
Report
Share

Recommended
Audio Assignment Client Pitch
The document outlines a proposed radio ad for the fictional cereal "Kool Kidz" aimed at teenagers ages 12-18. The ad would feature famous skateboarder Tony Hawk explaining the cereal's flavors and promoting prizes available by scanning a QR code on the box. It lists similar cereals, proposed radio stations to air the ad, a sample script, and credits team members to film the ad with a budget of £0 on a date to be determined.
Brighton Ruby 2016 Recap
Quick recap based on my messy notes from Brighton Ruby 2016. Watch the Brighton Ruby videos for actual details…
Джентльменский набор гемов. Поддержка единого стиля кода. Доставка кода на се...
This document provides an overview of tools and gems for Ruby on Rails development, deployment, and testing. It discusses authentication, authorization, data handling, image uploading, deployment with Mina/Capistrano, testing, linting, forms, and automation gems. Setup and deployment tasks for Mina are defined. Continuous integration and tools like Vexor are also mentioned. The document concludes by inviting questions.
Smart datamining semtechbiz 2013 report
A conference report of SemTechBiz 2013 in San Francisco, from a datamining and knowledge-management point of view. It covers several companies with their automatic algorithms to extract data from cleverly discovered crowed-curated data sources, or using UI tools to leverage existing utility to lure user help mark up the data...
Recommended
Audio Assignment Client Pitch
The document outlines a proposed radio ad for the fictional cereal "Kool Kidz" aimed at teenagers ages 12-18. The ad would feature famous skateboarder Tony Hawk explaining the cereal's flavors and promoting prizes available by scanning a QR code on the box. It lists similar cereals, proposed radio stations to air the ad, a sample script, and credits team members to film the ad with a budget of £0 on a date to be determined.
Brighton Ruby 2016 Recap
Quick recap based on my messy notes from Brighton Ruby 2016. Watch the Brighton Ruby videos for actual details…
Джентльменский набор гемов. Поддержка единого стиля кода. Доставка кода на се...
This document provides an overview of tools and gems for Ruby on Rails development, deployment, and testing. It discusses authentication, authorization, data handling, image uploading, deployment with Mina/Capistrano, testing, linting, forms, and automation gems. Setup and deployment tasks for Mina are defined. Continuous integration and tools like Vexor are also mentioned. The document concludes by inviting questions.
Smart datamining semtechbiz 2013 report
A conference report of SemTechBiz 2013 in San Francisco, from a datamining and knowledge-management point of view. It covers several companies with their automatic algorithms to extract data from cleverly discovered crowed-curated data sources, or using UI tools to leverage existing utility to lure user help mark up the data...
Webinar slides: ClusterControl New Features Webinar
On Tuesday, May 24th, we were discussing and demonstrating the latest version of ClusterControl, the one-stop console for your entire database infrastructure. We introduced some cool new features for MySQL and MongoDB users in particular and walked through the work we’d recently done for improved security.
Our colleagues Johan Andersson (CTO), Vinay Joosery (CEO) and Ashraf Sharif (System Support Engineer) demonstrated how you can deploy, monitor, manage and scale your databases on the technology stack of your choice with ClusterControl.
AGENDA
ClusterControl overview
New features deep-dive
For MySQL-based systems
For MongoDB-bases systems
Improved security
And more …
Live Demo
Q&A
Webinar slides: Managing MySQL Replication for High Availability
This new webinar on Managing MySQL Replication for High Availability led by Krzysztof Książek, Senior Support Engineer at Severalnines is part of our ongoing ‘Become a ClusterControl MySQL DBA’ series.
Deploying a MySQL Replication topology is only the beginning of your journey. Maintaining it also involves topology changes, managing slave lag, promoting slaves, repairing replication issues, fixing broken nodes, managing schema changes and scheduling backups. Multi-datacenter replication also adds another dimension of complexity. It is always good to be prepared up front and know how to deal with these cases.
In this webinar we will cover deployment and management of MySQL replication topologies using ClusterControl, show how to schedule backups, promote slaves and what are the most important metrics to keep a close eye on. We will also cover how you can deal with schema and topology changes and, if time permits, solve the most common replication issues.
Temporal Action Localization in Untrimmed Videos via Multi Stage CNNs
Temporal Action Localization in Untrimmed Videos via Multi Stage CNNsUniversitat Politècnica de Catalunya
Slides by Alberto Montes about the original CVPR 2016 paper:
Zheng Shou and Dongang Wang and Shih-Fu Chang, "Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs", CVPR 2016.
