Downloaded 26 times



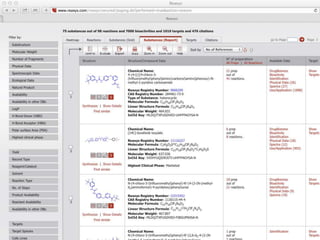
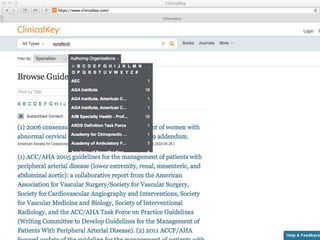

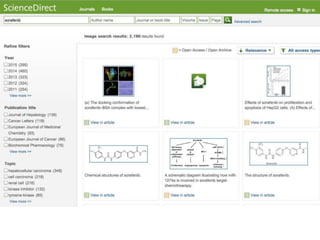









The document discusses knowledge graphs in the context of a panel led by Paul Groth, the Disruptive Technology Director at Elsevier. It highlights the importance of entity-based search as a disruptive technology. The mention of the 2015 WWW industry panel suggests a focus on advancements in knowledge graph applications.



































































