Download as PDF, PPTX





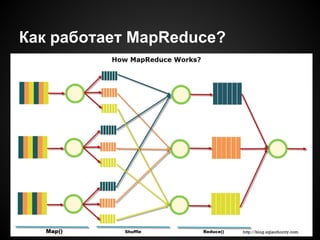
![Фазы mapreduce
map: mapper(line) -> (k1, v1)
shuffle: сортировка по k1
reduce: reducer(k1, [v1, v2, v3])](https://image.slidesharecdn.com/mapreduceinjavascript-150606103438-lva1-app6891/85/Mapreduce-in-JavaScript-7-320.jpg)
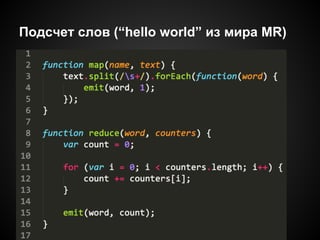
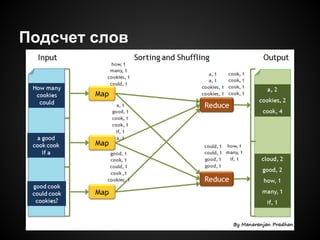


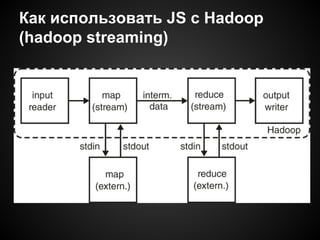





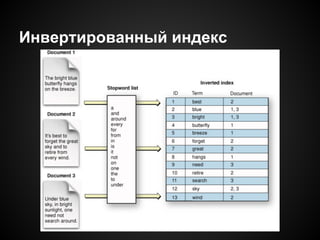
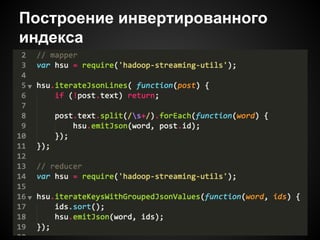





Документ описывает использование распределенных вычислений на JavaScript для обработки больших объемов данных из Twitter, с примерами анализа упоминаемости ключевых слов. Он рассматривает модель MapReduce, поясняет ее работу и включает практические рекомендации по интеграции с Hadoop через Streaming. В документе также представлены потенциальные проблемы, связанные с асинхронностью и обработкой текстов.






































