Downloaded 18 times










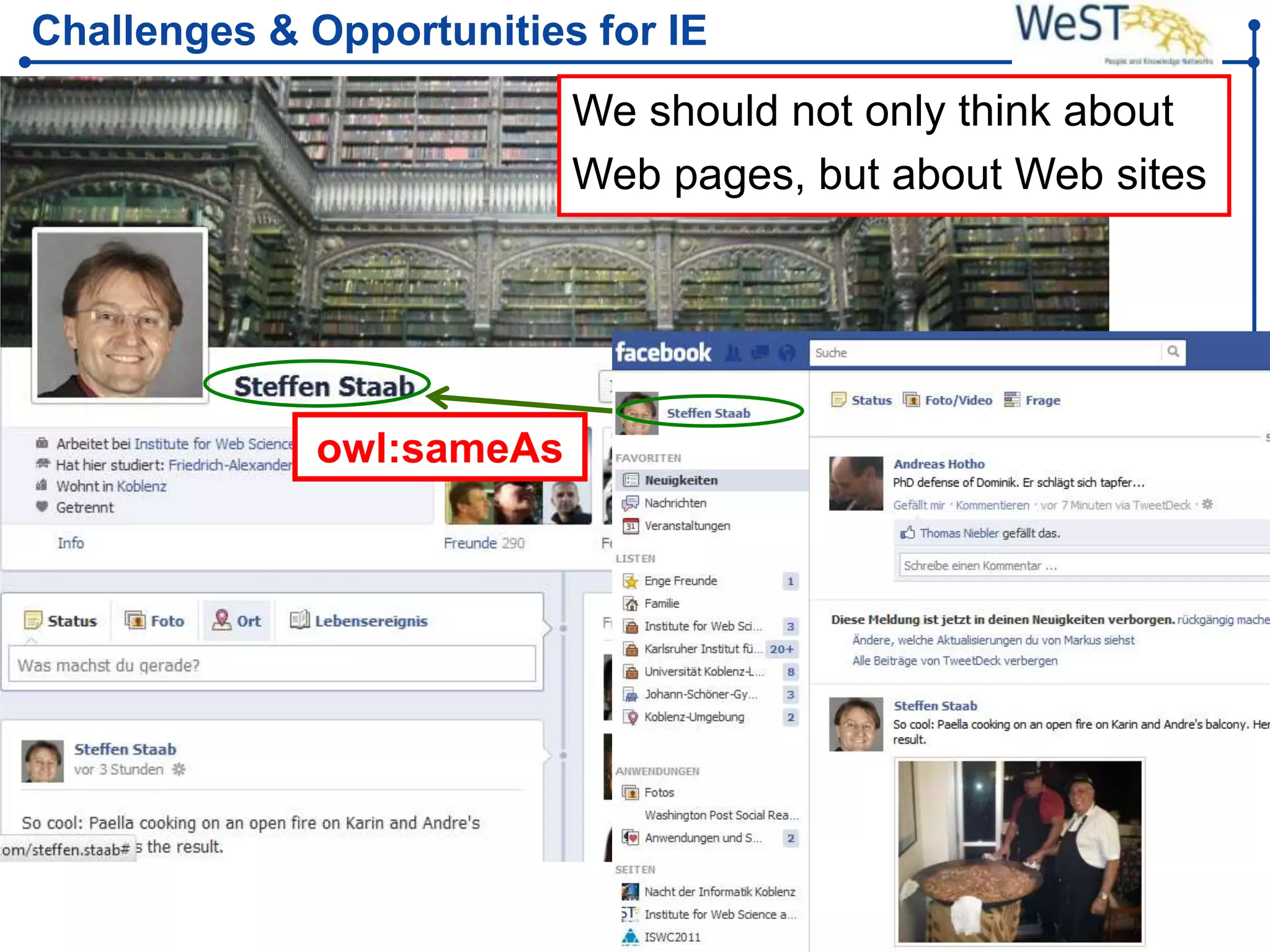


