Download to read offline




















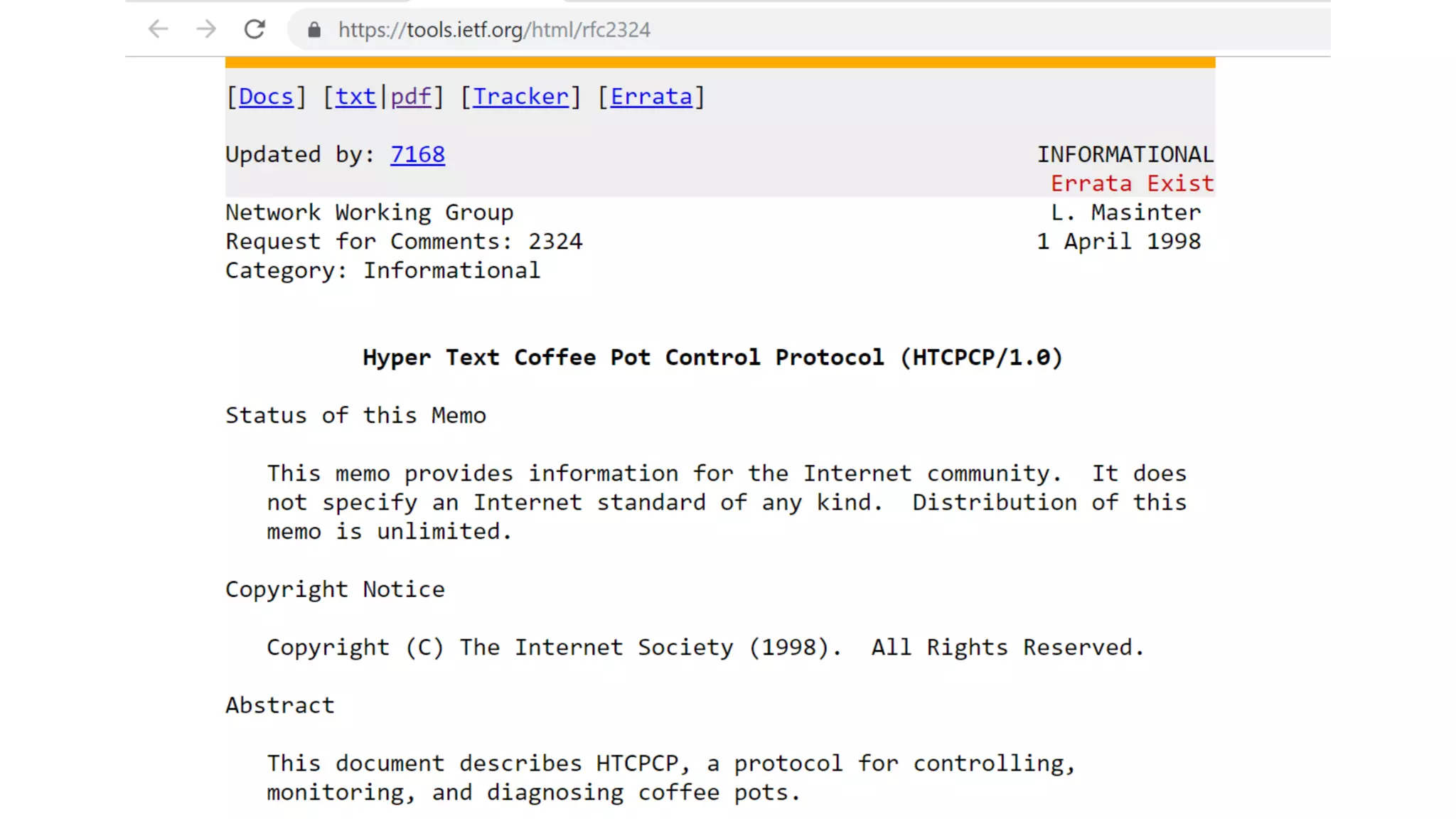

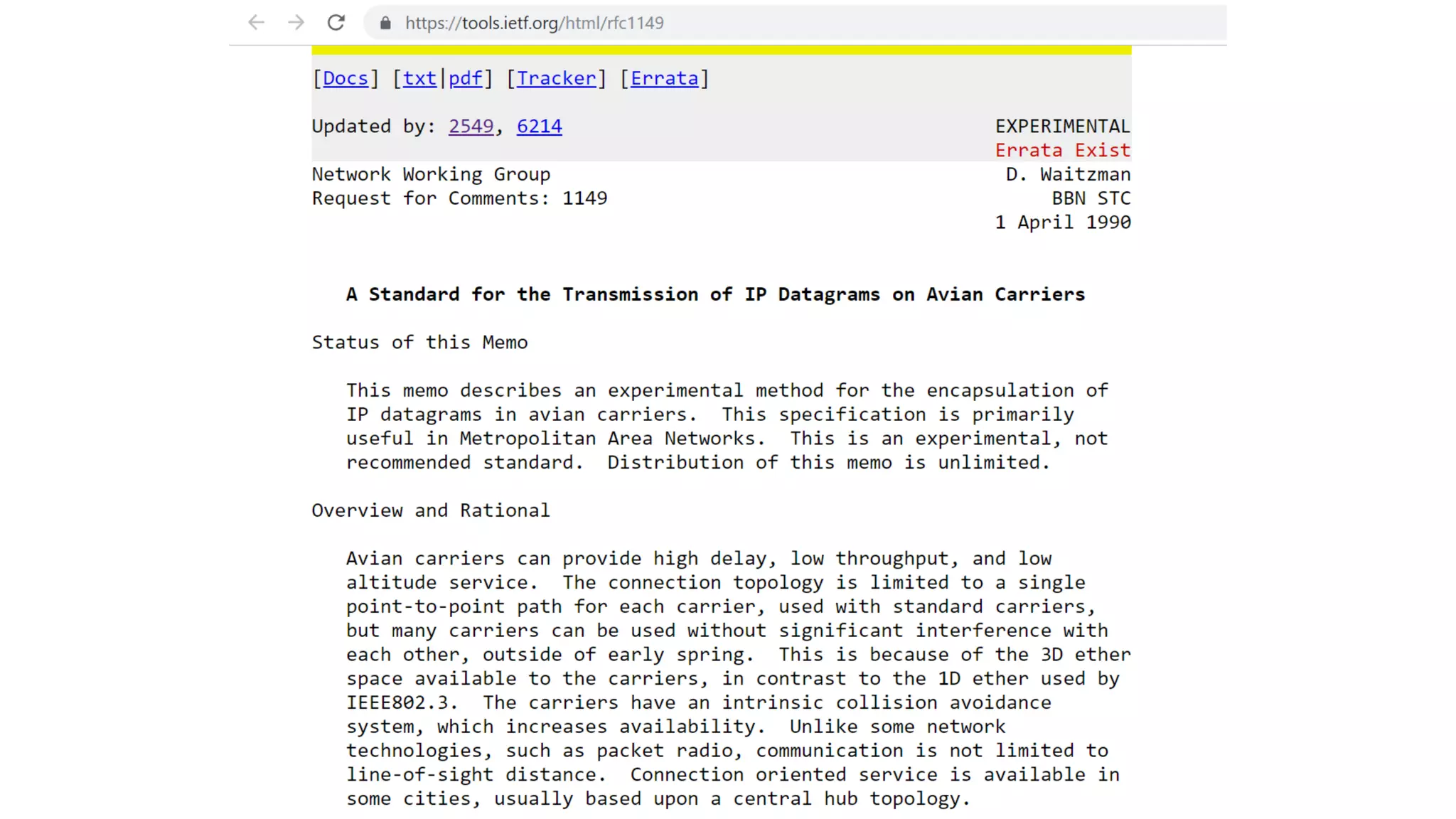



![Open, *[Read | Write], Close](https://image.slidesharecdn.com/interactionprotocols-190522103250/75/Interaction-Protocols-It-s-all-about-good-manners-29-2048.jpg)
![Open, *[Read | Write], Close
1. Open: ...
2. Read: ...
3. Write: ...
4. Close: ...](https://image.slidesharecdn.com/interactionprotocols-190522103250/75/Interaction-Protocols-It-s-all-about-good-manners-30-2048.jpg)






















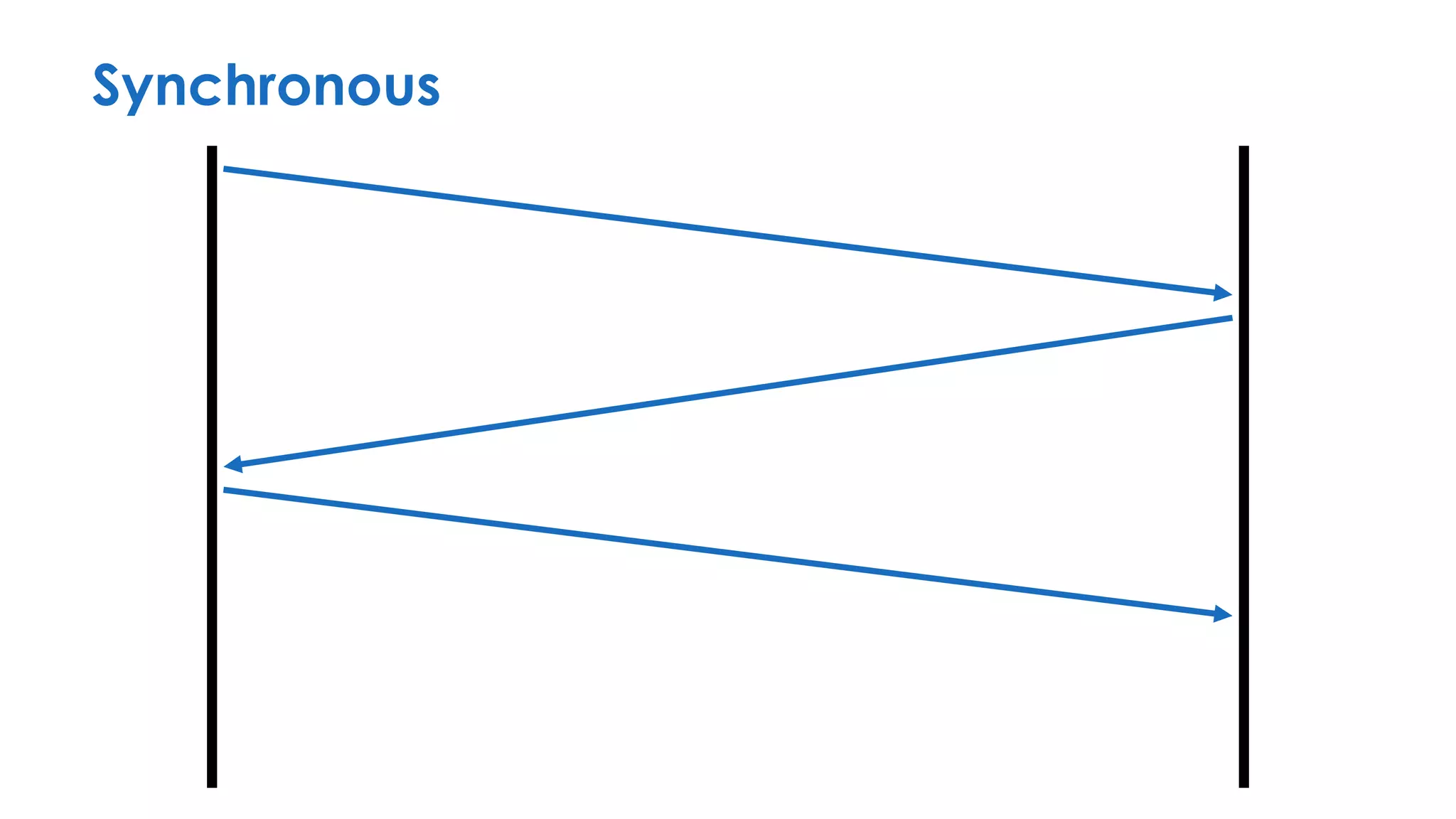
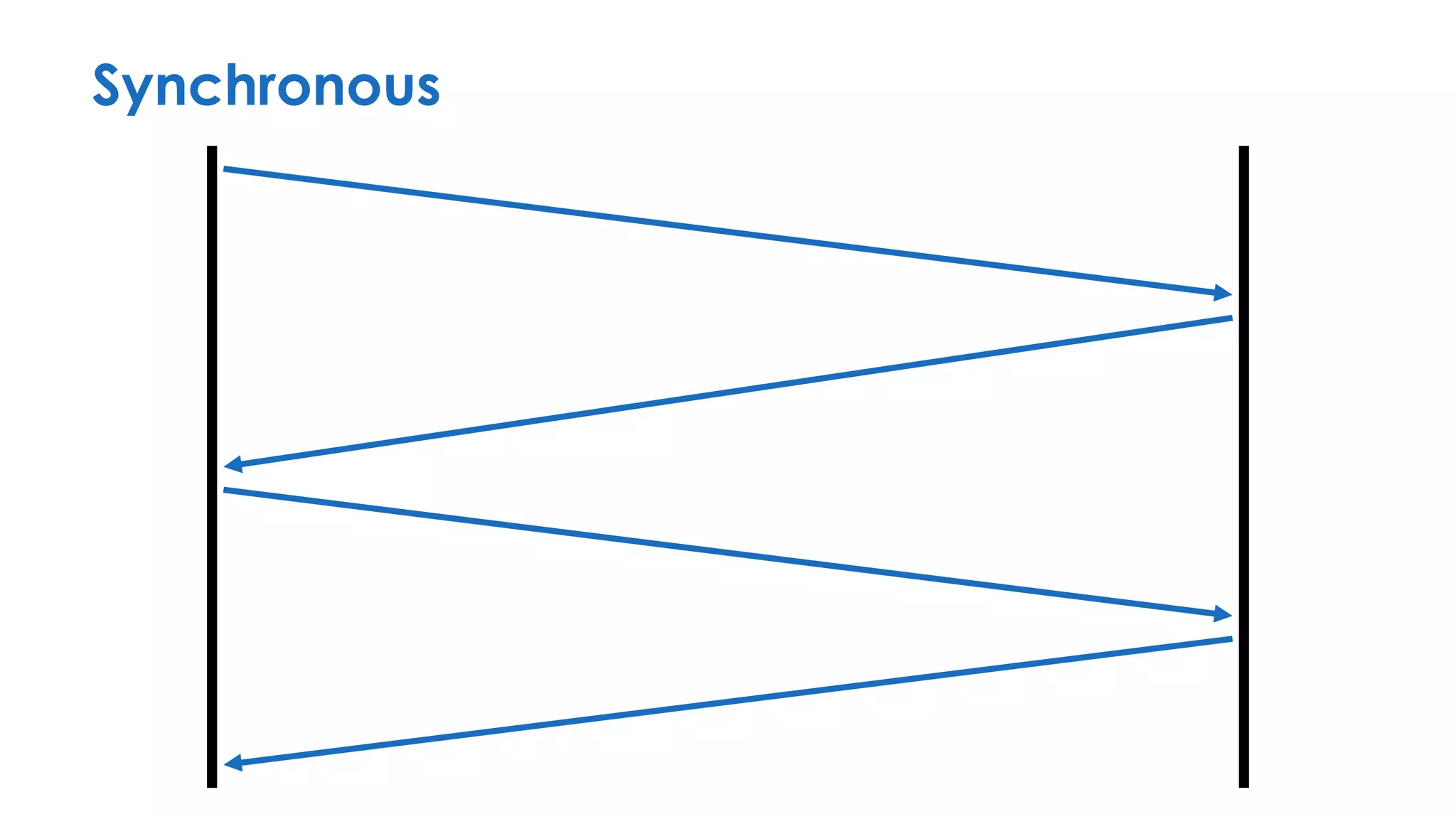




