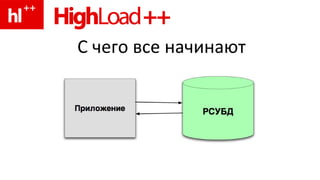
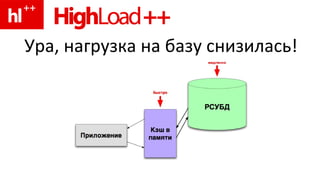
Документ рассматривает проблемы, связанные с использованием memcached и его альтернативами для кэширования данных в условиях высокой нагрузки на сервер базы данных. Основное внимание уделяется конкуренции кэшей, синхронизации данных и необходимости использования индексов для оптимизации производительности запросов. Также обсуждаются функции кэширования в современных системах управления базами данных, таких как Oracle и MySQL.