Download to read offline




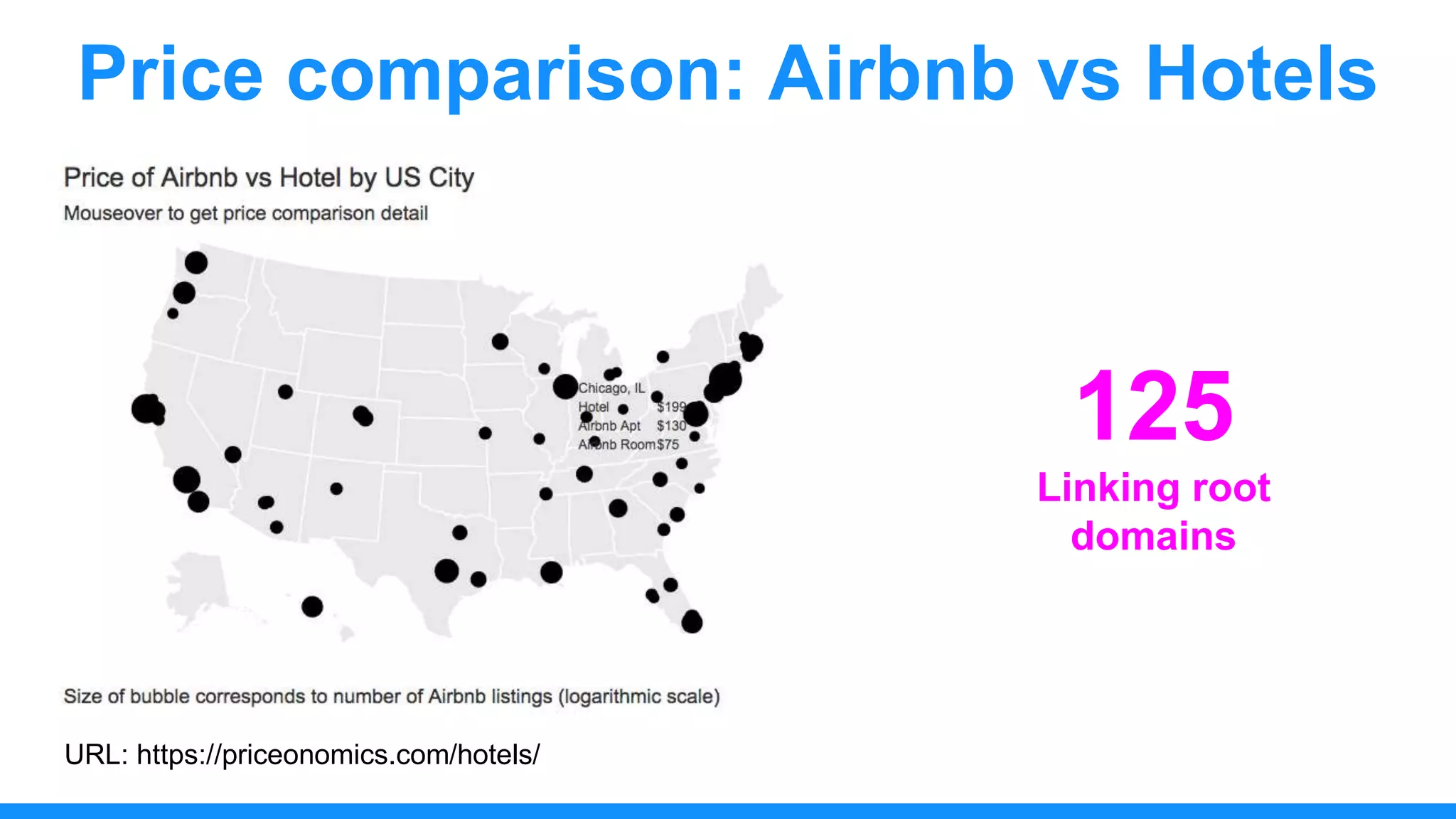
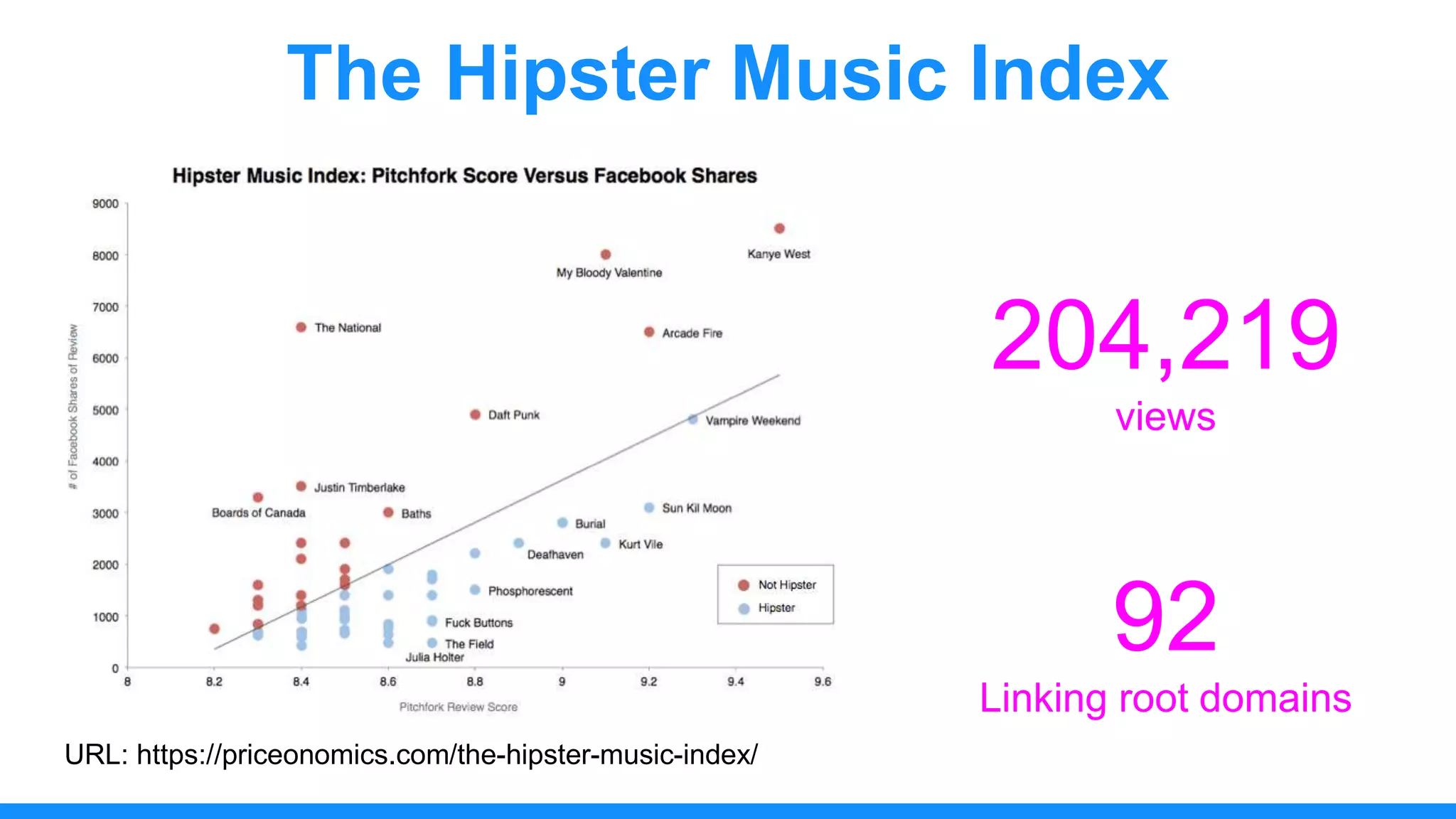





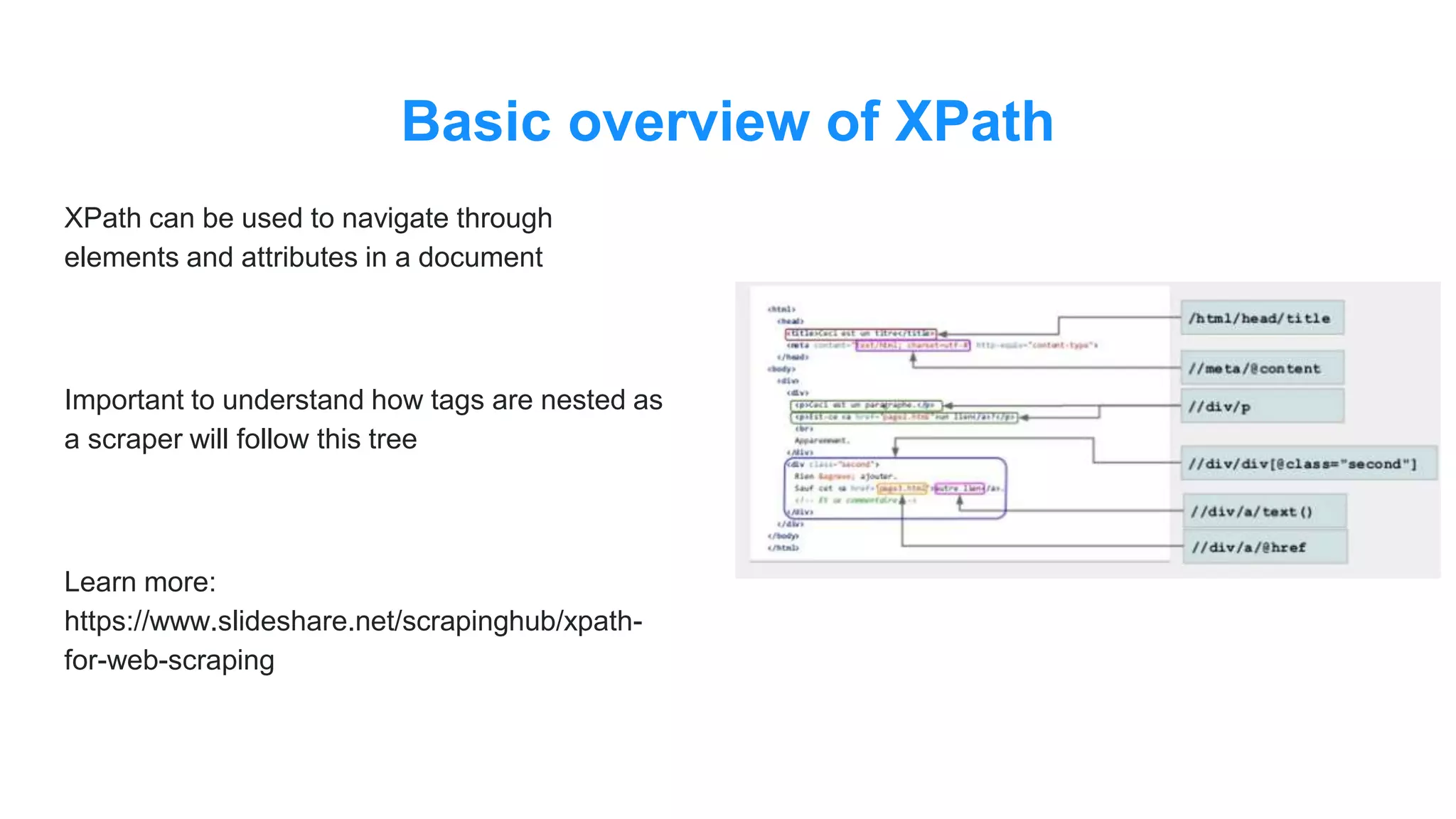
