The document discusses the use of more expressive types for Apache Spark through a framework called Frameless, which enhances type safety in Spark applications using Scala. It covers various concepts such as type classes, generic programming, and how Frameless improves on traditional Spark methods by offering type-safe operations and custom encoders. The presentation also highlights performance considerations and the limitations of existing Spark data types, ultimately advocating for Frameless as a robust solution for managing complex data types in Spark.








![RDDs
trait Person { val name: String }
case class Teacher(id: Int, name: String, salary: Double) extends Person
case class Student(id: Int, name: String) extends Person
val people: RDD[Person] = sc.parallelize(List(
Teacher(1, "Emma", 60000),
Student(2, "Steve"),
Student(3, "Arnold")
))](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-9-320.jpg)








![They’re not type-safe :(
AnalysisException: cannot resolve '`namee`'
given input columns: [id, name, age]
Runtime
val names: DataFrame = people.select("namee")](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-18-320.jpg)

![Datasets
val people: Dataset[Person] = List(
Person(1, "Miguel", 26),
Person(2, "Sarah", 28),
Person(2, "John", 32)
).toDS()](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-20-320.jpg)
![Datasets
● Try to get the best of both worlds
● We can use lambdas as in RDDs!
○ What about performance?
● Full DataFrame API as DataFrame = Dataset[Row]
● They seem type-safe](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-21-320.jpg)

![Still not type-safe :(
AnalysisException: cannot resolve '`namee`'
given input columns: [id, name, age]
Runtime
val names: DataFrame = people.select("namee")](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-23-320.jpg)
![But… we can cast them!
val names: Dataset[Int] = people.select("name").as[Int]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-24-320.jpg)
![But… we can cast them! ...and fail :(
AnalysisException: Cannot up cast `name` from
string to int as it may truncate
Runtime
val names: Dataset[Int] = people.select("name").as[Int]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-25-320.jpg)
![Lambdas...
val names: Dataset[String] = people.map(_.namee)](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-26-320.jpg)
![Lambdas… are type-safe!
Error: value namee is not a member of PersonCompile
val names: Dataset[String] = people.map(_.namee)](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-27-320.jpg)



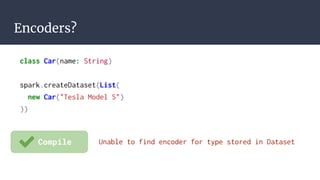
![Encoders?
case class PersonCar(personId: Int, car: Car)
val cars: Dataset[PersonCar] = spark.createDataset(List(
PersonCar(1, new Car("Tesla Model S"))
))](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-32-320.jpg)
![Encoders?
UnsupportedOperationException: No Encoder found for
Car
- field (class: "Car", name: "car")
- root class: "PersonCar"
case class PersonCar(personId: Int, car: Car)
val cars: Dataset[PersonCar] = spark.createDataset(List(
PersonCar(1, new Car("Tesla Model S"))
))
Runtime](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-33-320.jpg)


![Typed Datasets
val peopleFL: TypedDataset[Person] = people.typed
val names: TypedDataset[String] = peopleFL.select(peopleFL('namee))](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-36-320.jpg)
![Typed Datasets
No column Symbol with
shapeless.tag.Tagged[String("namee")] of type A in
Person
Compile
val peopleFL: TypedDataset[Person] = people.typed
val names: TypedDataset[String] = peopleFL.select(peopleFL('namee))](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-37-320.jpg)
![Column operations are also supported
scala> val agesDivided = peopleFL.select(peopleFL('age)/2)
agesDivided: TypedDataset[Double]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-38-320.jpg)
![Column operations are also supported
scala> val agesDivided = peopleFL.select(peopleFL('age)/2)
agesDivided: TypedDataset[Double]
val intToString = (x: Int) => x.toString
val udf = peopleFL.makeUDF(intToString)
scala> val result = peopleFL.select(udf(peopleFL('age)))
result: TypedDataset[String]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-39-320.jpg)
![Aggregations
case class AvgAge(name: String, age: Double)
val ageByName: TypedDataset[AvgAge] = {
peopleFL.groupBy(peopleFL('name)).agg(avg(peopleFL('age)))
}.as[AvgAge]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-40-320.jpg)


![Custom encoders: Injection
implicit val genderToInt: Injection[Gender, Int] = Injection(
{
case Female => 1; case Male => 2; case Other => 3
},{
case 1 => Female; case 2 => Male; case 3 => Other
}
)
scala> TypedDataset.create(peopleGender)
res0: TypedDataset[PersonGender] = [id: int, gender: int]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-43-320.jpg)
![Lazy actions
val numPeopleJob: Job[Long] = people.count().withDescription("...")
val num: Long = numPeopleJob.run()](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-44-320.jpg)
![Lazy actions
val numPeopleJob: Job[Long] = people.count().withDescription("...")
val num: Long = numPeopleJob.run()
val sampleJob = for {
num <- people.count()
sample <- people.take((num/10).toInt)
} yield sample](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-45-320.jpg)

