Download as PDF, PPTX










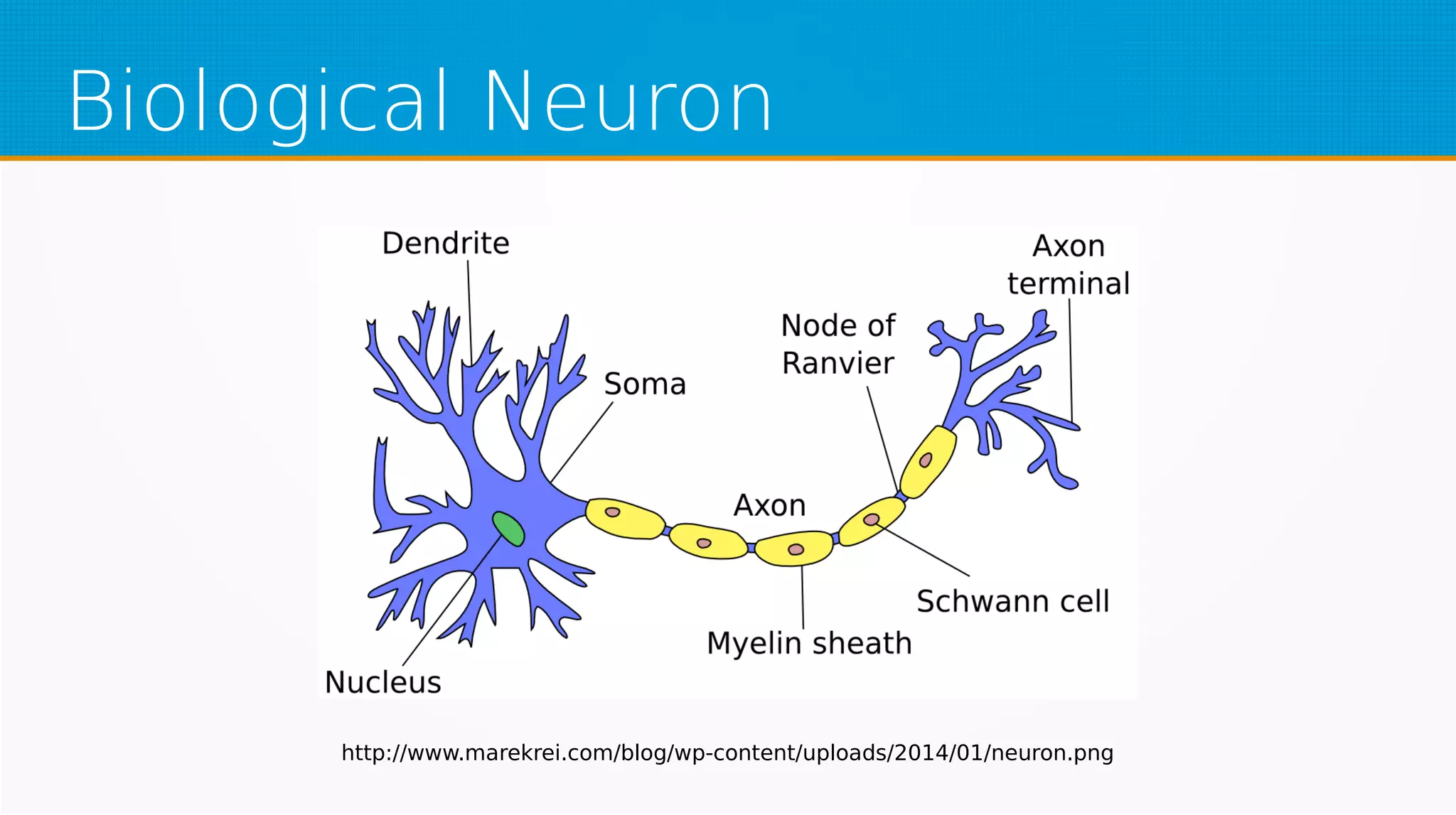
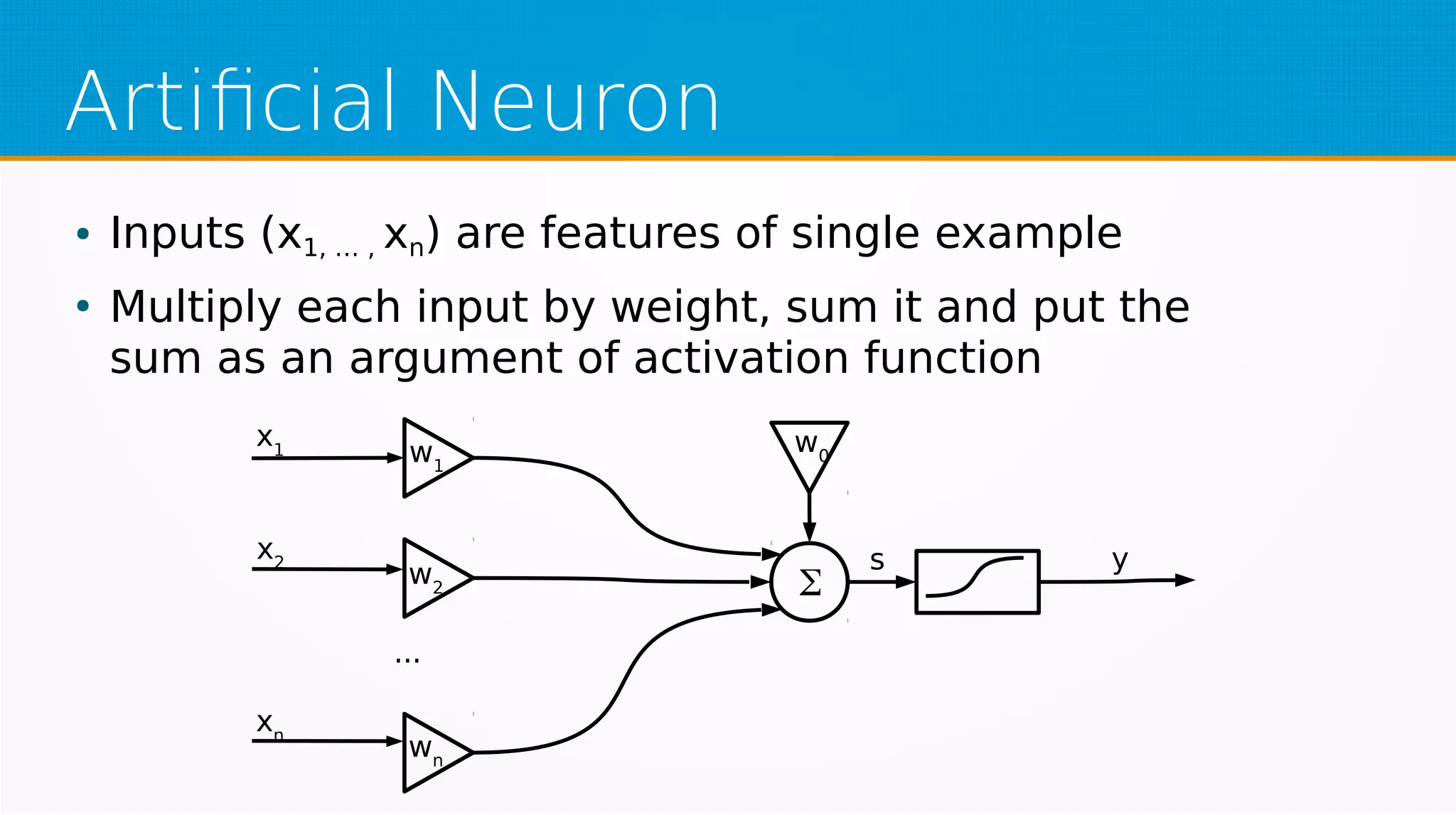
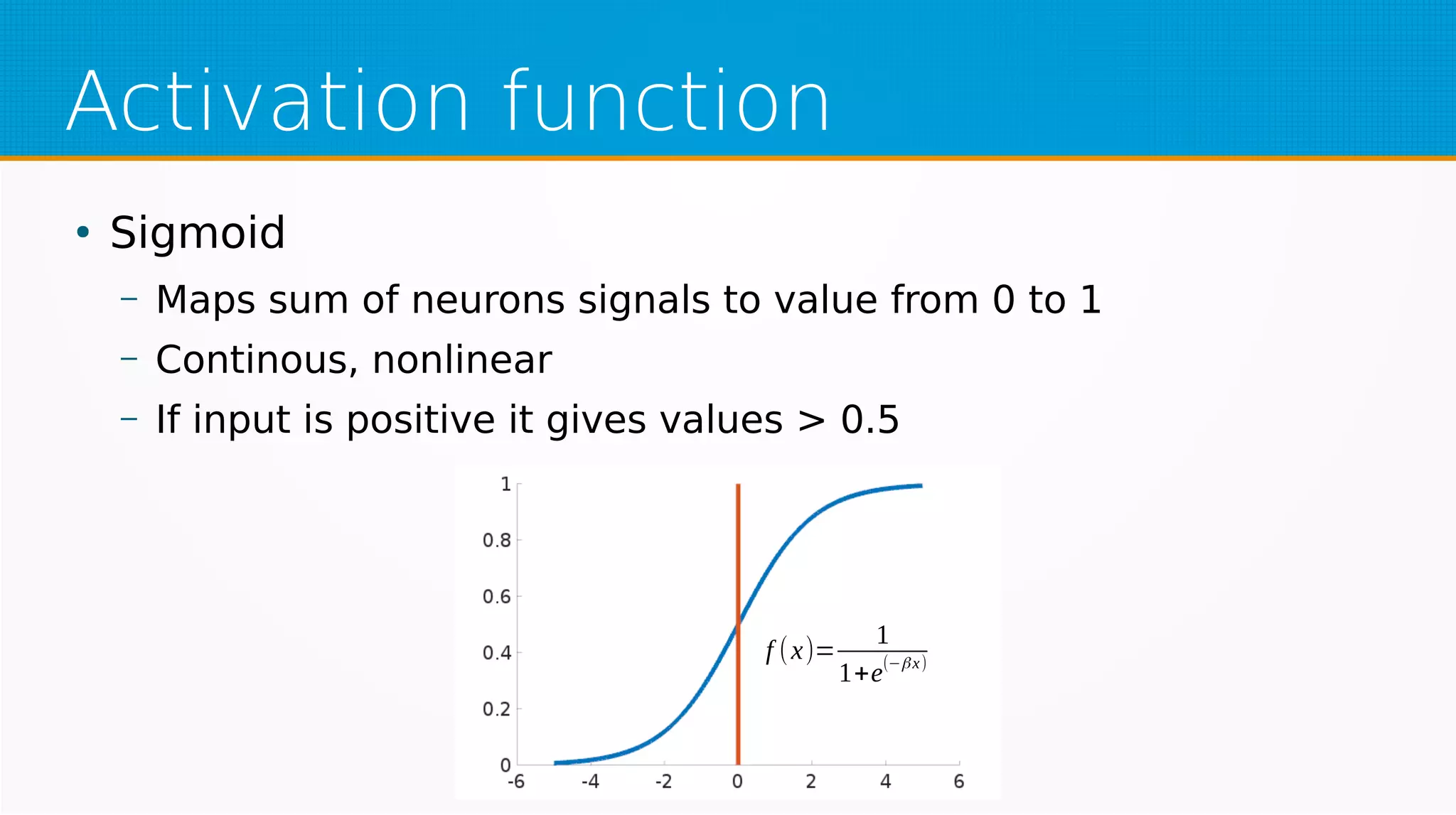



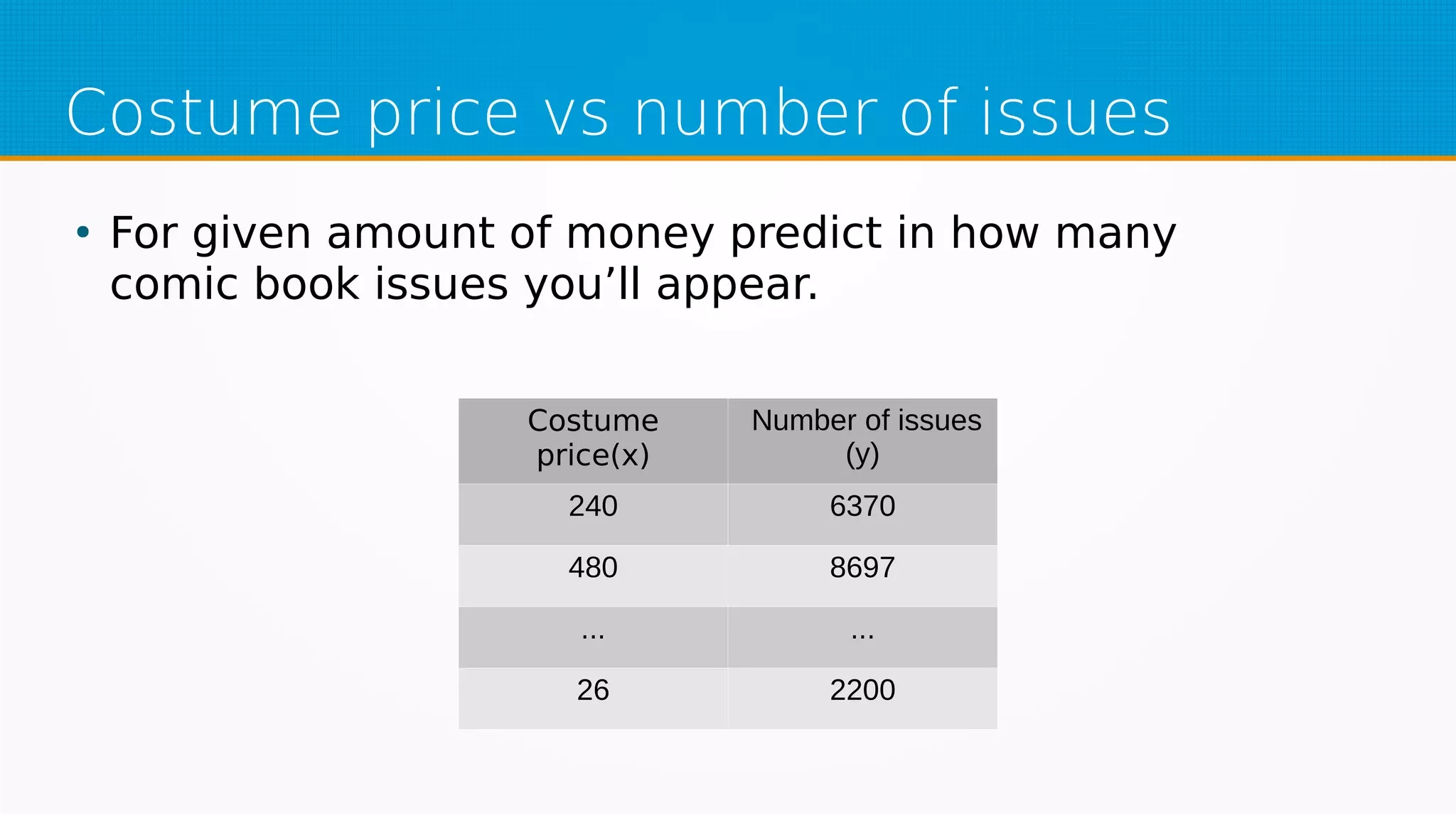


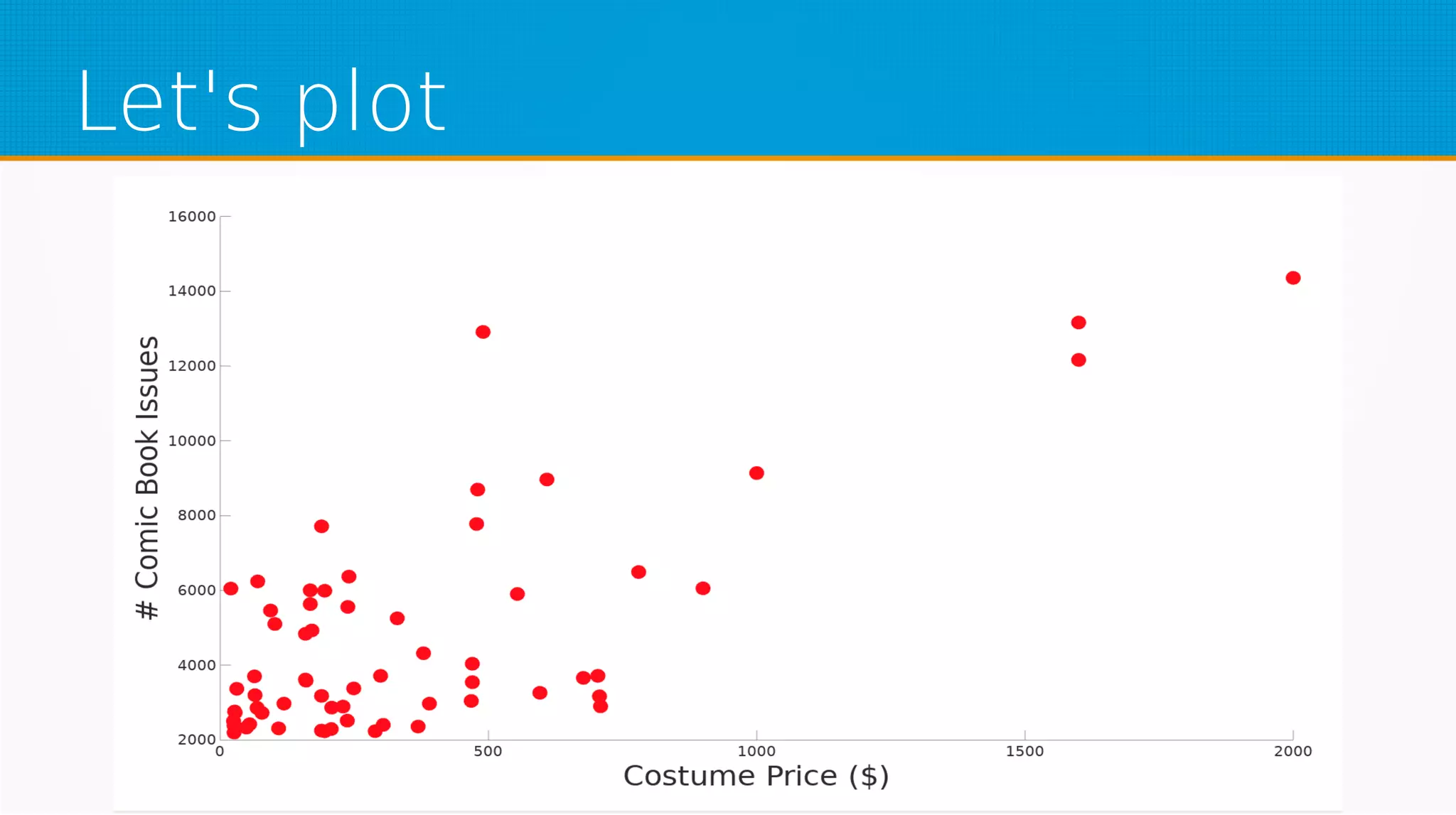
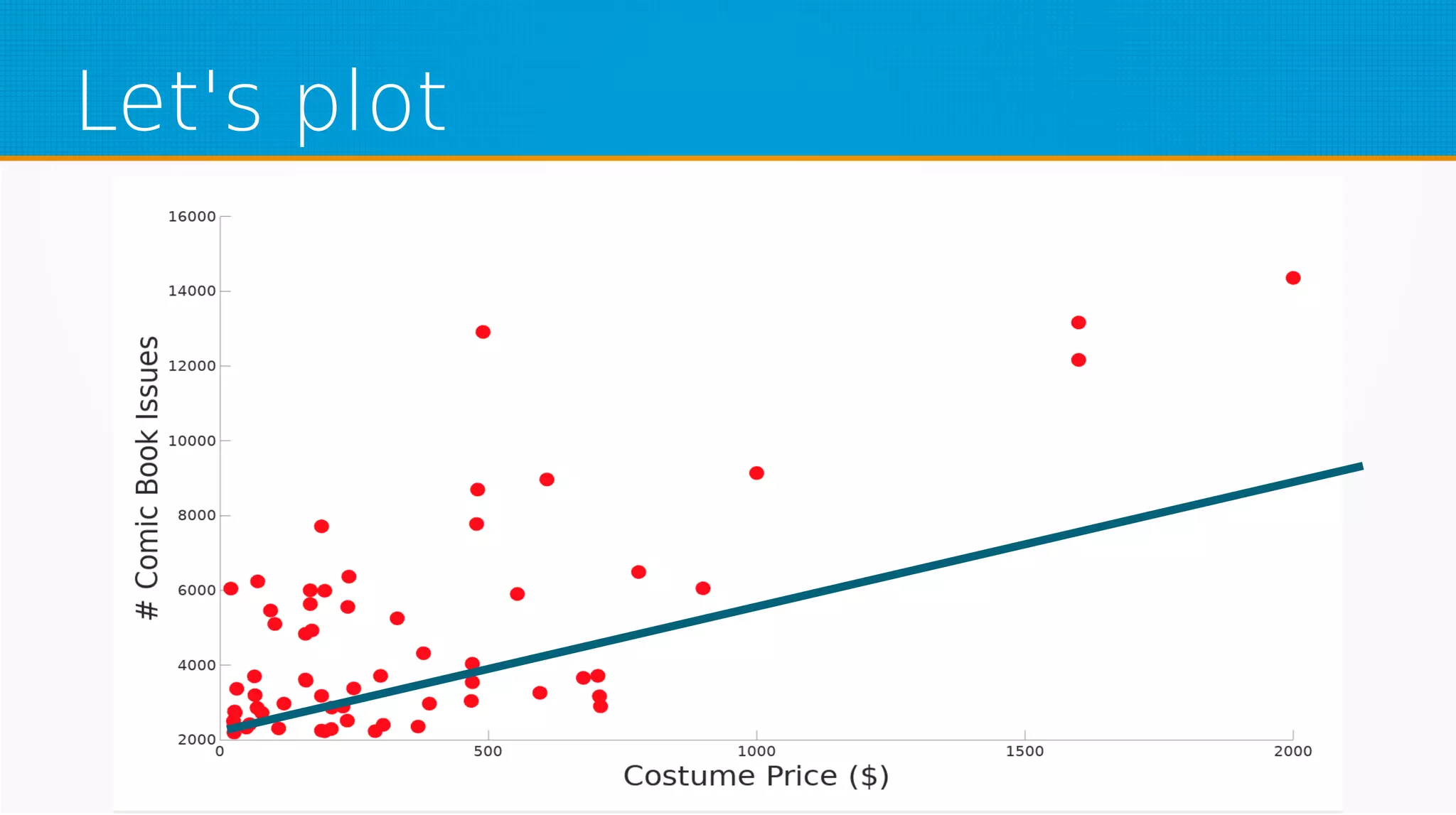
