Download to read offline












![DEFENSES, BARRIERS, SAFEGUARDS
[...] High-tech systems have many defensive layers: some are designed (alarms,
physical barriers, automatic shutdowns, etc.), others rely on people (surgeons,
anesthetists, pilots, control room operators, etc.) and others rely on procedures and
administrative controls. [...]
Source: Human error: models and management](https://image.slidesharecdn.com/odsc-mlops-active-failures-latent-conditions-200919115802/75/Machine-Learning-Operations-Active-Failures-Latent-Conditions-14-2048.jpg)
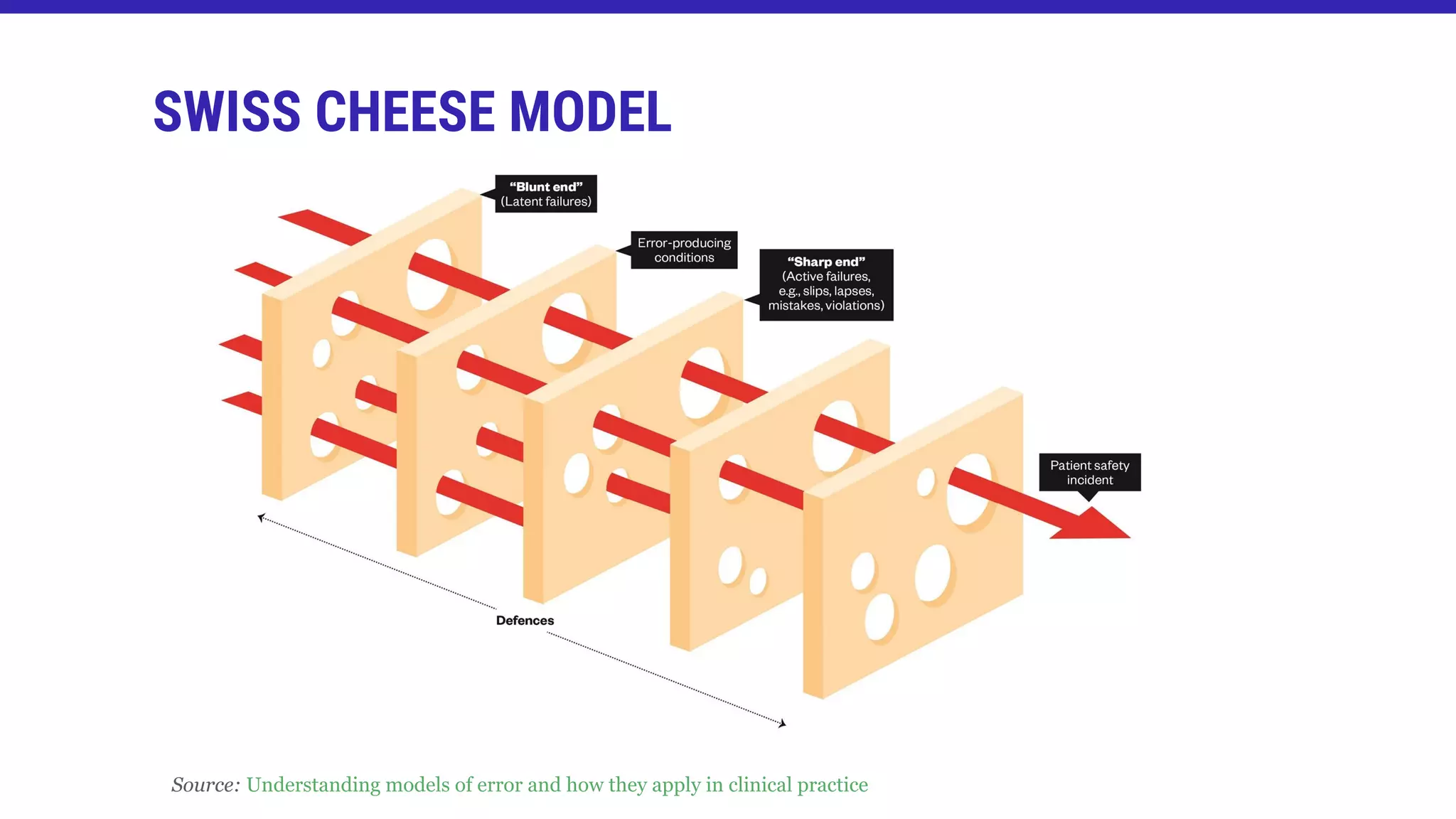
![[...] In an ideal world, each defensive layer would be intact. In reality, however, they are
more like slices of Swiss cheese, with many holes - although, unlike cheese, these holes
are continually opening, closing and moving. The presence of holes in any "slice" does
not normally cause a bad result. This can usually happen only when the holes in several
layers line up momentarily to allow for an accident opportunity trajectory - bringing risks
to harmful contact with victims[...]
