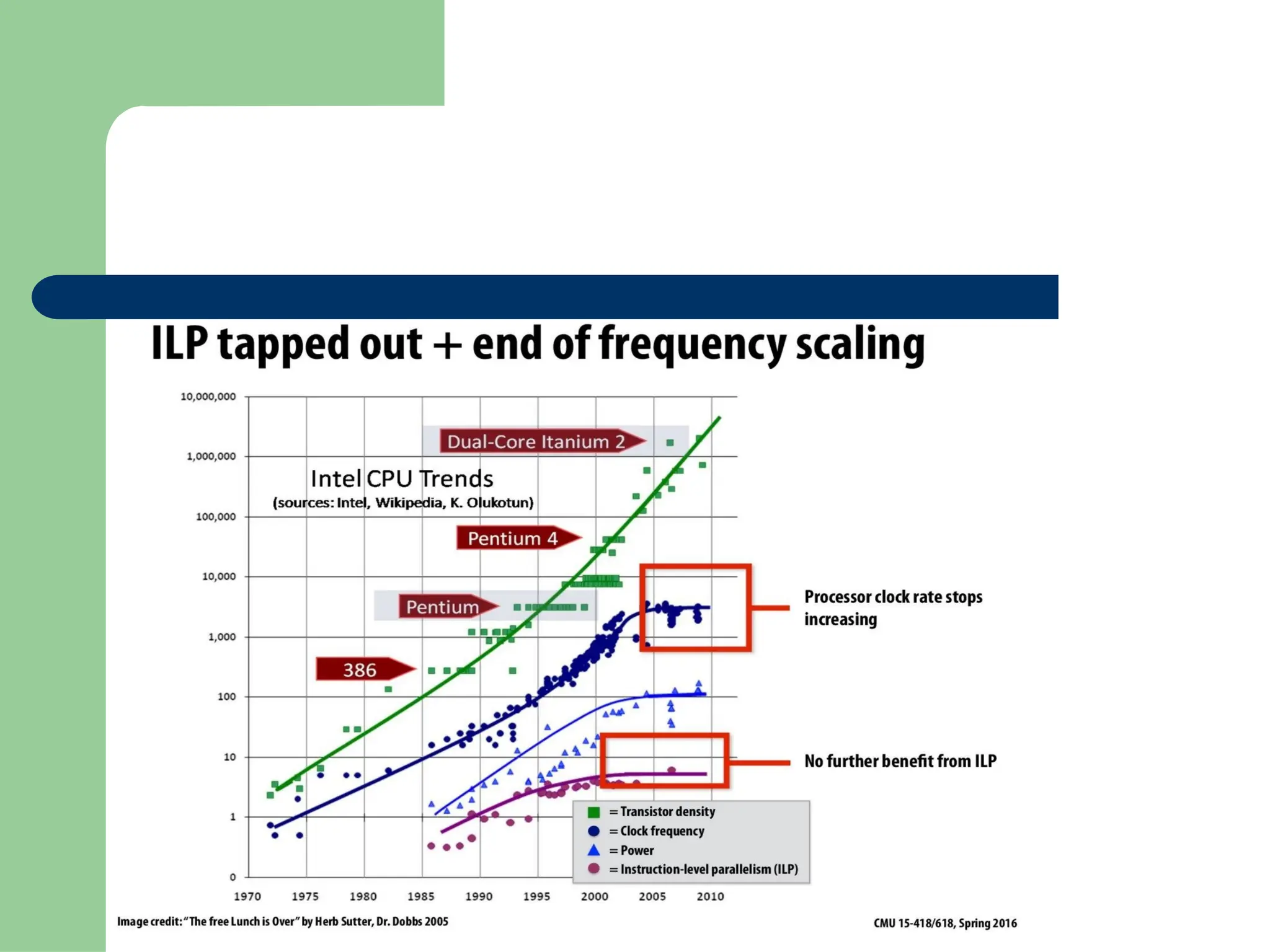
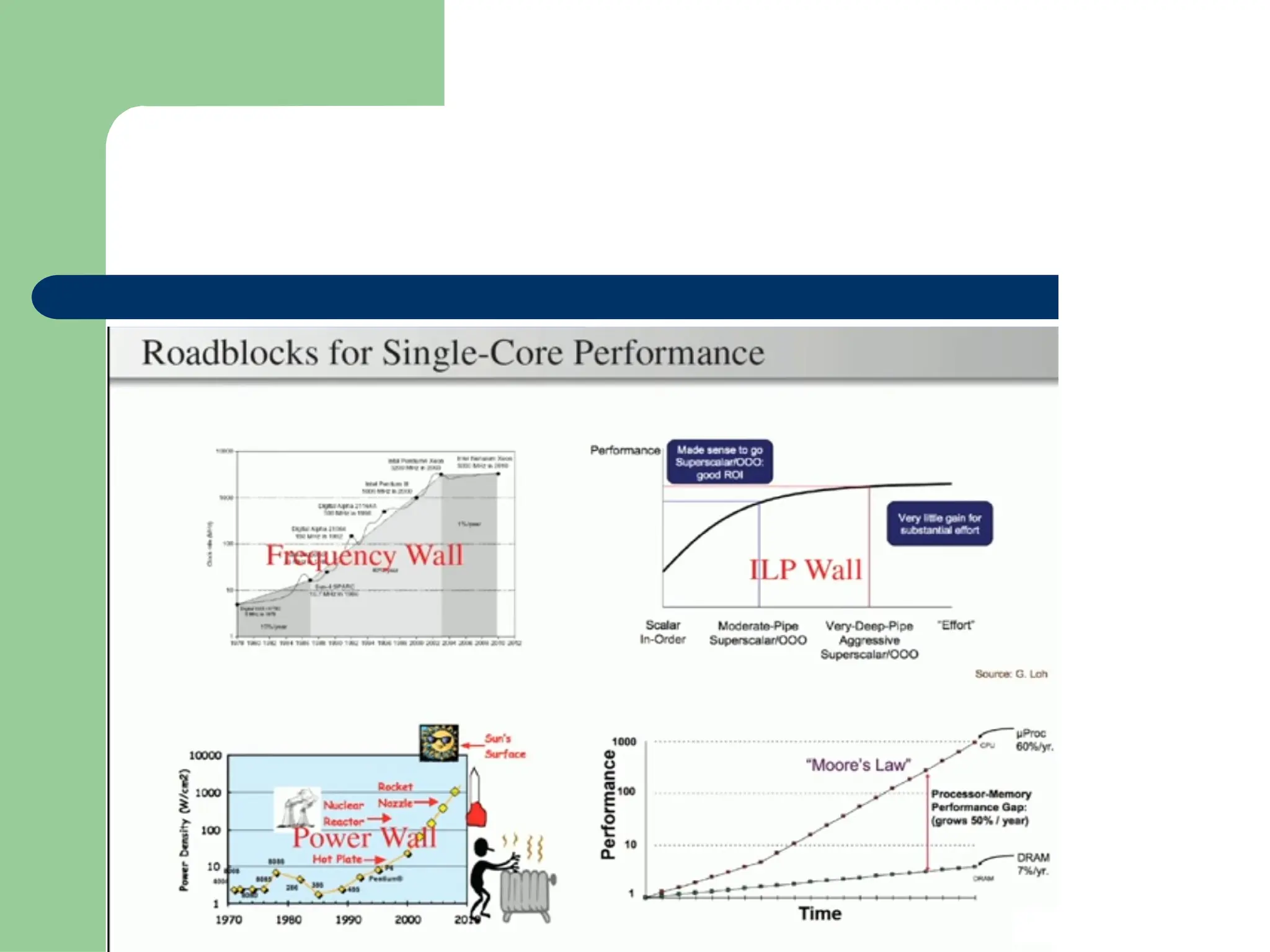