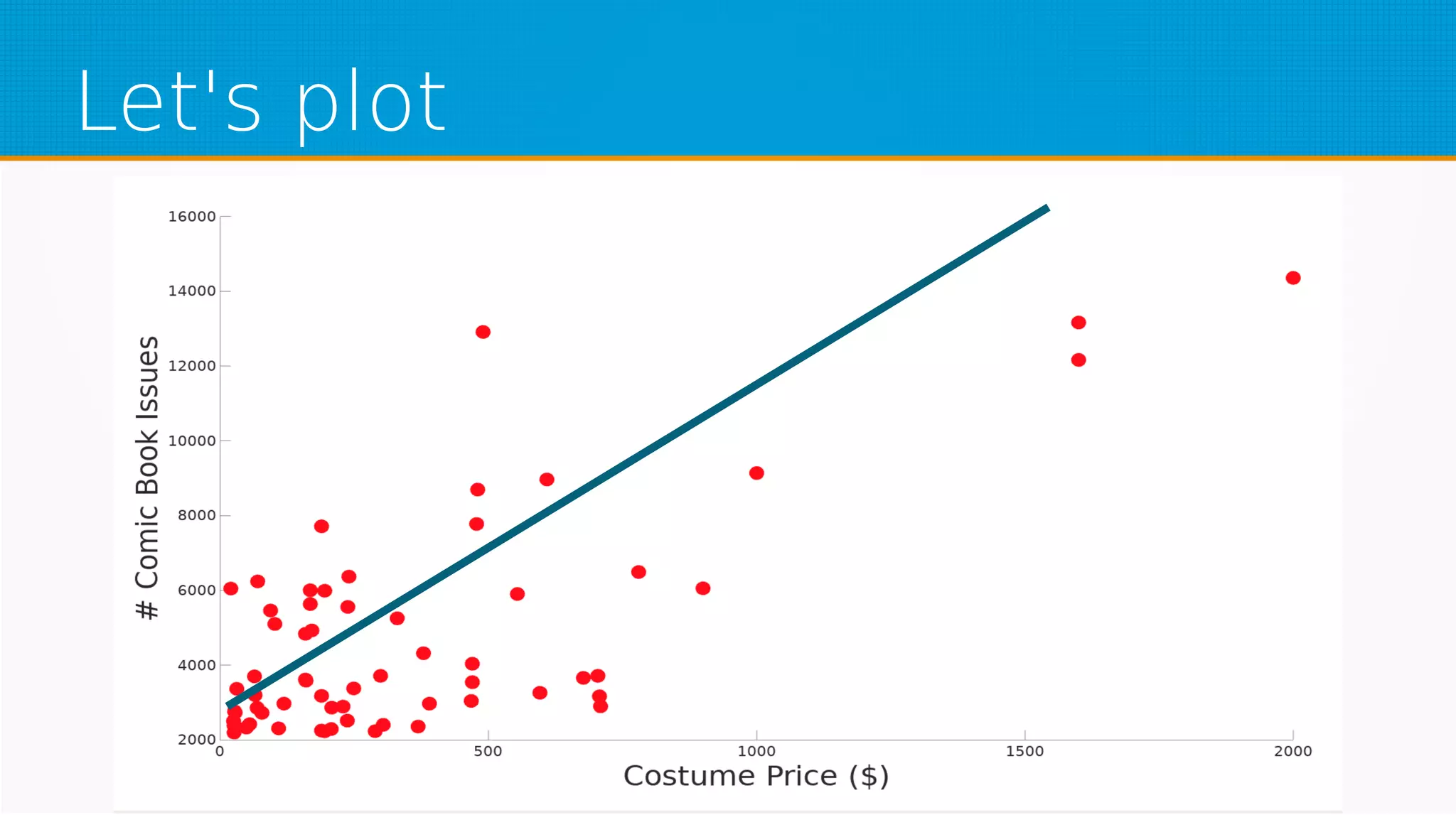





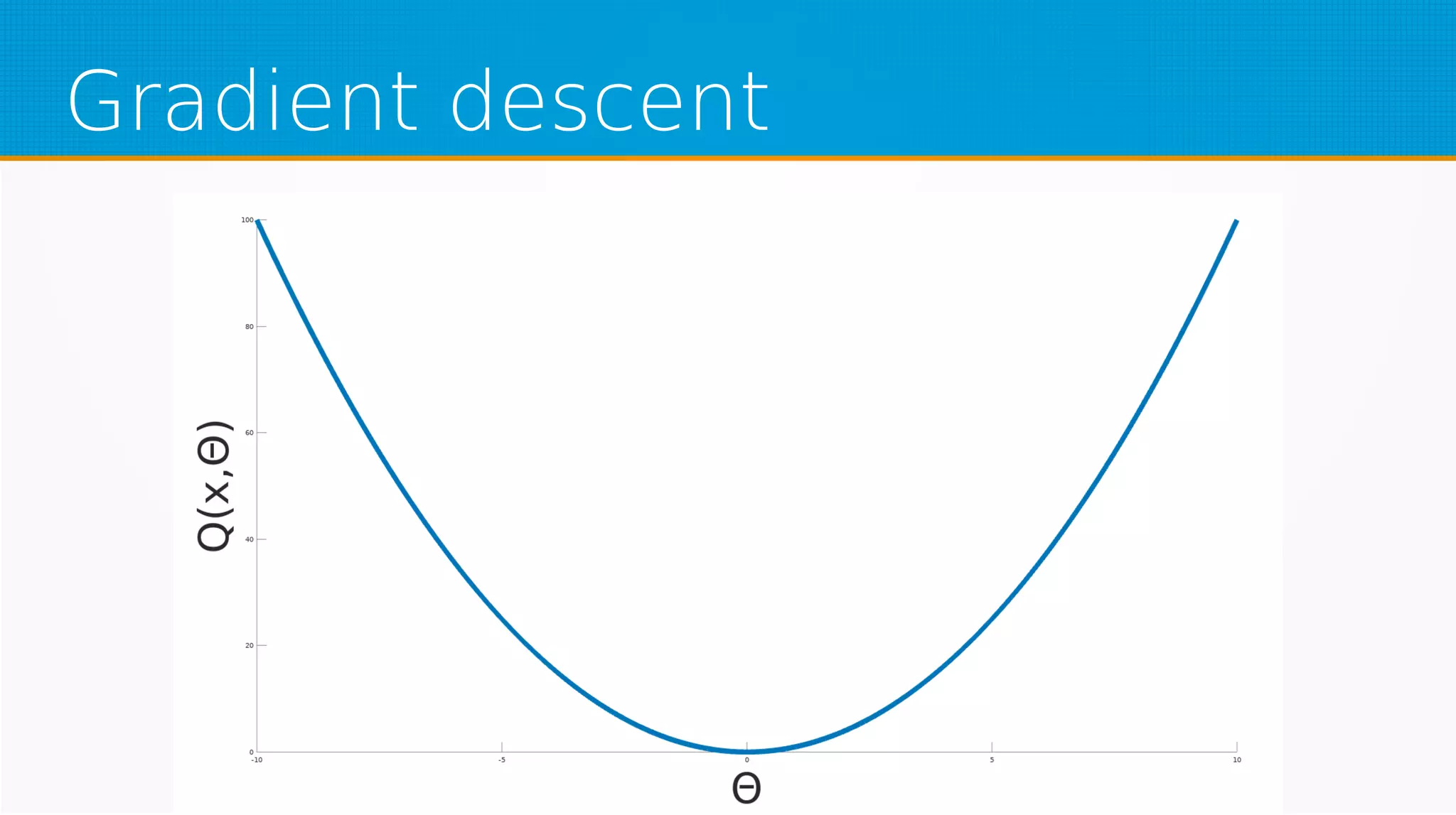
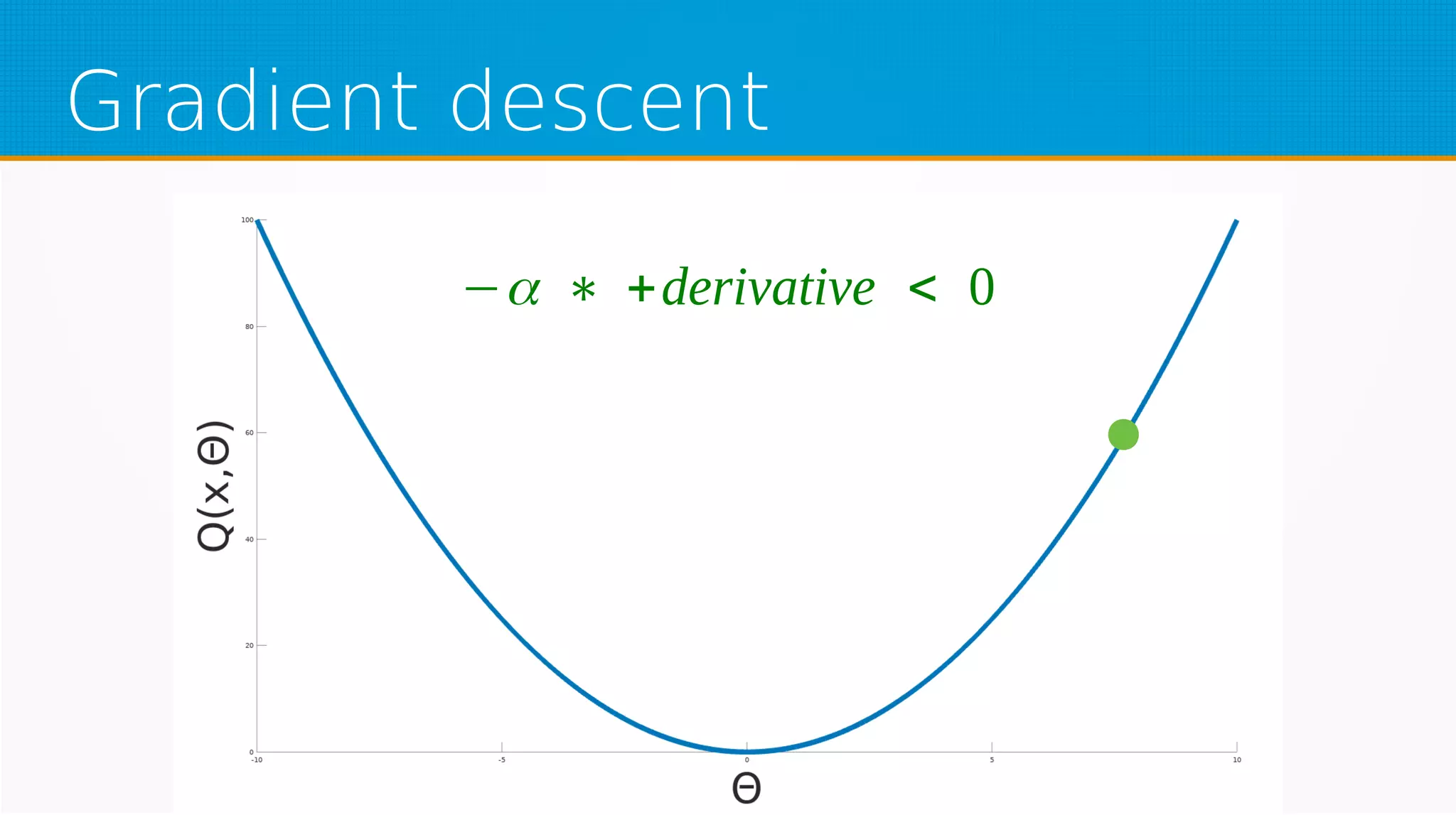
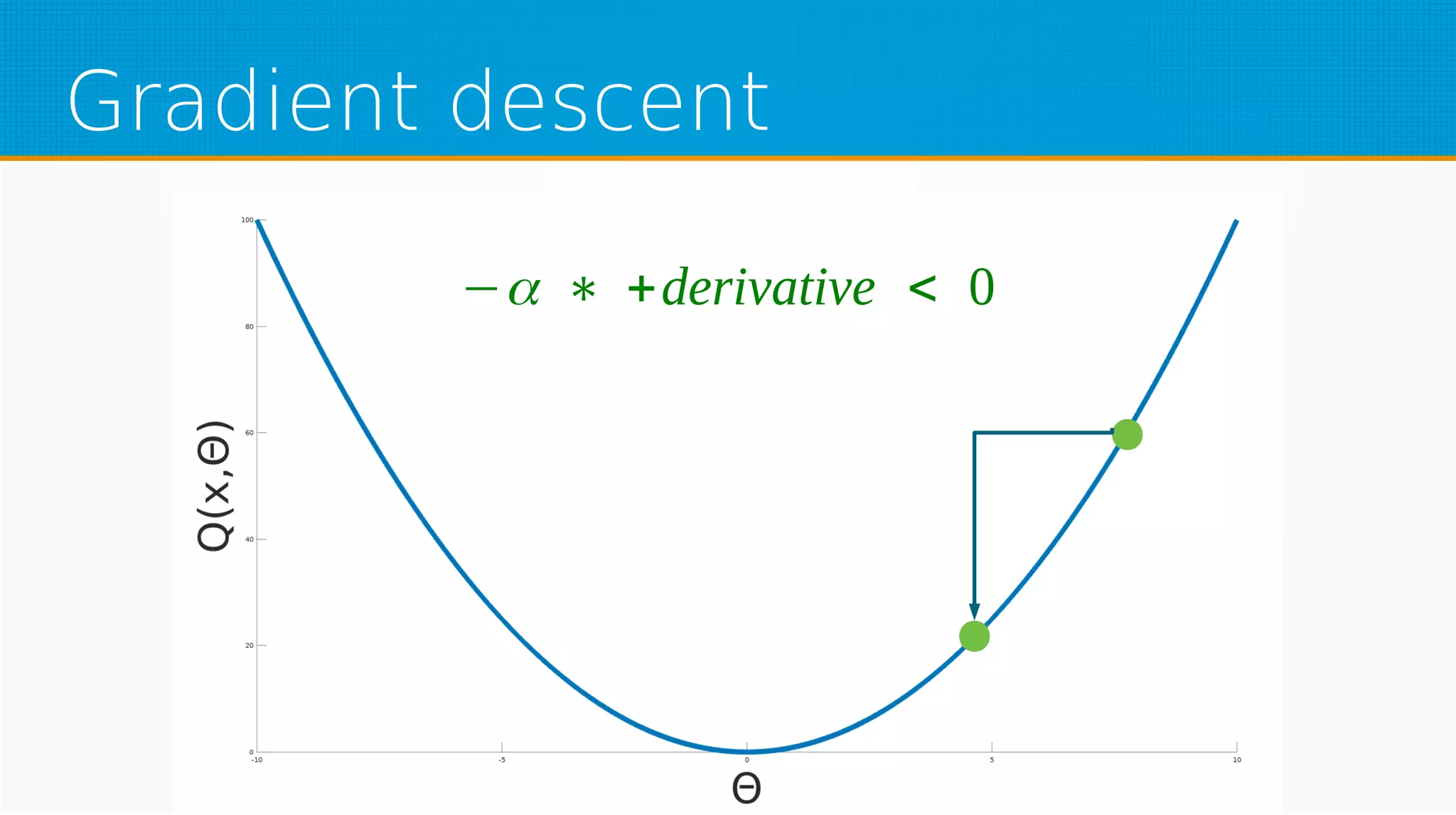
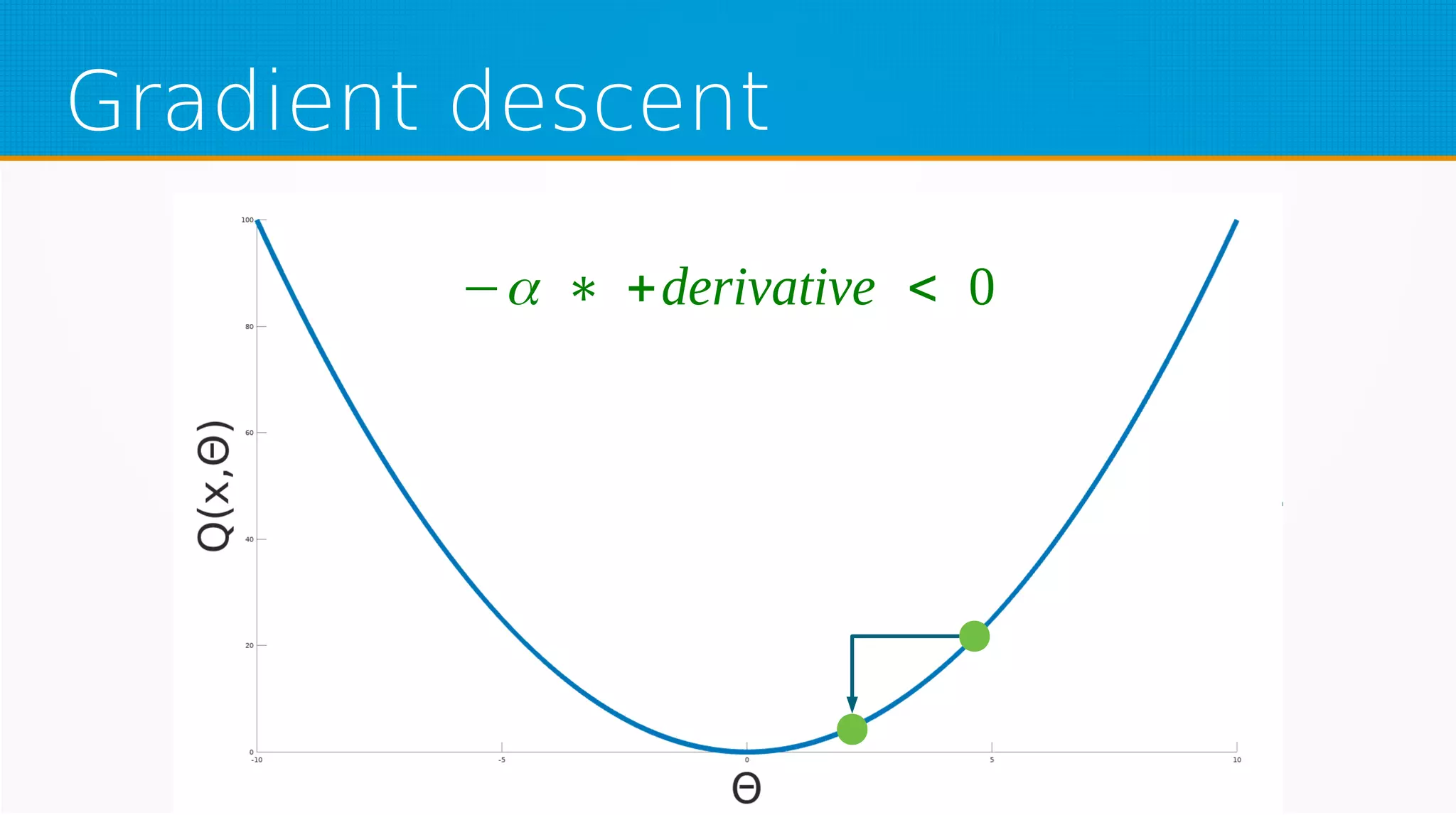
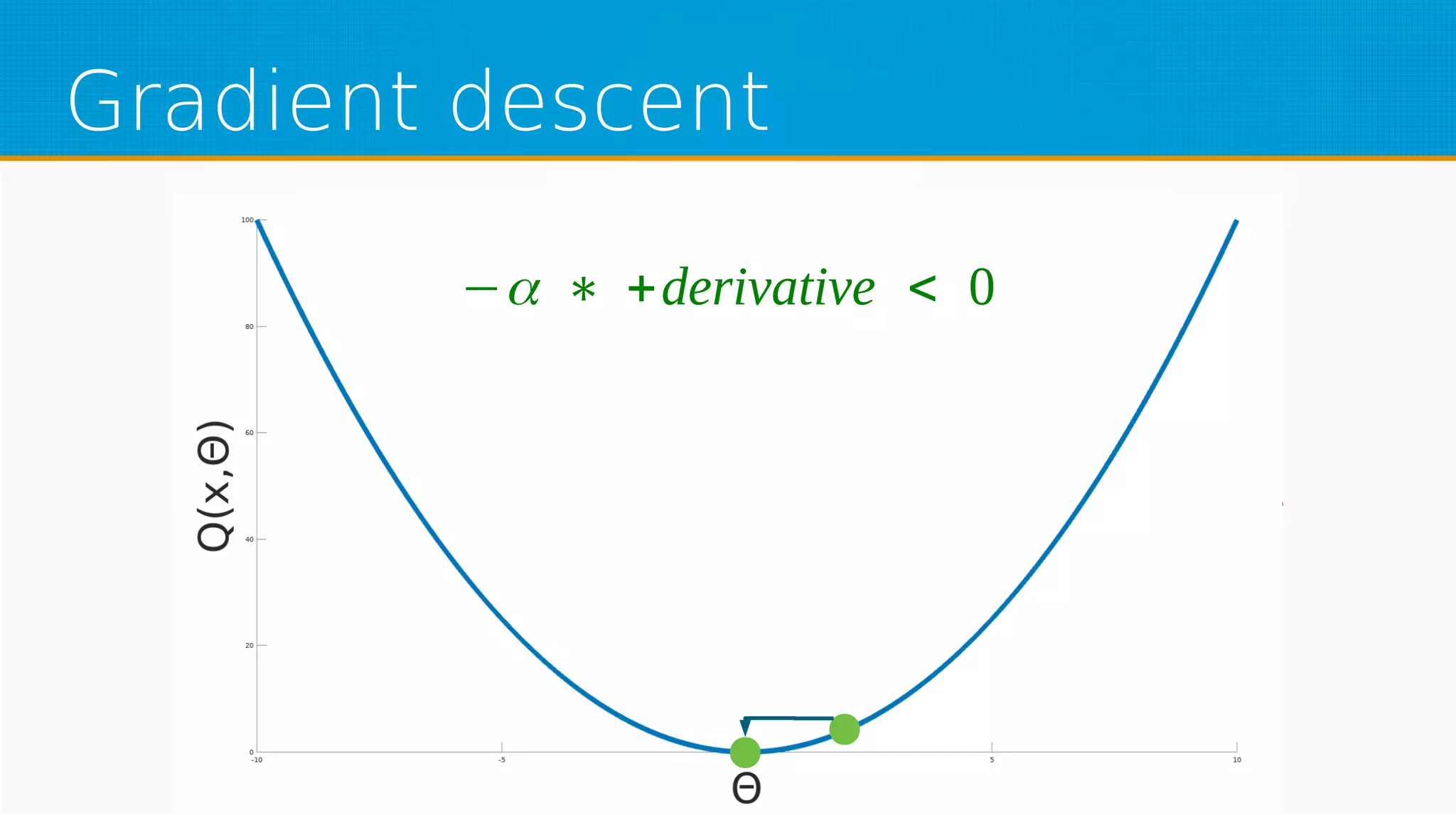
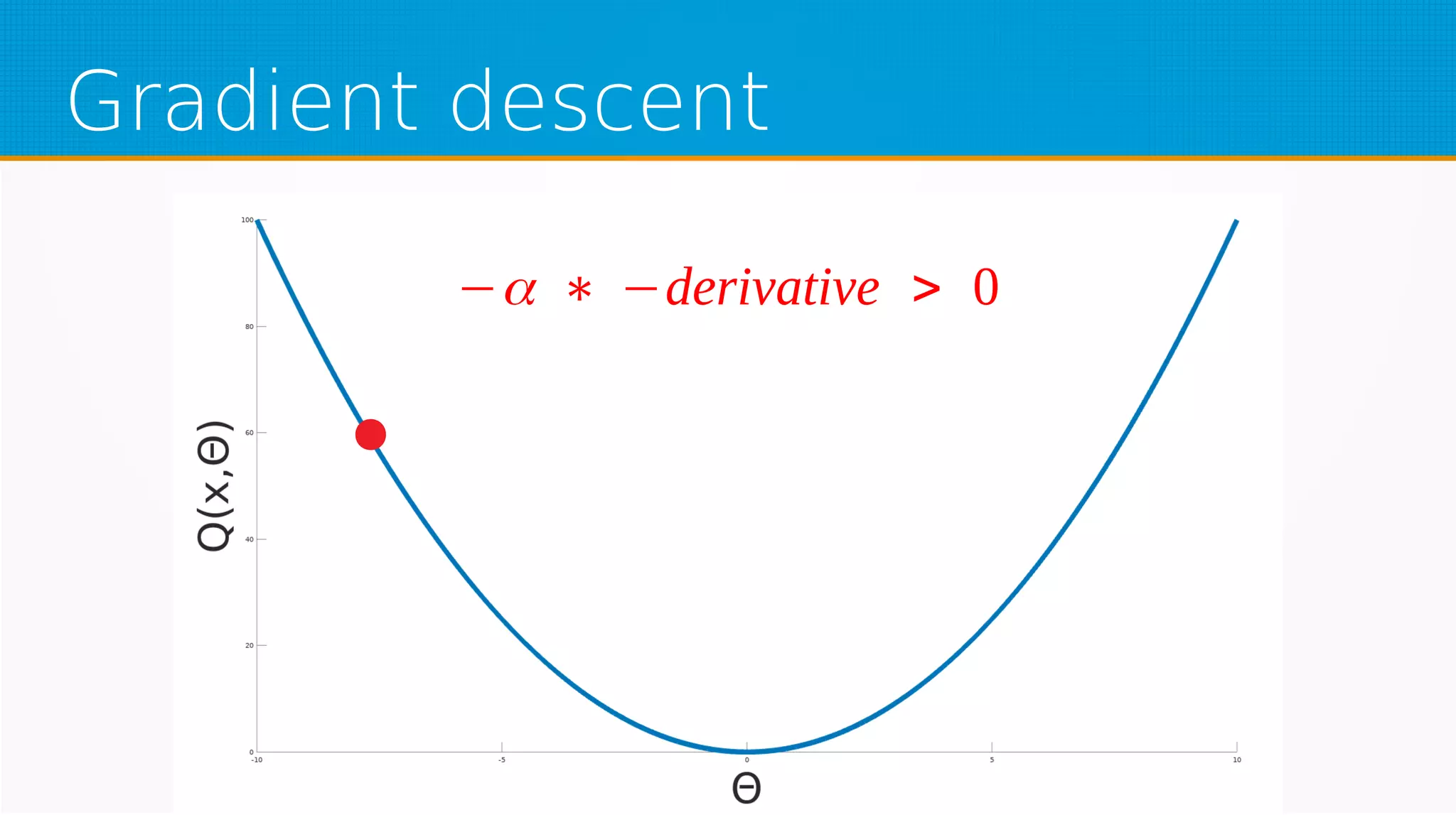
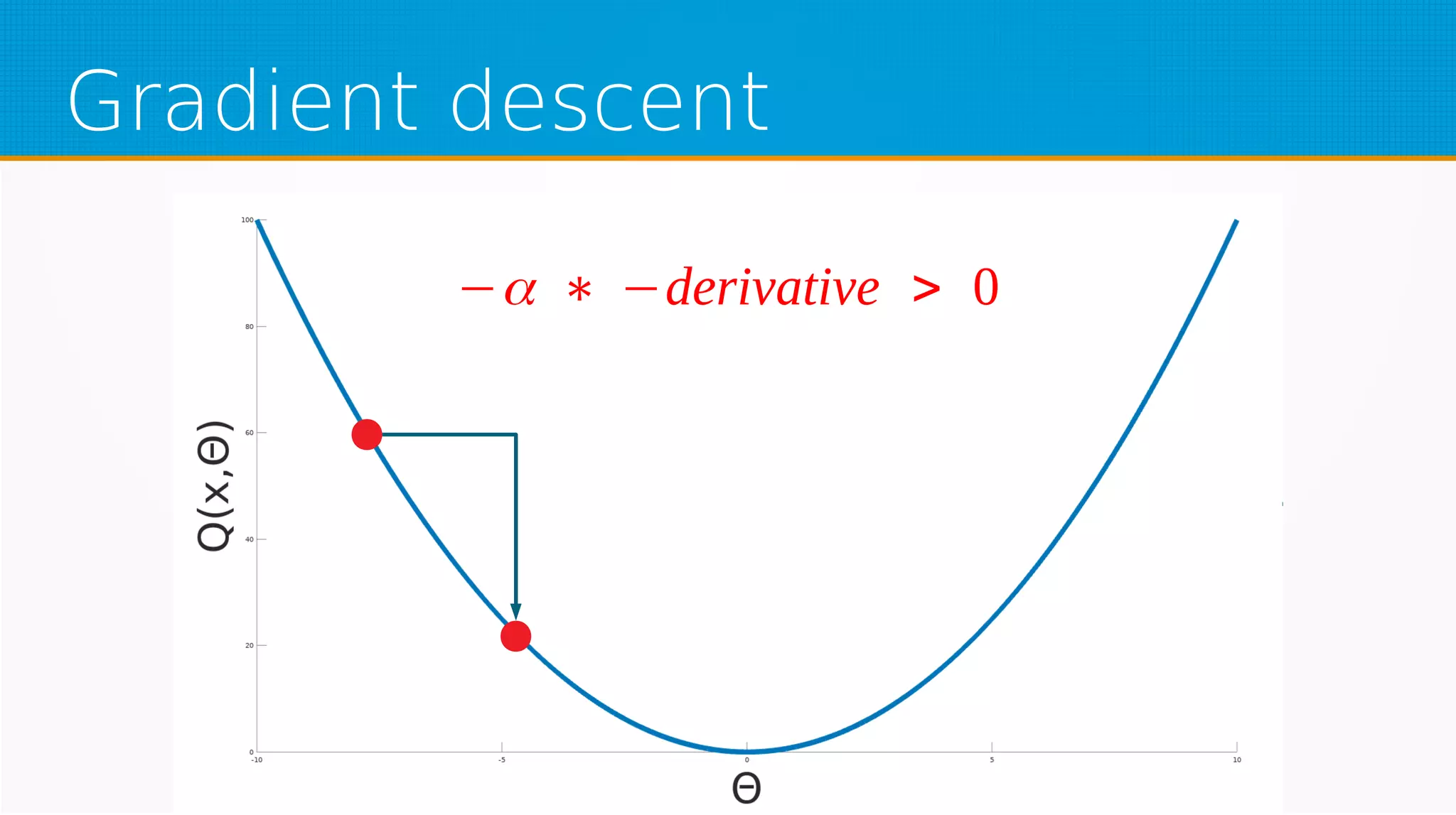
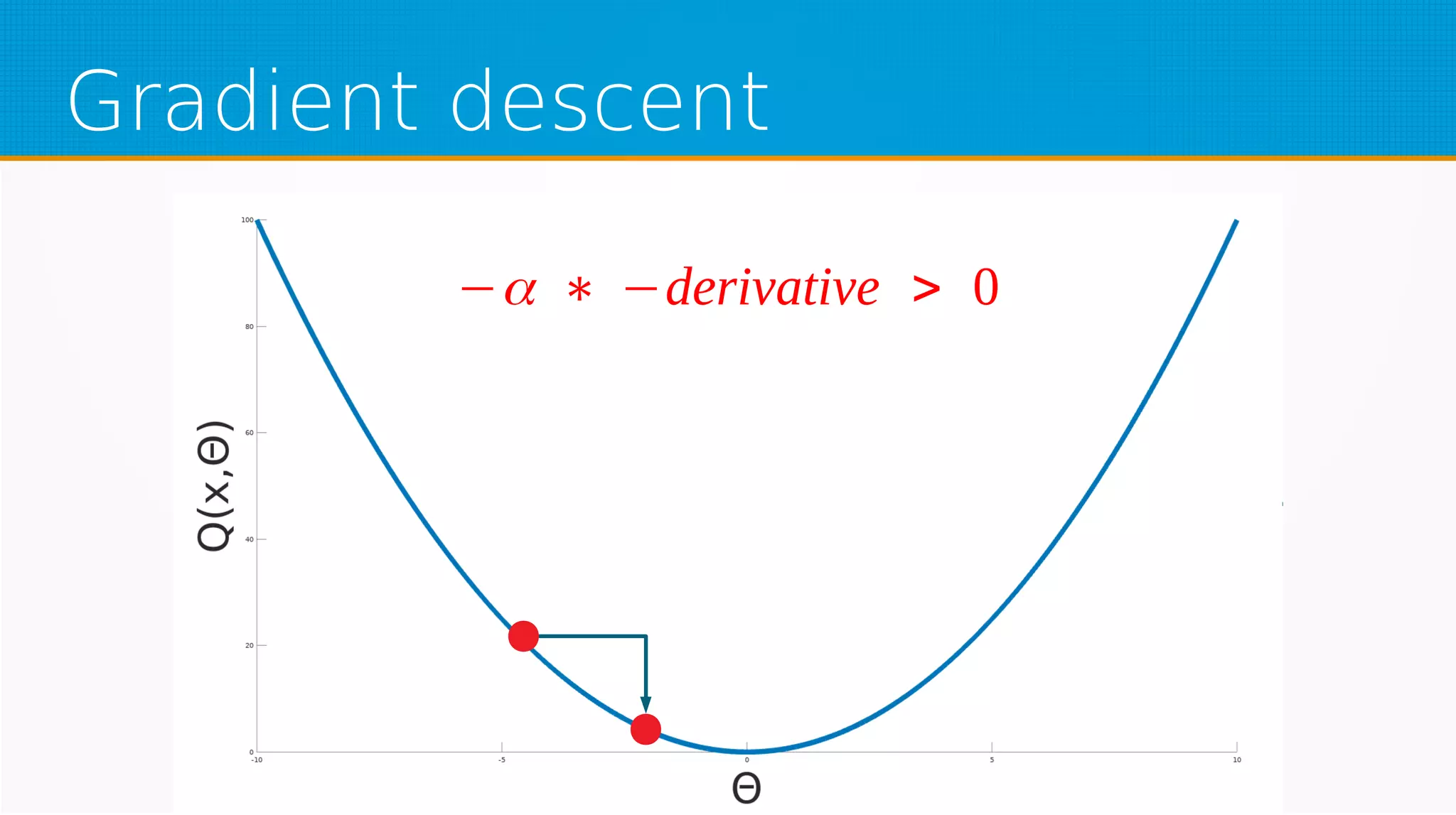
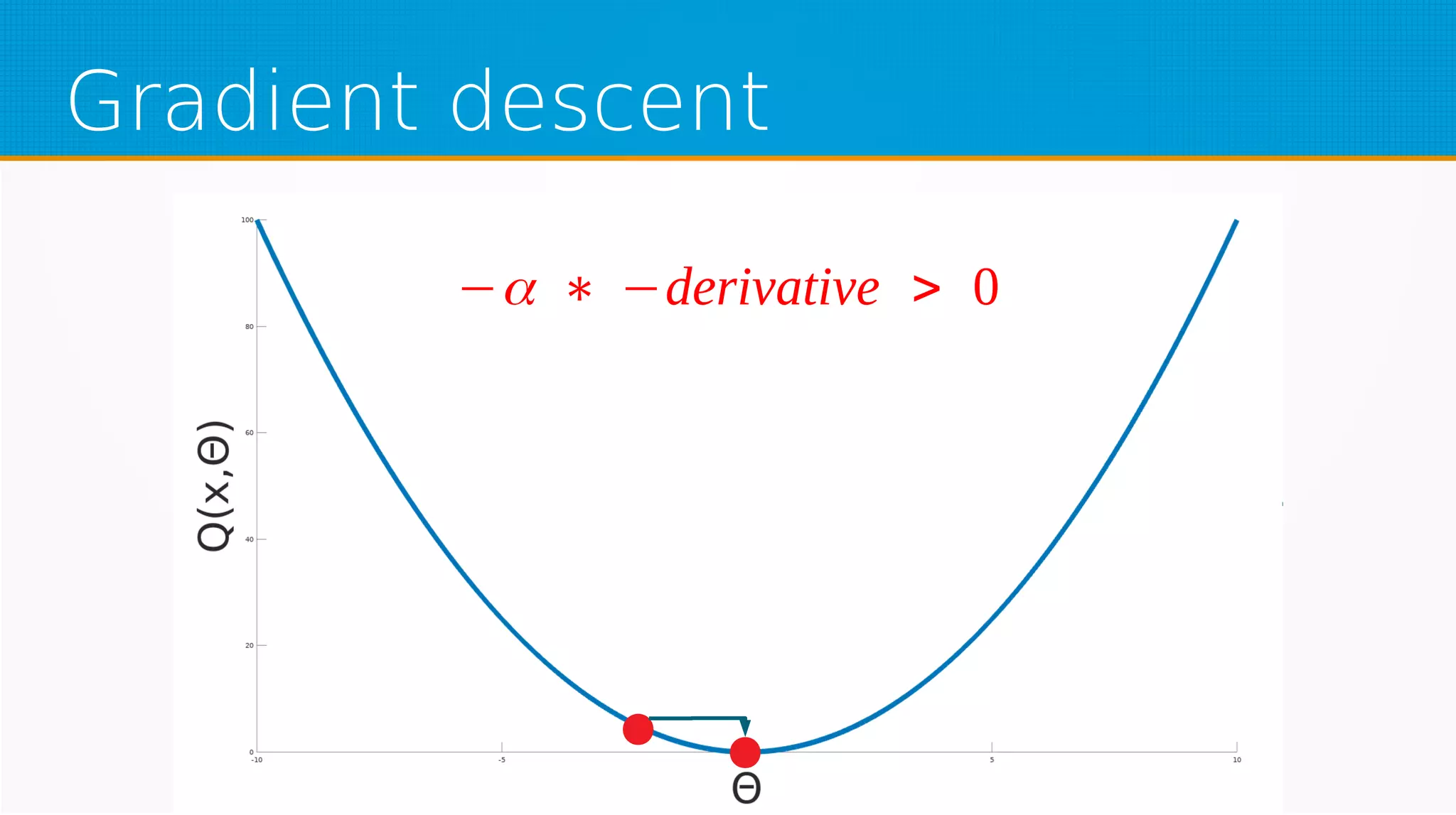


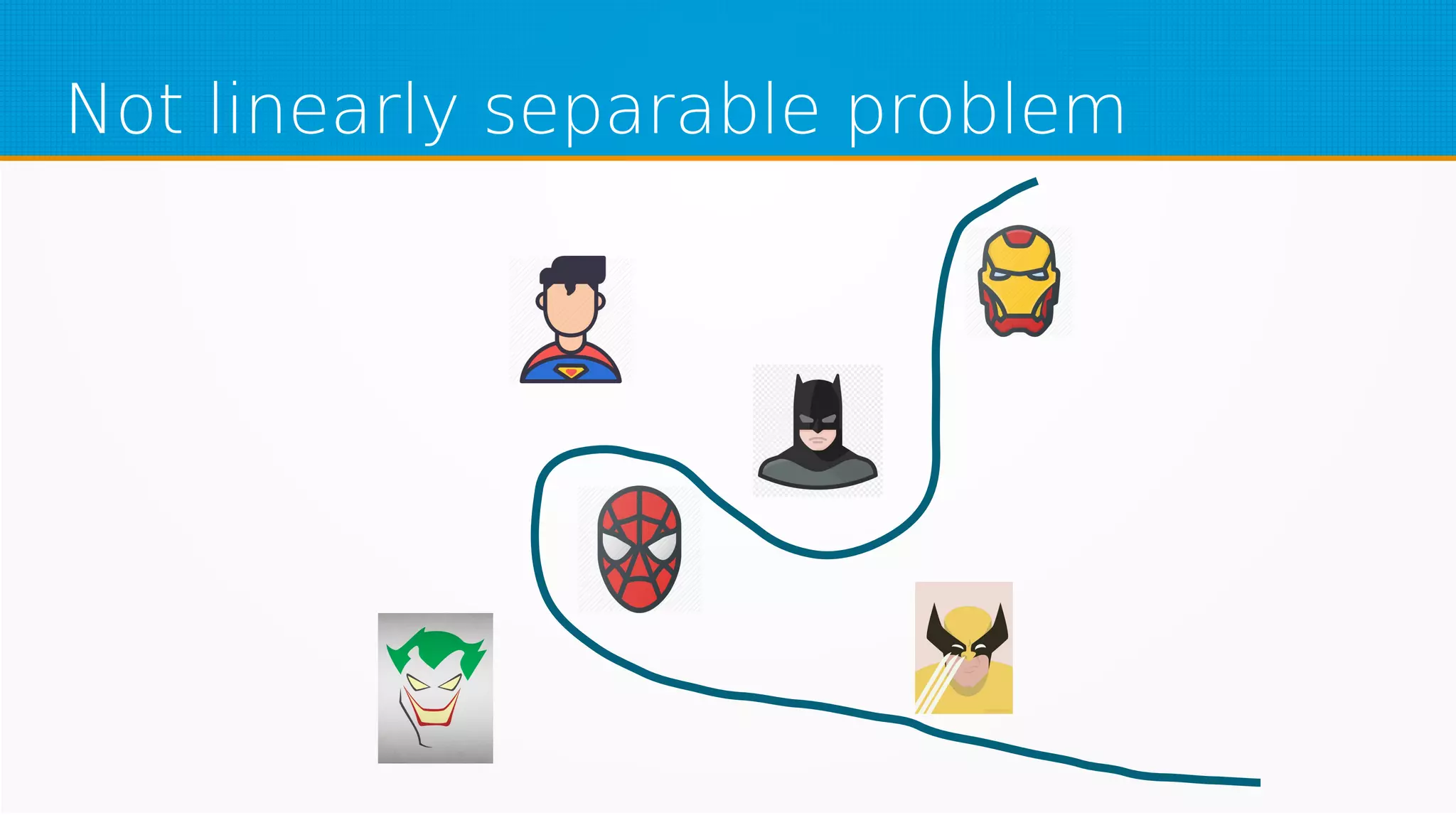
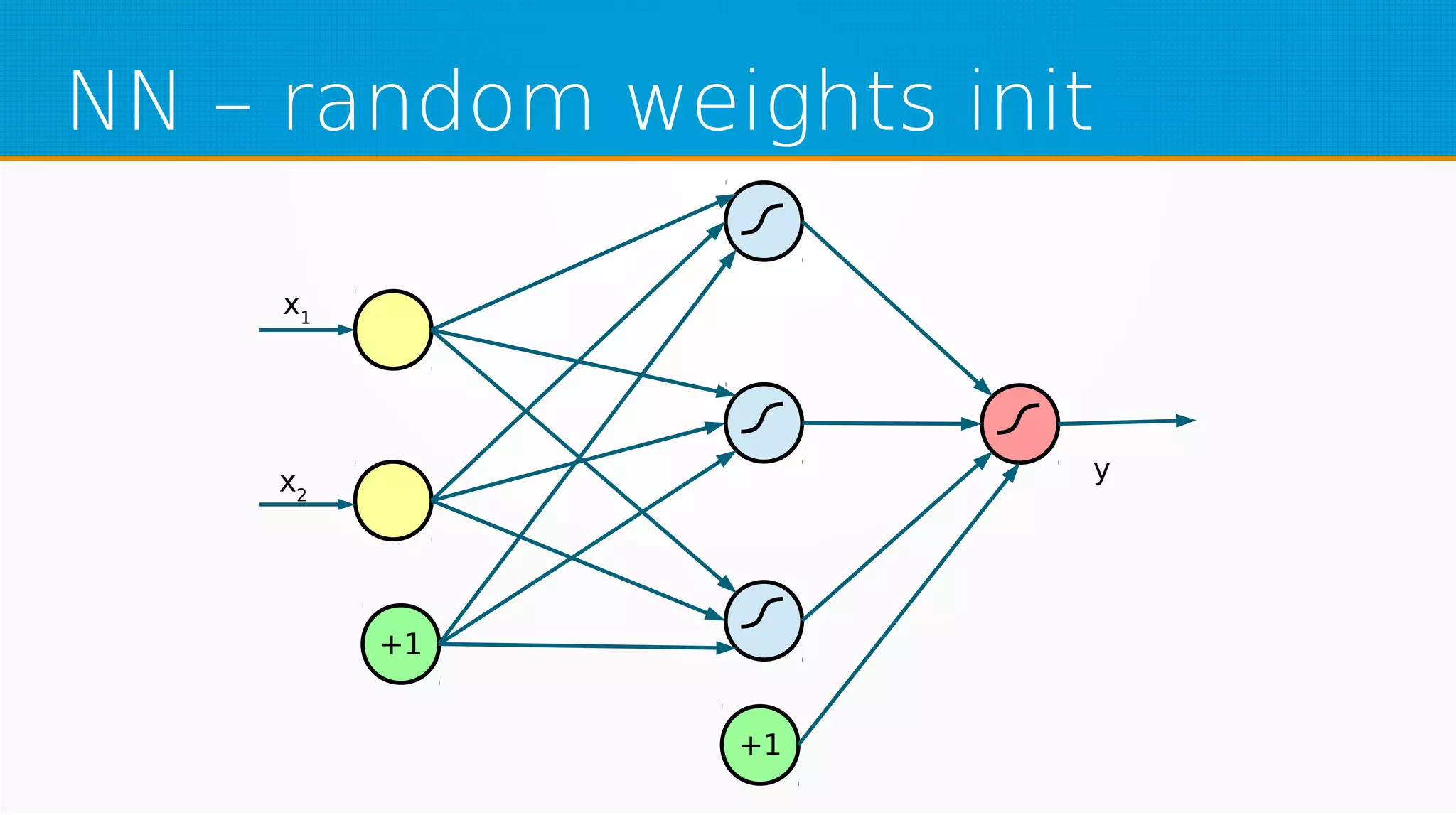