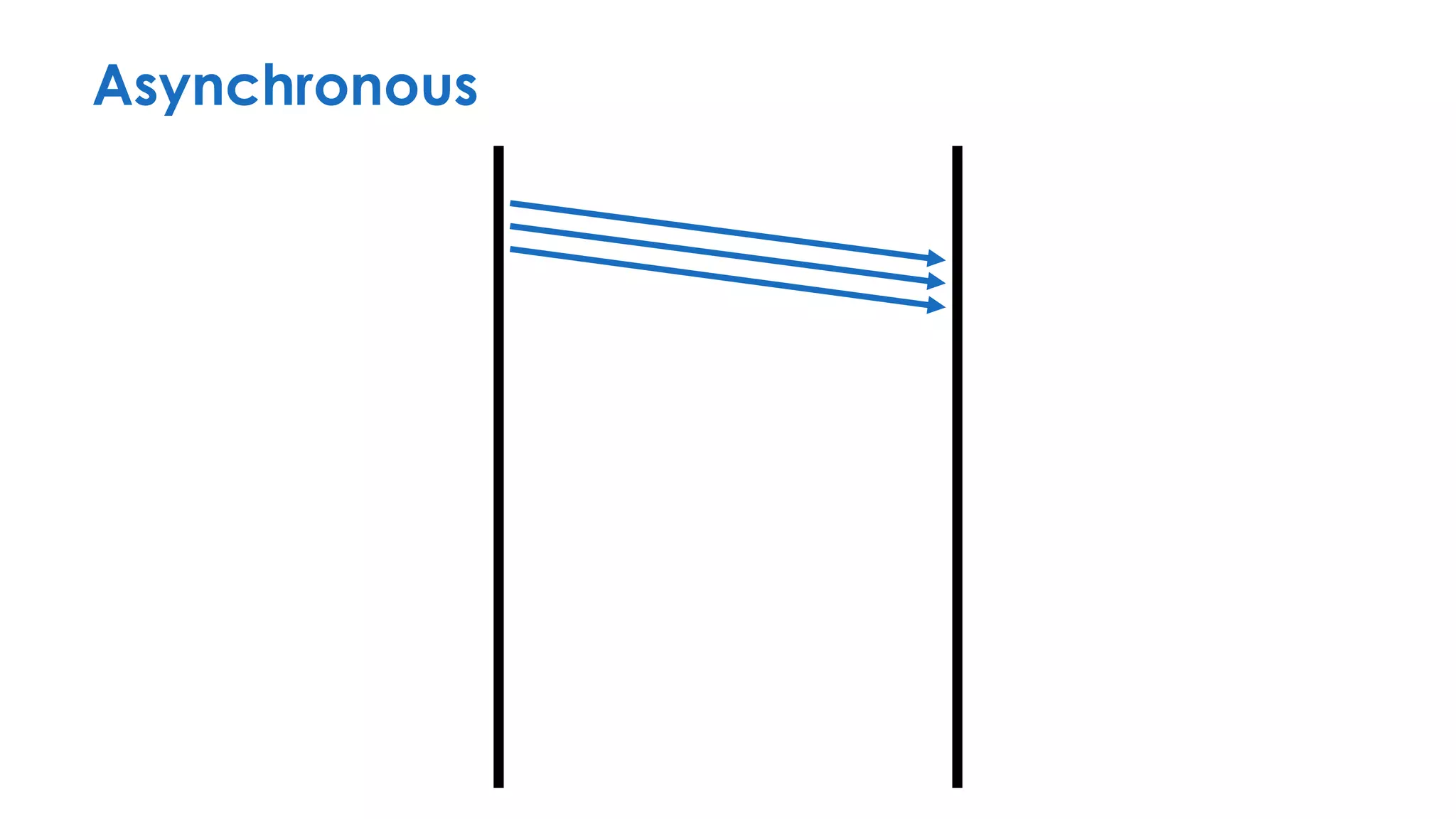
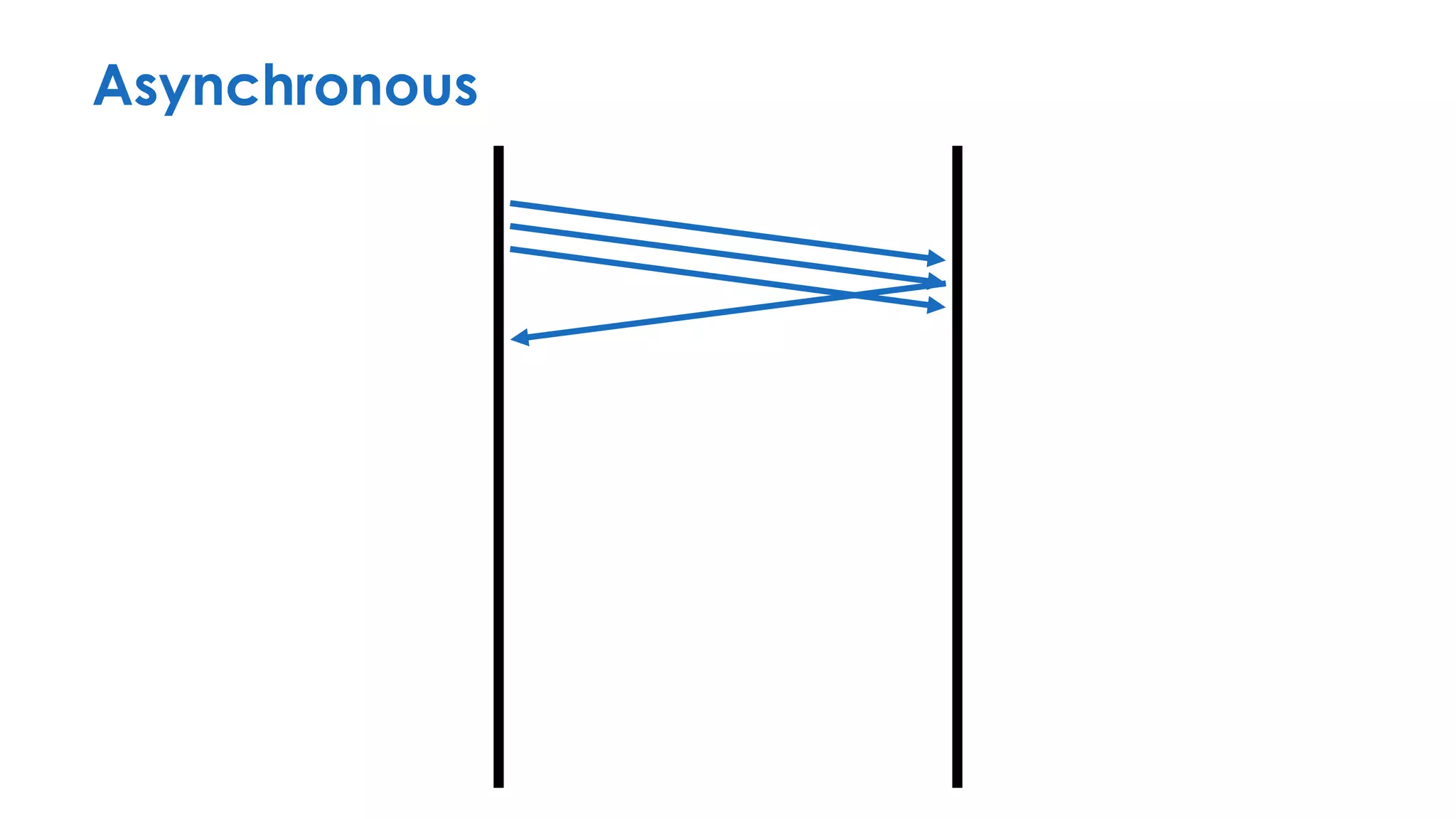
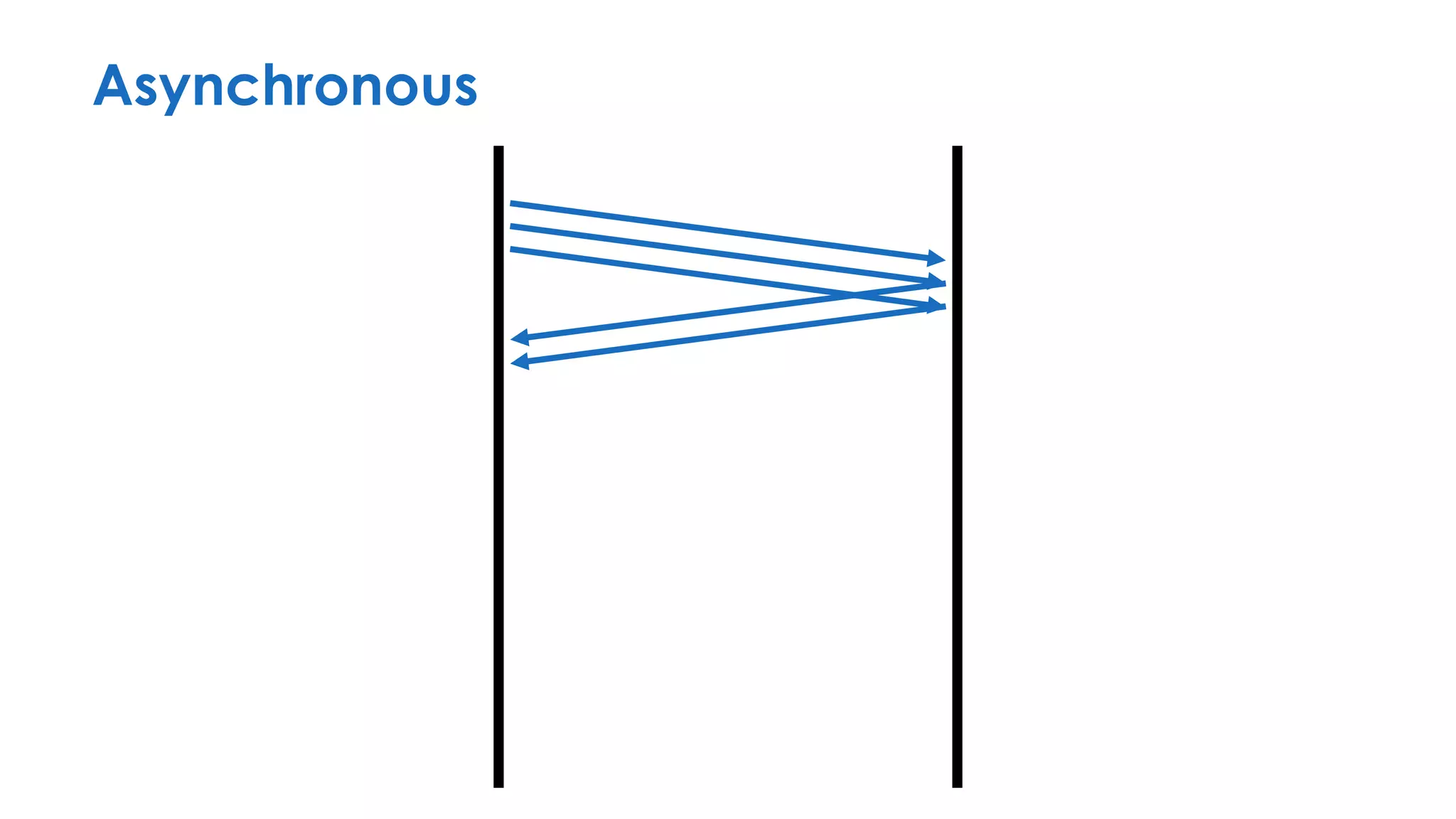
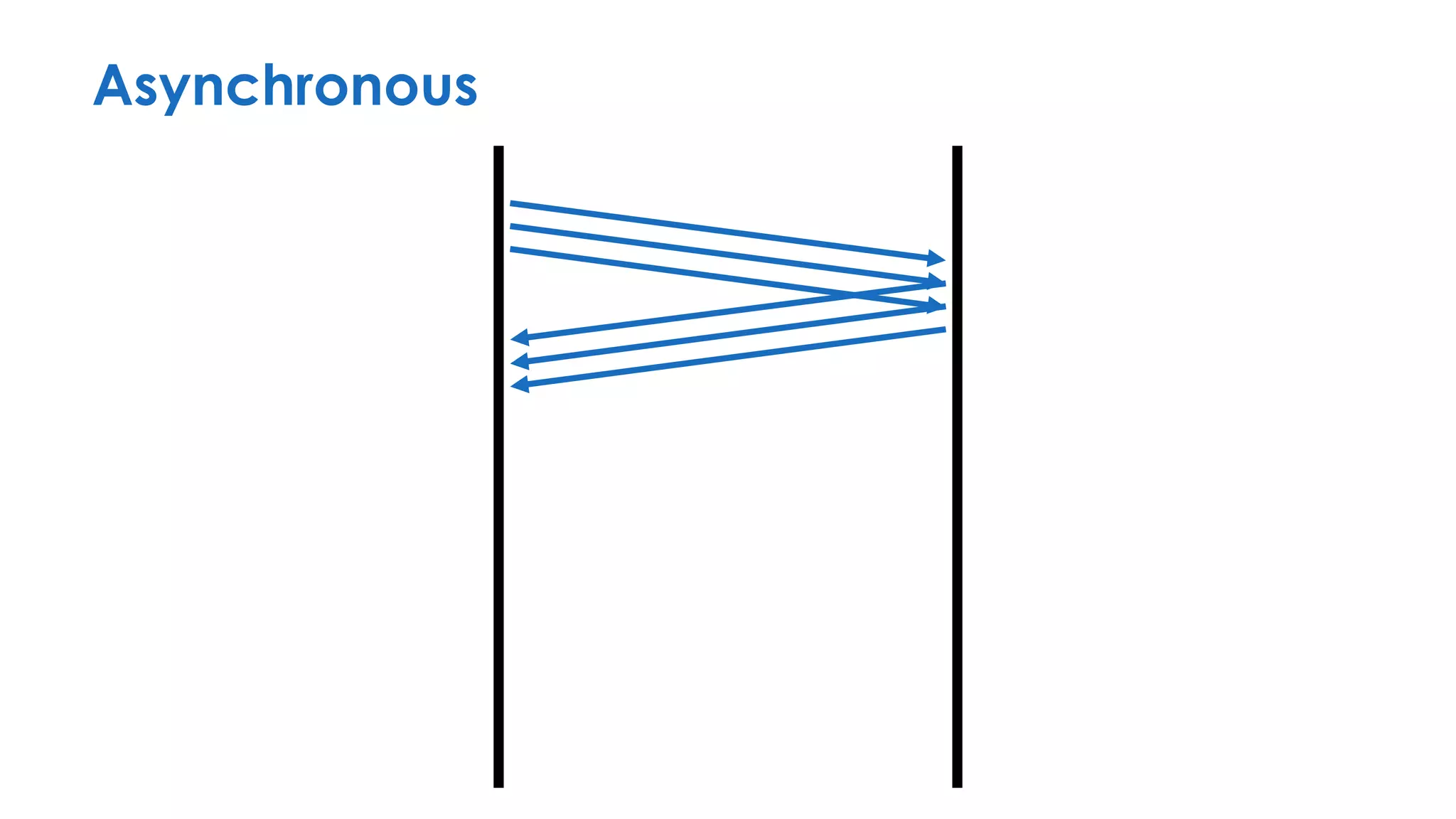




