www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
2.การจัดหมวดหมู่ของคา(Lexical Chain)
REPEAT
READnext word
IFword is suitable for lexical analysis (see section 3.2.1)THEN
CHECKfor chains within a suitable span
(up to 3 intermediary sentences, and nolimitation on returns):
CHECKthesaurus for relationships (section 3.2.2).
CHECKother knowledgesources
(situational, general words,proper names).
IF chain relationship is foundTHEN
INCLUDEword in chain.
CALCULATEchain so far
(allow one transitive link).
ENDIF
IF there are wordsthat have not formed a chain for a suitable
number of sentences (up to 3) THEN
ELIMINATEwordsfrom the span.
ENDIF
CHECKnew wordfor relevance to existing chains that
are suitable for checking.
ELIMINATEchains that are not suitable for checking.
ENDIF
ENDREPEAT
1. กาหนดให้เซตของคาที่จะสร้าง Chain เป็น n1 .. nm และ v1 .. vm
2. เริ่มต้นด้วยการเลือกคาหลักคานามที่1 (n1) และคาหลักคากริยาที่1 (v1) กาหนดให้เป็น
ส่วนหัวเริ่มต้น Chain ที่1 (Cn1) และ (Cv1) ของคาหลักคานามและคาหลักคากริยาตาม
ลาดับ
3. เลือกคาที่2 (n2) และ (v2)
ค้นหา Chain ตั้งแต่ Cn1 ... Cnm และ Cv1 ... Cvm โดยพิจารณาความสัมพันธ์ในลักษณะ
ต่างๆ ที่ปรากฏในฐานความรู้เวิร์ดเนต ที่ทาให้ n2 และ v2 มีความสัมพันธ์กับคาที่อยู่ใน
Chain แบบใดแบบหนึ่งดังต่อไปนี้
1) Extra-strong (Repection)
2) Strong (Synonym, kindOf, Is-A, hasPart, part of, oppositeOF)
3) Medium-strong (ความสัมพันธ์แบบถ่ายถอด) ถ้าพบความสัมพันธ์แบบใดแบบ
หนึ่ง จะทาการเพิ่ม n2 และ v2 เข้าไปใน Chain ที่พบความสัมพันธ์แบบเหนียว
แน่นที่สุด (mostly strong) หรือถ้าพบความสัมพันธ์ที่มีความเหนียวแน่นเท่ากัน
ให้เพิ่มลงใน chain ที่ update ล่าสุด ถ้าไม่พบ ทาการสร้างให้ n2 และ n2 เป็น
ส่วนหัวของ Chain ใหม่
4. ทาซ้าขั้นตอนที่3 จนถึงค่า nm และ vm
ภาพที่1: ลาดับขั้นตอนการสร้าง Lexical Chain
14.
