Download to read offline




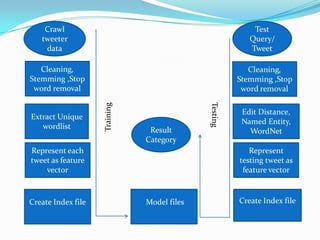













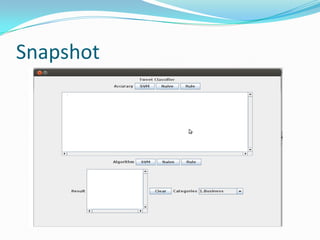
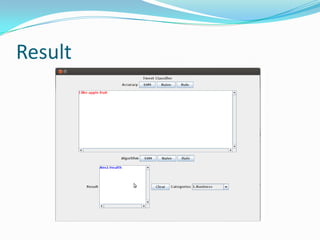
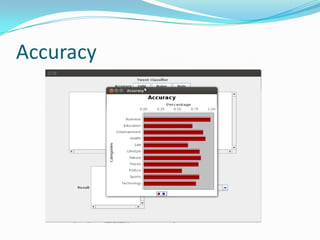





The document discusses a project aimed at automatically classifying tweets into predefined categories using algorithms like Naïve Bayes, SVM, and rule-based methods. The project utilizes data from Twitter, along with techniques for data cleaning and feature extraction, and achieves classification accuracy ranging from 85% to 95%. Key concepts include stop word removal, spell correction, and named entity recognition, with a focus on enhancing information retrieval from trending topics.






















