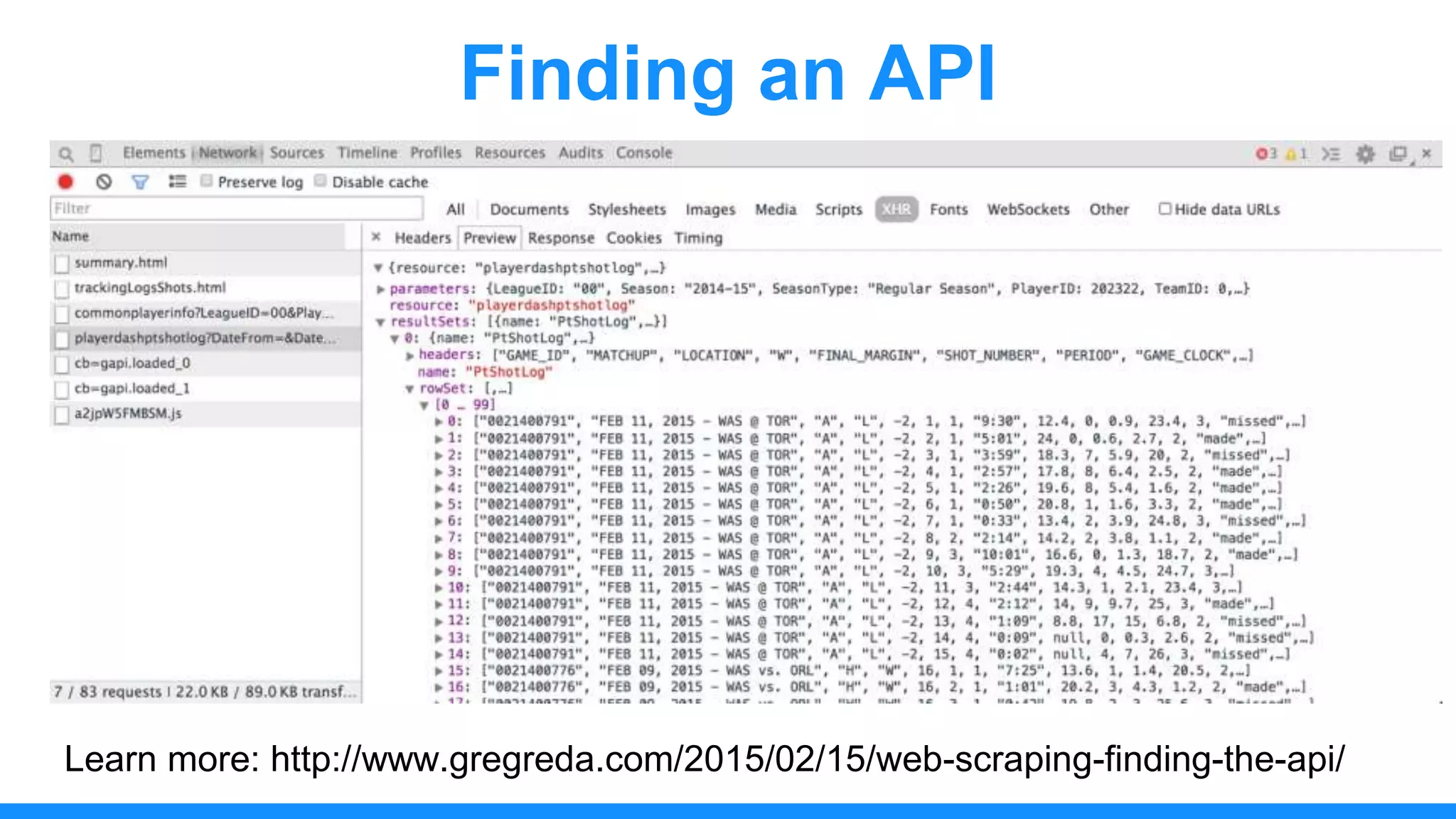








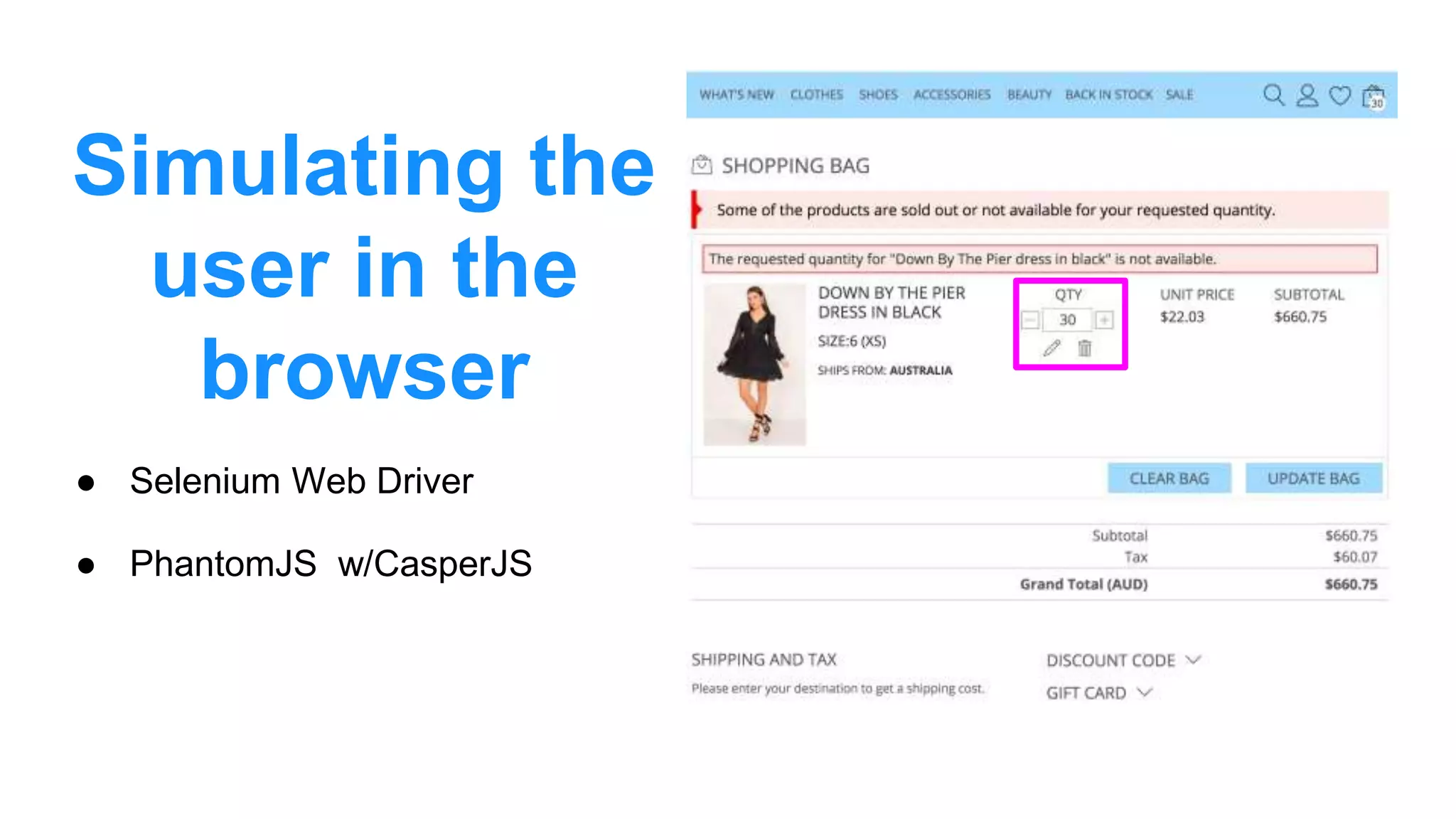



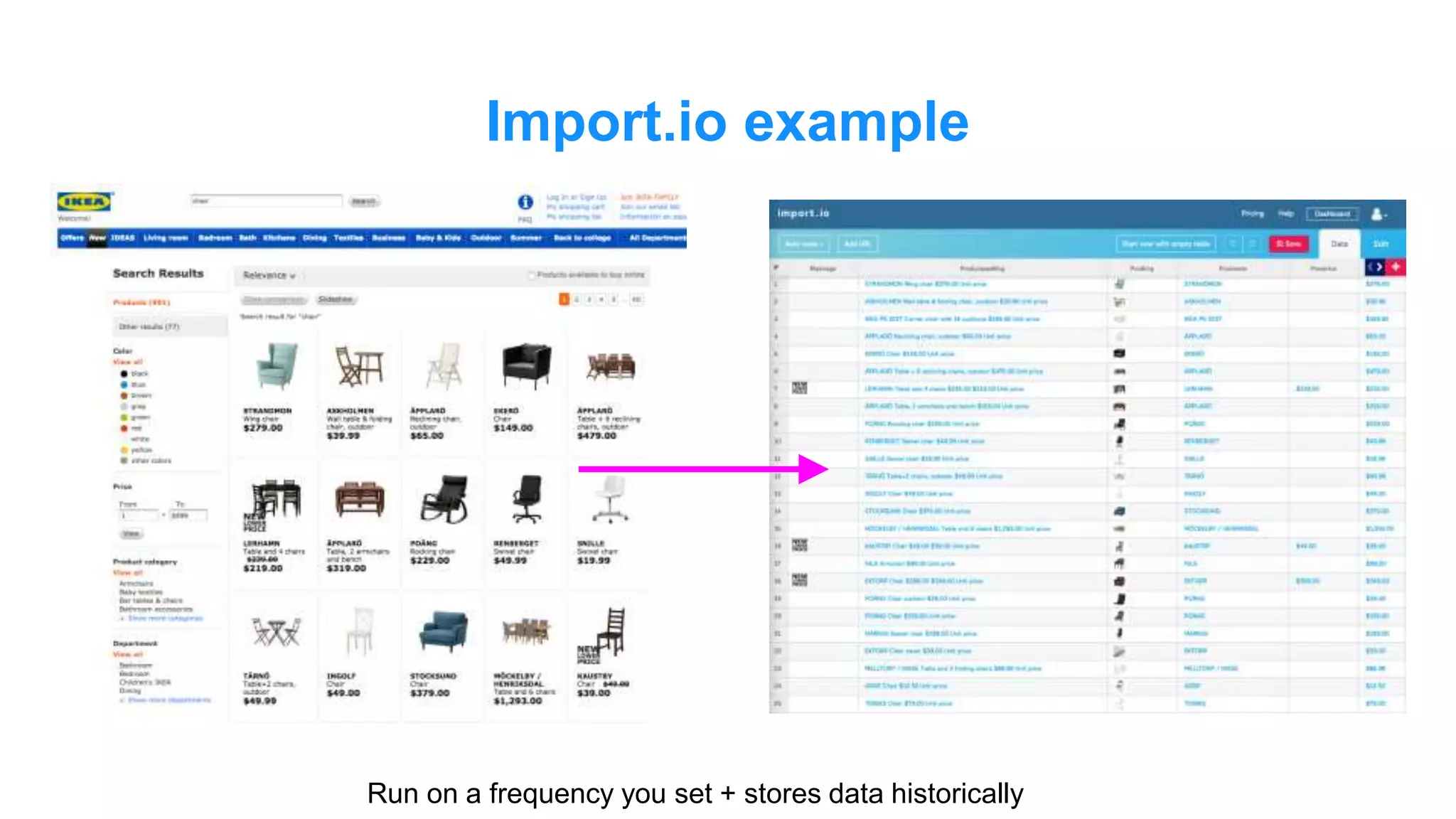
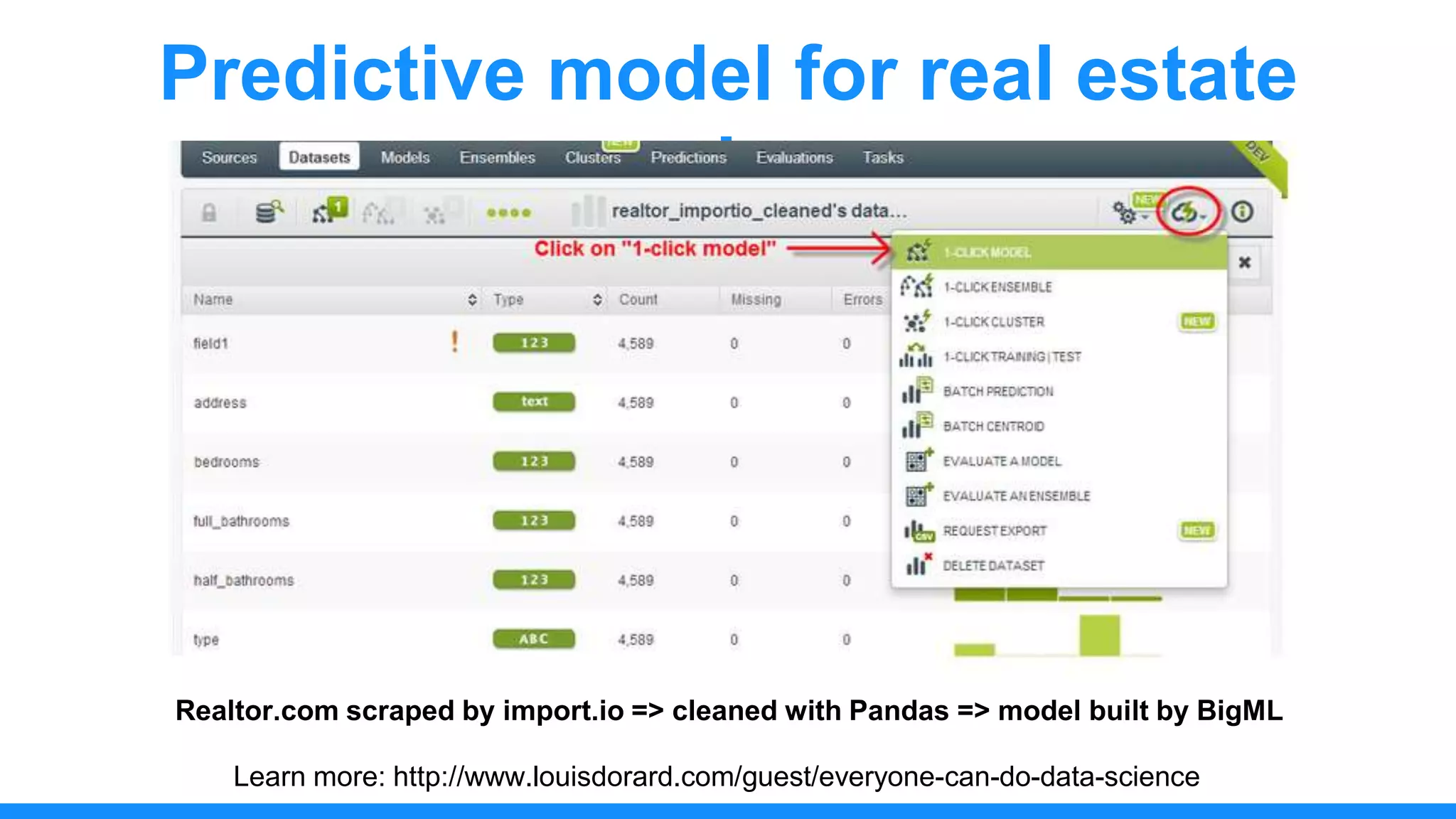
