This module performs semantic analysis on the input program to ensure logical correctness and adherence to the rules of the PIM ISA. It involves type checking, symbol table management, scope resolution, and validation of instruction semantics. The module detects invalid operations, ensures proper use of memory and registers, and enforces constraints specific to the architecture. By verifying the correctness of high-level constructs before code generation, it helps prevent runtime errors and optimizes instruction translation for efficient execution.
















![Bottom up evaluation of S-attributed definitions
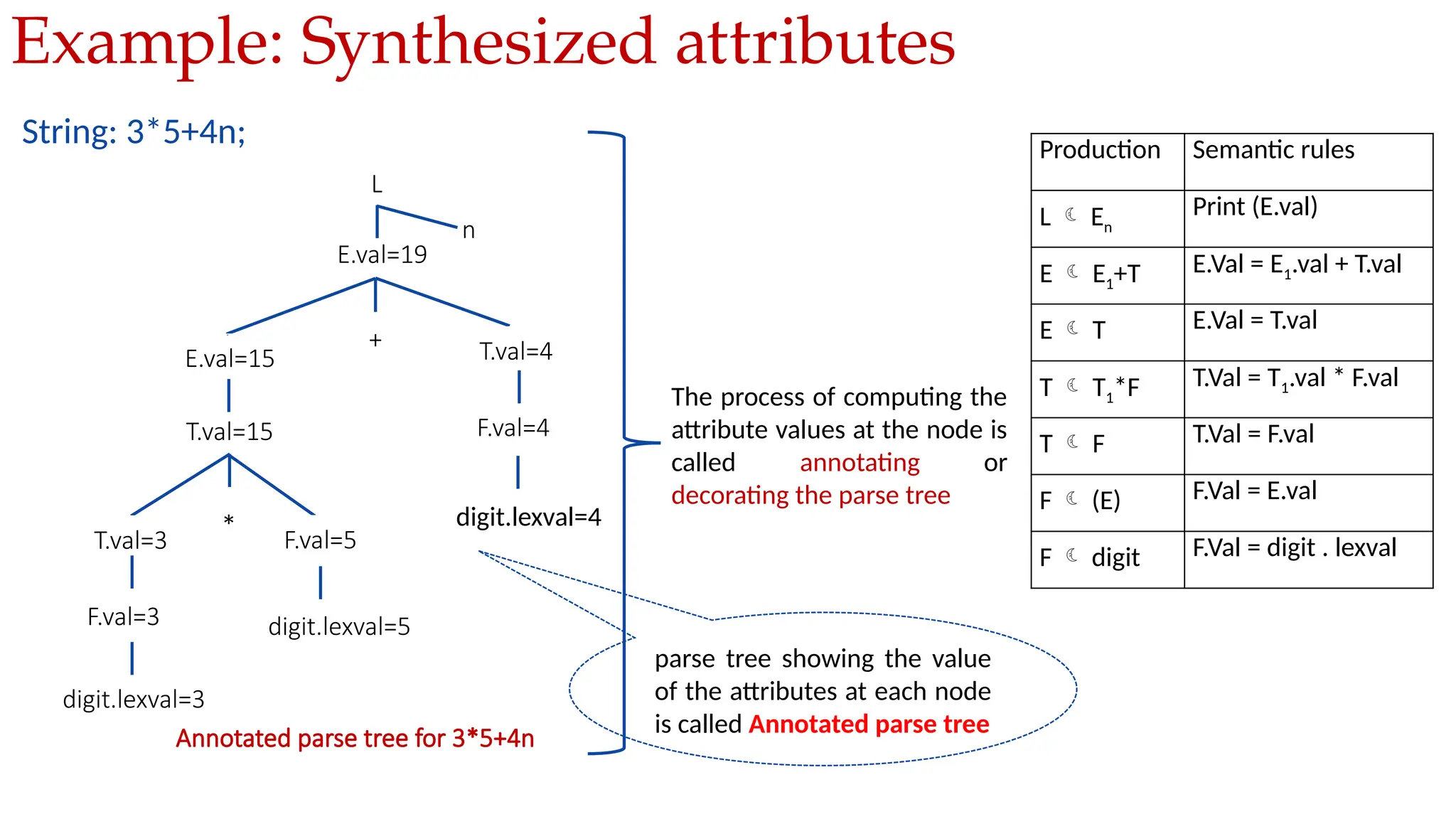
Production Semantic rules
L En
Print (val[top])
E E1+T val[top]=val[top-2] + val[top]
E T
T T1*F val[top]=val[top-2] * val[top]
T F
F (E) val[top]=val[top-2] - val[top]
F digit
Input State Val Production Used
3*5n - -
*5n 3 3
*5n F 3 Fdigit
*5n T 3 TF
5n T* 3
n T*5 3,5
n T*F 3,5 Fdigit
n T 15 TT1*F
n E 15 ET
En 15
L 15 L En
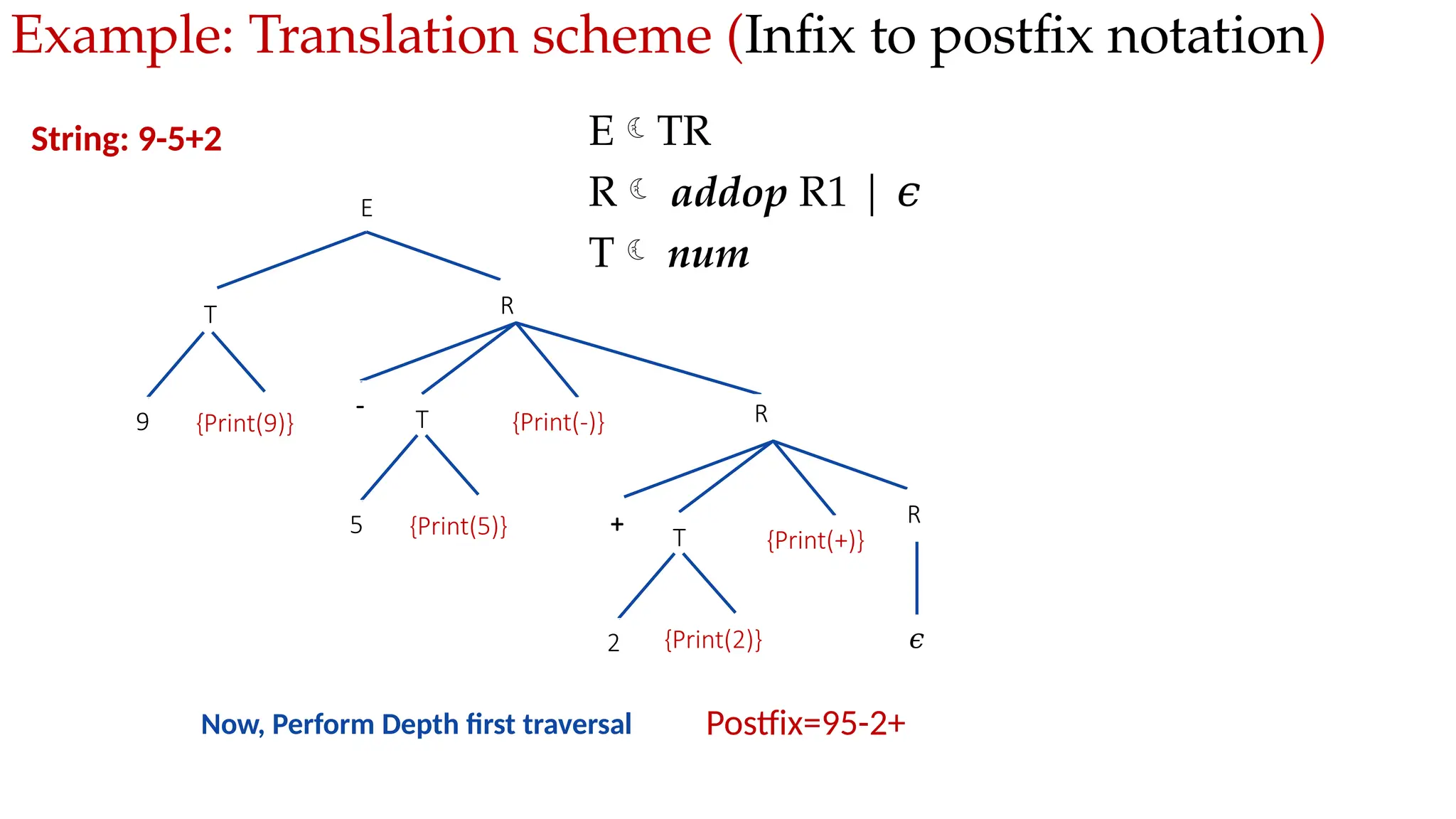
Implementation of a desk calculator
with bottom up parser
Move made by translator](https://image.slidesharecdn.com/module3-semanticanalysis-250331144028-7fca97cb/75/Module-3-Semantic-Analysis-Compiler-Design-pptx-21-2048.jpg)