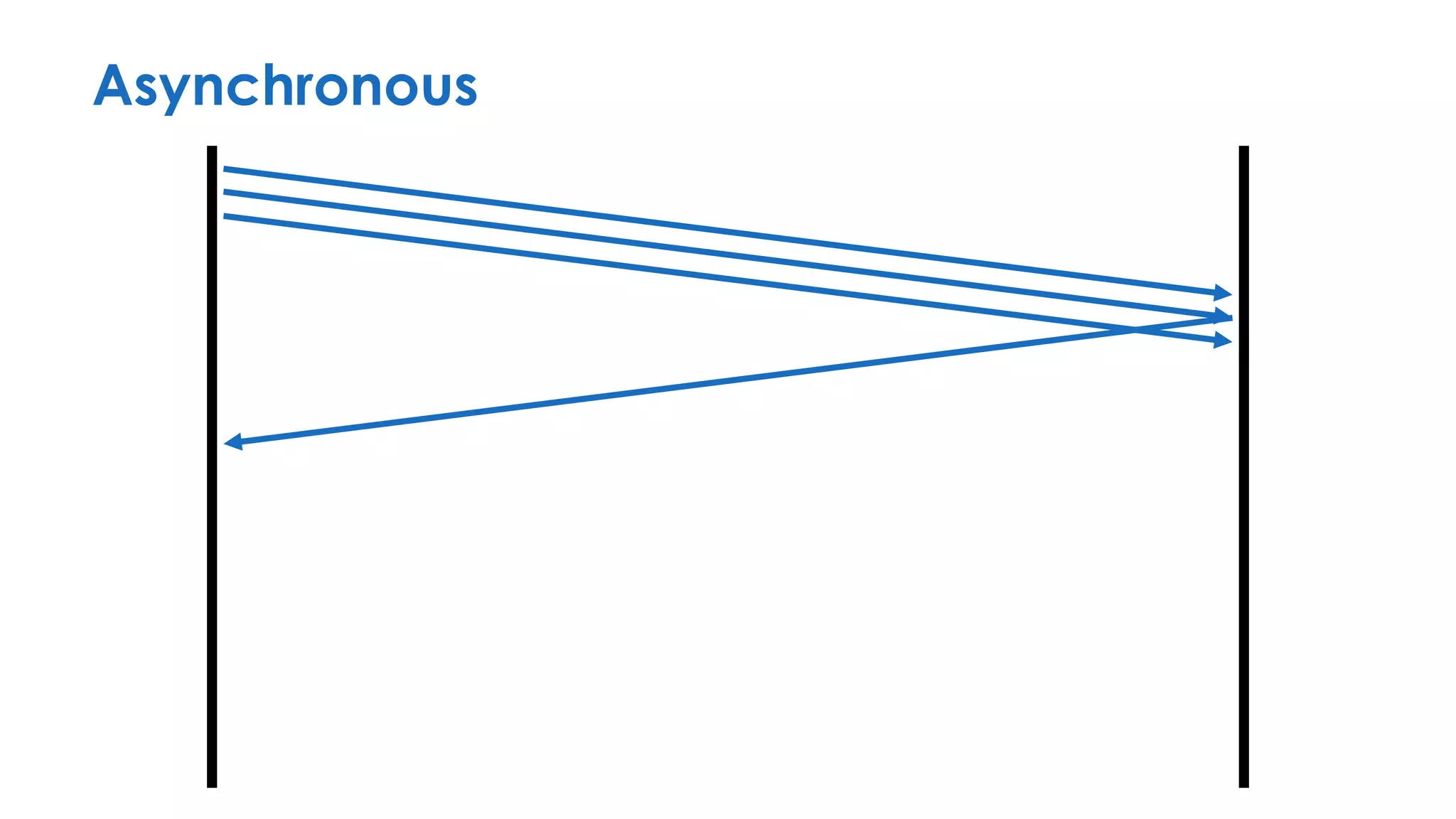
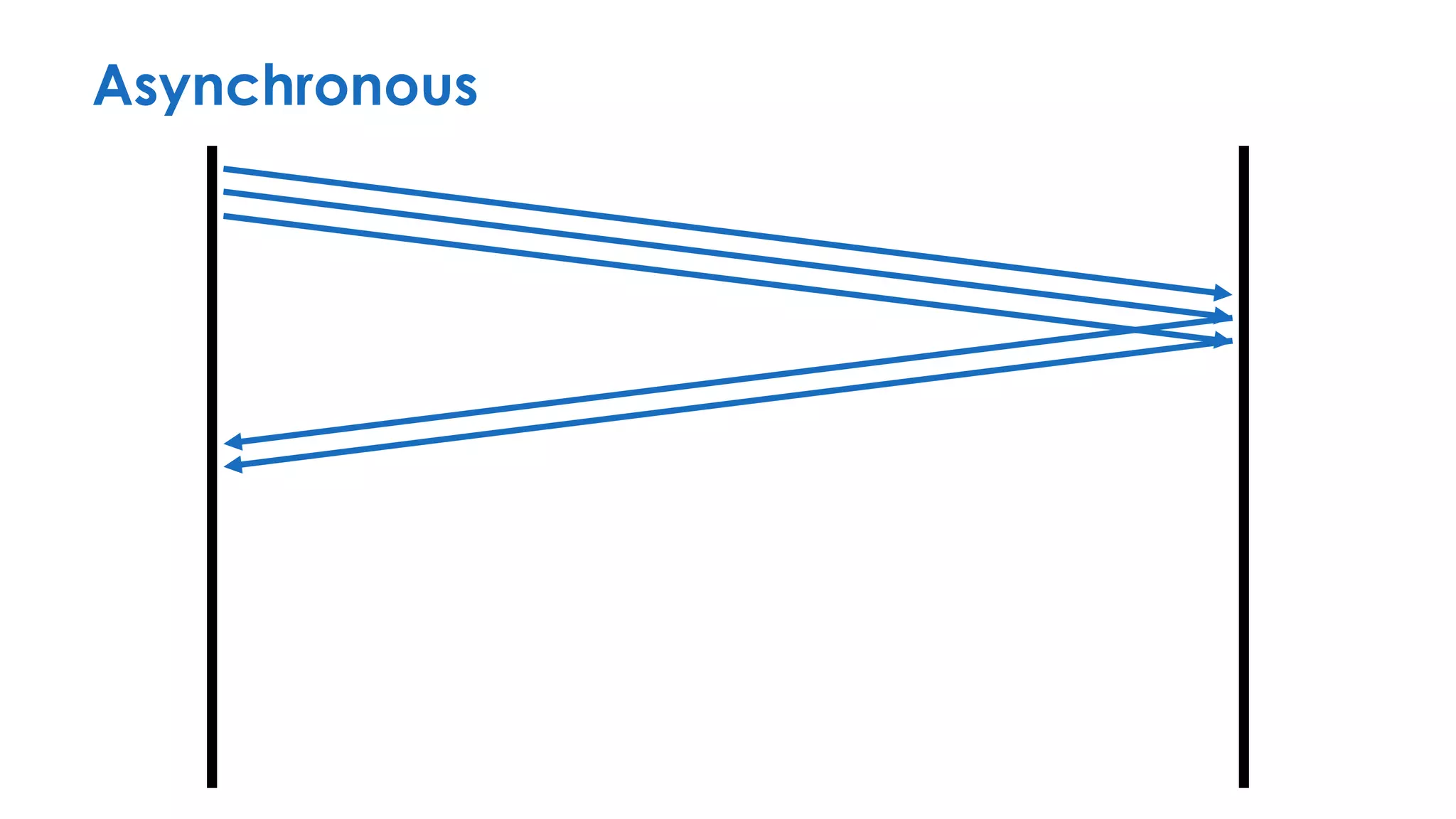
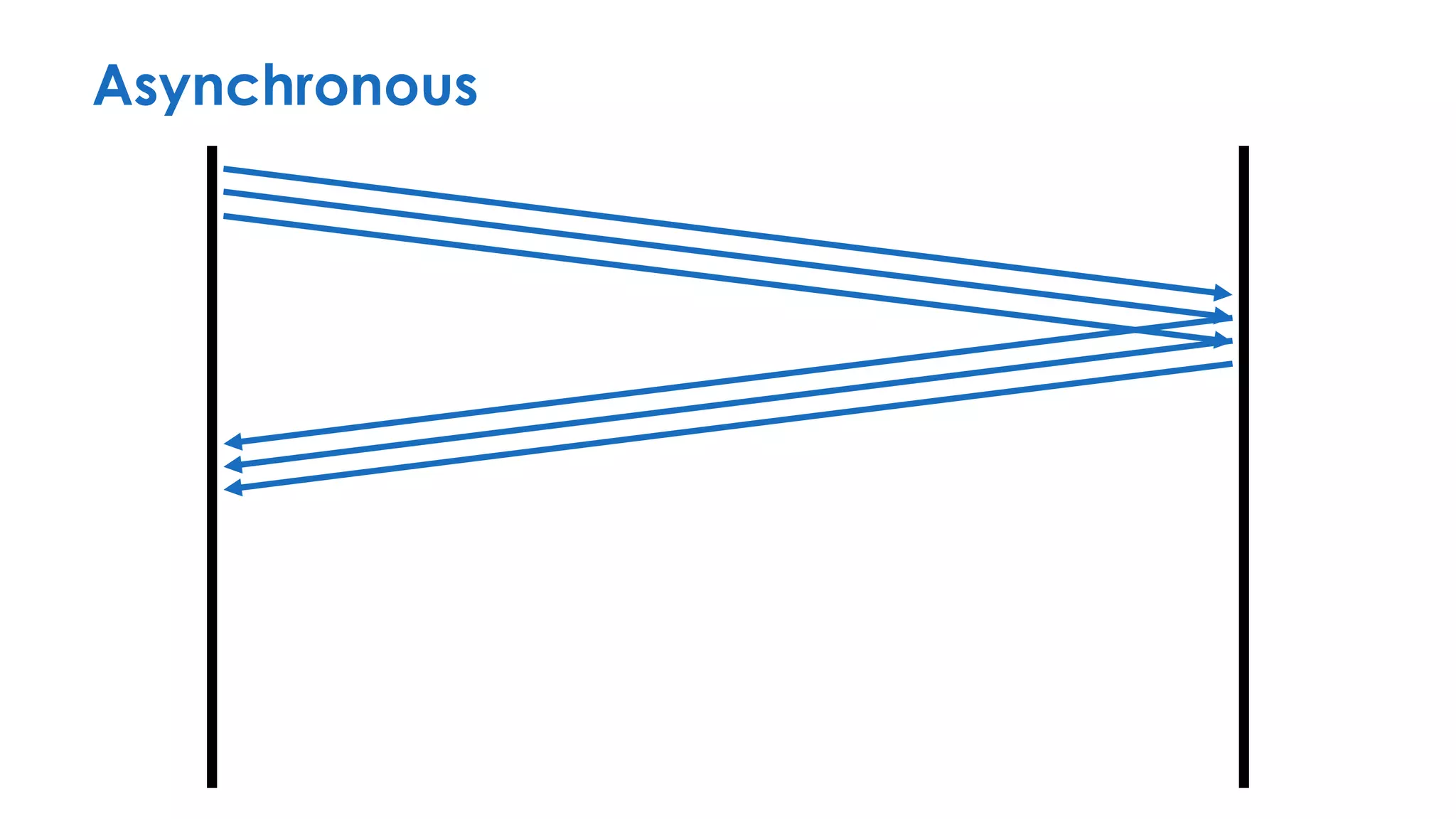






























The document discusses the importance of interaction protocols in communications and computing, exploring their definitions, applications, and implications across various realms such as evolutionary biology and distributed systems. It emphasizes the need for rigorous standards and considerations in protocol design, including versioning, encoding, and error handling, while posing reflective questions about the significance and study of these protocols. Ultimately, it challenges the reader to consider the foundational role of protocols as a key human discovery amid a landscape of technological evolution.



































