ทฤษฎีที่เกี่ยว้้อง
www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
3. การคานวณค่าน้าหนัก LexicalChain
𝑆 𝑘 = (
𝑚=1
𝑃 𝑘+1
𝑡𝑓 𝑚𝑘 𝑅 𝑚𝑘 𝑊 𝑚𝑘)𝐻 𝑘
โดย Sk คือ ค่าน้าหนักของ Lexical Chain ที่ k
m คือ คาหลักที่ m
fmk คือ ความถี่ของการเกิดคาหลักที่ m ที่เกิดขึ้นซ้าใน Lexical Chain ที่ k
Rmk คือ น้าหนักของความสัมพันธ์ของคาที่ m ใน Lexical Chainที่ k
Wmk คือ น้าหนักของคาหลักที่ m ที่เกิดซ้าใน Lexical Chain ที่ k
Hk คือ ค่า Homogeneity Index ซึ่งคานวณได้จาก
𝐻 𝑘 = 1 −
𝑃𝑘
𝐿 𝑘
โดย Lk คือ จานวนสมาชิกที่เกิดแตกต่างกันใน Lexical Chain ที่ k
Pk คือ จานวนคาหลักที่เป็นสมาชิกทั้งหมดใน Lexical Chain ที่ k
(2)
(3)
เป็นการคานวณและให้ค่าน้าหนักในแต่ละ Chain ว่าสมาชิกใน
Chain มีความสัมพันธ์กันมากน้อยเพียงใดการหาค่าน้าหนักของ
Lexical Chain สามารถคานวณได้จากสมการ







![ทฤษฎีที่เกี่ยว้้อง
www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
1 เว็บเชิงความหมาย (Semantic Web)
เว็บเชิงความหมาย (Semantic Web)[1,2] เป็นการจัดการข้อมูลในลักษณะ
ของการเชื่อมโยงความสัมพันธ์ของข้อมูลในระดับเมตาดาต้า (Metadata) เพื่อทาการ
อ่านข้อมูลแบบออนไลน์ทาให้เครื่องคอมพิวเตอร์สามารถเข้าใจ ความหมายของข้อมูลต่างๆ
ได้ว่าเป็นอะไรมาจากข้อมูลส่วนไหนของชุดข้อมูล ทาให้คอมพิวเตอร์ สามารถนาข้อมูล
ที่ได้นั้นไปประมวลผลได้โดยอัตโนมัติ ยกตัวอย่างเช่น
ถ้าคอมพิวเตอร์พบข้อมูลว่า X เป็นน้องของ Y และ Z เป็นลูกของ Y
คอมพิวเตอร์จะสามารถรับรู้ได้เองว่า Z เป็นหลานของ X เป็นต้น](https://image.slidesharecdn.com/nccit2014-69-140610044036-phpapp01/85/Slide-ProceedingNccit-2014-69-8-320.jpg)
![ทฤษฎีที่เกี่ยว้้อง
www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
2 การตัดคา (Word Segmentation)
การตัดคา (Word segmentation) [3,4,5]คือการแบ่งตัวอักษรจากข้อความ
(String)เพื่อหาขอบเขตของแต่ละหน่วยคา (Morpheme) เนื่องจากส่วนมากภาษา
ไทยมีการเขียนในลักษณะที่ ติดกันโดยไม่มีการใช้เครื่องหมายวรรคตอนคั่นระหว่างคา
เหมือนภาษาอังกฤษซึ่งใช้ช่องว่าง(Space) คั่นระหว่างคา แต่ภาษาไทยจะมีการเว้นวรรค
เป็นระยะดังนั้นการตัดคาในงานวิจัยฉบับนี้ได้ใช้หลักการตัดคาโดยใช้พจนานุกรมโดยวิธี
เทียบคาที่ยาวที่สุด (Longest Matching) ซึ่งเป็นเทคนิคอย่างหนึ่งที่เป็นการตัดคา
ด้วยวิธีทาง Heuristic อย่างหนึ่ง และเมื่อทดสอบกับระบบผู้วิจัยพบว่าให้ประสิทธิภาพ
ที่ดีเมื่อใช้กับภาษาไทย](https://image.slidesharecdn.com/nccit2014-69-140610044036-phpapp01/85/Slide-ProceedingNccit-2014-69-9-320.jpg)
![ทฤษฎีที่เกี่ยว้้อง
www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
