




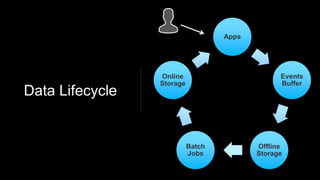
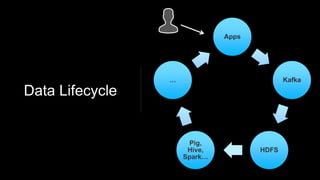



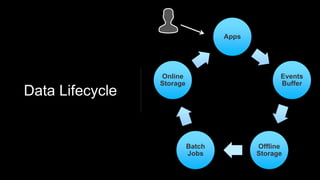
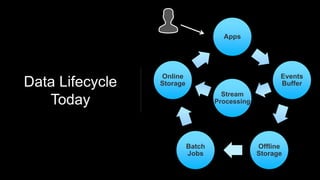

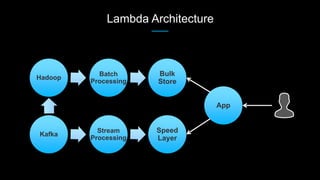

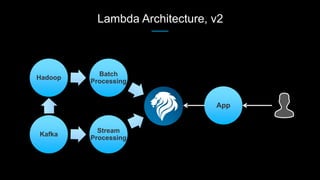









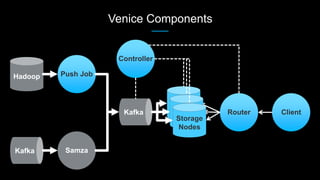

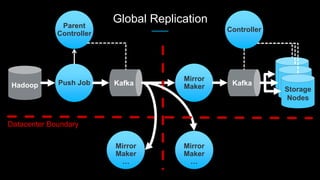


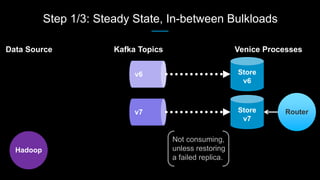
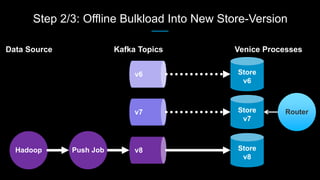
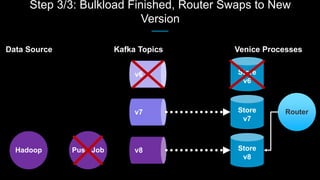



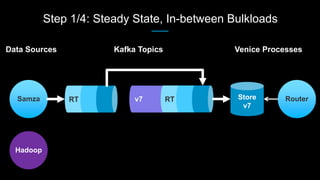
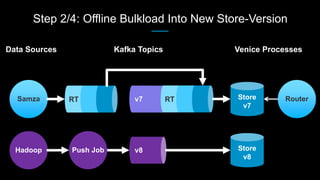
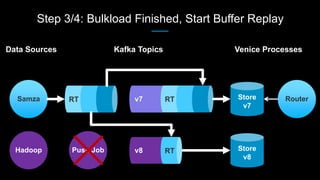
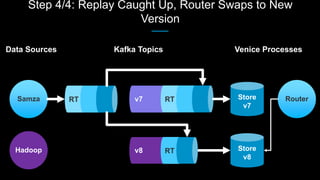






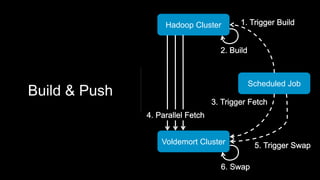
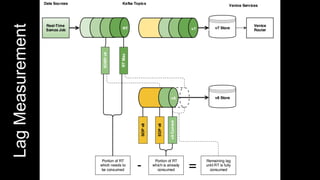

Venice is a derived data store that can handle both batch and streaming data. It uses Kafka to ingest all data, whether from Hadoop batch jobs or real-time sources like Samza. This allows Venice to offer a hybrid storage model that can merge the two data types. Venice improves on earlier systems by offering high availability, automatic data distribution, and seamless rollbacks between versions. It has been in production at LinkedIn since 2016 and is replacing their legacy Voldemort read-only stores.








![[WSO2Con EU 2018] Decentralized Data Architectures](https://cdn.slidesharecdn.com/ss_thumbnails/wso2coneu2018-decentraliseddataarchitectures-181113104248-thumbnail.jpg?width=640&height=640&fit=bounds)


