Abstract:
We address temporal action localization in untrimmed long videos. This is important because videos in real applications are usually unconstrained and contain multiple action instances plus video content of background scenes or other activities. To address this challenging issue, we exploit the effectiveness of deep networks in temporal action localization via three segment-based 3D ConvNets: (1) a proposal network identifies candidate segments in a long video that may contain actions; (2) a classification network learns one-vs-all action classification model to serve as initialization for the localization network; and (3) a localization network fine-tunes the learned classification network to localize each action instance. We propose a novel loss function for the localization network to explicitly consider temporal overlap and achieve high temporal localization accuracy. In the end, only the proposal network and the localization network are used during prediction. On two largescale benchmarks, our approach achieves significantly superior performances compared with other state-of-the-art
systems: mAP increases from 1.7% to 7.4% on MEXaction2
and increases from 15.0% to 19.0% on THUMOS 2014.Marcapasos: Aspectos Prácticos
Este documento resume aspectos prácticos relacionados con los marcapasos, incluyendo los modos de estimulación más comunes, cómo elegir y optimizar un marcapasos, posibles problemas en pacientes con marcapasos y cómo realizar un electrocardiograma en estos pacientes. También describe brevemente la historia de los marcapasos y estadísticas sobre su uso.
Scaling Analytics with Apache Spark
Since its debut in 2010, Apache Spark has become one of the most popular Big Data technologies in the Apache open source ecosystem. In addition to enabling processing of large data sets through its distributed computing architecture, Spark provides out-of-the-box support for machine learning, streaming and graph processing in a single framework. Spark has been supported by companies like Microsoft, Google, Amazon and IBM and in financial services, companies like Blackrock (http://bit.ly/1Q1DVJH ) and Bloomberg (http://bit.ly/29LXbPv ) have started to integrate Apache Spark into their tool chain and the interest is growing. Unlike other big-data technologies which require intensive programming using Java etc., Spark enables data scientists to work with a big-data technology using higher level languages like Python and R making it accessible to conduct experiments and for rapid prototyping.
In this talk, we will introduce Apache Spark and discuss the key features that differentiate Apache Spark from other technologies. We will provide examples on how Apache Spark can help scale analytics and discuss how the machine learning API could be used to solve large-scale machine learning problems using Spark’s distributed computing framework. We will also illustrate enterprise use cases for scaling analytics with Apache Spark.
MNIST for ML beginners
Tensorflow Tutorial 예제 중 ML 입문자들을 위한 예제. 간단한 Classifier Nets을 구성하여 Nets의 훈련 및 검증과정을 배울 수 있는 예제
Creative AI & multimodality: looking ahead
This document discusses creative AI and multimodality. It begins by looking at current possibilities for creative AI, including appropriating standard neural networks for creative use, reinforcement learning approaches that frame creativity as a game, recurrent neural networks, sequence-to-sequence models that treat creativity as translation, autoencoders, attention-based models, and generative adversarial networks. It also discusses needs for creative AI, including developing a system that marries a creative process with creative outputs using minimal human input data but with its own style and the ability for human-level supervision to enable rapid experimentation. The document frames creative AI as a "brush" that can be used for painting.
Introduction to DialogFlow
The document appears to be notes from a training or tutorial on building a weather chatbot. It includes steps for setting up APIs from OpenWeatherMap and Dialogflow, as well as deploying the chatbot to services like Heroku. Sections cover choosing a programming language, integrating additional APIs, and configuring responses and fulfillment.
Udacity Meet Up - 0413
This document summarizes an Udacity study group in Taiwan focused on artificial intelligence (AI) courses. It provides details on past meetup events and speakers, an overview of AI programs offered by Udacity, Coursera, and Microsoft, and contact information for the group manager Ryan Chung who works on AI, data science, and web development programs at Institute for Information Industry.
More Related Content
Viewers also liked
Webinar slides: ClusterControl New Features Webinar
On Tuesday, May 24th, we were discussing and demonstrating the latest version of ClusterControl, the one-stop console for your entire database infrastructure. We introduced some cool new features for MySQL and MongoDB users in particular and walked through the work we’d recently done for improved security.
Our colleagues Johan Andersson (CTO), Vinay Joosery (CEO) and Ashraf Sharif (System Support Engineer) demonstrated how you can deploy, monitor, manage and scale your databases on the technology stack of your choice with ClusterControl.
