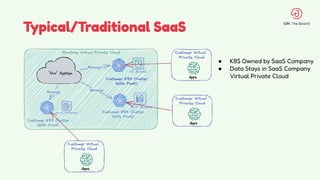
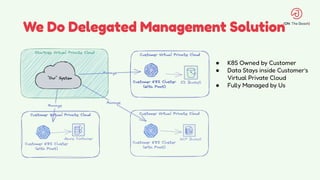
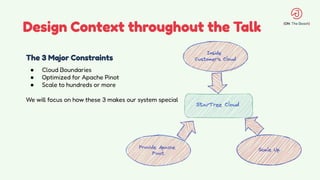
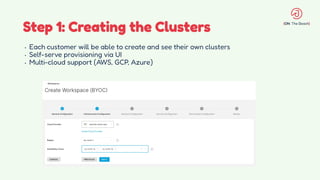
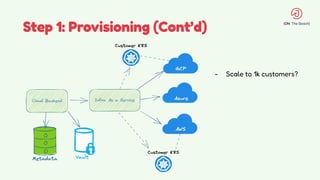
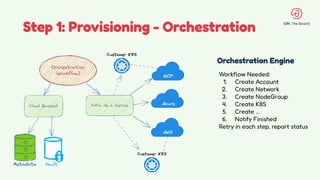
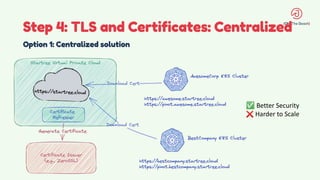
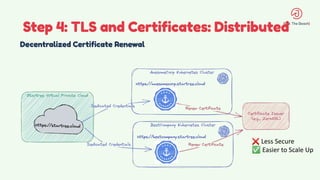
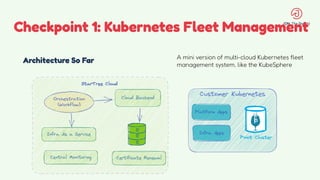
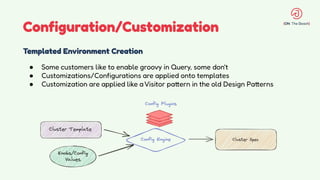
The document discusses the design and management of Kubernetes clusters at scale for deploying Apache Pinot, an OLAP datastore, within customer clouds. It outlines the steps for creating and provisioning these clusters, including automation, application installation, networking, and security measures like TLS and certificates. Key lessons learned from the process emphasize the importance of efficiency, reliability, and disciplined DevOps practices.