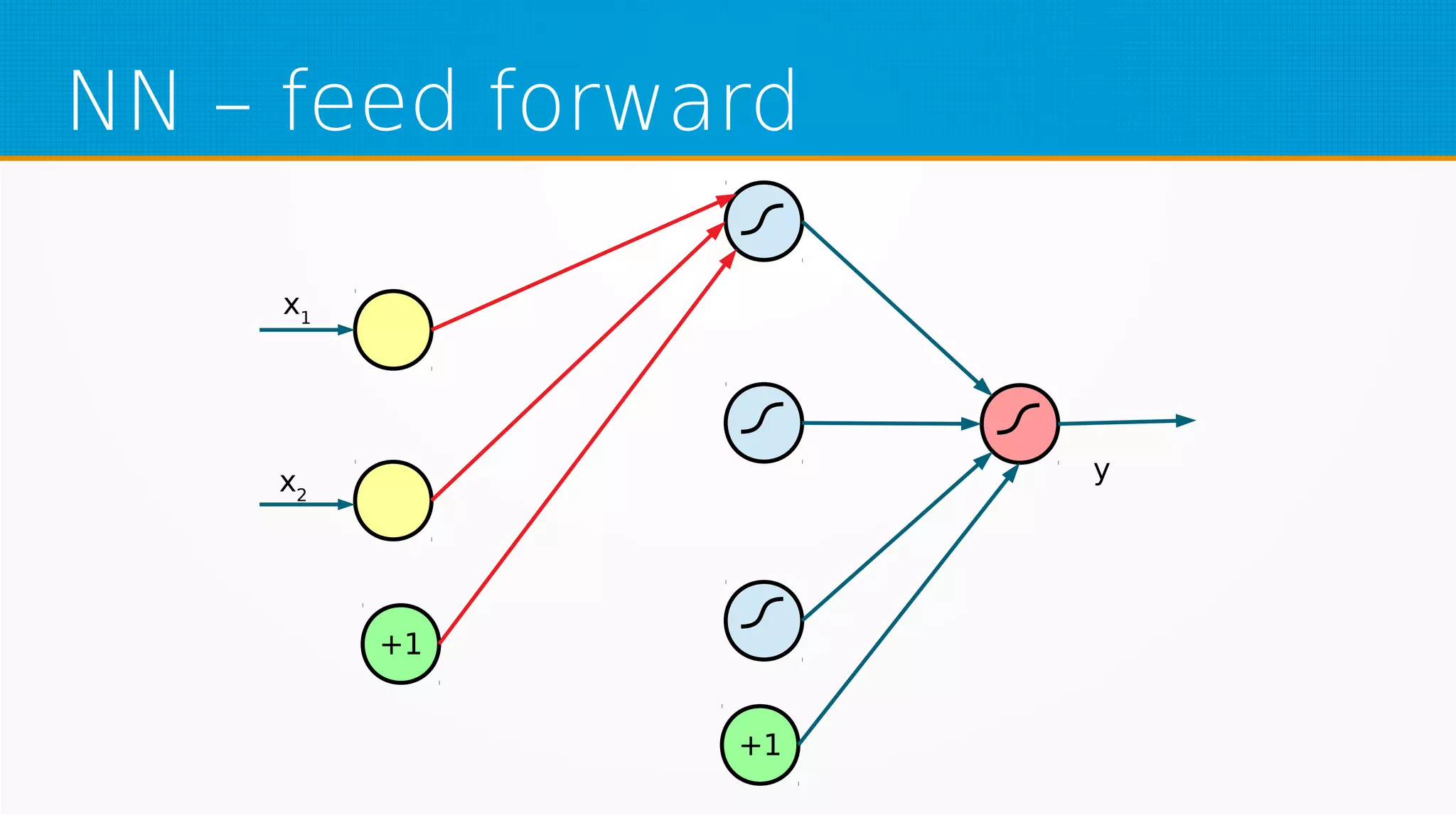
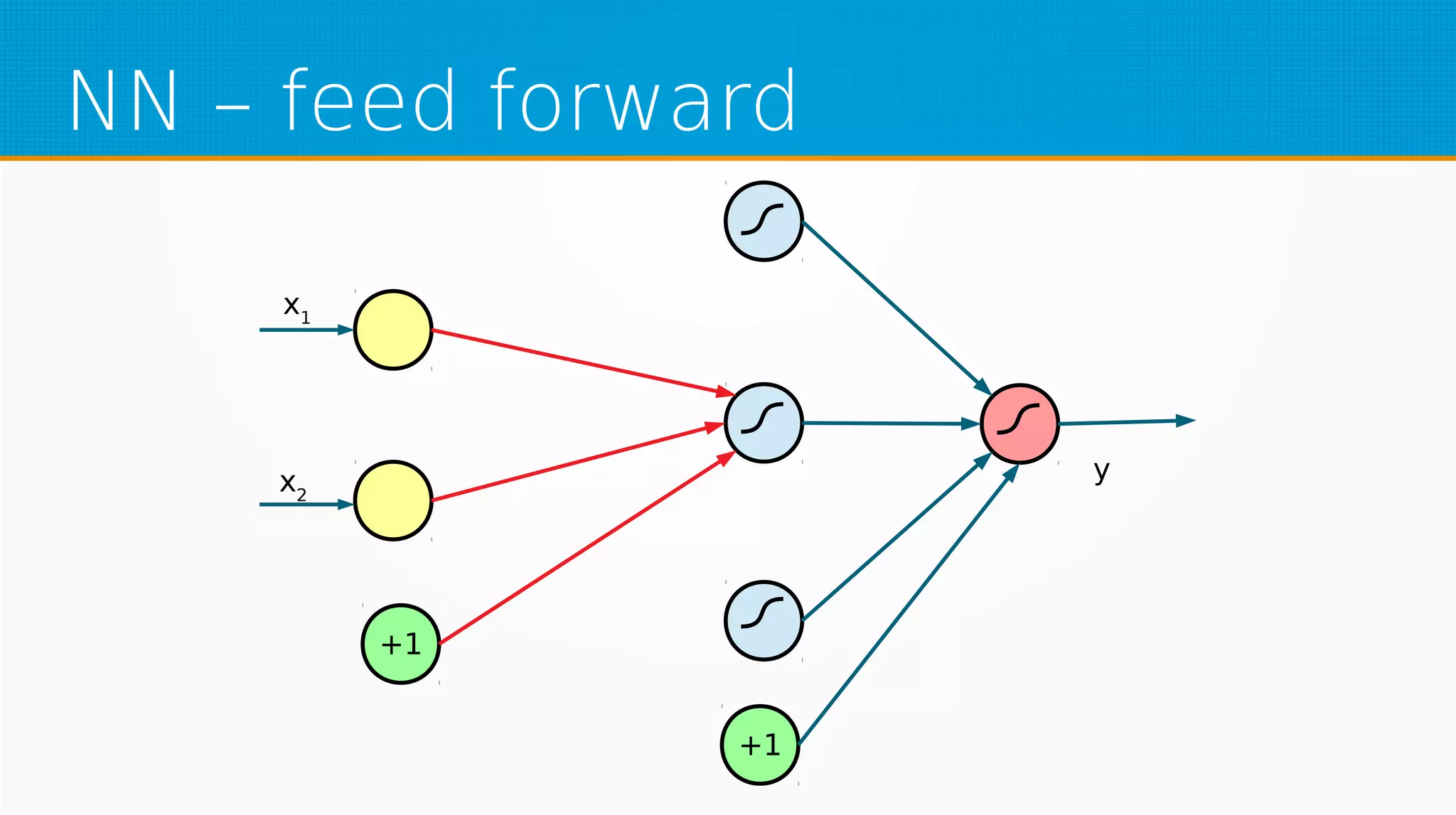
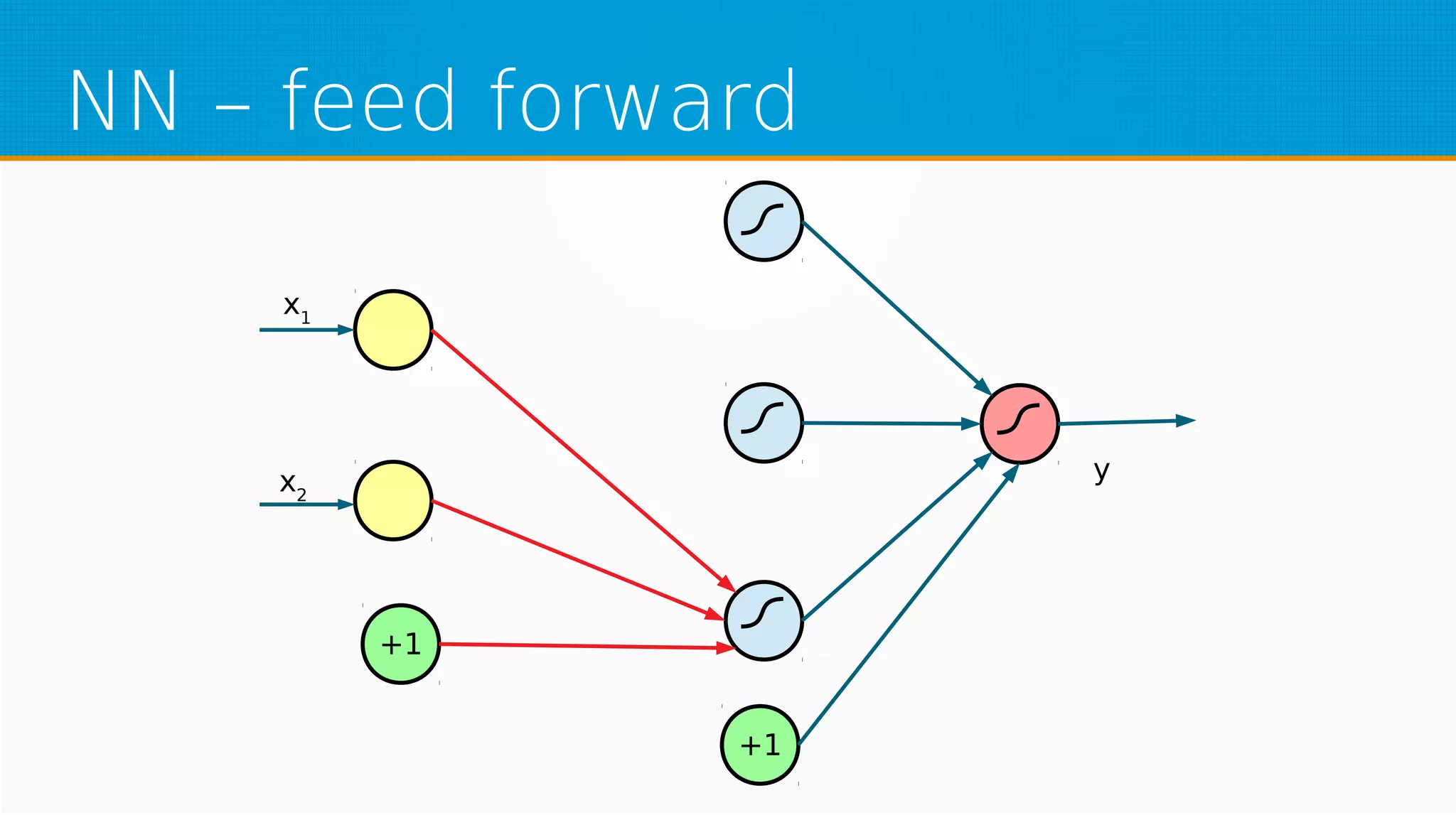
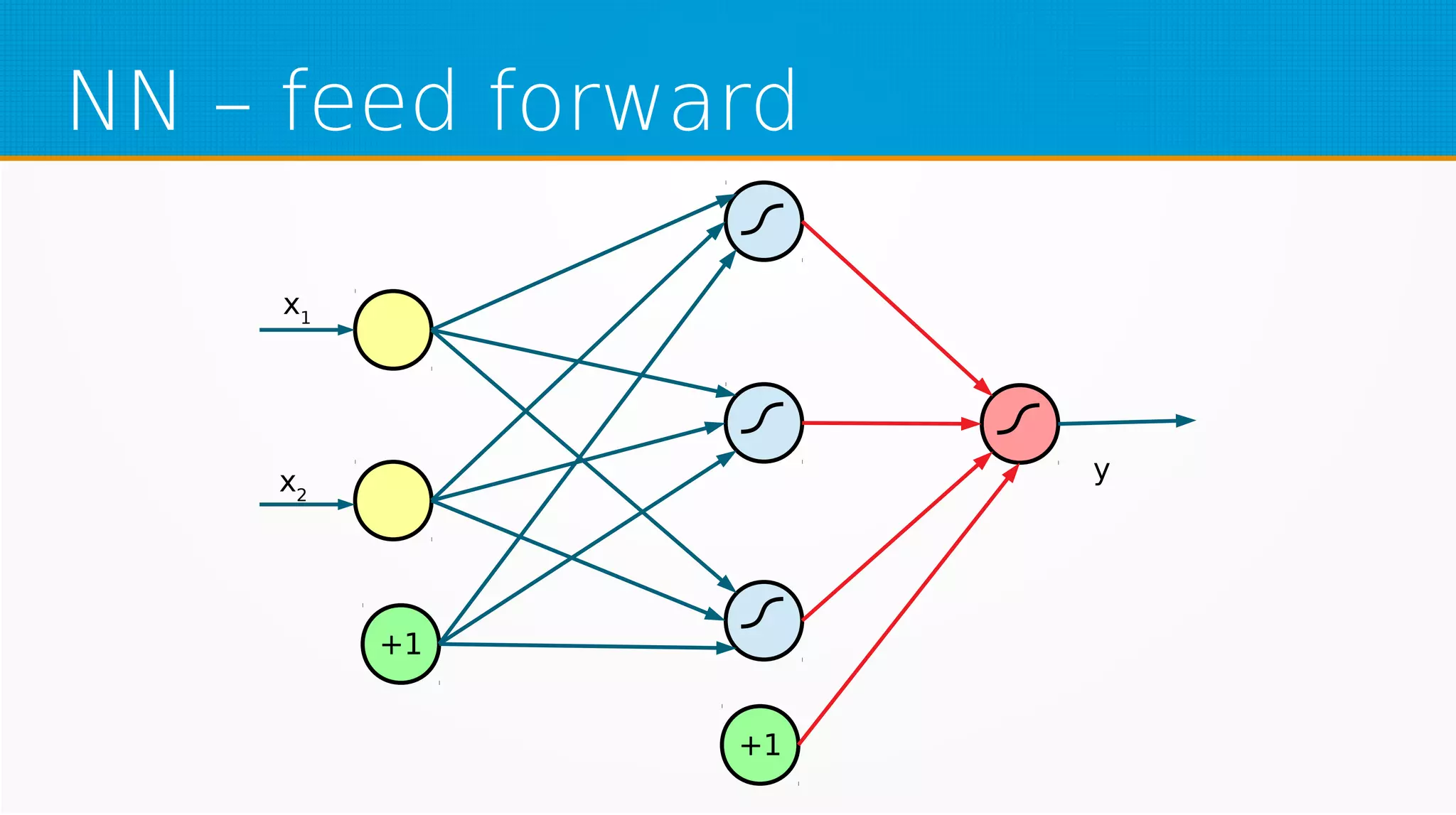
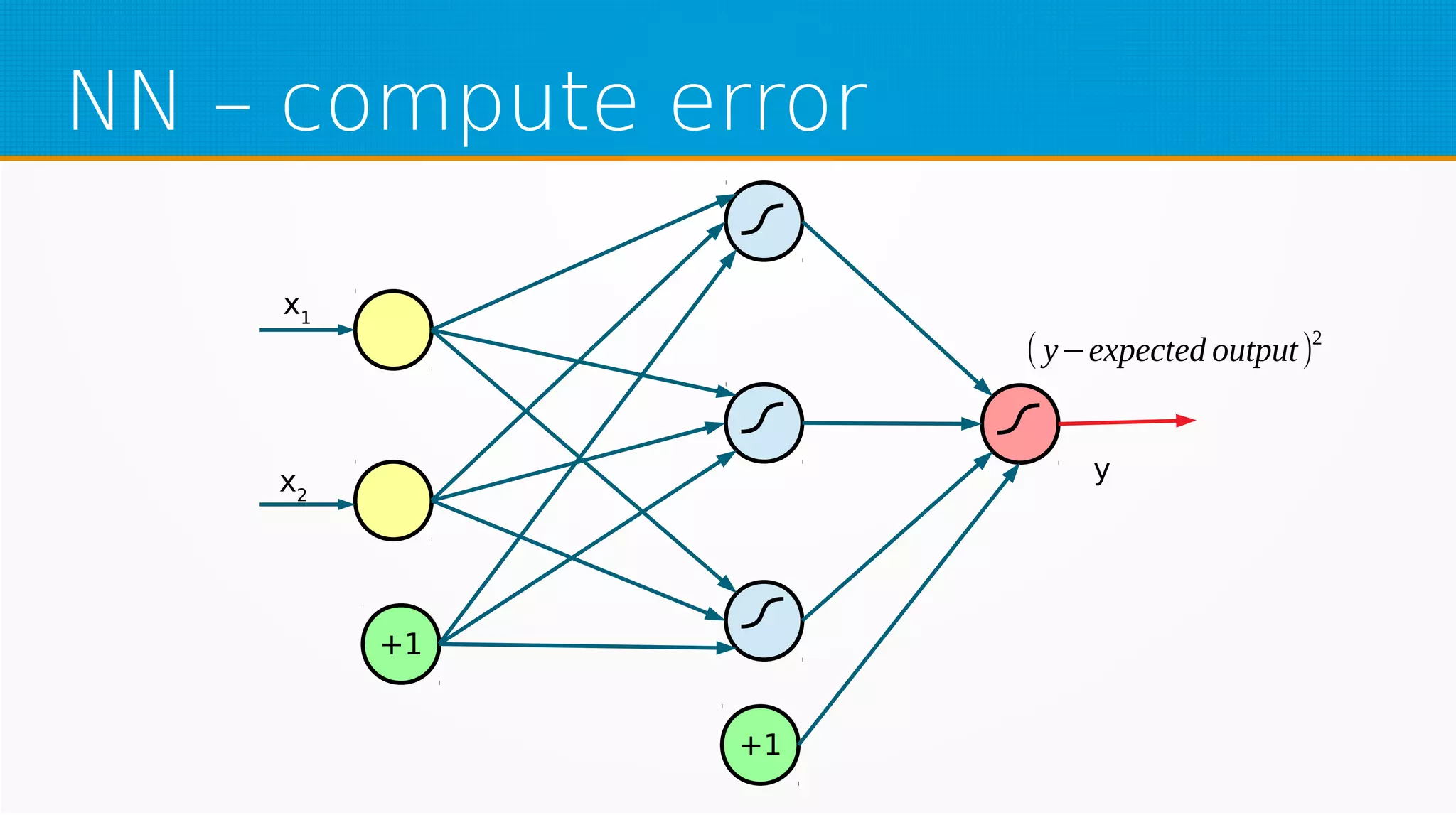

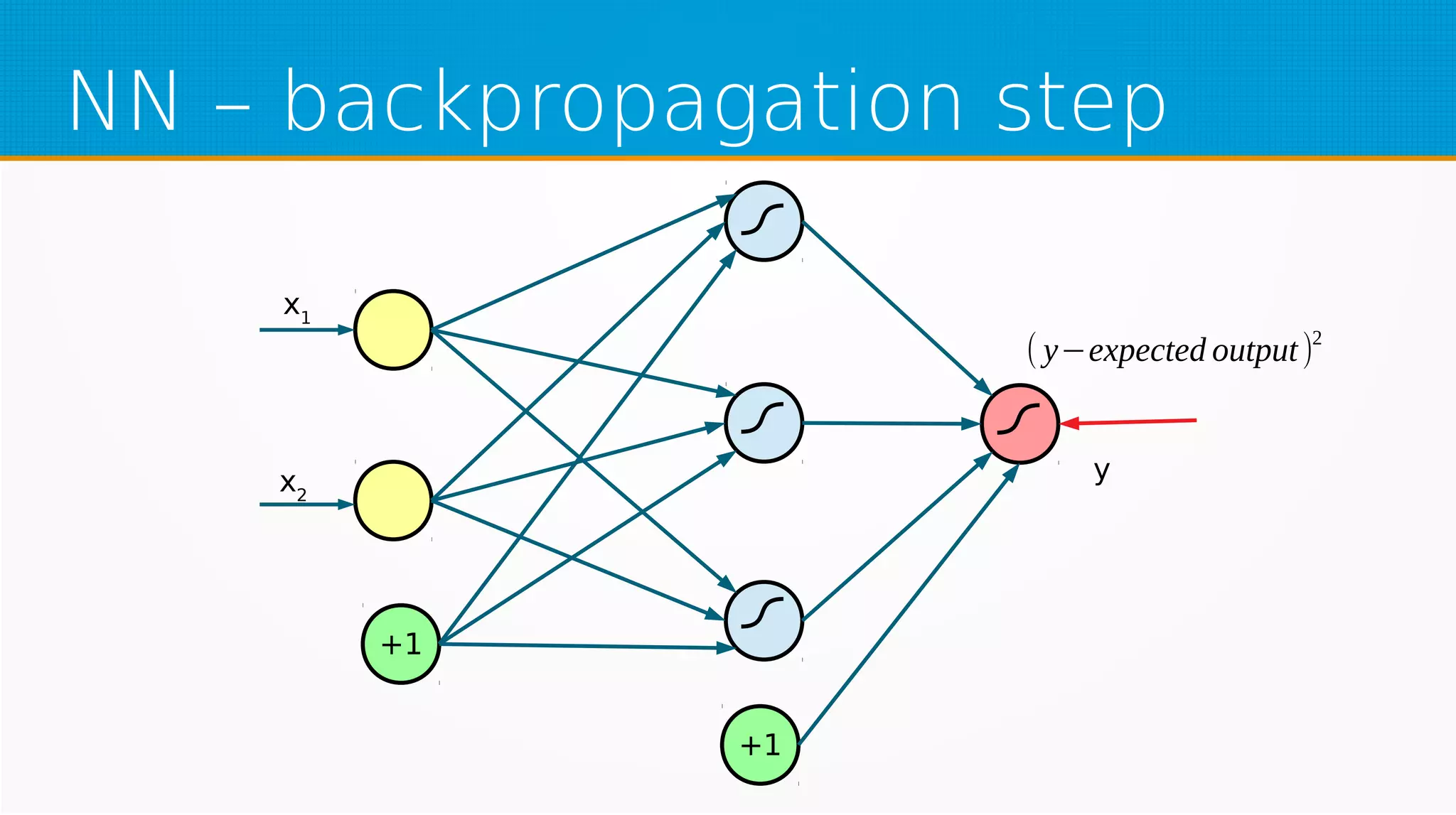
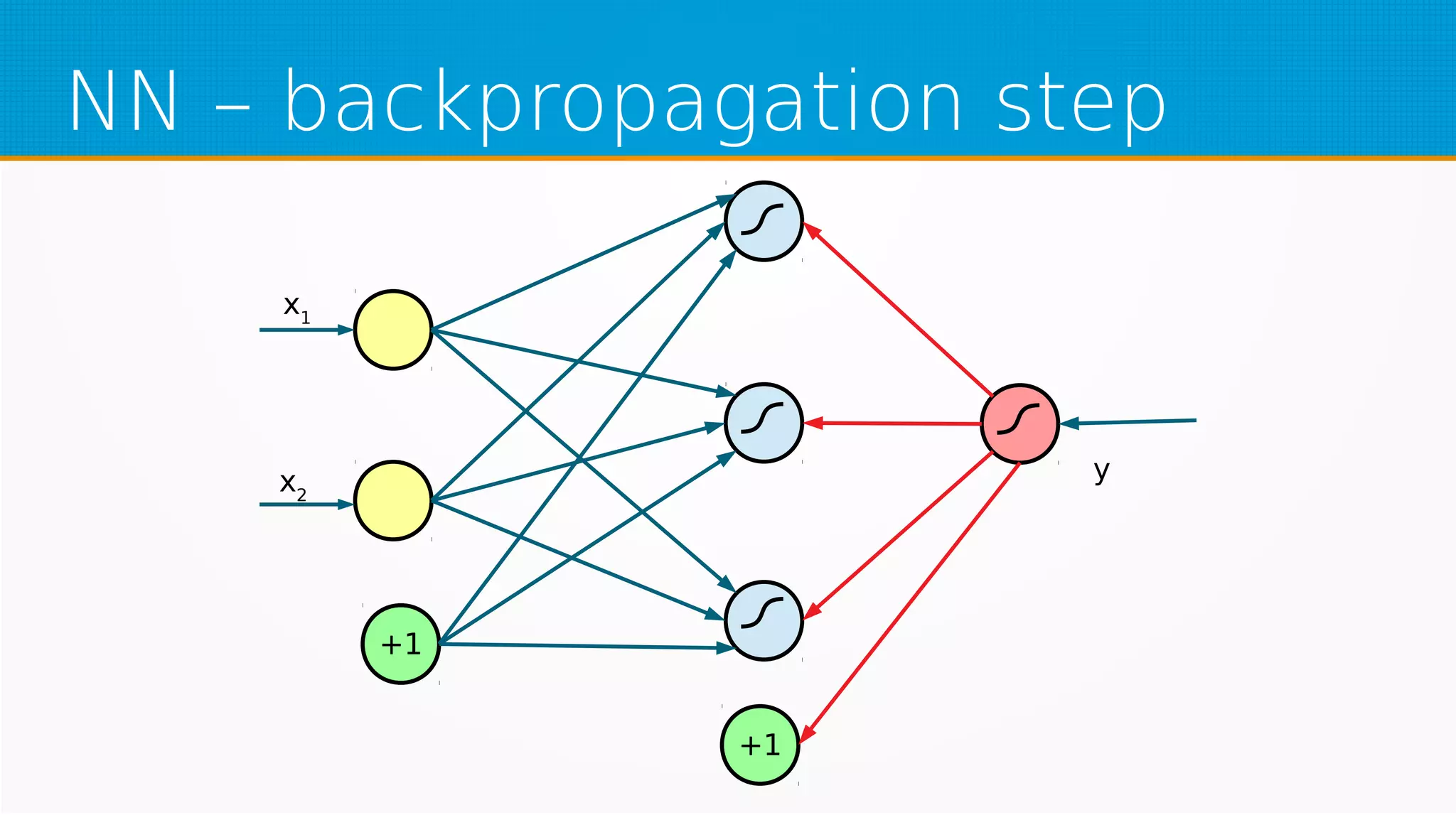