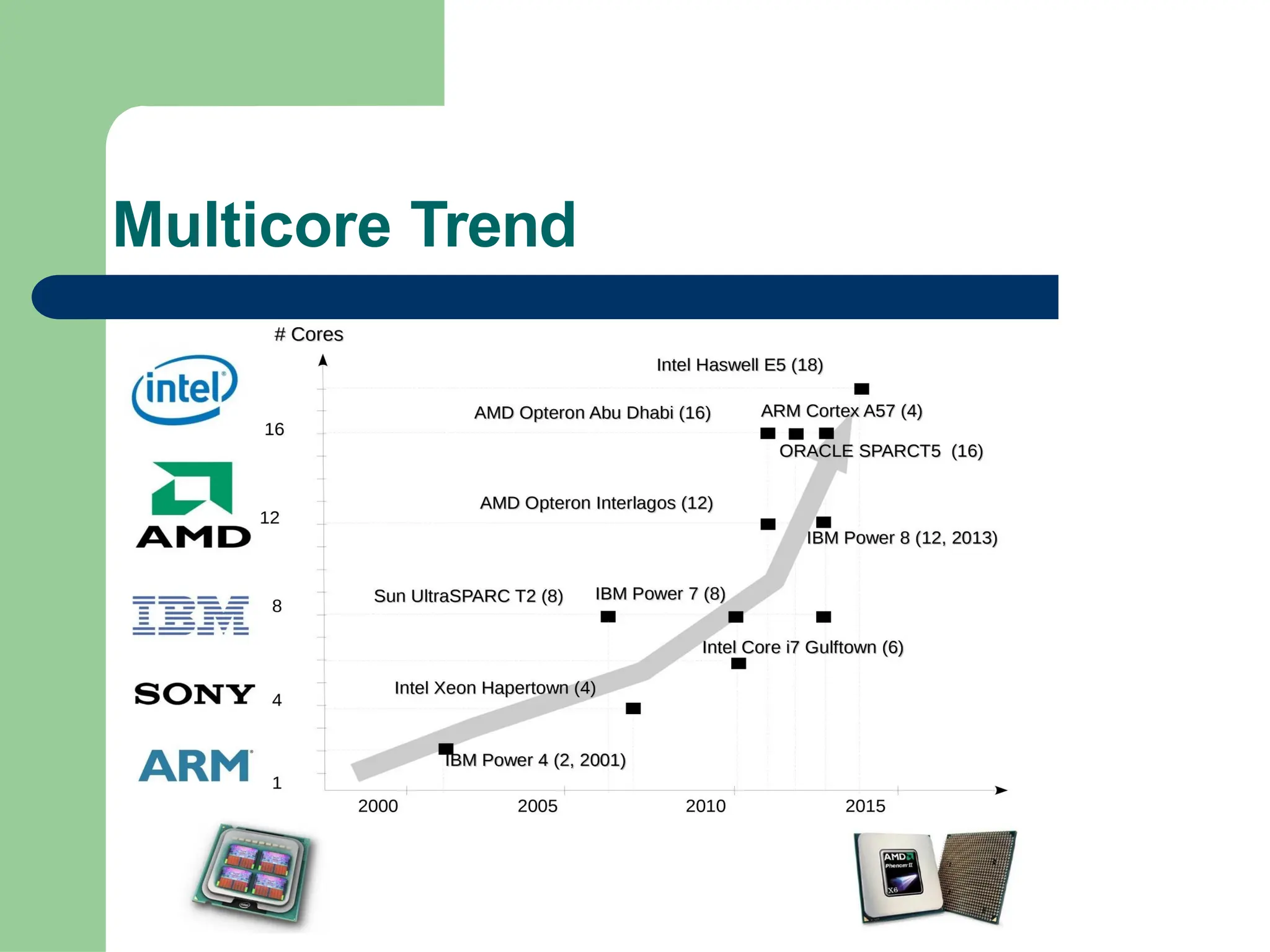
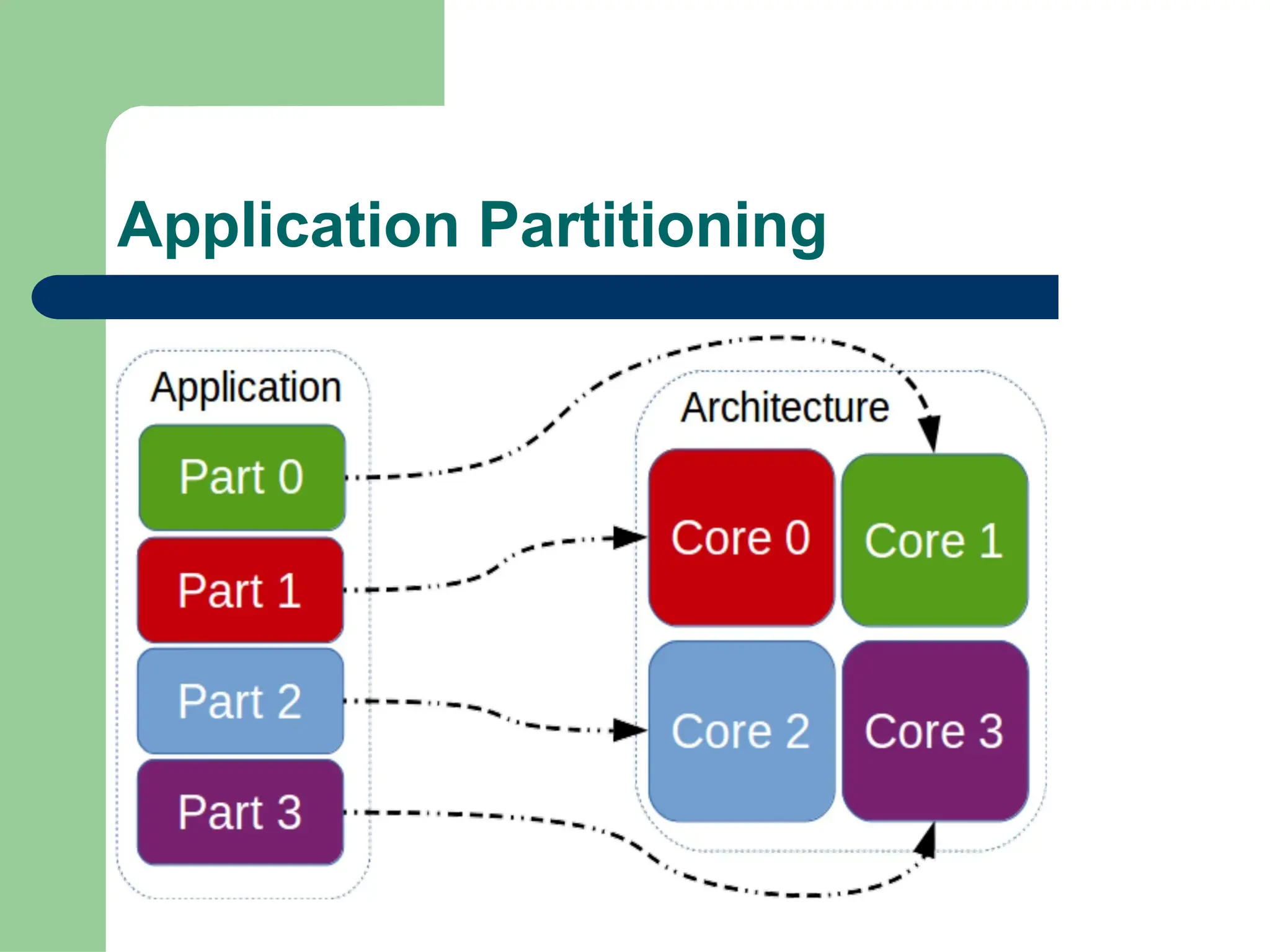