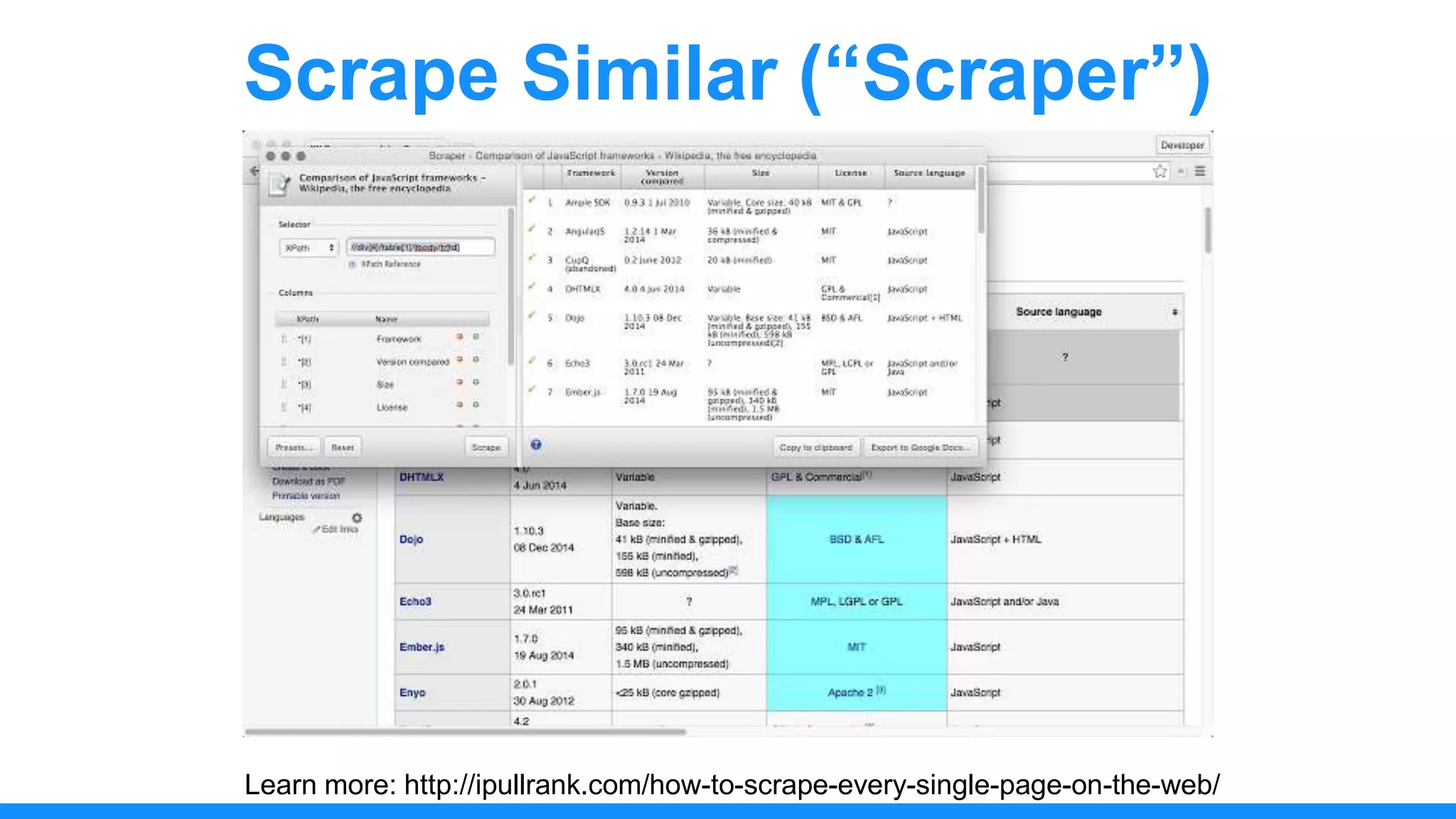
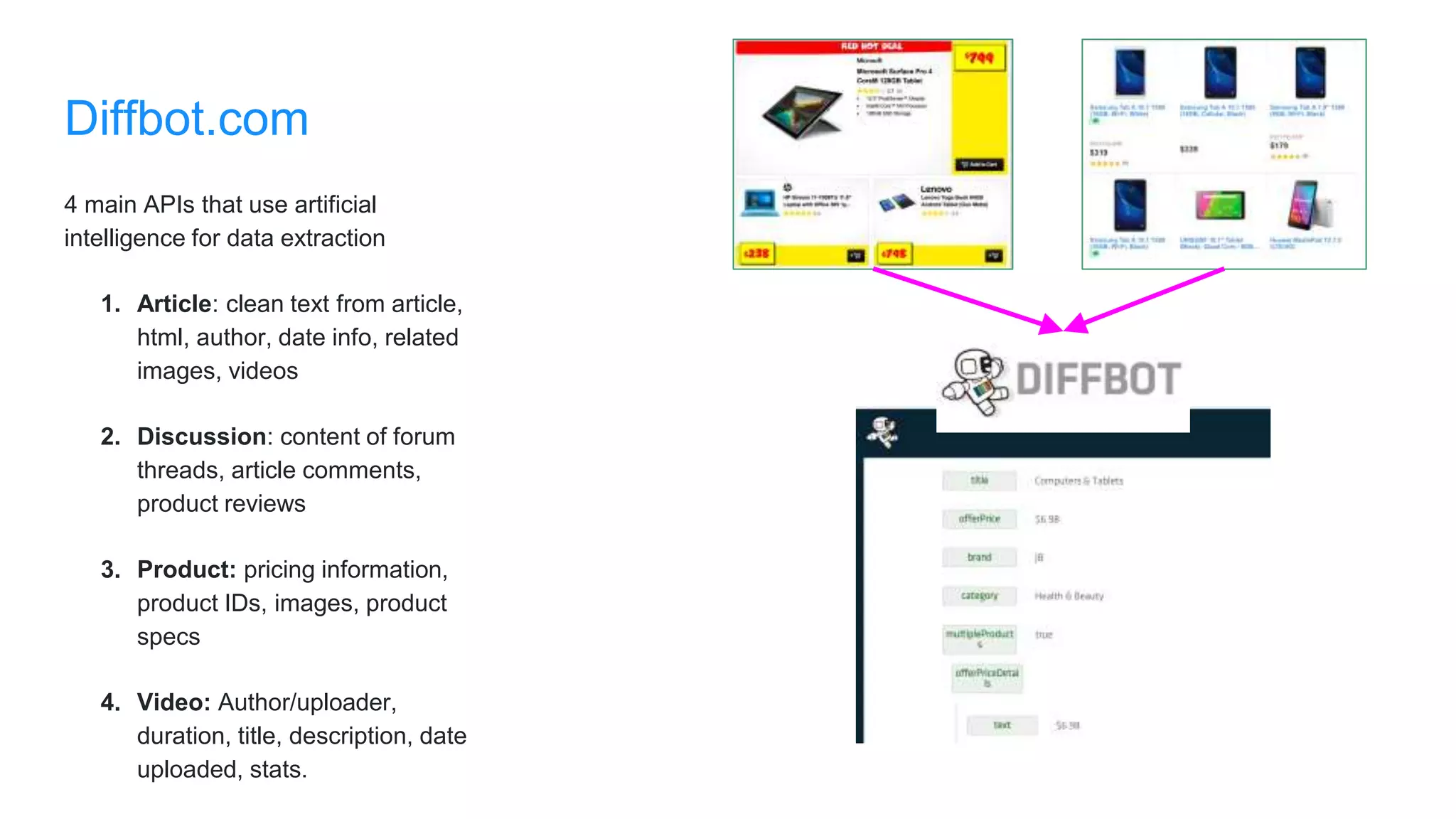
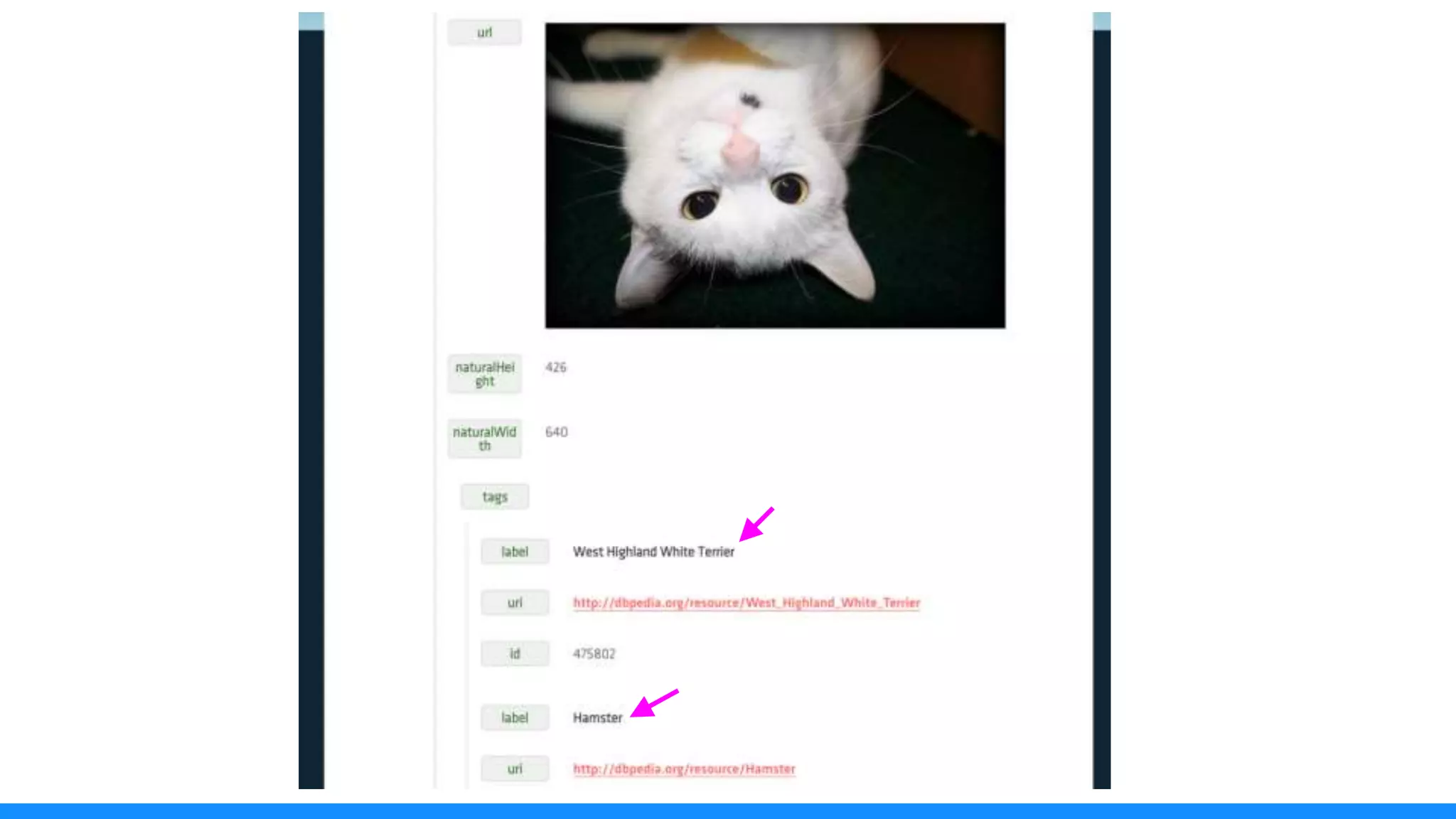






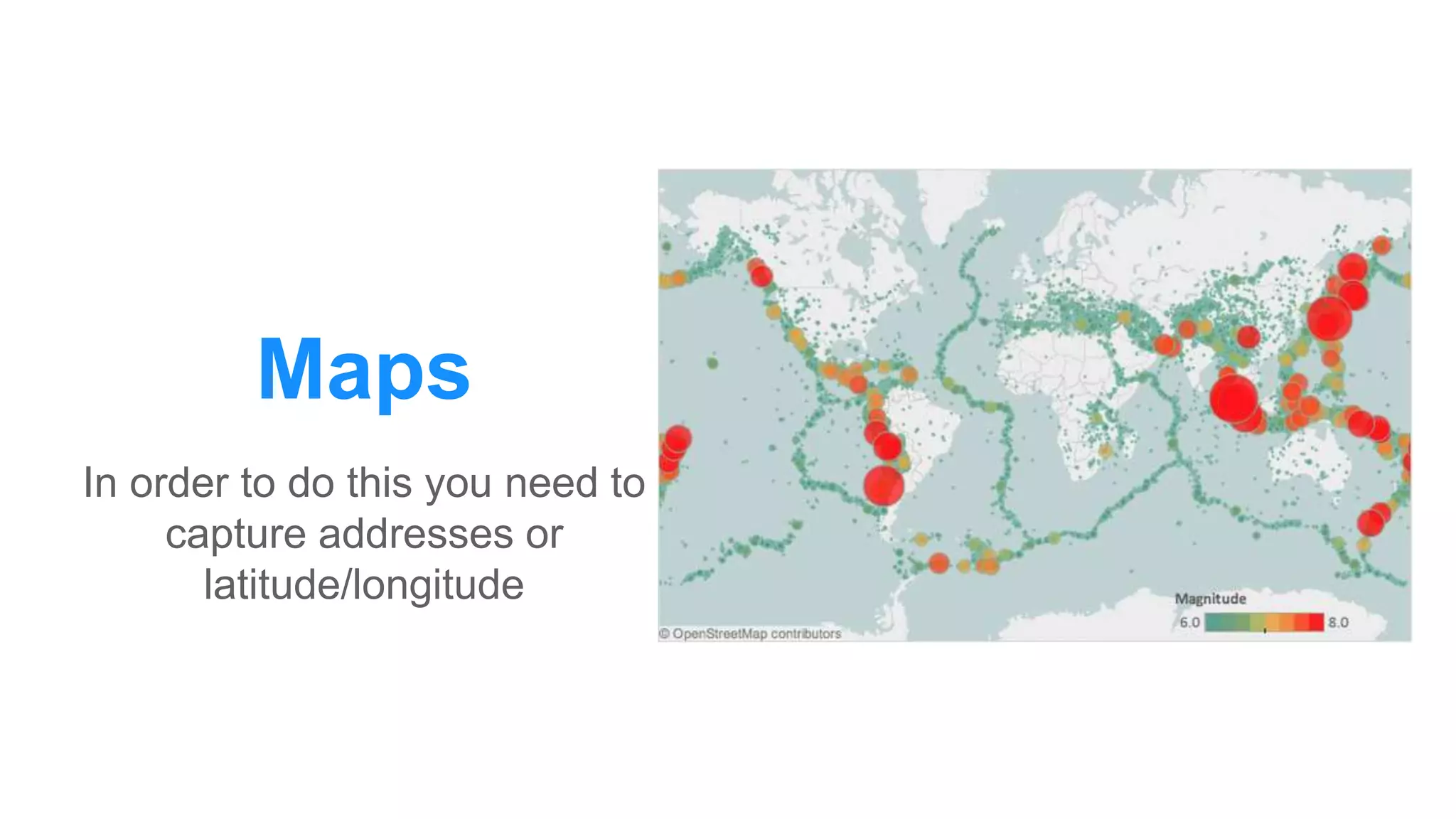