AGENDA
ClusterControl overview
New features deep-dive
For MySQL-based systems
For MongoDB-bases systems
Improved security
And more …
Live Demo
Q&A
Webinar slides: Managing MySQL Replication for High Availability
This new webinar on Managing MySQL Replication for High Availability led by Krzysztof Książek, Senior Support Engineer at Severalnines is part of our ongoing ‘Become a ClusterControl MySQL DBA’ series.
Deploying a MySQL Replication topology is only the beginning of your journey. Maintaining it also involves topology changes, managing slave lag, promoting slaves, repairing replication issues, fixing broken nodes, managing schema changes and scheduling backups. Multi-datacenter replication also adds another dimension of complexity. It is always good to be prepared up front and know how to deal with these cases.
In this webinar we will cover deployment and management of MySQL replication topologies using ClusterControl, show how to schedule backups, promote slaves and what are the most important metrics to keep a close eye on. We will also cover how you can deal with schema and topology changes and, if time permits, solve the most common replication issues.
Temporal Action Localization in Untrimmed Videos via Multi Stage CNNs
Temporal Action Localization in Untrimmed Videos via Multi Stage CNNsUniversitat Politècnica de Catalunya
Slides by Alberto Montes about the original CVPR 2016 paper:
Zheng Shou and Dongang Wang and Shih-Fu Chang, "Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs", CVPR 2016.
Abstract:
We address temporal action localization in untrimmed long videos. This is important because videos in real applications are usually unconstrained and contain multiple action instances plus video content of background scenes or other activities. To address this challenging issue, we exploit the effectiveness of deep networks in temporal action localization via three segment-based 3D ConvNets: (1) a proposal network identifies candidate segments in a long video that may contain actions; (2) a classification network learns one-vs-all action classification model to serve as initialization for the localization network; and (3) a localization network fine-tunes the learned classification network to localize each action instance. We propose a novel loss function for the localization network to explicitly consider temporal overlap and achieve high temporal localization accuracy. In the end, only the proposal network and the localization network are used during prediction. On two largescale benchmarks, our approach achieves significantly superior performances compared with other state-of-the-art
systems: mAP increases from 1.7% to 7.4% on MEXaction2
and increases from 15.0% to 19.0% on THUMOS 2014.Marcapasos: Aspectos Prácticos
Este documento resume aspectos prácticos relacionados con los marcapasos, incluyendo los modos de estimulación más comunes, cómo elegir y optimizar un marcapasos, posibles problemas en pacientes con marcapasos y cómo realizar un electrocardiograma en estos pacientes. También describe brevemente la historia de los marcapasos y estadísticas sobre su uso.
Scaling Analytics with Apache Spark
Since its debut in 2010, Apache Spark has become one of the most popular Big Data technologies in the Apache open source ecosystem. In addition to enabling processing of large data sets through its distributed computing architecture, Spark provides out-of-the-box support for machine learning, streaming and graph processing in a single framework. Spark has been supported by companies like Microsoft, Google, Amazon and IBM and in financial services, companies like Blackrock (http://bit.ly/1Q1DVJH ) and Bloomberg (http://bit.ly/29LXbPv ) have started to integrate Apache Spark into their tool chain and the interest is growing. Unlike other big-data technologies which require intensive programming using Java etc., Spark enables data scientists to work with a big-data technology using higher level languages like Python and R making it accessible to conduct experiments and for rapid prototyping.
In this talk, we will introduce Apache Spark and discuss the key features that differentiate Apache Spark from other technologies. We will provide examples on how Apache Spark can help scale analytics and discuss how the machine learning API could be used to solve large-scale machine learning problems using Spark’s distributed computing framework. We will also illustrate enterprise use cases for scaling analytics with Apache Spark.
MNIST for ML beginners
Tensorflow Tutorial 예제 중 ML 입문자들을 위한 예제. 간단한 Classifier Nets을 구성하여 Nets의 훈련 및 검증과정을 배울 수 있는 예제
Creative AI & multimodality: looking ahead
This document discusses creative AI and multimodality. It begins by looking at current possibilities for creative AI, including appropriating standard neural networks for creative use, reinforcement learning approaches that frame creativity as a game, recurrent neural networks, sequence-to-sequence models that treat creativity as translation, autoencoders, attention-based models, and generative adversarial networks. It also discusses needs for creative AI, including developing a system that marries a creative process with creative outputs using minimal human input data but with its own style and the ability for human-level supervision to enable rapid experimentation. The document frames creative AI as a "brush" that can be used for painting.