3 การสรุปใจความสาคัญ (Text Summarization)
การสรุปใจความสาคัญ (Text Summarization)[6] เป็นเทคนิคที่ใช้ในการสรุป
เนื้อหาของเอกสารโดยมีขั้นตอนในการสรุปเนื้อหาของเอกสารอยู่ 3ขั้นตอนคือขั้นตอนการ
วิเคราะห์คา ขั้นตอนการหาประเด็นสาคัญ และขั้นตอนการสังเคราะห์ประโยคโดยสามารถ
แบ่งวิธีการสรุปใจความสาคัญตามวิธีการสรุปแบบภาพรวม (Abstraction) ซึ่งเป็น
การวิเคราะห์คาจากต้นฉบับด้วยหลักการทางภาษาศาสตร์ (Semantic)โดยเป็นการถอด
ความหมายหรือแปลความหมายจากต้นฉบับผลที่ได้มีประสิทธิภาพและความถูกต้องมาก
กว่าการใช้วิธี Extraction ซึ่งวิธีการ Abstraction ประกอบด้วย 3 ขั้นตอนดังนี้](https://image.slidesharecdn.com/nccit2014-69-140610044036-phpapp01/85/Slide-ProceedingNccit-2014-69-10-320.jpg)




![ทฤษฎีที่เกี่ยว้้อง
www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
4 กฎความสัมพันธ์ (Association Rules)
การหากฎความสัมพันธ์ [7] คือ การได้มาของกฎความสัมพันธ์โดยการหารูปแบบที่เกิดขึ้น
บ่อยคู่กัน และเรียกว่า frequent pattern และความสัมพันธ์ที่เกิดขึ้น เรียกว่า
association ของกลุ่มไอเท็มจากข้อมูลที่อยู่ในรูปแบบ transaction ผลลัพธ์ที่ได้
จะอยู่ในรูปแบบของกฎความสัมพันธ์ (Association Rules)
item1 item2](https://image.slidesharecdn.com/nccit2014-69-140610044036-phpapp01/85/Slide-ProceedingNccit-2014-69-15-320.jpg)
![ทฤษฎีที่เกี่ยว้้อง
www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
4. กฎความสัมพันธ์ (Association Rules)(ต่อ)
ในงานวิจัยนี้ได้ใช้อัลกอรึทึมเพื่อหากฎความสัมพันธ์ คือ แอพพริออริ(Apriori) หาก
ต้องการทราบความสัมพันธ์ของกฎ จะต้องคานวณหาค่าสนับสนุน ค่าความเชื่อมั่นและการ
หาค่าสหสัมพันธ์ระหว่างข้อมูล เพื่อทราบความสัมพันธ์ของข้อมูลทั้งสองว่ามีความสัมพันธ์
มากน้อยเพียงใด
การคานวณหาค่าสนับสนุน Support
Support(XY) = P(X∪Y)
คือ ค่าความน่าจะเป็นของจานวนของค่าข้อมูล X เกิดขึ้นคู่กับค่าข้อมูล Y ซึ่งมีค่าอยู่ระหว่าง
[0-1] ถ้าค่าใกล้1 หมายถึงมีความสัมพันธ์กันมาก
(4)](https://image.slidesharecdn.com/nccit2014-69-140610044036-phpapp01/85/Slide-ProceedingNccit-2014-69-16-320.jpg)
![ทฤษฎีที่เกี่ยว้้อง
www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
4. กฎความสัมพันธ์ (Association Rules)(ต่อ)
การคานวณหาค่าความเชื่อมั่น Confidence (Conf)
Confidence(XY) = P(X∪Y)/P(X)
คือ ค่าความน่าจะเป็นของจานวนของค่าข้อมูล X เกิดขึ้นคู่กับค่าข้อมูล Y ตามมาเสมอโดยที่
มีลาดับเหตุการณ์ของข้อมูลเข้ามาเกี่ยวข้องซึ่งมีค่าอยู่ระหว่าง [0-1] ถ้าค่าใกล้1 หมายถึง
มีความสัมพันธ์กันตามลาดับของข้อมูลมาก