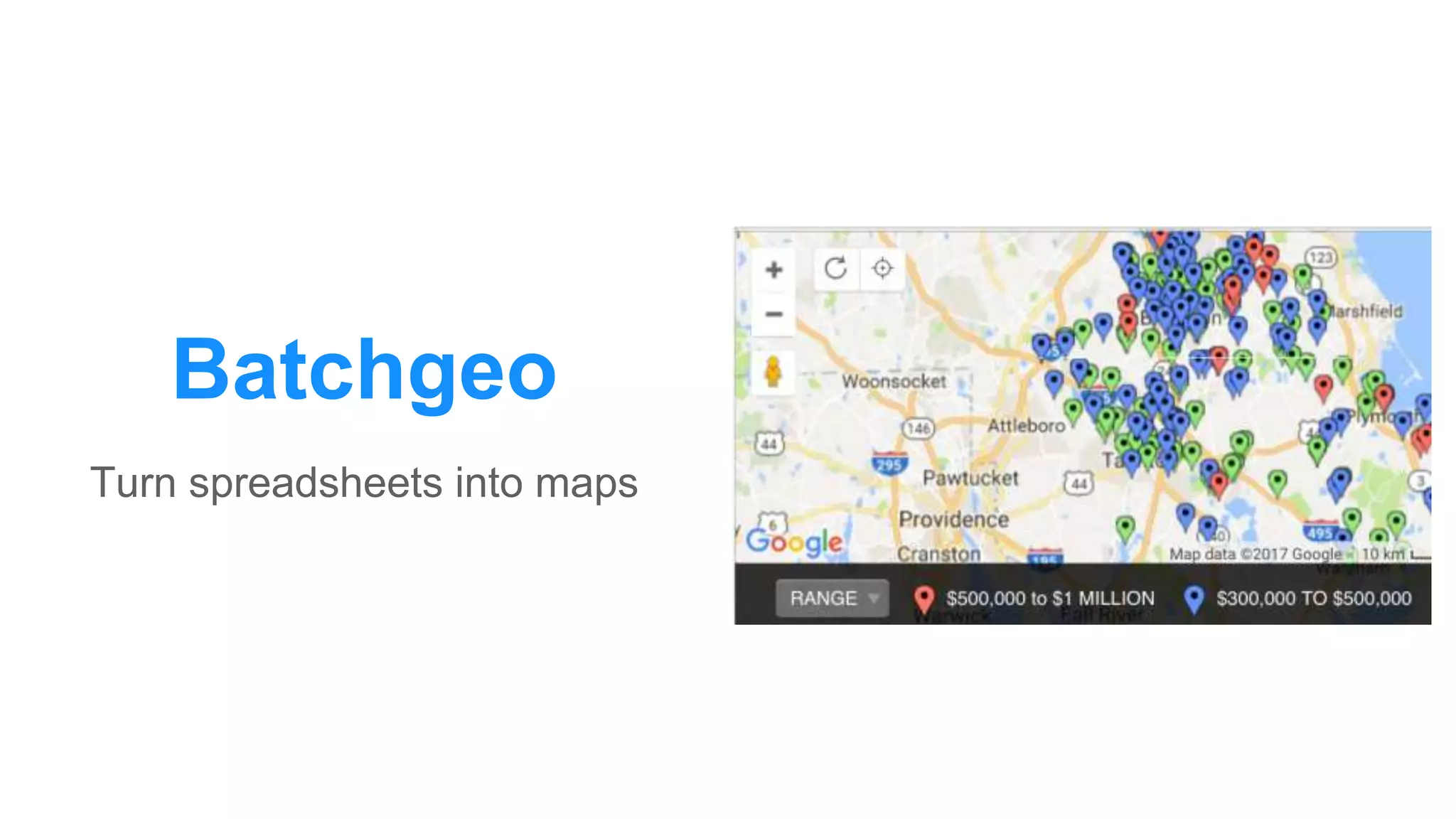
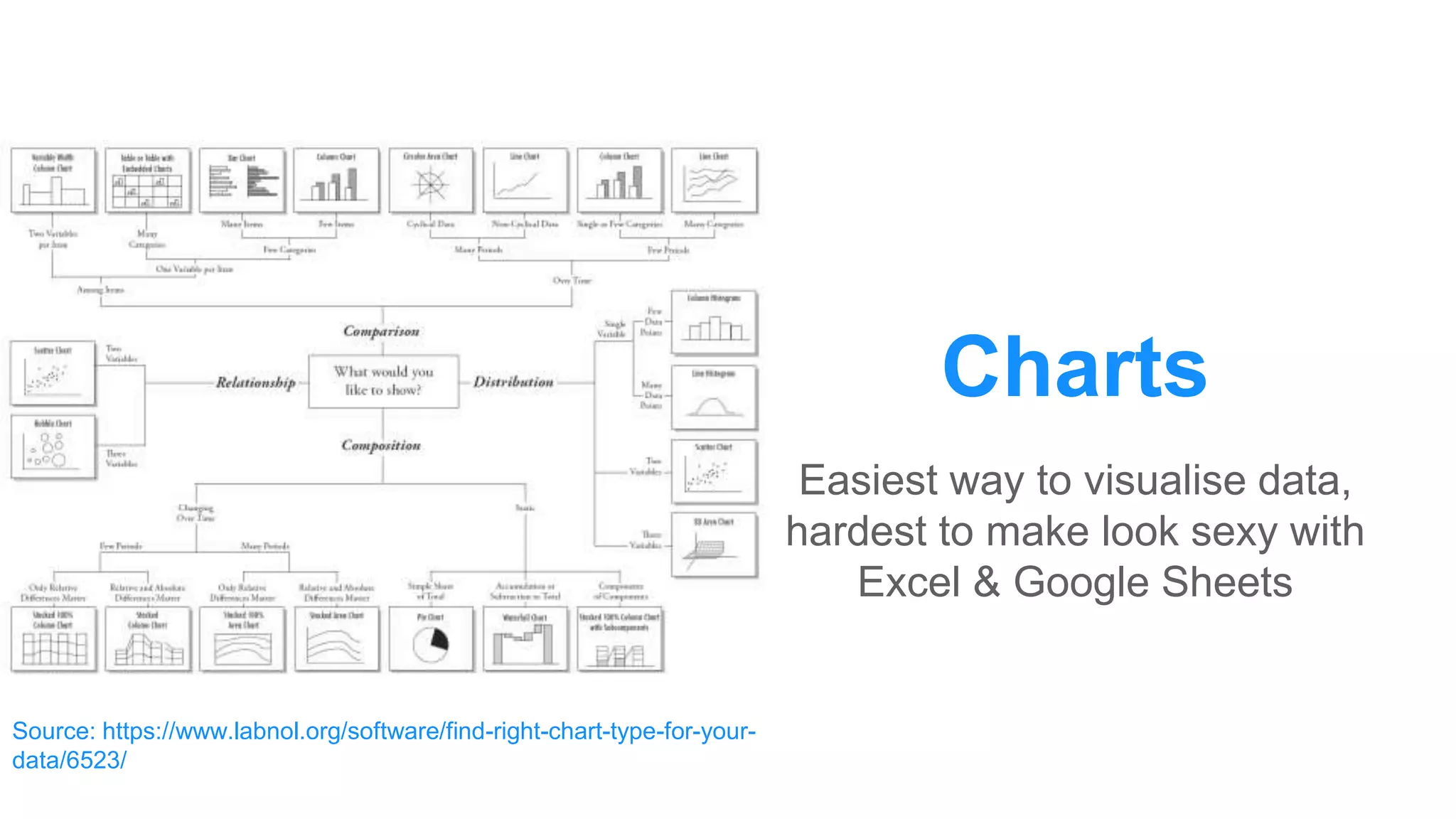

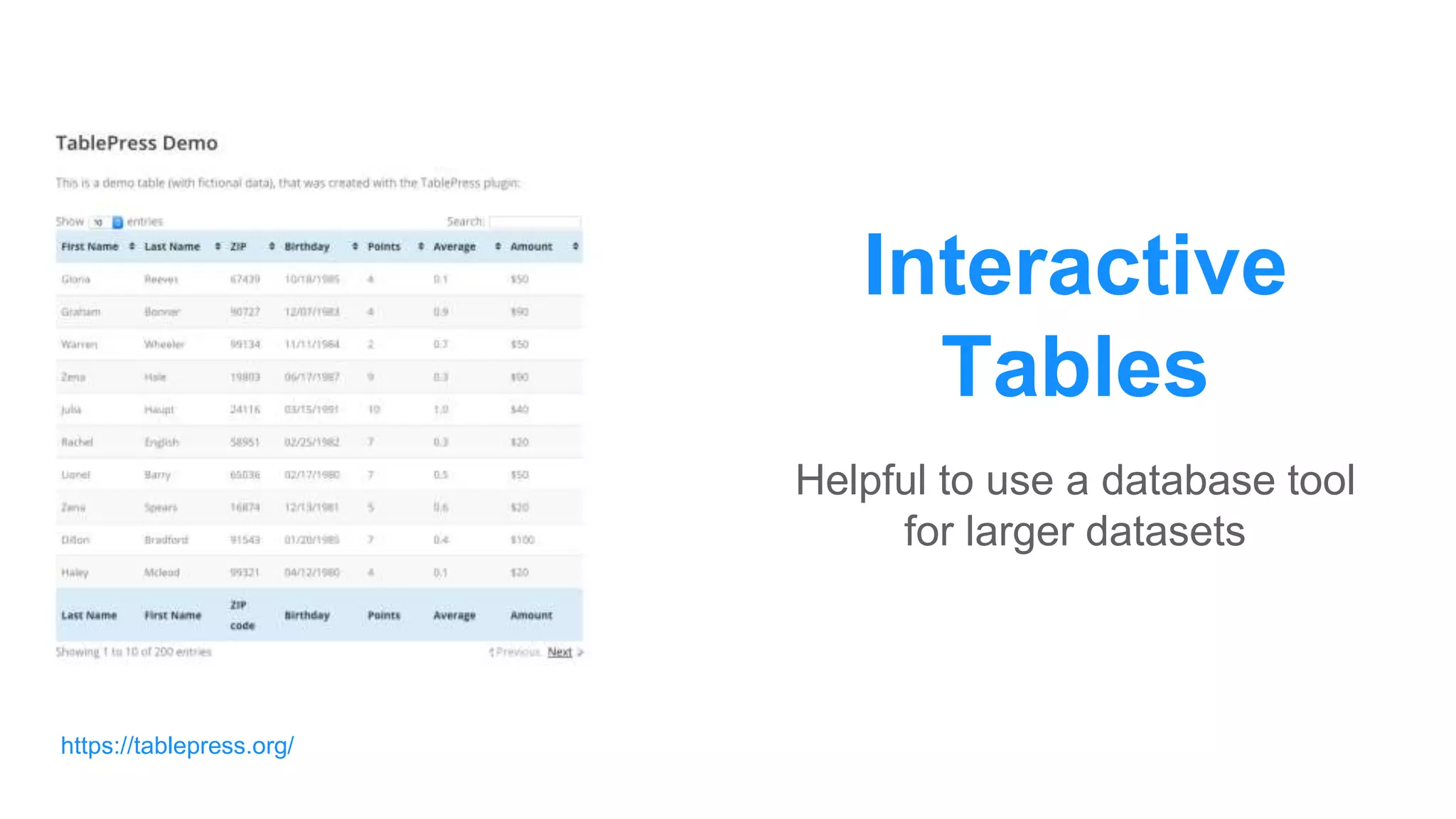






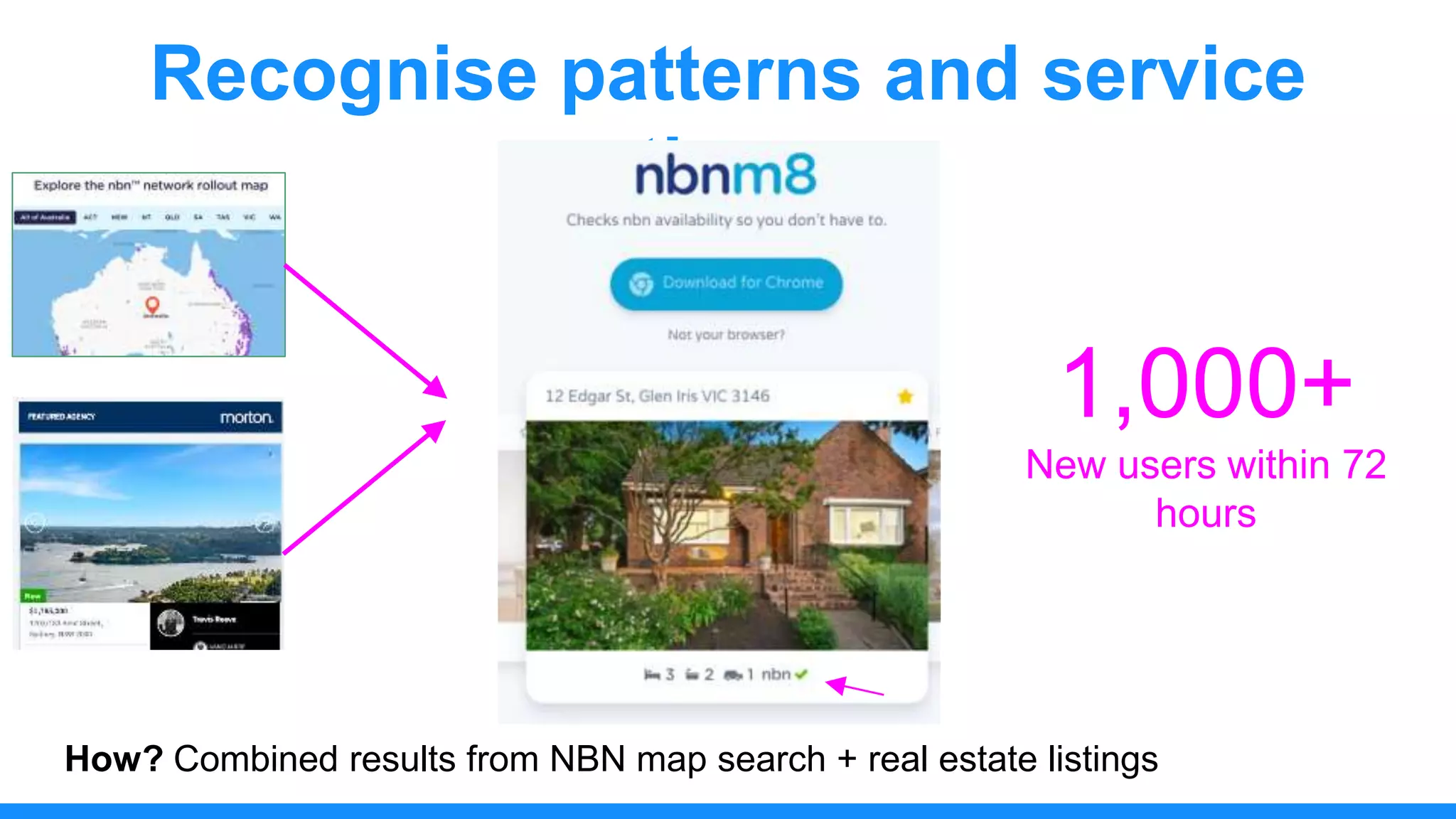