Viewers also liked (8)
Webinar slides: ClusterControl New Features Webinar
Webinar slides: ClusterControl New Features Webinar
Webinar slides: Managing MySQL Replication for High Availability
Webinar slides: Managing MySQL Replication for High Availability
Temporal Action Localization in Untrimmed Videos via Multi Stage CNNs
Temporal Action Localization in Untrimmed Videos via Multi Stage CNNs
More from Ryan Chung
Introduction to DialogFlow
The document appears to be notes from a training or tutorial on building a weather chatbot. It includes steps for setting up APIs from OpenWeatherMap and Dialogflow, as well as deploying the chatbot to services like Heroku. Sections cover choosing a programming language, integrating additional APIs, and configuring responses and fulfillment.
Udacity Meet Up - 0413
This document summarizes an Udacity study group in Taiwan focused on artificial intelligence (AI) courses. It provides details on past meetup events and speakers, an overview of AI programs offered by Udacity, Coursera, and Microsoft, and contact information for the group manager Ryan Chung who works on AI, data science, and web development programs at Institute for Information Industry.
Amazon Alexa Development Part II
This document appears to be notes from a training on Amazon Alexa skills. It includes:
1. Links to Amazon documentation on speech conventions and interjections for different languages.
2. Steps for building skills like setting a default response, creating functions, and testing the skill.
3. Examples of skills that could be built like trivia, flashcards, and checking the weather.
4. References to Amazon services like Alexa Presentation Language, Alexa Skills Kit, and slot types that can be used in skills.
Amazon Alexa Development
This document provides an overview of the Alexa Dev 101 training session. It includes topics like the Alexa voice service, interaction model, custom slots, video skills, sample utterances and code samples. Links are provided to developer documentation and tools on the Amazon developer portal. Sample code snippets are shown for handling intents and slots. The training covers key concepts like invocation name, custom skills, AWS Lambda, and publishing skills.
Microsoft Professional Program - AI
This document discusses an IT training center in Taiwan called III that offers data science courses. It provides links to III's website and details on a partnership with Microsoft to cultivate data scientists in Taiwan. The document also mentions that III focuses on AI and IoT topics and compares outcomes of fewer graduates with higher revenue and skills versus more graduates with lower revenue and basic skills.
More from Ryan Chung (20)
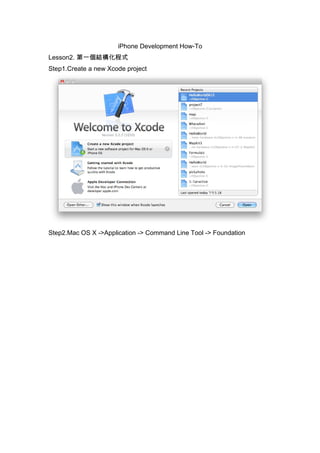
Lesson 2 Basicstructure
- 1. iPhone Development How-To Lesson2. 第一個結構化程式 Step1.Create a new Xcode project Step2.Mac OS X ->Application -> Command Line Tool -> Foundation
- 3. Step4.在 Source 資料夾上按右鍵,Add -> New File… Step5.Cocoa Touch Class -> Objective-C class -> NSObject,Next
- 4. Step6.命名
- 5. Step7.在 fraction.h 中進行修改, .h 檔負責存放@interface 區段: 1. 宣告一個新的類別,並指出此類別的父類別是誰 2. 描述此類別有哪些資料成員 3. 定義方法(method) 備註: A. Fraction 繼承自 NSObject 類別 B. Fraction 有兩個整數變數:numerator, denominator C. –(void) setNumerator:( int)n; 減號代表實體方法,加號代表類別方法 void 代表該方法沒有傳回值 setNumerator 接收一個整數參數,參數名稱為 n Step8.修改 Fraction.m 撰寫 print, setNumerator, setDenominator 方法的內容
- 6. 9.撰寫主程式 function0615.m #import <Foundation/Foundation.h> #import "Fraction.h" int main (int argc, const char * argv[]) { NSAutoreleasePool * pool = [[NSAutoreleasePool alloc] init]; Fraction *myFraction;//宣告一個Fraction物件 myFraction=[[Fraction alloc]init];//分配記憶體與初始化 [myFraction setNumerator:1]; //執行setNumerator方法,並傳入1 [myFraction setDenominator:3];//執行setDenominator方法,並傳入3 NSLog(@"The value of myFraction is:");//於Console視窗顯示字串 [myFraction print];//執行print方法,會顯示出結果 [myFraction release];//釋放記憶體 [pool drain]; return 0; }
- 7. 10.Build -> Build & Debug,然後點選 Run -> Console 觀看執行結果