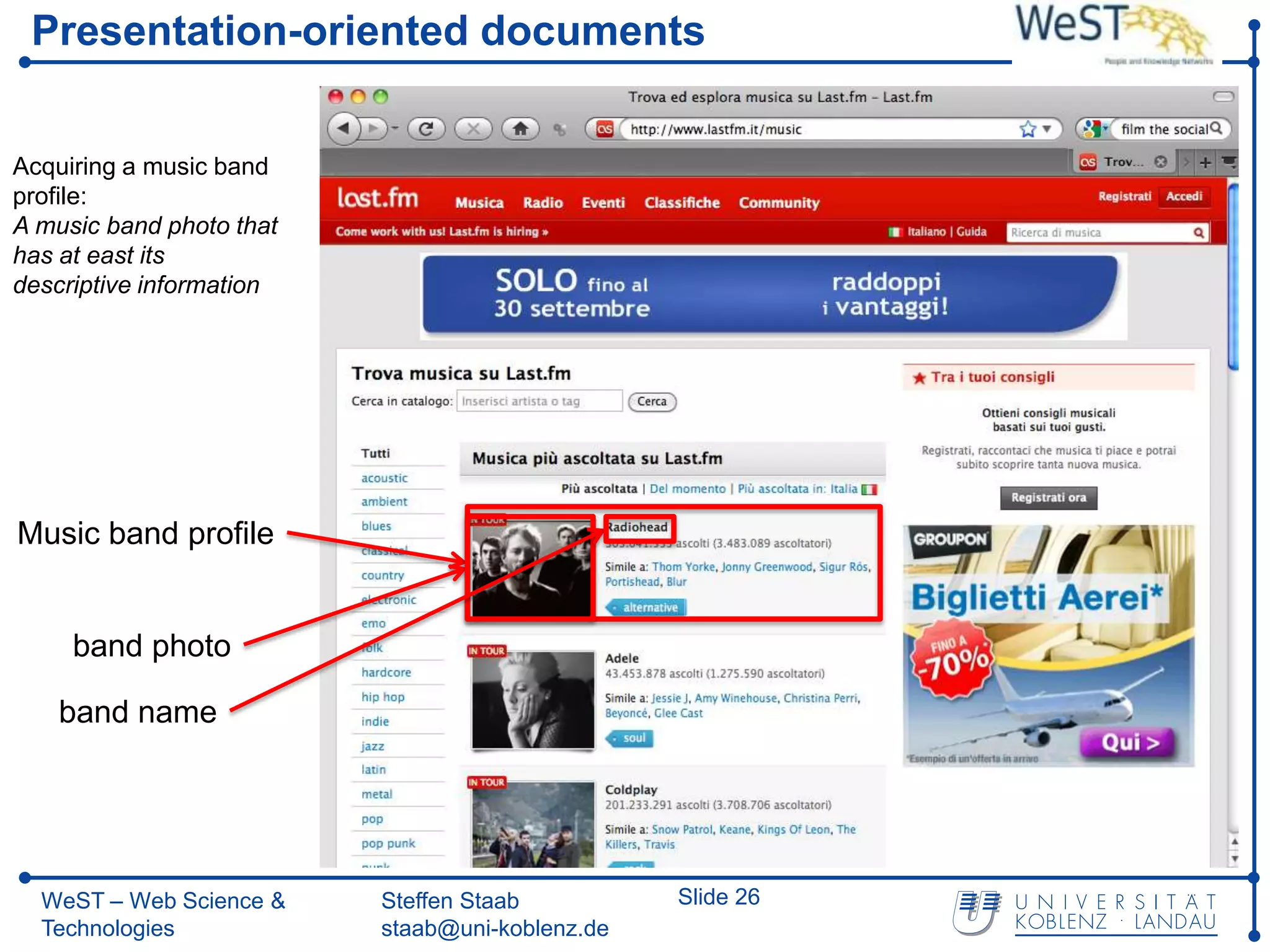