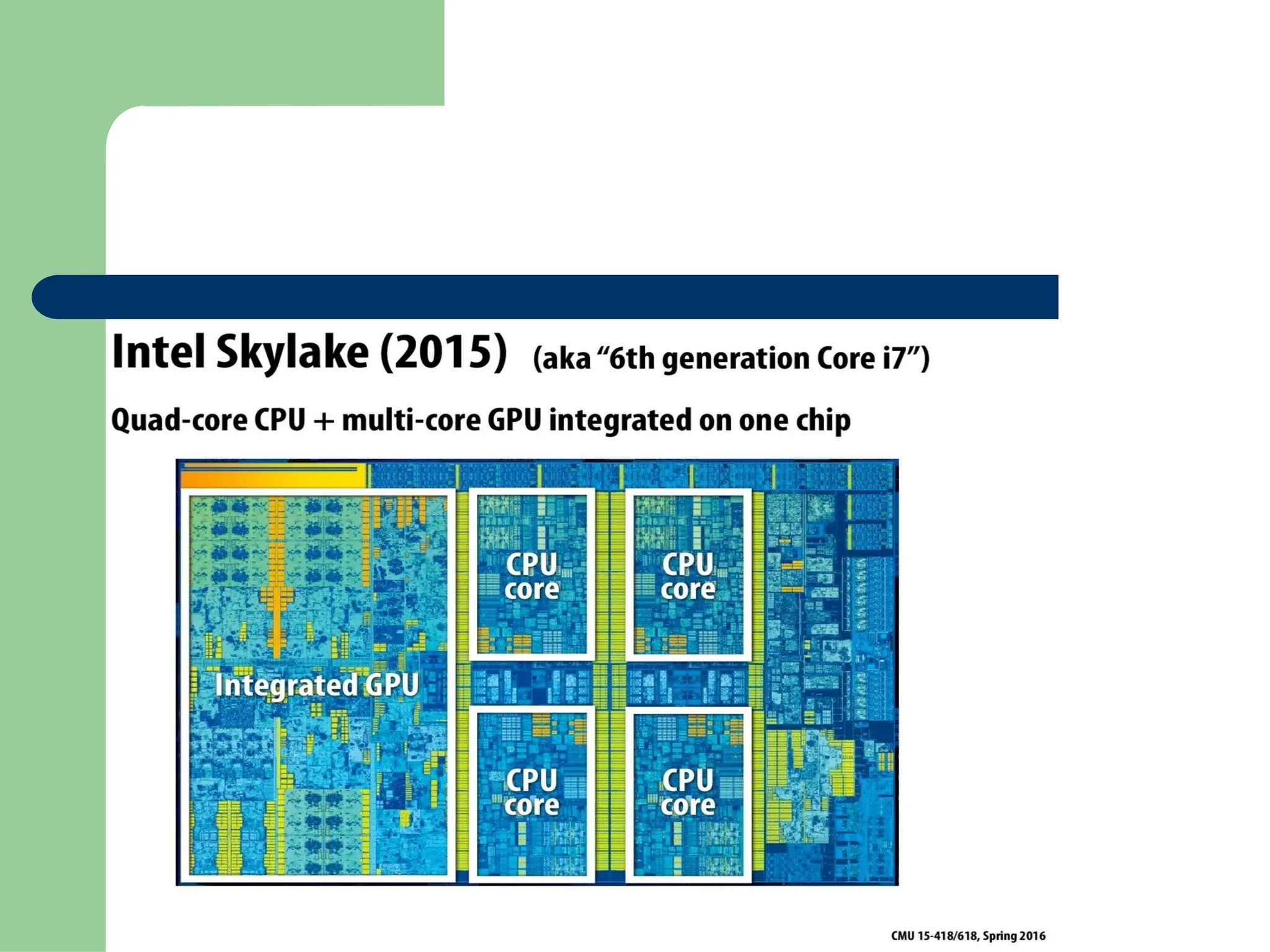
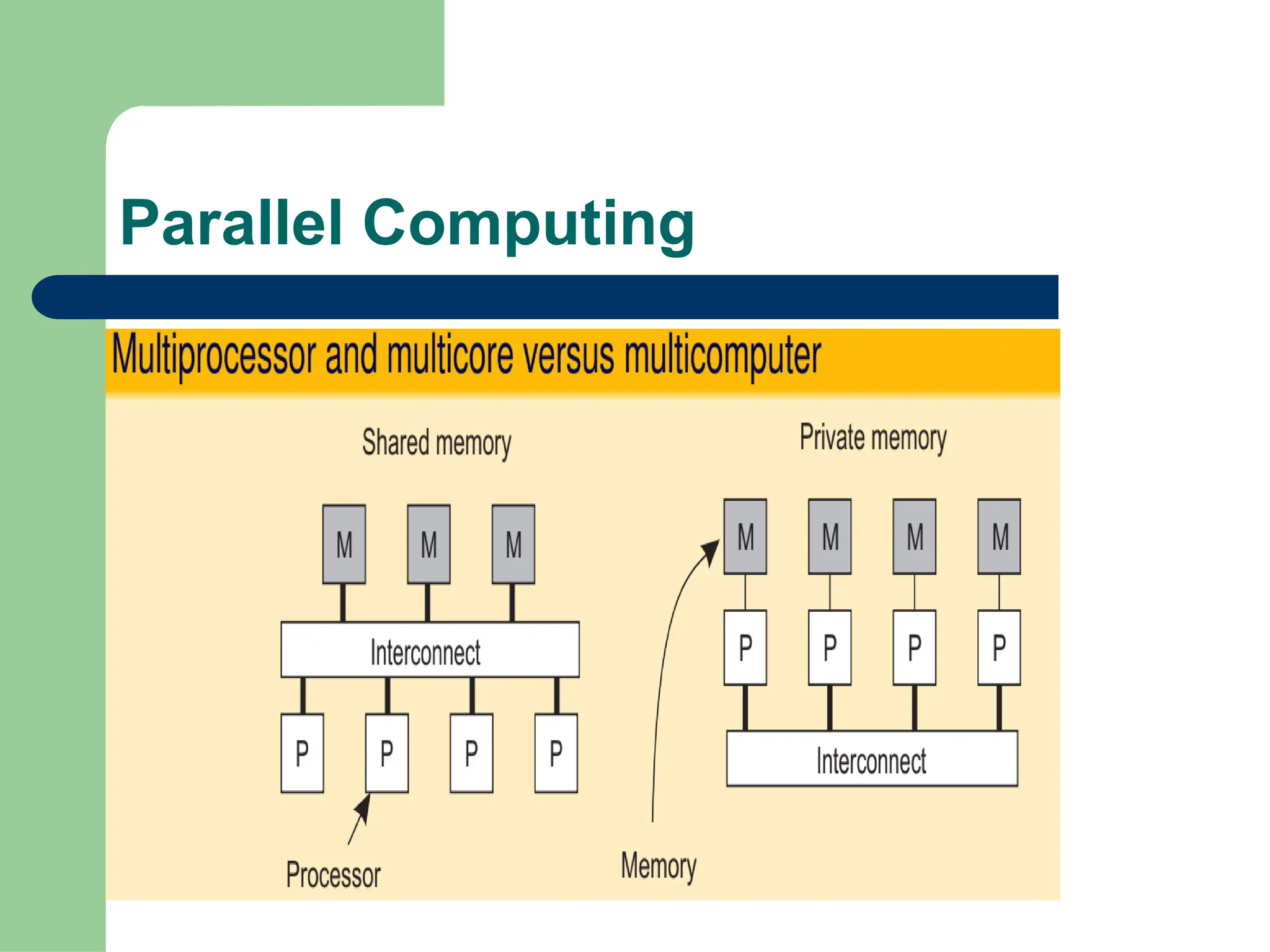