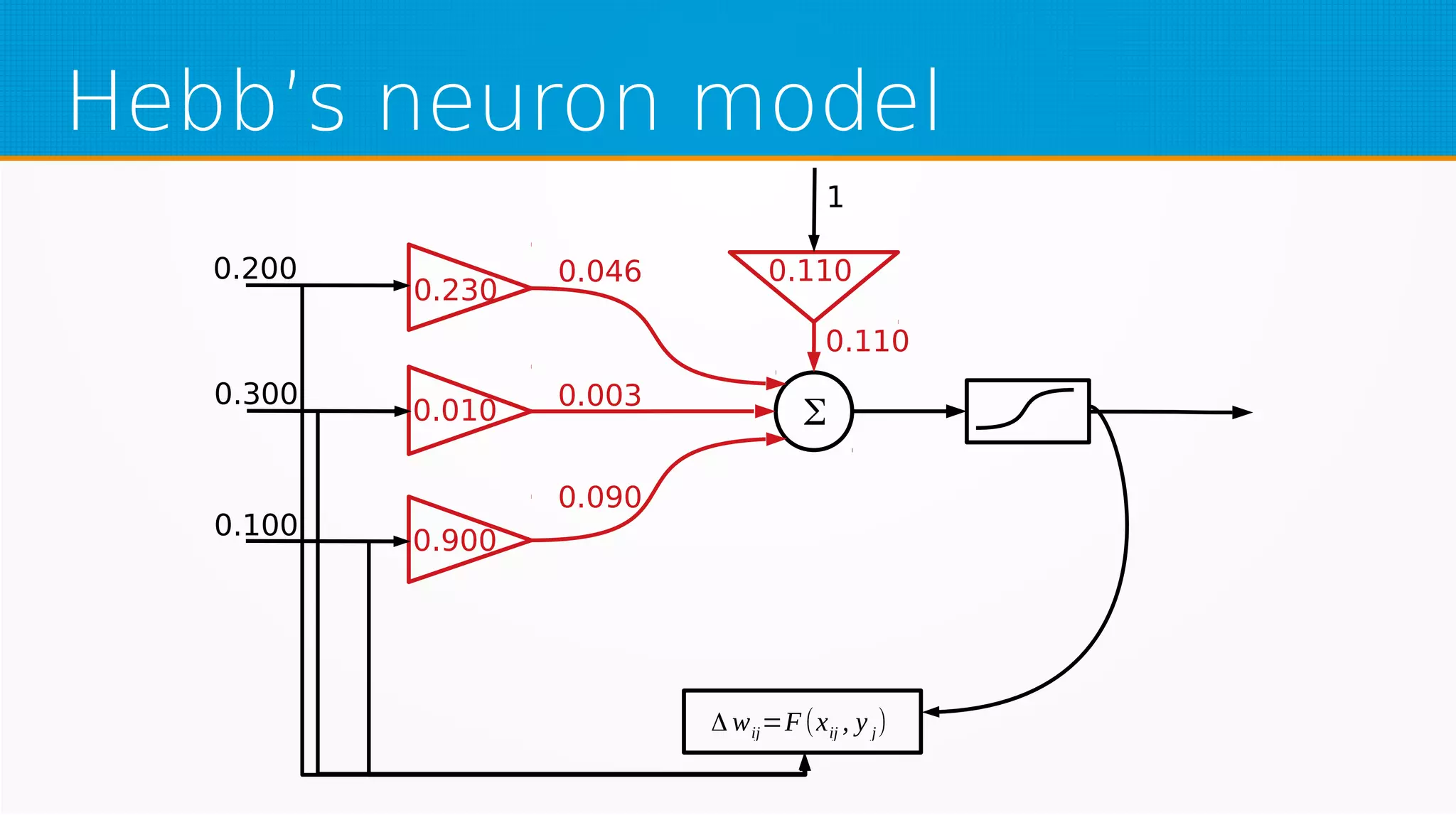
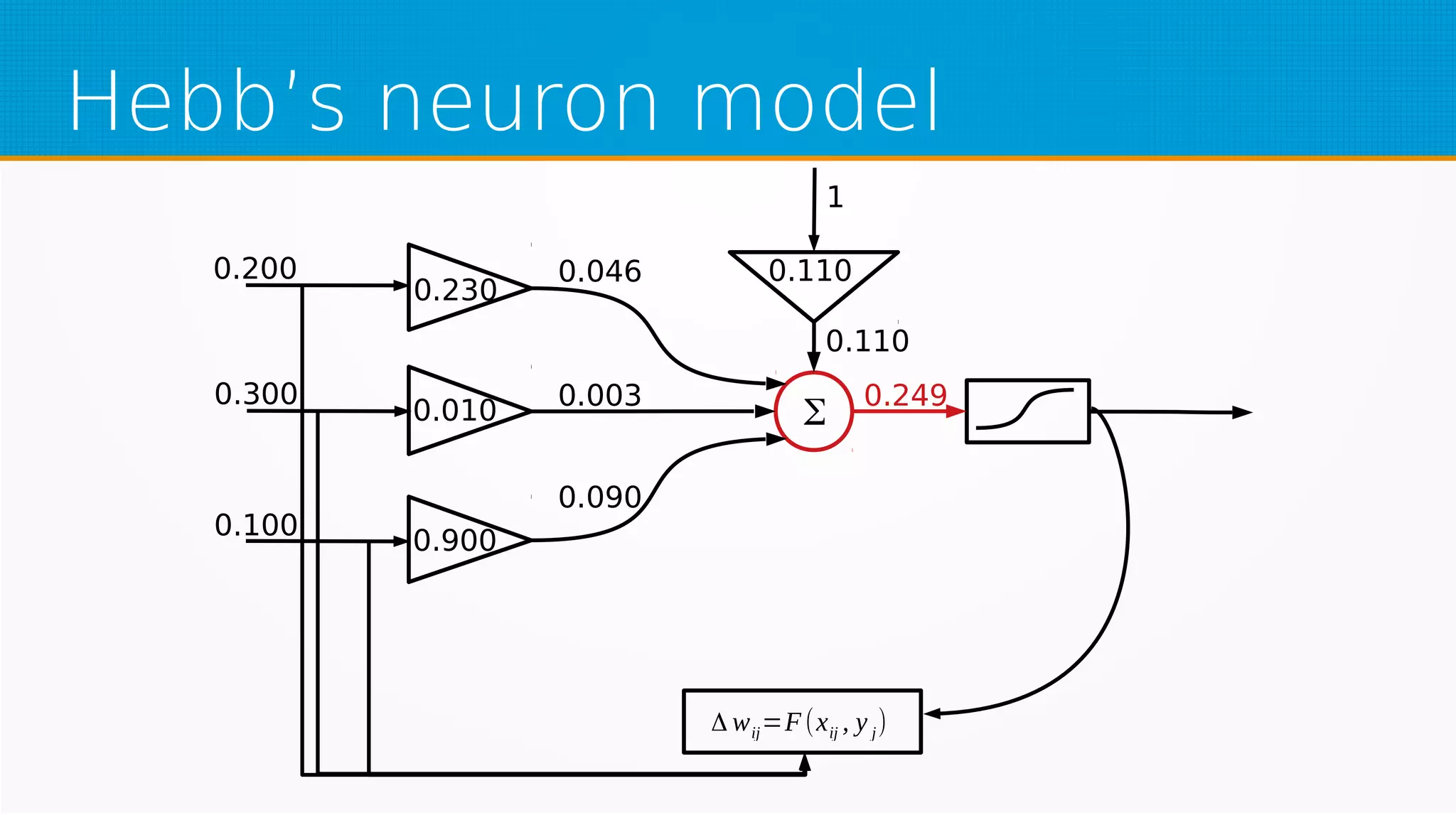
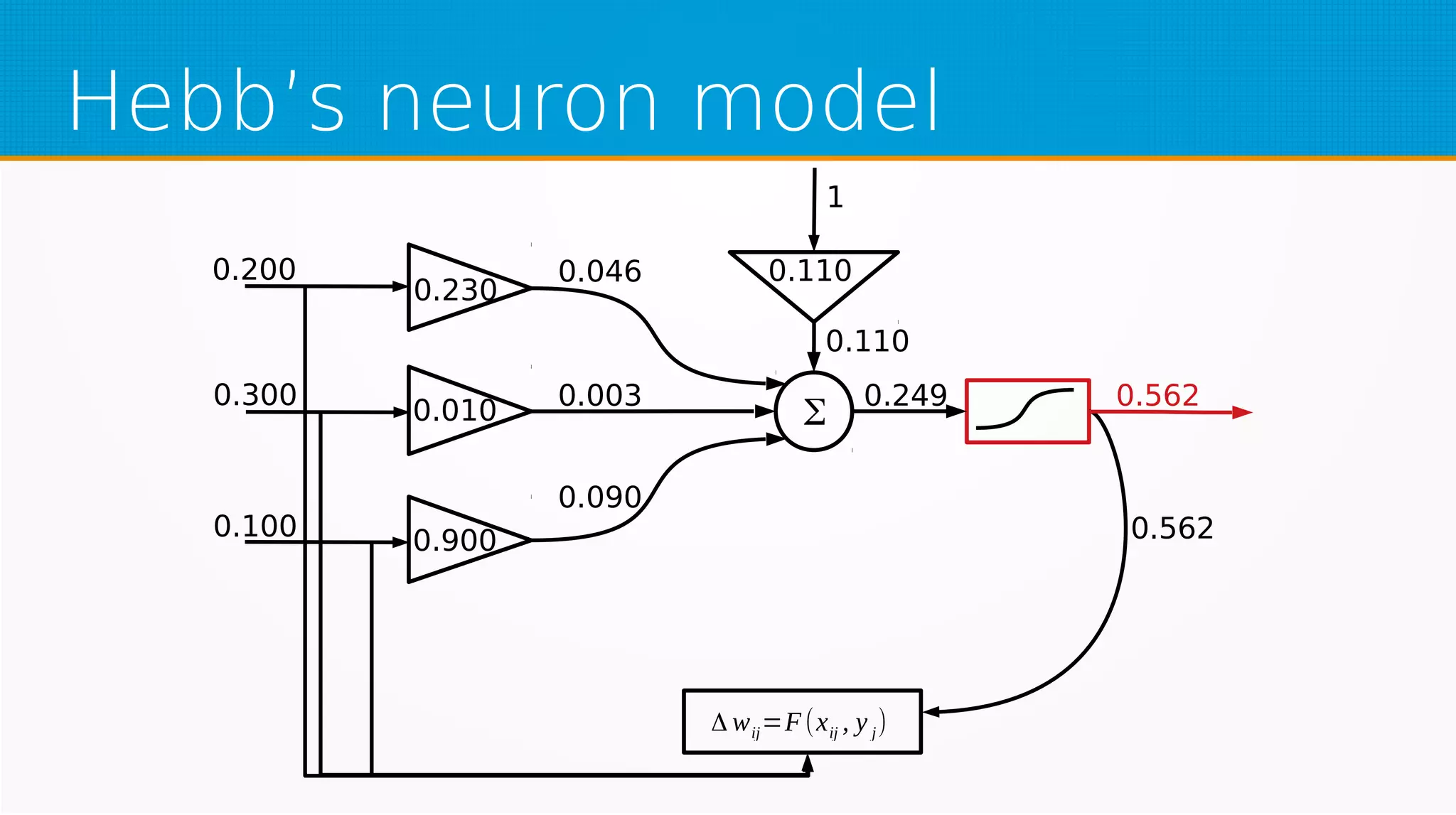
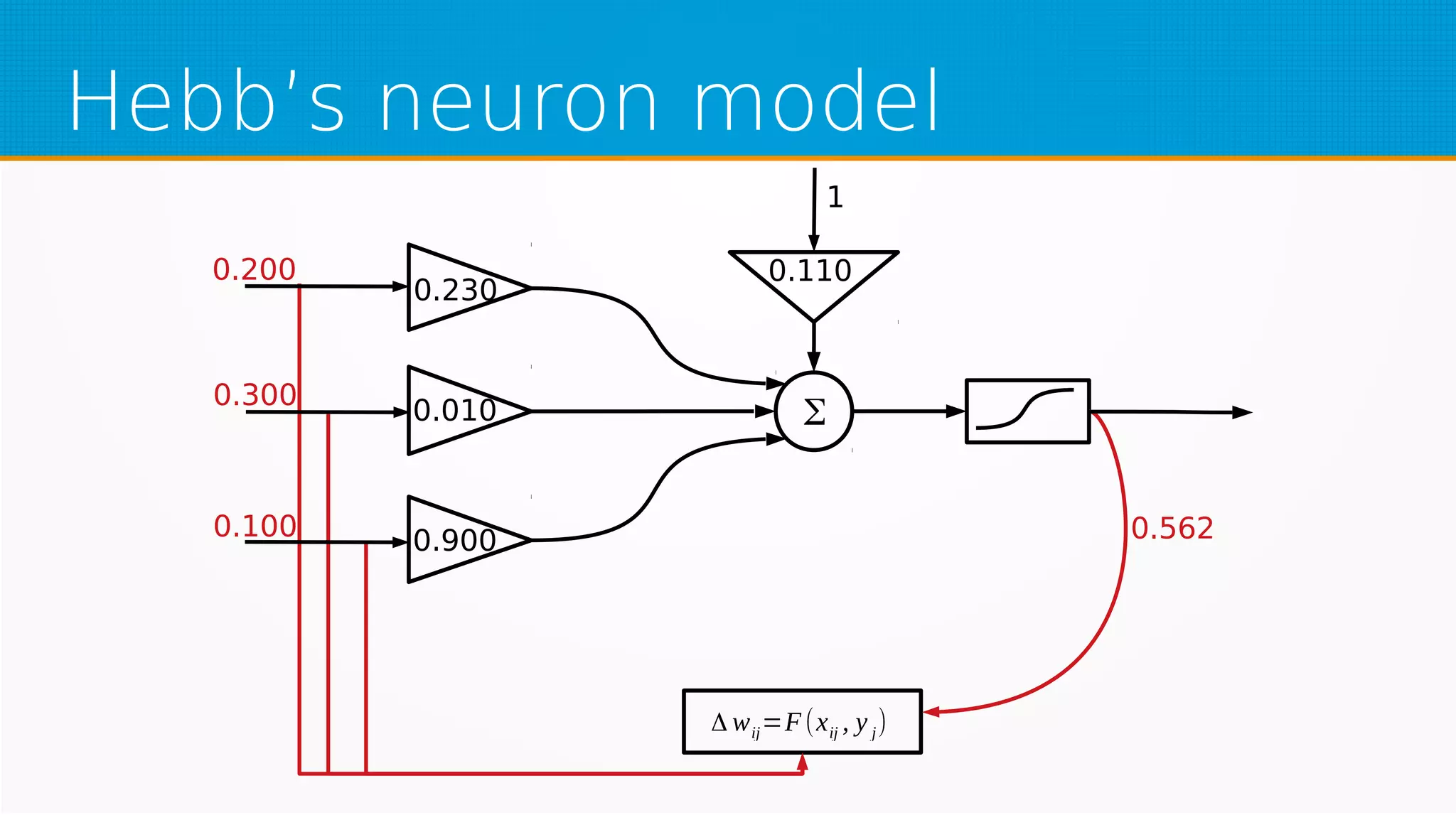
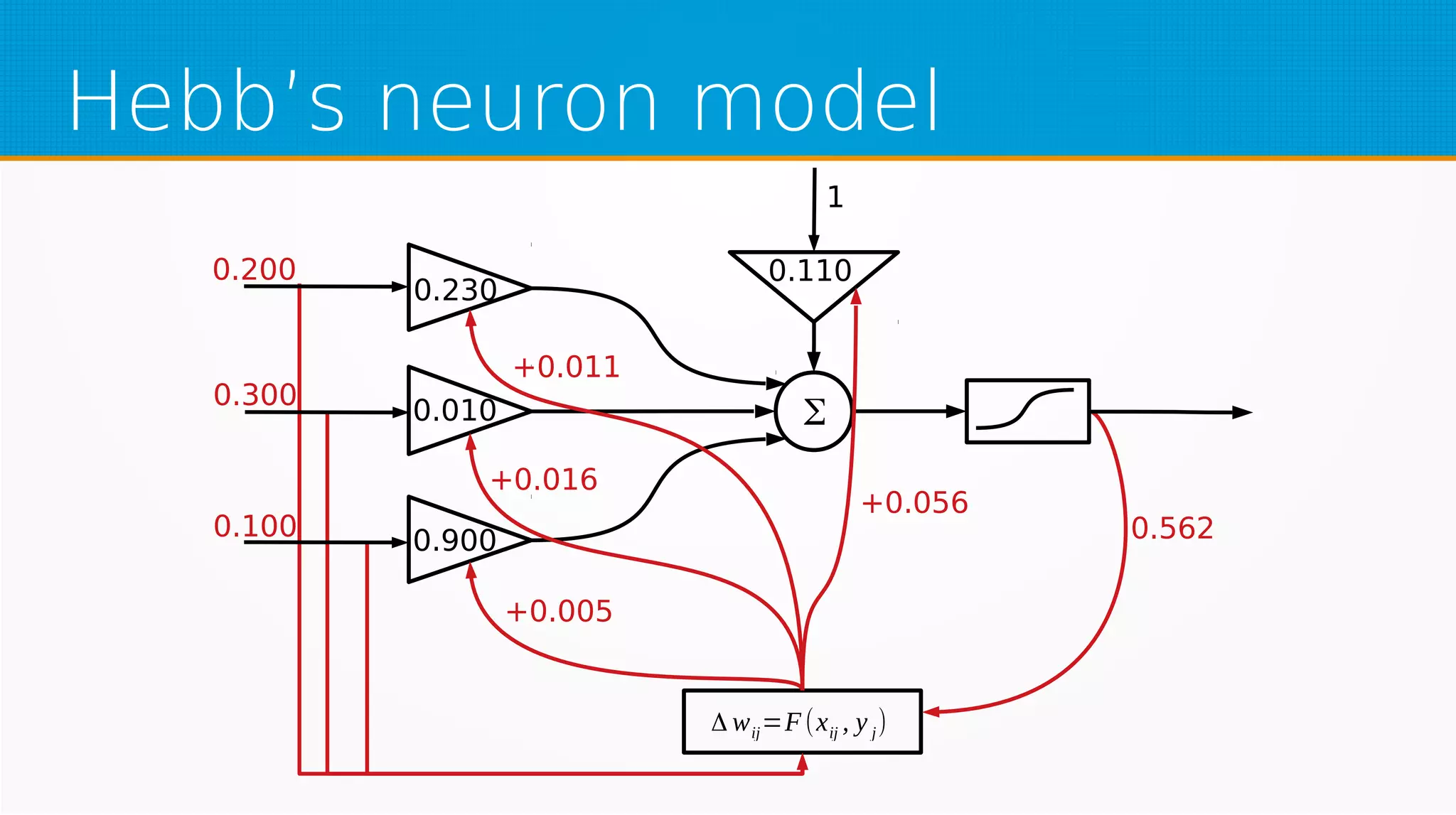
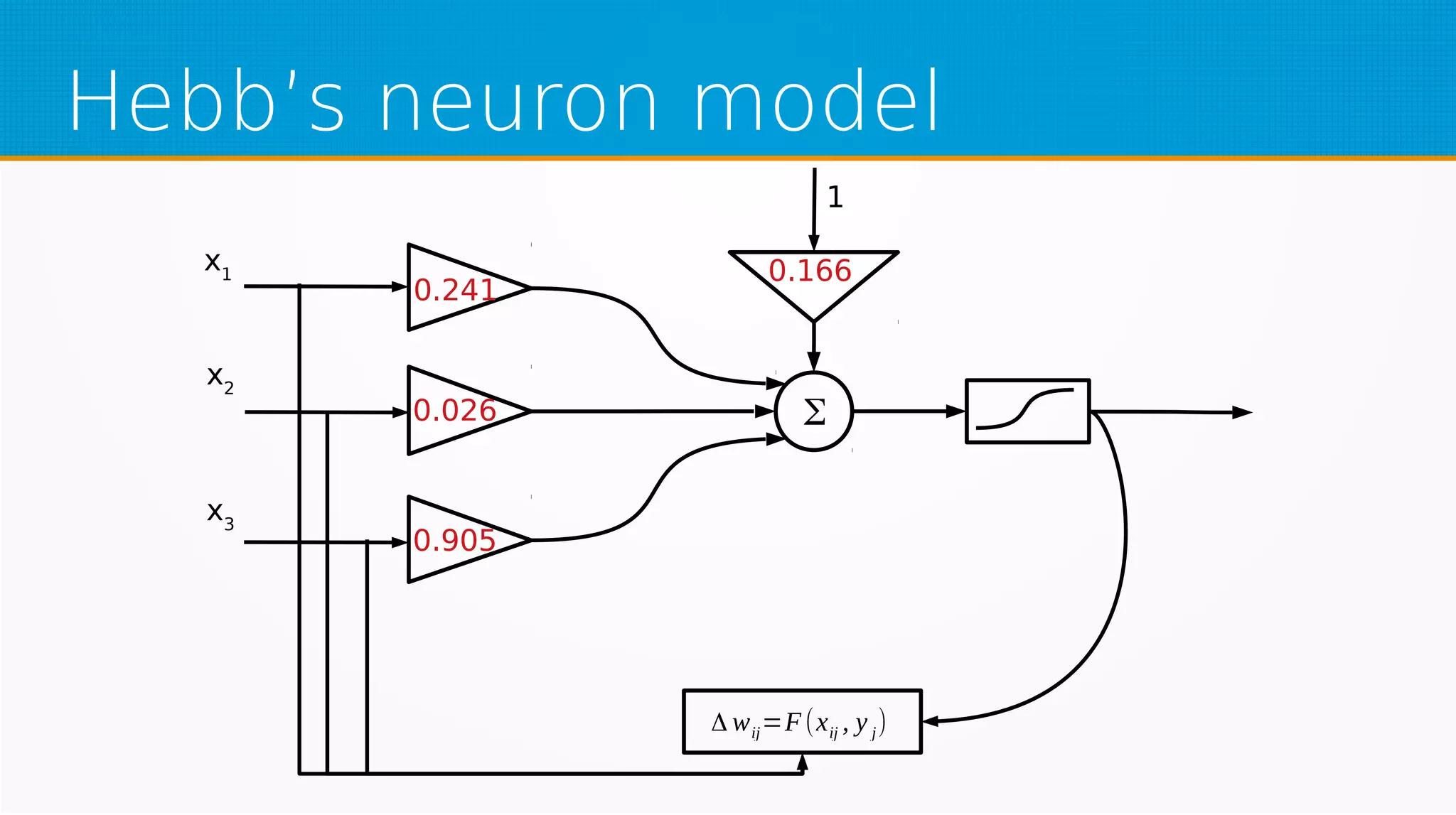


