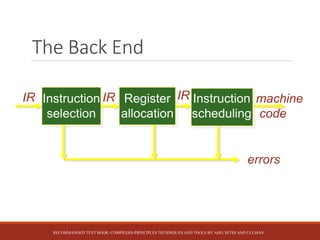
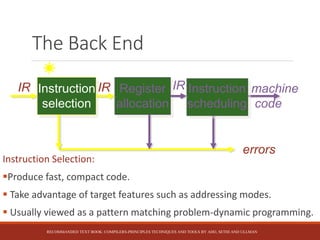
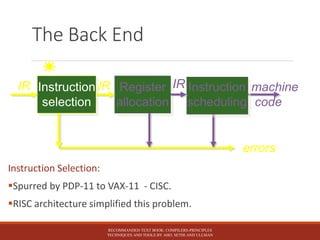
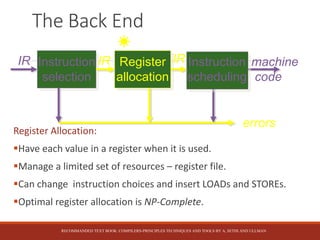
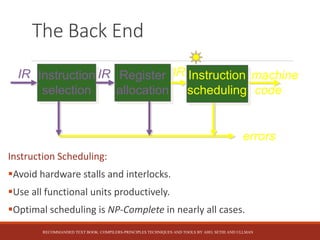
This document discusses the key stages of compiler construction including the front-end which involves parsing the source code and generating an abstract syntax tree, and the back-end which involves translating the intermediate representation into machine code. The back-end consists of instruction selection to choose machine instructions, register allocation to assign values to registers, and instruction scheduling to avoid hardware stalls and optimize functional unit usage. The recommended textbook for further information is "Compilers: Principles, Techniques, and Tools" by Aho, Sethi, and Ullman.