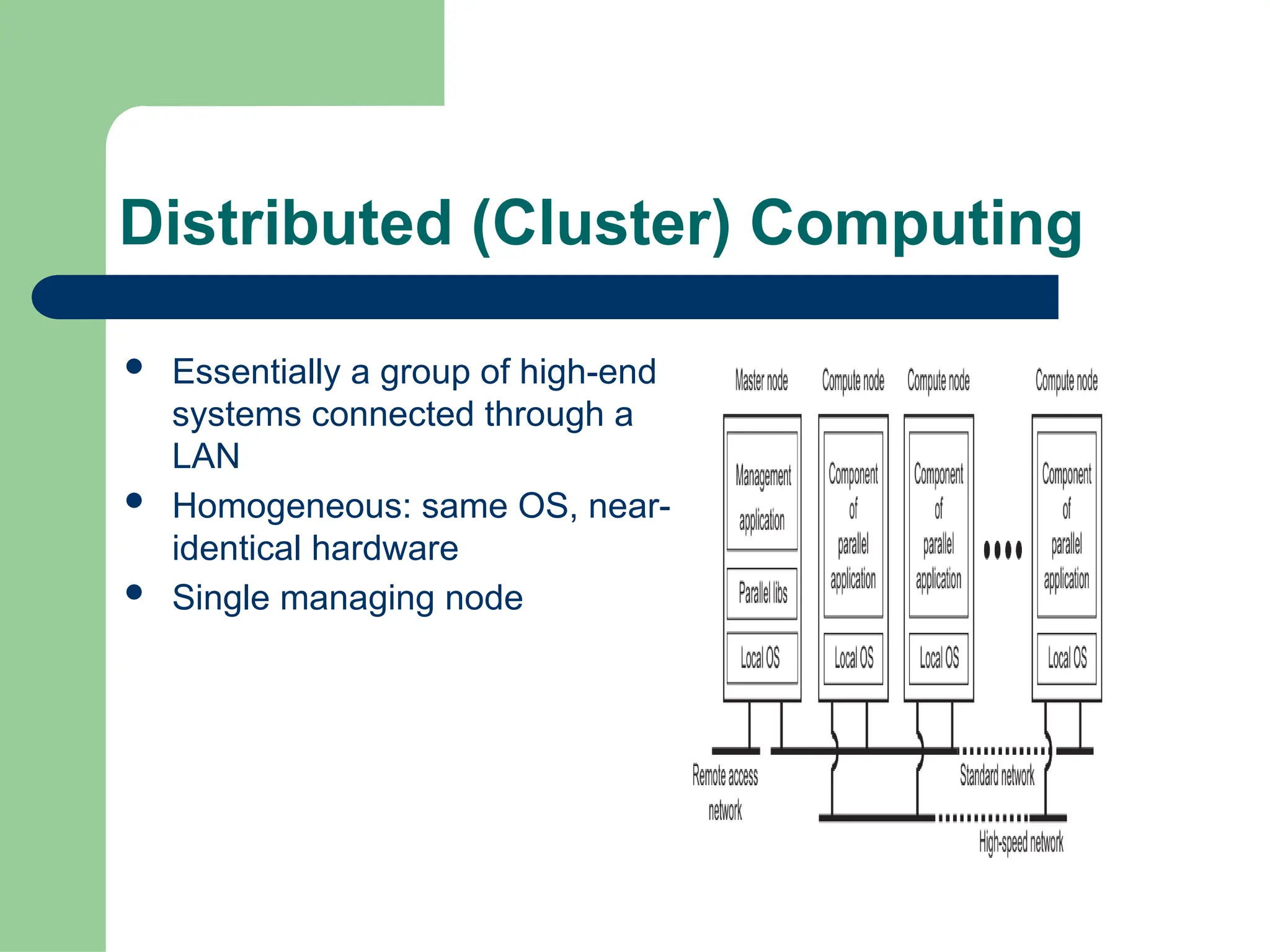
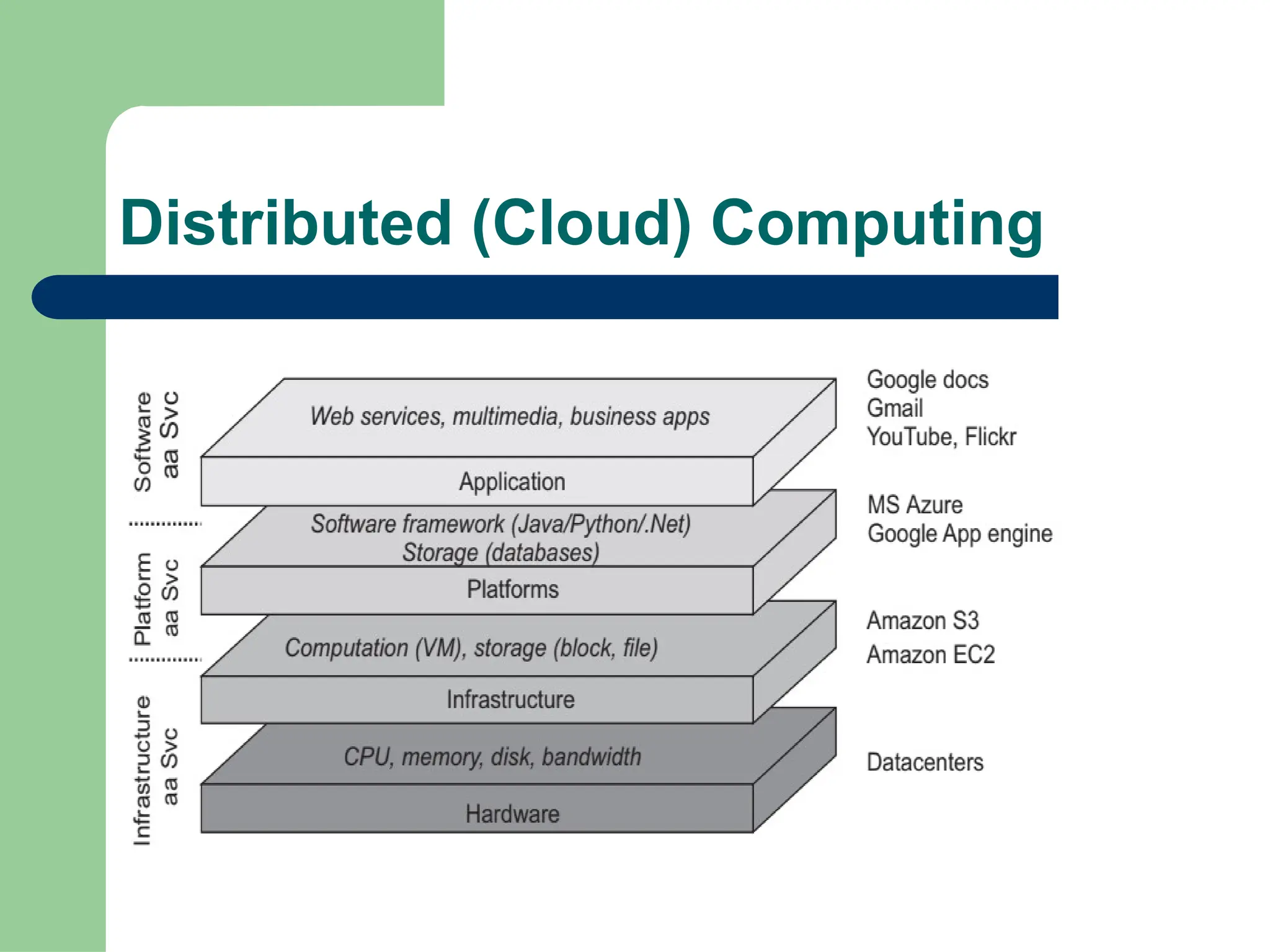