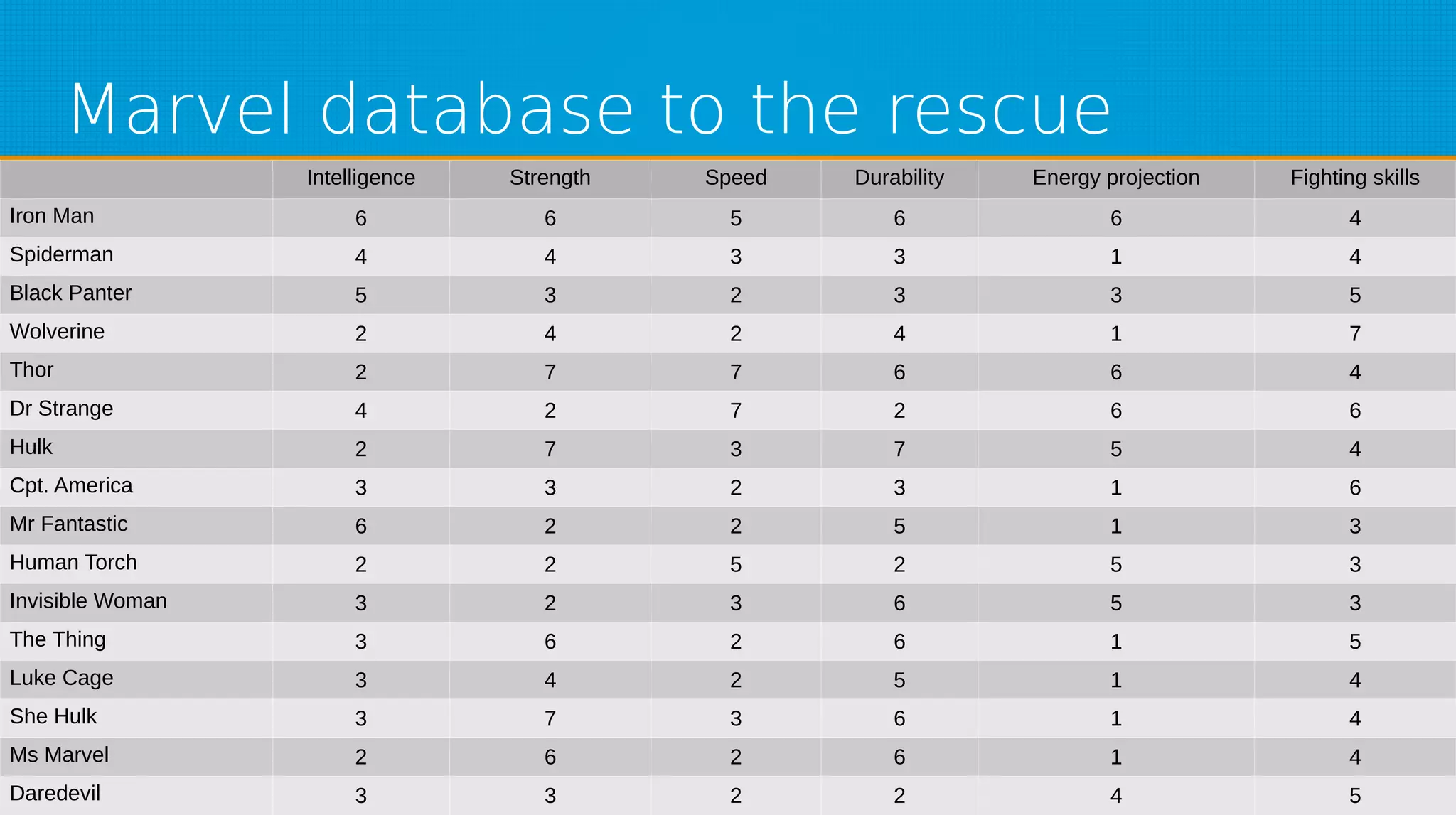




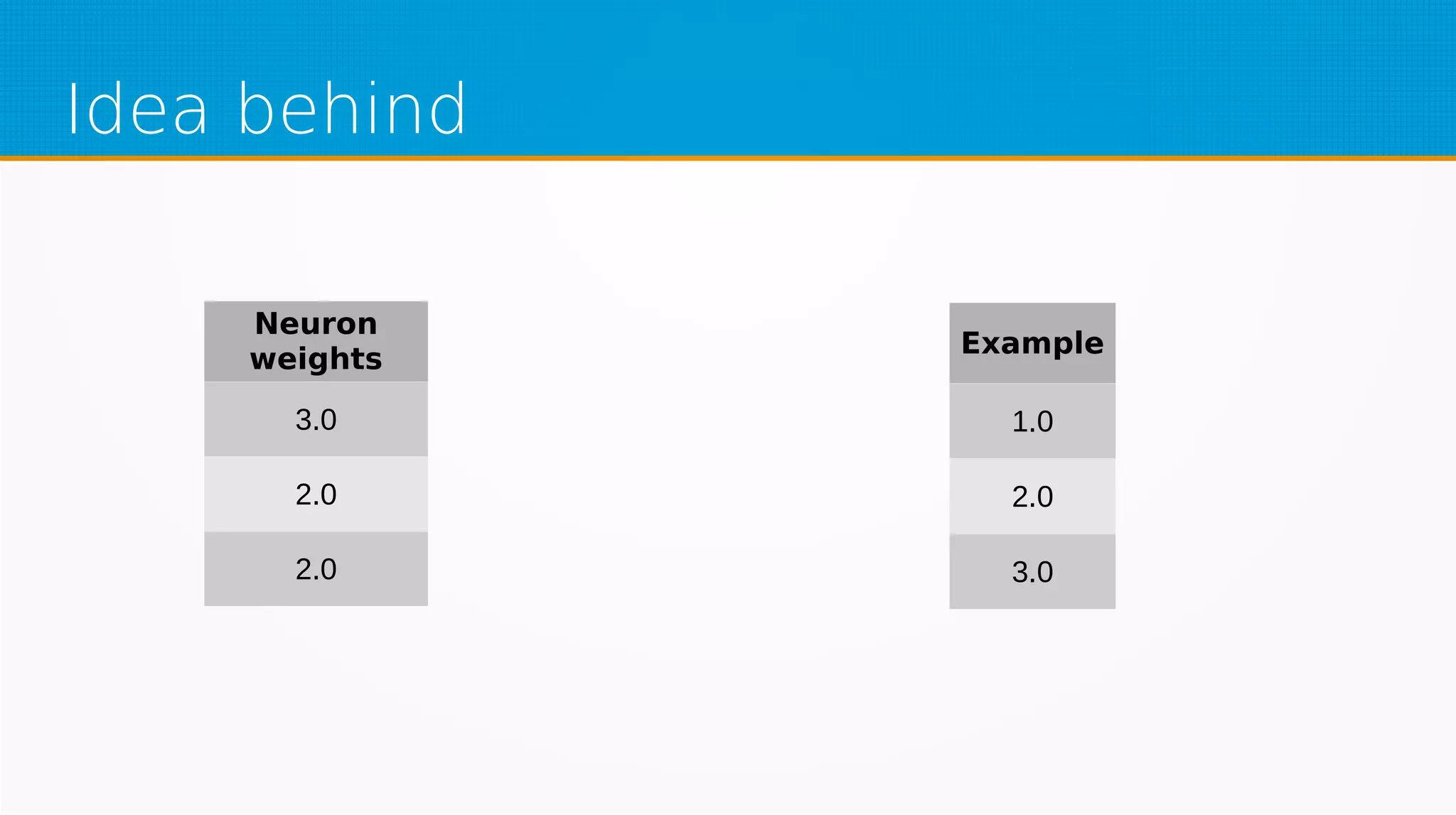
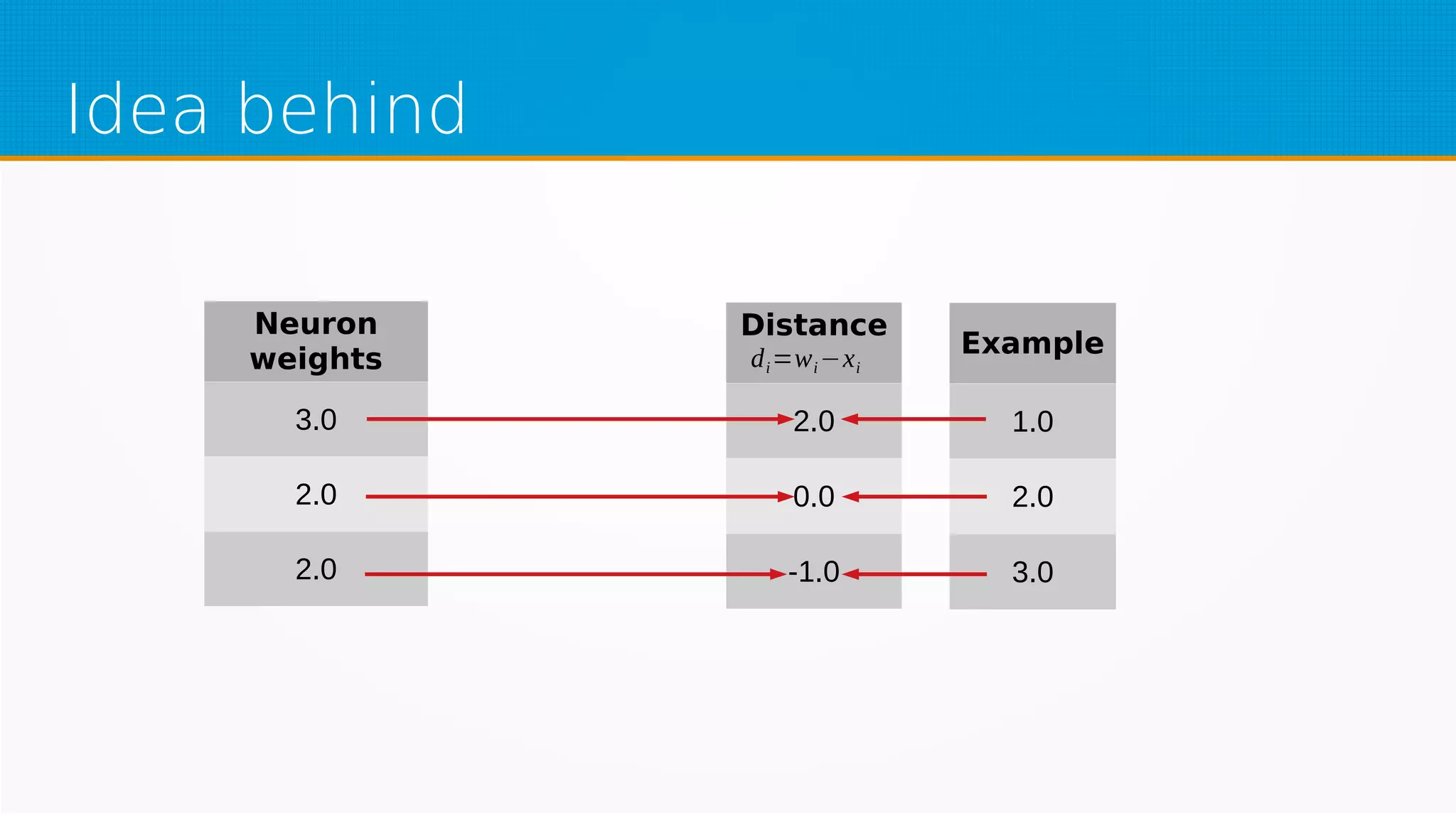
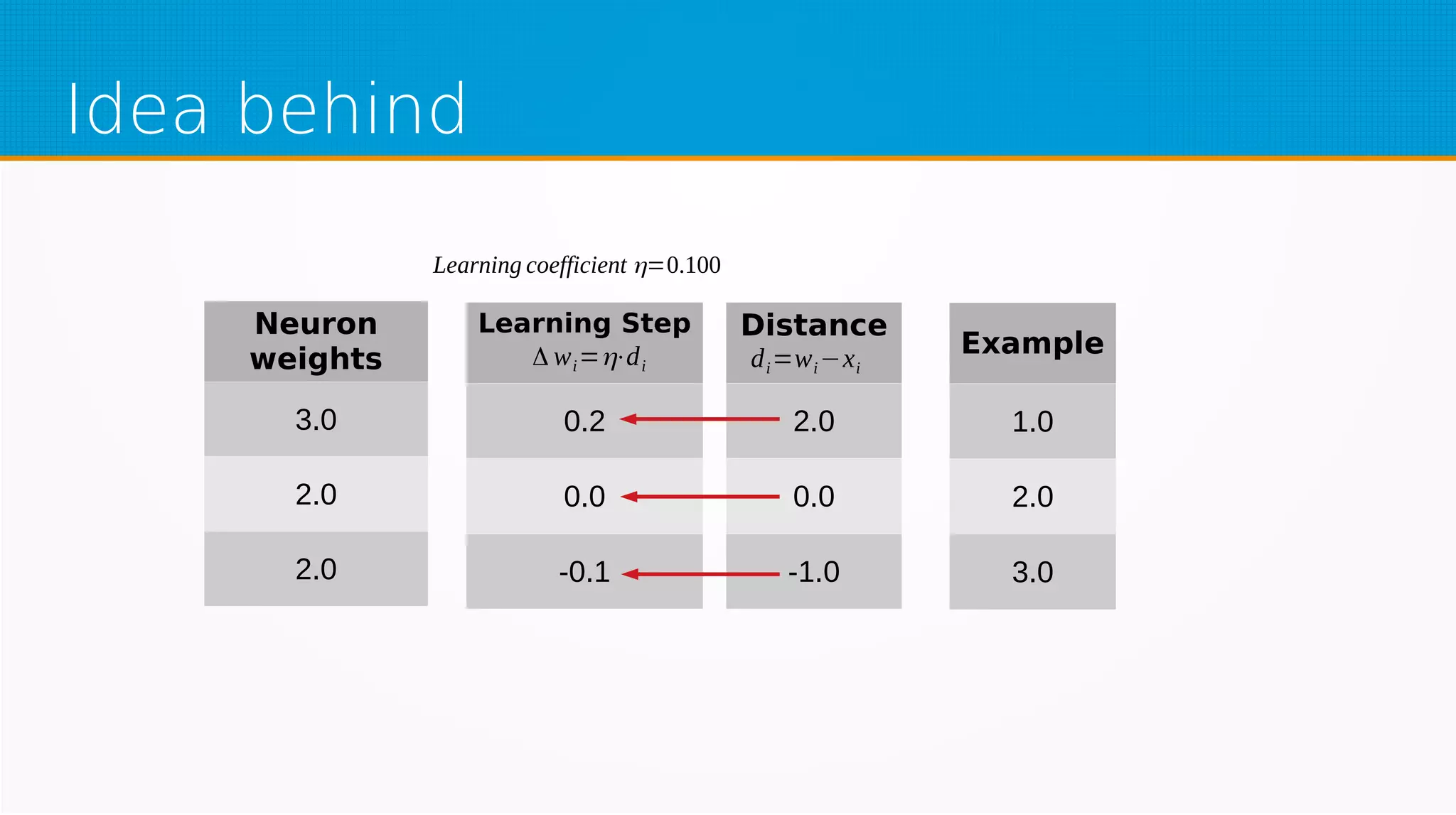
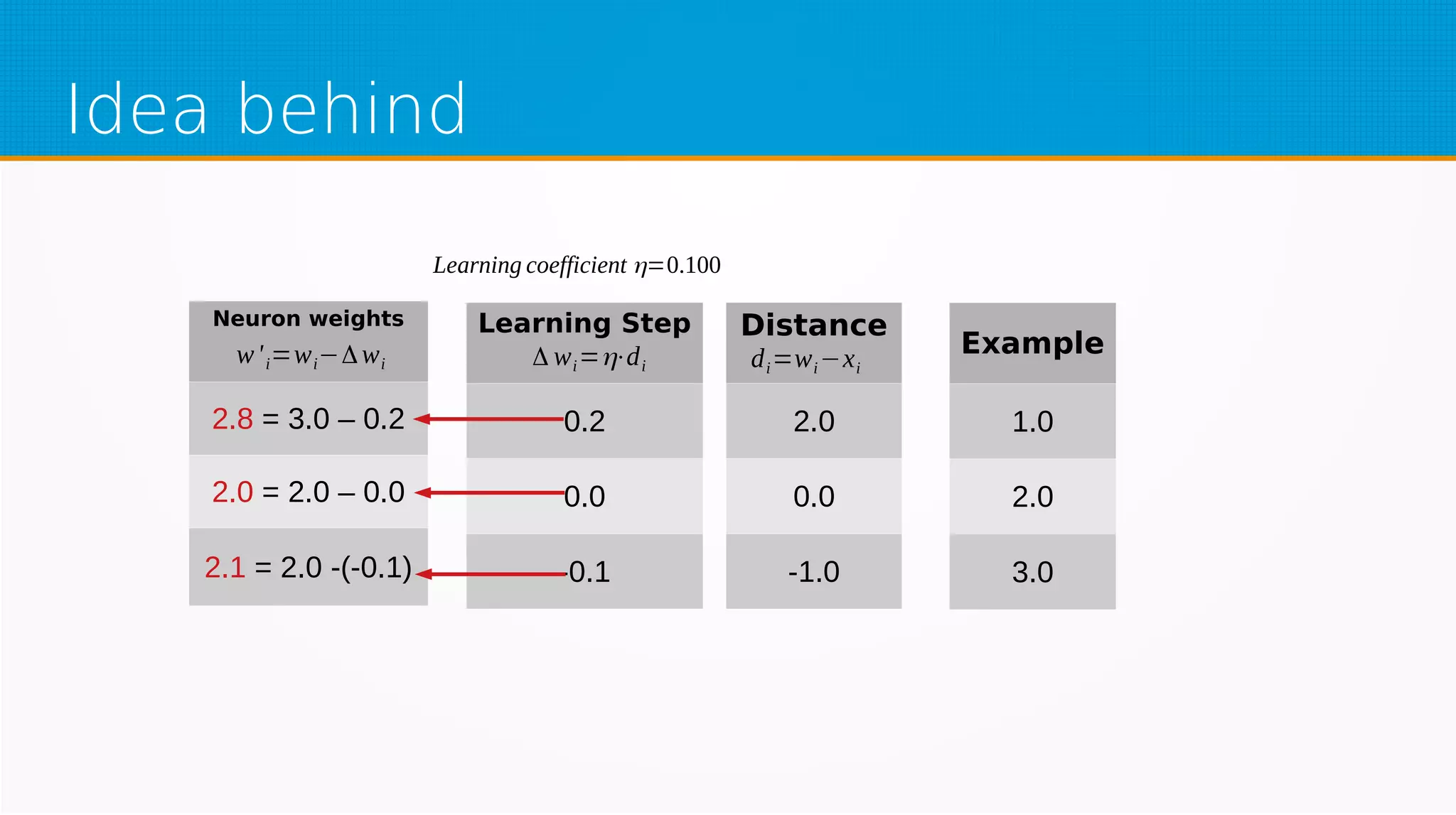










The document provides an overview of machine learning, covering key topics such as supervised and unsupervised learning, neural networks, linear regression, and gradient descent. It emphasizes the mathematical foundations of these concepts and illustrates practical applications including example scenarios like predicting comic book issues based on costume prices. Additionally, it discusses learning algorithms like Hebbian learning and self-organizing maps, highlighting their strengths and weaknesses.























































