(5)](https://image.slidesharecdn.com/nccit2014-69-140610044036-phpapp01/85/Slide-ProceedingNccit-2014-69-17-320.jpg)
![ทฤษฎีที่เกี่ยว้้อง
www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
4. กฎความสัมพันธ์ (Association Rules)(ต่อ)
การคานวณหาค่าสหสัมพันธ์ (Lift)
Lift(XY) =
𝑃(𝑋∪𝑌)
𝑃 𝑋 𝑃(𝑌)
คือ ค่าความน่าจะเป็นของจานวนของค่าข้อมูล X เกิดขึ้นคู่กับค่าข้อมูล Y ตามมาเสมอโดยที่
มีลาดับเหตุการณ์ของข้อมูลเข้ามาเกี่ยวข้องซึ่งมีค่าอยู่ระหว่าง [0-1] ถ้าค่าใกล้1 หมายถึง
มีความสัมพันธ์กันตามลาดับของข้อมูลมาก
(6)](https://image.slidesharecdn.com/nccit2014-69-140610044036-phpapp01/85/Slide-ProceedingNccit-2014-69-18-320.jpg)
![ทฤษฎีที่เกี่ยว้้อง
www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
5 การวัดประสิทธิภาพการสืบค้นของระบบ
การวัดประสิทธิภาพการสืบค้น [8] เป็นการตรวจสอบความถูกต้องของการสืบค้นเอกสาร
โดยพิจารณาจากระดับความ แม่นยา (Precision) และความครบถ้วน (Recall) รวม
ไปถึงประสิทธิภาพโดยรวมของการสืบค้น (F-Measure) ตามสมการต่อไปนี้
𝐹 − 𝑚𝑒𝑎𝑠𝑢𝑟𝑒 =
2𝑅𝑃
𝑅 + 𝑃
(7)](https://image.slidesharecdn.com/nccit2014-69-140610044036-phpapp01/85/Slide-ProceedingNccit-2014-69-19-320.jpg)




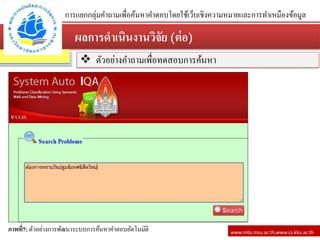
![วิธีดาเนินงานวิจัย (ต่อ)
www.mbs.msu.ac.th,www.cs.kku.ac.th
การแยกกลุ่มคาถามเพื่อค้นหาคาตอบโดยใช้เว็บเชิงความหมายและการทาเหมืองข้อมูล
ภาพที่4: ผลลัพธ์จากโปรแกรม Weka ที่ใช้ในการวิเคราะห์
การประมวลผลในโปแกรม Weka เพื่อหากฏที่ต้องการ
Best rules found:
1.Q8=4543 1 ==>A17=95650 1 conf:(1) <lift:(14.75)> lev:(0.01) [0] conv:(0.93)
2.A17=95650 8 ==>Q8=4543 1 conf:(0.13) <lift:(14.75)> lev:(0.01) [0] conv:(0.99)
3.Q9=4 4 ==>A19=39455 1 conf:(0.25) <lift:(9.83)> lev:(0.01) [0] conv:(0.97)
4.A19=39455 3 ==>Q9=4 1 conf:(0.33) <lift:(9.83)> lev:(0.01) [0] conv:(0.97)
5.Q10=81559 5 ==>A22=34997 1 conf:(0.2) <lift:(7.87)> lev:(0.01) [0] conv:(0.97)
6.A22=34997 3 ==>Q10=81559 1 conf:(0.33) <lift:(7.87)> lev:(0.01) [0] conv:(0.96)
7.Q14=95650 5 ==>A22=34997 1 conf:(0.2) <lift:(7.87)> lev:(0.01) [0] conv:(0.97)
8.A22=34997 3 ==>Q14=95650 1 conf:(0.33) <lift:(7.97)> lev:(0.01) [0] conv:(0.96)
9.Q3=85108 1 ==>A4=90293 1 conf:(1) <lift:(7.38)> lev:(0.01) [0] conv:(0.86)
10.A4=90293= 16 ==>Q3=85108 1 conf:(0.06) <lift:(7.38)> lev:(0.01) [0] conv:(0.99)](https://image.slidesharecdn.com/nccit2014-69-140610044036-phpapp01/85/Slide-ProceedingNccit-2014-69-25-320.jpg)