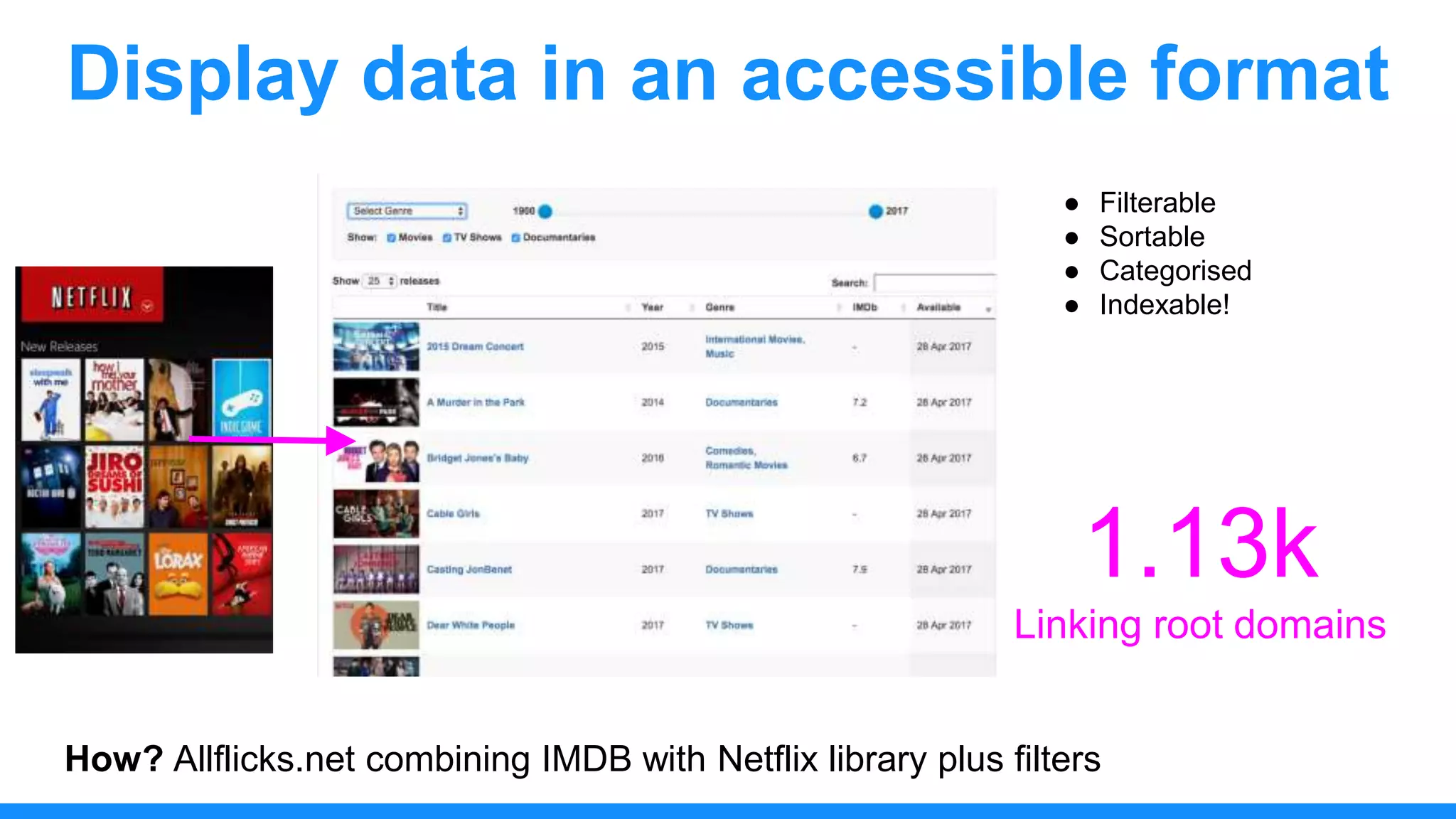
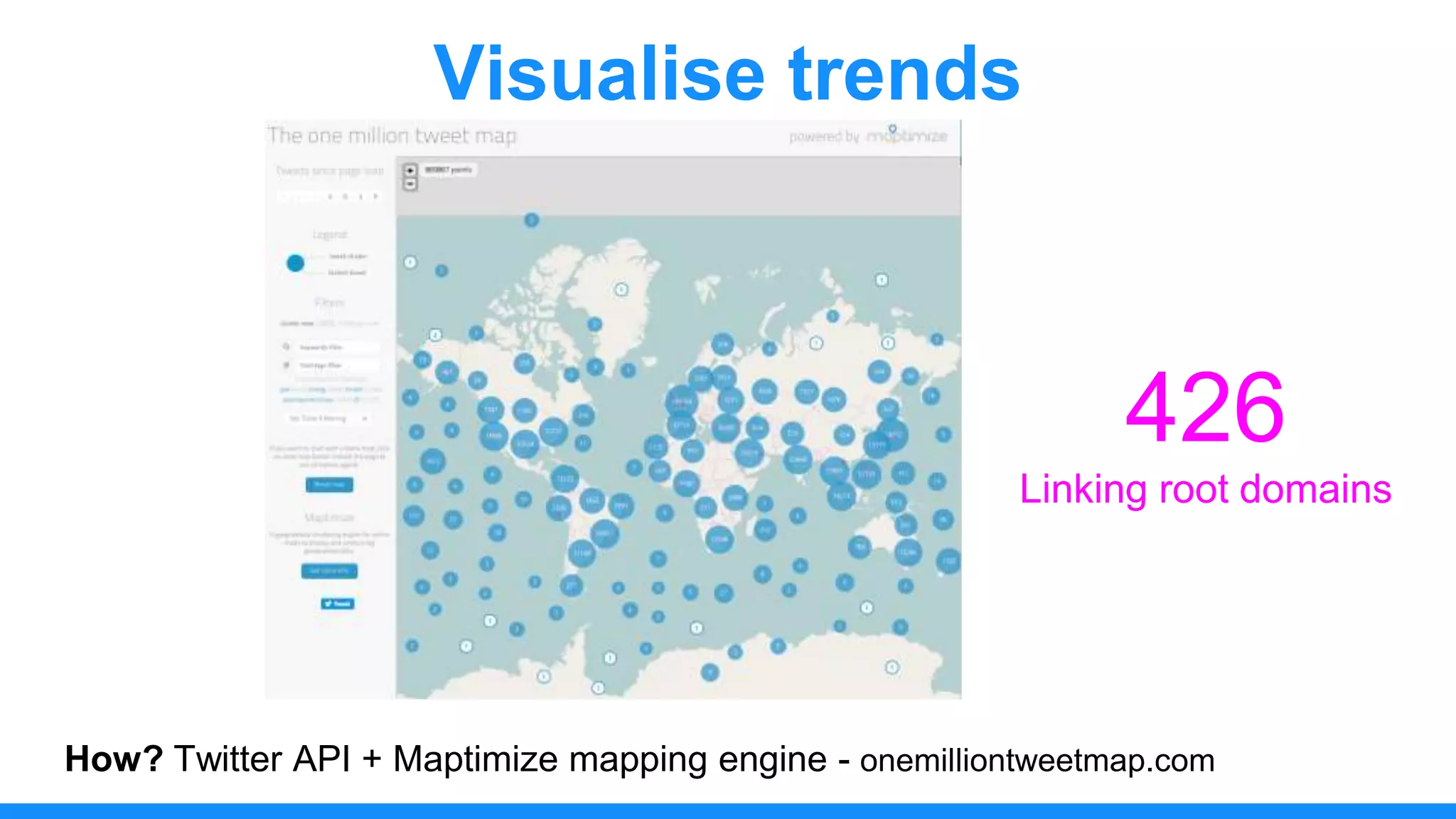
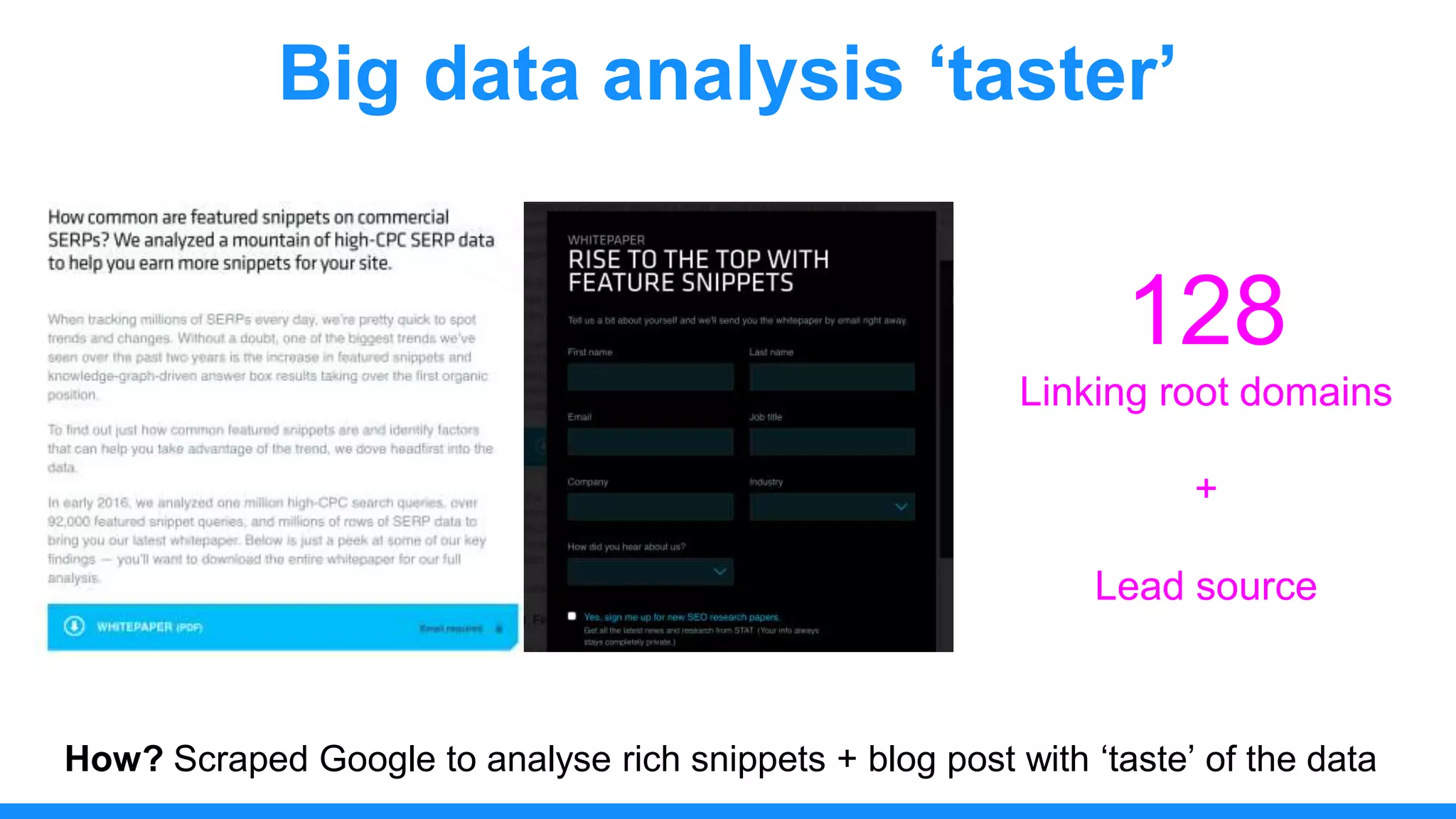







The document discusses the use of data scraping for content marketing, highlighting its potential for generating original research and driving engagement. It provides a comprehensive overview of data scraping methods, tools, and best practices, as well as the legal considerations involved. Additionally, it emphasizes the importance of data visualization and effective content distribution strategies to enhance data-driven marketing efforts.


































