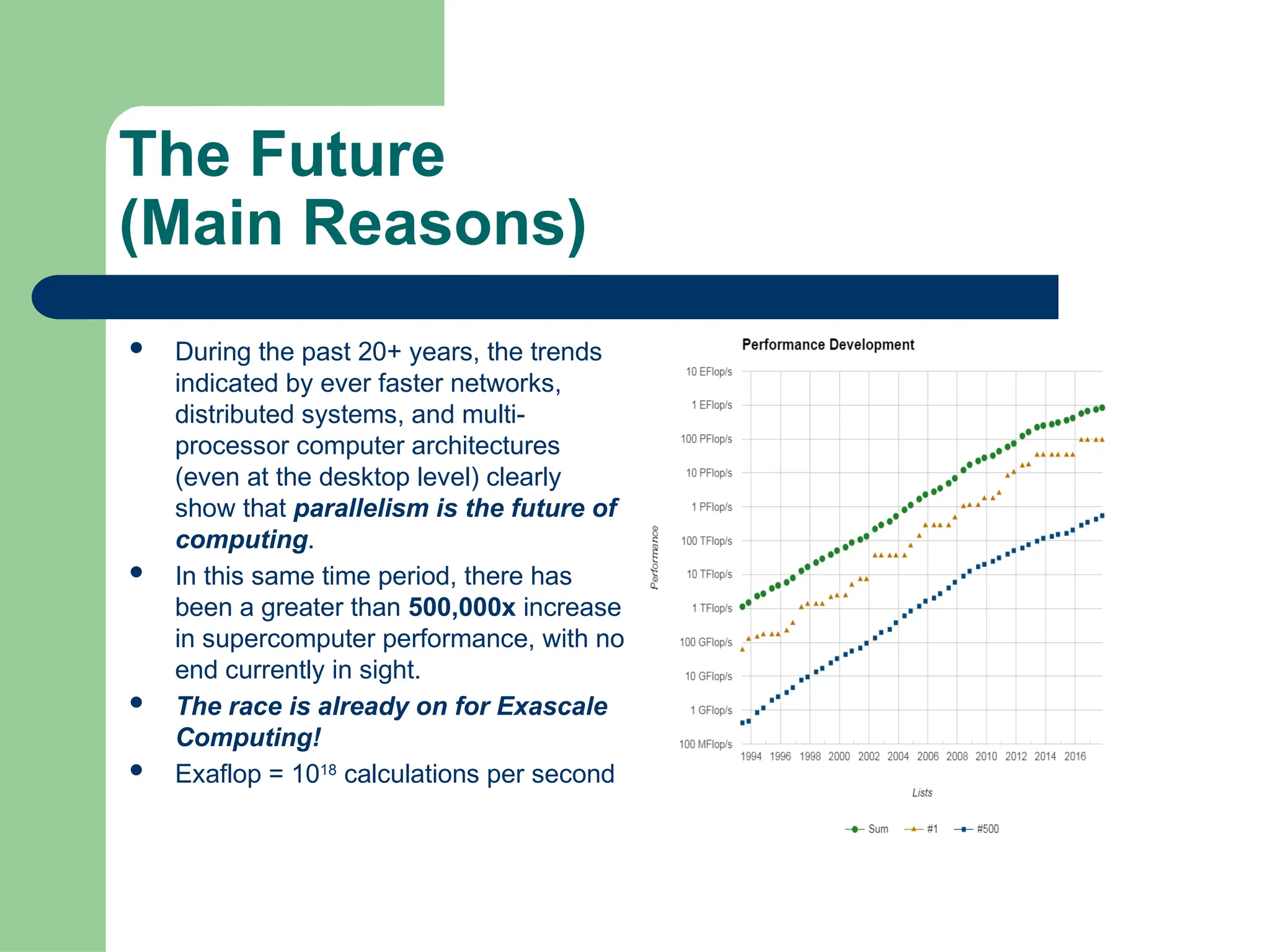
Parallel vs Distributed Computing: Core Differences Explained
Parallel computing divides a single task among multiple processors to run simultaneously, often within one computer with shared memory, whereas distributed computing uses multiple independent computers connected by a network to work on tasks.