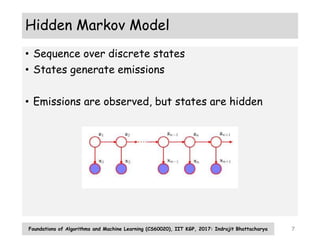
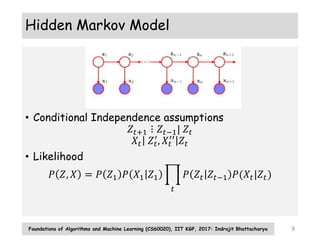
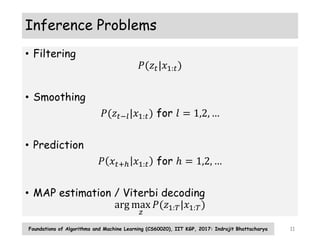
The document discusses probabilistic models for sequence data, including Markov models and hidden Markov models (HMMs). It introduces the key concepts of Markov models, including the state transition matrix and parameter estimation using maximum likelihood. For HMMs, it describes the generative process, inference algorithms like forward-backward, Viterbi, and parameter estimation using the Baum-Welch algorithm. The document provides an overview of these fundamental probabilistic models for sequential data.














![EM for HMMs (Baum Welch Algorithm)
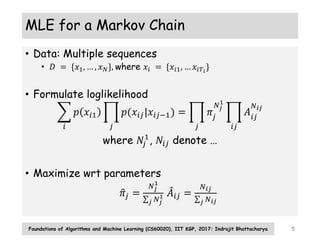
• Formulate complete data loglikelihood
𝑙 Θ
=
𝑘
𝑁𝑘
1
log 𝜋𝑘 +
𝑗 𝑗′
𝑁𝑗𝑗′ log 𝐴𝑗𝑗′
+
𝑖 𝑡 𝑘
𝛿 𝑧𝑡, 𝑘 log 𝑝(𝑥𝑖𝑡|𝜙𝑘)
• Formulate expectation given current parameters
𝑄 Θ, 𝜃𝑜𝑙𝑑
=
𝑘
𝐸[𝑁𝑘
1
] log 𝜋𝑘 +
𝑗 𝑗′
𝐸[𝑁𝑗𝑗′] log 𝐴𝑗𝑗′
+
𝑖 𝑡 𝑘
𝑝 𝑧𝑡 = 𝑘|𝑥𝑖𝑡 log 𝑝(𝑥𝑖𝑡|𝜙𝑘)
Foundations of Algorithms and Machine Learning (CS60020), IIT KGP, 2017: Indrajit Bhattacharya 18](https://image.slidesharecdn.com/lecture7-230523145828-1dfbf269/85/lecture7-pptx-18-320.jpg)

![M-step
• Maximize expected complete loglikelihood using
current expected sufficient statistics
𝐴𝑗𝑘 =
𝐸 𝑁𝑗𝑘
𝑘′ 𝐸[𝑁𝑗𝑘′]
𝜋𝑘 =
𝐸 𝑁𝑘
1
𝑁
• Emission parameter estimates depend on emission
distribution
Foundations of Algorithms and Machine Learning (CS60020), IIT KGP, 2017: Indrajit Bhattacharya 20](https://image.slidesharecdn.com/lecture7-230523145828-1dfbf269/85/lecture7-pptx-20-320.jpg)




















