Source: Human error: models and management
DEFENSES, BARRIERS, SAFEGUARDS](https://image.slidesharecdn.com/odsc-mlops-active-failures-latent-conditions-200919115802/75/Machine-Learning-Operations-Active-Failures-Latent-Conditions-15-2048.jpg)


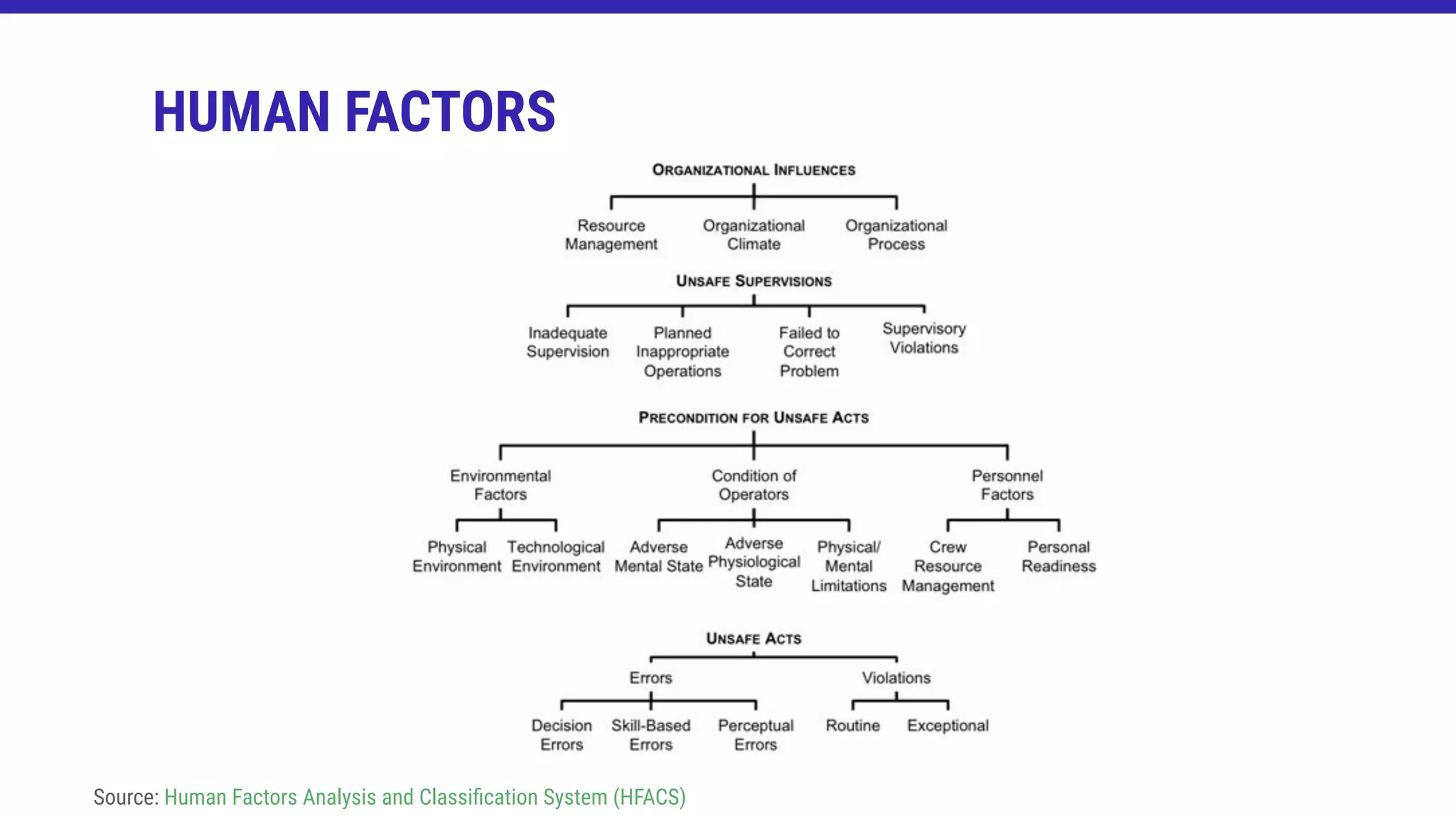
![LATENT CONDITIONS
[...] Latent conditions are like a kind of situations intrinsically resident within the
system; which are consequences of design, engineering decisions, who wrote the rules
or procedures and even the highest hierarchical levels in an organization. These latent
conditions can lead to two types of adverse effects, which are situations that cause
error and the creation of vulnerabilities. That is, the solution has a design that increases
the likelihood of high negative impact events that can be equivalent to a causal or
contributing factor.[...]
Source: Human error: models and management](https://image.slidesharecdn.com/odsc-mlops-active-failures-latent-conditions-200919115802/75/Machine-Learning-Operations-Active-Failures-Latent-Conditions-19-2048.jpg)
![ACTIVE FAILURES
[...]Active failures are insecure acts or minor transgressions committed by people who
are in direct contact with the system; these acts can be mistakes, lapses, distortions,
omissions, errors and procedural violations.[...]
