Data Mining Extensions (DMX) is a query language used to create, manage, and query data mining models. DMX was introduced in 1999 to define common concepts for data mining. It includes objects like mining structures and models. Mining structures define columns and hold cached data, while models perform machine learning on structures. DMX statements are used for creation, prediction, and training. Prediction joins apply model patterns to estimate unknown values in source data.










![TrainingCREATING MINING STRUCTURES:Creating mining structures is similar to creating tables in SQL.Syntax:CREATE [SESSION] MINING STRUCTURE <structure> ( [(<column definition list>)] )StructureA unique name for the structure.column definitionlistA comma-separated list of column definitions](https://image.slidesharecdn.com/dataminingconceptsanddmx-100712053820-phpapp01/85/MS-SQL-Server-Data-mining-concepts-and-dmx-10-320.jpg)
![CREATING MINING STRUCTURES:The following example creates a new mining structure called New Mailing.CREATE MINING STRUCTURE [New Mailing] ( CustomerKey LONG KEY, Gender TEXT DISCRETE, [Number Cars Owned] LONG DISCRETE, [Bike Buyer] LONG DISCRETE )](https://image.slidesharecdn.com/dataminingconceptsanddmx-100712053820-phpapp01/85/MS-SQL-Server-Data-mining-concepts-and-dmx-11-320.jpg)
![ALTERING MINING STRUCTURES:Creates a new mining model that is based on an existing mining structure. When you use the alter structure statement to create a new mining model, the structure must already exist. Syntax:ALTER MINING STRUCTURE <structure> ADD MINING MODEL <model> ( <column definition list> [(<nested column definition list>) [WITH FILTER (<nested filter criteria>)]] ) USING <algorithm> [(<parameter list>)] FILTER keyword is used to filter condition.](https://image.slidesharecdn.com/dataminingconceptsanddmx-100712053820-phpapp01/85/MS-SQL-Server-Data-mining-concepts-and-dmx-12-320.jpg)
![ALTERING MINING STRUCTURESThe following example adds a Naive Bayes mining model to the New Mailing mining structure and limits the maximum number of attribute states to 50.ALTER MINING STRUCTURE [New Mailing] ADD MINING MODEL [Naive Bayes] ( CustomerKey, Gender, [Number Cars Owned], [Bike Buyer] PREDICT ) USING Microsoft_Naive_Bayes (MAXIMUM_STATES = 50)](https://image.slidesharecdn.com/dataminingconceptsanddmx-100712053820-phpapp01/85/MS-SQL-Server-Data-mining-concepts-and-dmx-13-320.jpg)

![DROP MINING MODEL Deletes a mining model from the database.Syntax:DROP MINING MODEL <model >ModelA model identifier.Ex: The following sample code drops the mining model NBSample.DROP MINING MODEL [NBSample]](https://image.slidesharecdn.com/dataminingconceptsanddmx-100712053820-phpapp01/85/MS-SQL-Server-Data-mining-concepts-and-dmx-15-320.jpg)


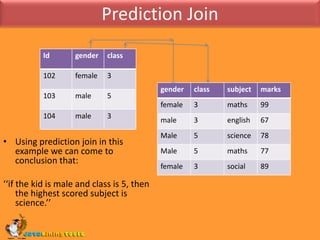

![Prediction Join syntaxSELECT [TOP <count>] <column references> FROM <mining model> [[NATURAL] PREDICTION JOIN <source-data> [ ON <mapping clause> ] [ WHERE <condition clause> ] [ ORDER BY <order clause> [DESC | ASC] ]]Count Optional, An integer that specifies how many rows to return.column referencesA comma-separated list of column identifiers an expressions that are derived from the mining model.mining modelA model identifier.source -dataThe source query.mapping clauseOptional, A logical expression that compares columns from the model to columns from the source query.condition clause Optional, A condition to restrict the values that are returned from the column list.order clause Optional, An expression that returns a scalar value.](https://image.slidesharecdn.com/dataminingconceptsanddmx-100712053820-phpapp01/85/MS-SQL-Server-Data-mining-concepts-and-dmx-20-320.jpg)
























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)