: Dataset[T]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-47-320.jpg)
: Dataset[T]
// It’s the same as
def createDataset[T](data: Seq[T])(implicit encoder: Encoder[T])](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-48-320.jpg)
![Encoders are typeclasses
● Instances provided by SQLImplicits class
● That’s why we need import spark.implicits._ everywhere!
implicit def newSequenceEncoder[T <: Seq[_] : TypeTag]: Encoder[T] =
ExpressionEncoder() // <- Reflection at runtime!](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-49-320.jpg)
![Reflection is not our friend
class Car(name: String)
val cars = Seq(Car("Tesla"))
val ds: Dataset[Car] = spark.createDataset(cars)
Compile Unable to find encoder for type stored in a Dataset.](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-50-320.jpg)
![Reflection is not our friend
class Car(name: String)
val cars = Seq(Car("Tesla"))
val ds: Dataset[Car] = spark.createDataset(cars)
val ds: Dataset[Seq[Cars]] = spark.createDataset(Seq(cars))
Runtime
Compile
No encoder found for Car
Unable to find encoder for type stored in a Dataset.](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-51-320.jpg)
(
implicit
encoder: TypedEncoder[A],
sqlContext: SQLContext
): TypedDataset[A]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-52-320.jpg)
: TypedEncoder[Map[A, B]]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-53-320.jpg)
![How to know if our class has a column?
// We were calling people(‘name)
def TypedDataset[T] {
def apply[A](column: Witness.Lt[Symbol])(
implicit
exists: TypedColumn.Exists[T, column.T, A],
encoder: TypedEncoder[A]
): TypedColumn[T, A]
}](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-54-320.jpg)
![How to know if our class has a column?
object TypedColumn.Exists[T, K, V] {
implicit def deriveRecord[T, H <: HList, K, V](
implicit
lgen: LabelledGeneric.Aux[T, H],
selector: Selector.Aux[H, K, V]
): Exists[T, K, V] = new Exists[T, K, V] {}
}](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-55-320.jpg)

![Generic programming!
HList = HNil | ::[A, H <: HList]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-57-320.jpg)
![Generic programming!
val genericMe = 1 :: "Miguel" :: (26: Short) :: HNil
scala> :type genericMe
::[Int, ::[String, ::[Short, HNil]]]
HList = HNil | ::[A, H <: HList]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-58-320.jpg)
![Shapeless Generic typeclass
val genericPerson = Generic[Person]
val genericMe = 1 :: "Miguel" :: (26: Short) :: HNil
scala> val me = genericPerson.from(genericMe)
me: Person = Person(1,Miguel,26)
scala> val genericMeAgain = genericPerson.to(me)
gemericMeAgain: genericPerson.Repr = 1 :: Miguel :: 26 :: HNil](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-59-320.jpg)


![trait Increasable
def inc(x: Int with Increasable) = x+1
inc(3.asInstanceOf[Int with Increasable]): Int = 4
inc(3)
error: type mismatch; found: Int(3); required: Int with Increasable
Phantom types and type tagging
● Phantom type: no runtime behaviour
● Type tagging: assign a phantom type to other types](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-62-320.jpg)
![All combined with Shapeless!
"name" ->> 1
res1: Int with KeyTag[String("name"),Int] = 1](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-63-320.jpg)
![All combined with Shapeless!
"name" ->> 1
res1: Int with KeyTag[String("name"),Int] = 1
val me = ("id" ->> 1) :: ("name" ->> "Miguel") :: ("age" ->> 26) :: HNil
::Int with KeyTag[String("id"),Int],
::String with KeyTag[String("name"),String],
::Short with KeyTag[String("age"),Short],
::HNil](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-64-320.jpg)
![LabelledGeneric
val genericPerson = LabelledGeneric[Person]
::Int with KeyTag[Symbol with Tagged[String("id")],Int],
::String with KeyTag[Symbol with Tagged[String("name")],String],
::Short with KeyTag[Symbol with Tagged[String("age")],Short],
HNil](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-65-320.jpg)
![Dependent types
trait Generic[A] {
type Repr
def to(value: A): Repr
}
def getRepr[A](v: A)(gen: Generic[A]): gen.Repr = gen.to(v)
// Is it not the same as this?
def getRepr[A, R](v: A)(gen: Generic2[A, R]): R = ???](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-66-320.jpg)

(implicit witness: Witness.Aux[K]) = witness.value
// Aux[K] = Witness { type T = K }
>scala getField("name" ->> 1)
res0: String("name") = name](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-67-320.jpg)
![Shapeless Witness
Witness.Aux[A] = Witness { type T = A }
>scala val witness = Witness(‘name)
witness: Witness.Aux[Symbol with Tagged[String("name")]
Witness.Lt[A] = Witness { type T <: A }
// Tagged Symbol is a subtype of Symbol. So previous line is also...
witness: Witness.Lt[Symbol]](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-68-320.jpg)
![Back to Frameless
// We were calling people(‘name)
def TypedDataset[T] {
def apply[A](column: Witness.Lt[Symbol])(
implicit
exists: TypedColumn.Exists[T, column.T, A],
encoder: TypedEncoder[A]
): TypedColumn[T, A]
}](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-69-320.jpg)
![Back to Frameless
object TypedColumn.Exists[T, K, V] {
implicit def deriveRecord[T, H <: HList, K, V](
implicit
lgen: LabelledGeneric.Aux[T, H],
selector: Selector.Aux[H, K, V]
): Exists[T, K, V] = new Exists[T, K, V] {}
}](https://image.slidesharecdn.com/moreexpressivetypesforsparkwithframeless-180223094133/85/More-expressive-types-for-spark-with-frameless-70-320.jpg)



































