Source: Human error: models and management](https://image.slidesharecdn.com/odsc-mlops-active-failures-latent-conditions-200919115802/75/Machine-Learning-Operations-Active-Failures-Latent-Conditions-20-2048.jpg)


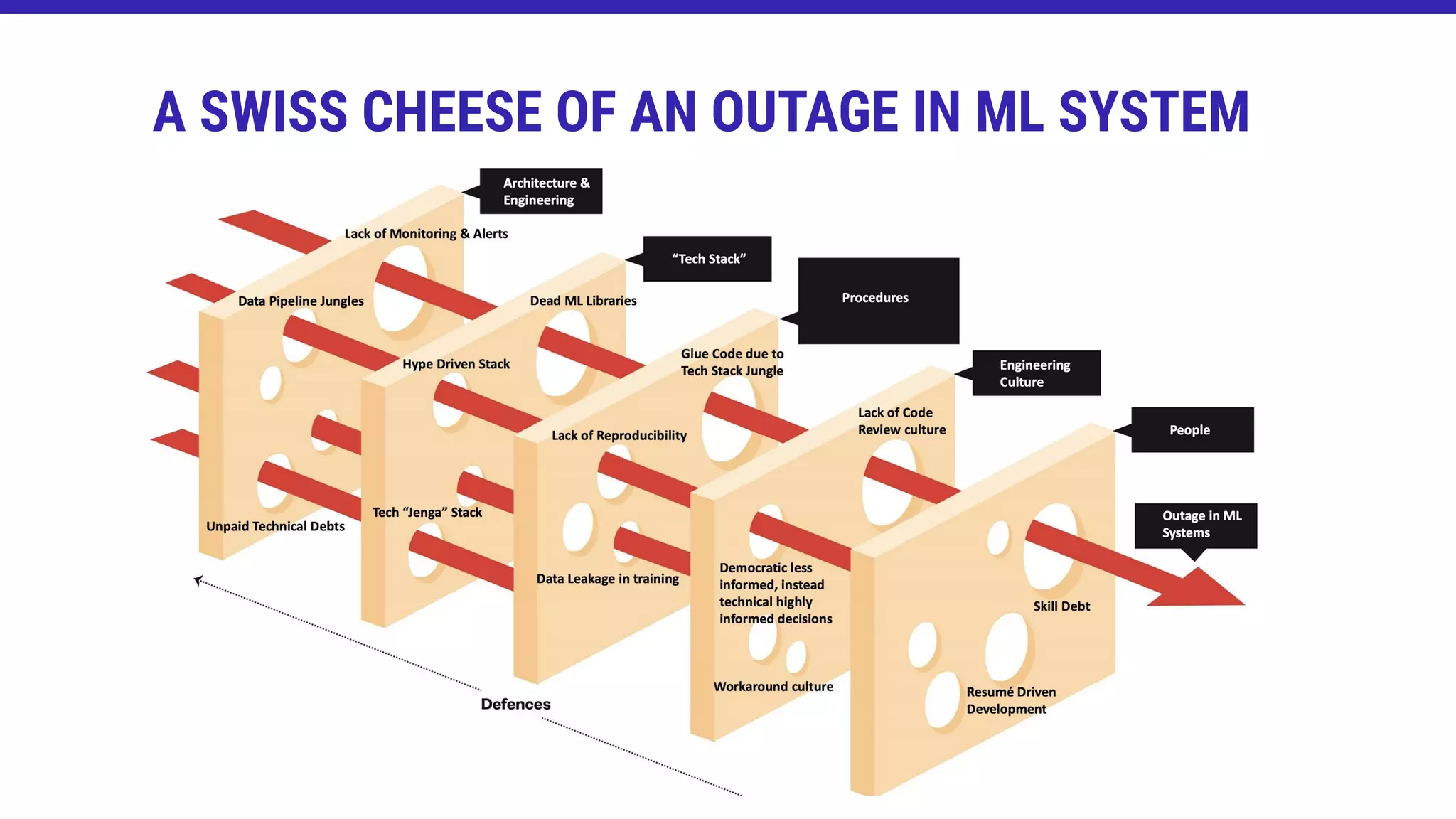









The document discusses the importance of addressing failures in machine learning systems, emphasizing that learning from mistakes is crucial for improving reliability and performance. It highlights examples of significant operational failures across industries and proposes strategies to mitigate risks, such as enhancing testing and cultural changes in engineering. The concept of the Swiss cheese model is presented to illustrate how multiple latent conditions and active failures can align to cause outages.























































