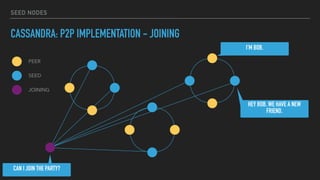
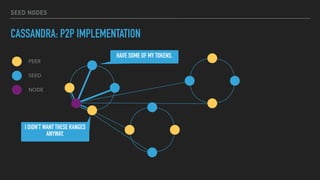
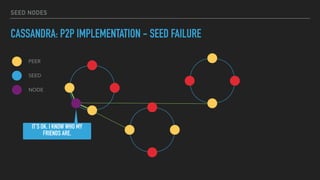
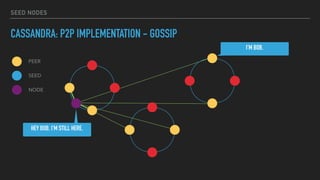
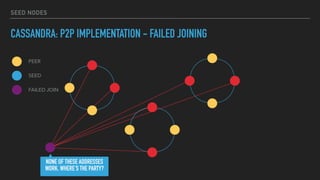
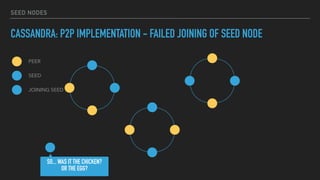
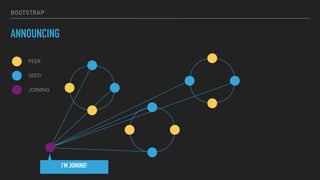
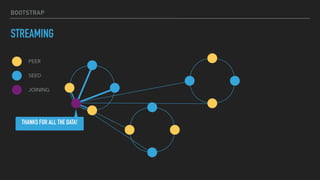
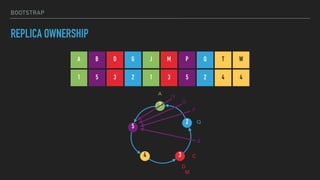
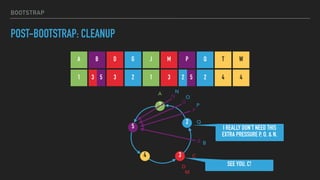
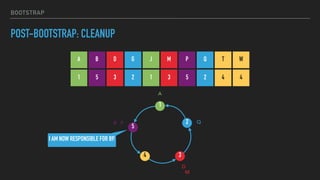
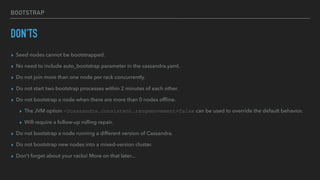
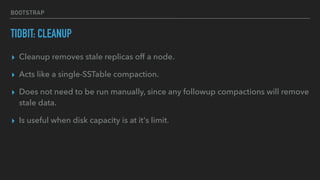
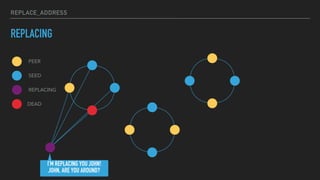
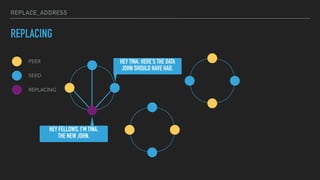
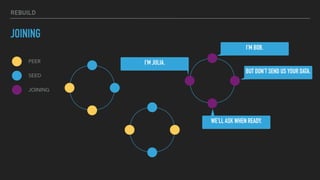
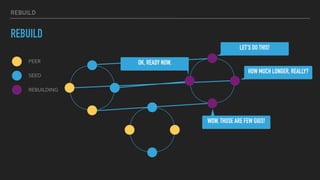
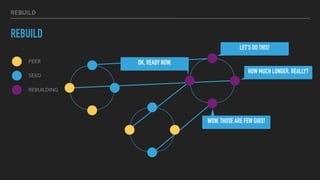
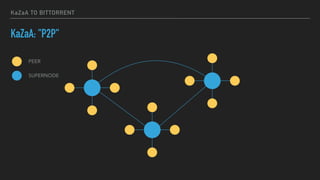
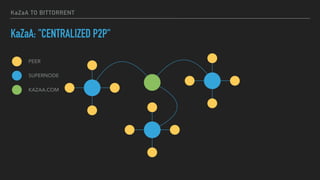
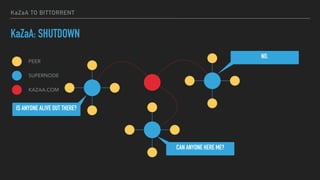
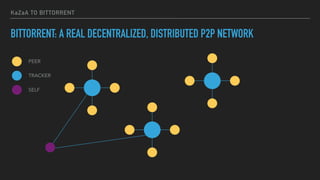
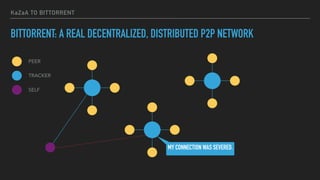
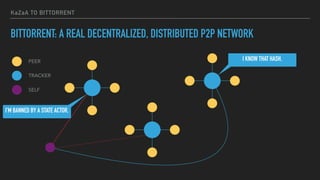
This document provides an overview of joining a peer-to-peer (p2p) conversation about Apache Cassandra. It begins with introductions from Joaquin Casares of The Last Pickle consulting firm. It then covers definitions of p2p networks and examples like KaZaA and BitTorrent. Specific Cassandra topics discussed include token ownership and virtual nodes, seed nodes, bootstrapping, replacing addresses, and rebuilding nodes. Throughout, analogies are used to explain concepts in conversational terms between network "peers".






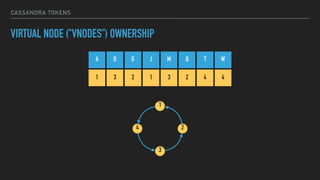
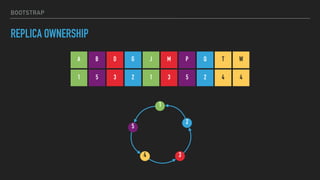
![CASSANDRA TOKENS
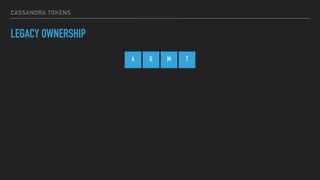
LEGACY OWNERSHIP
A G M T
M
G
A
T
(T, A]
(G, M]
(A, G](M, T]](https://image.slidesharecdn.com/joiningap2pconversation-2017-06meetup-170620024317/85/Joining-a-p2p-Conversation-2017-06-Meetup-17-320.jpg)
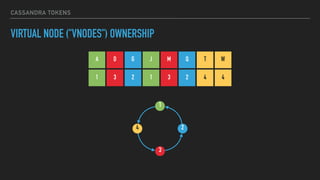
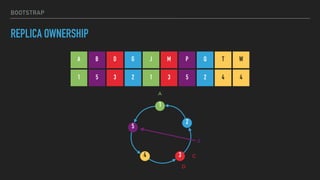
![CASSANDRA TOKENS
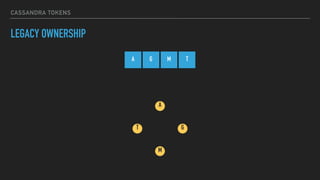
LEGACY OWNERSHIP
A G M T
M
G
A
T
(T, A]
(A, G]
(G, M]
(M, T]](https://image.slidesharecdn.com/joiningap2pconversation-2017-06meetup-170620024317/85/Joining-a-p2p-Conversation-2017-06-Meetup-18-320.jpg)