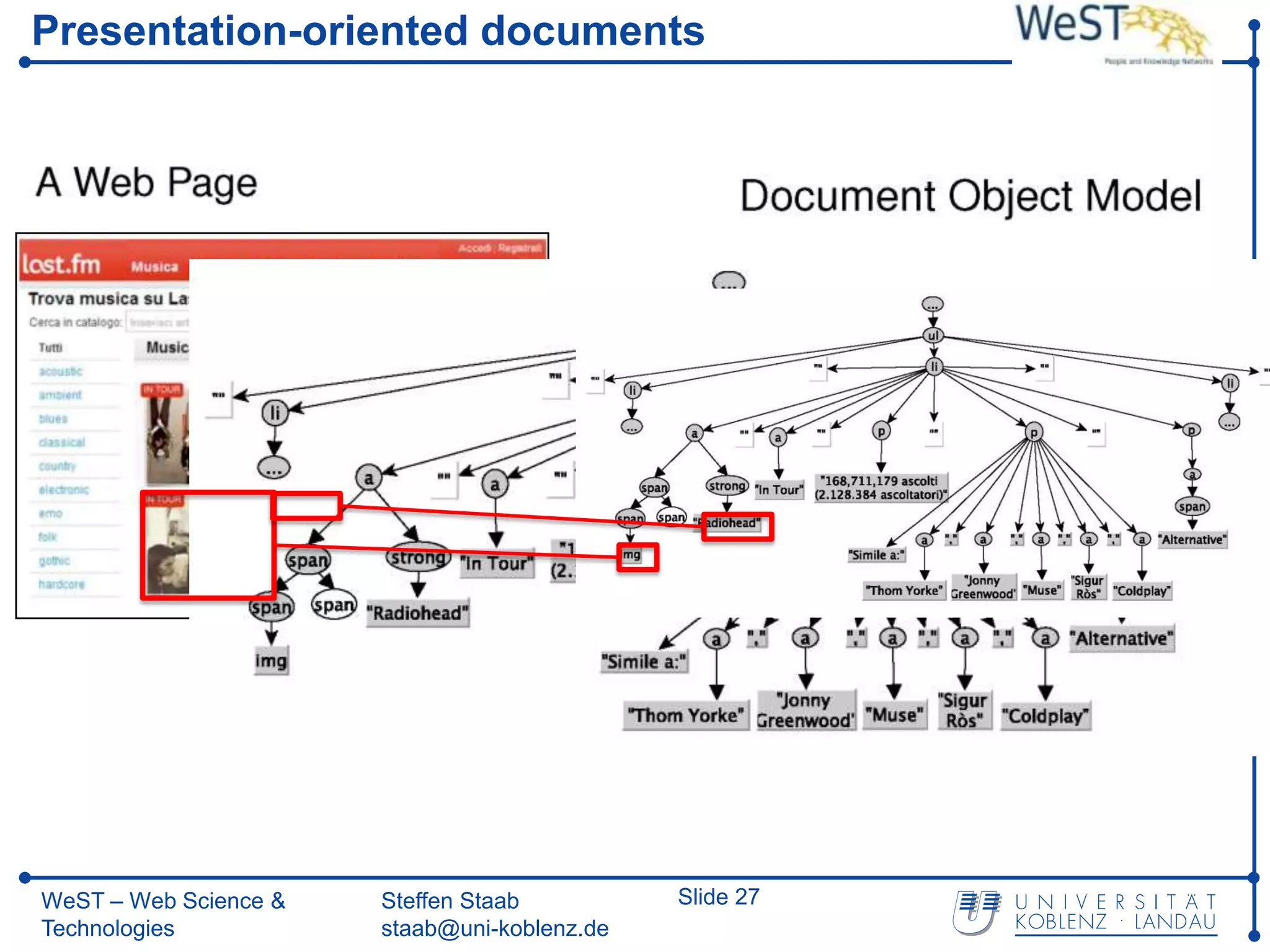
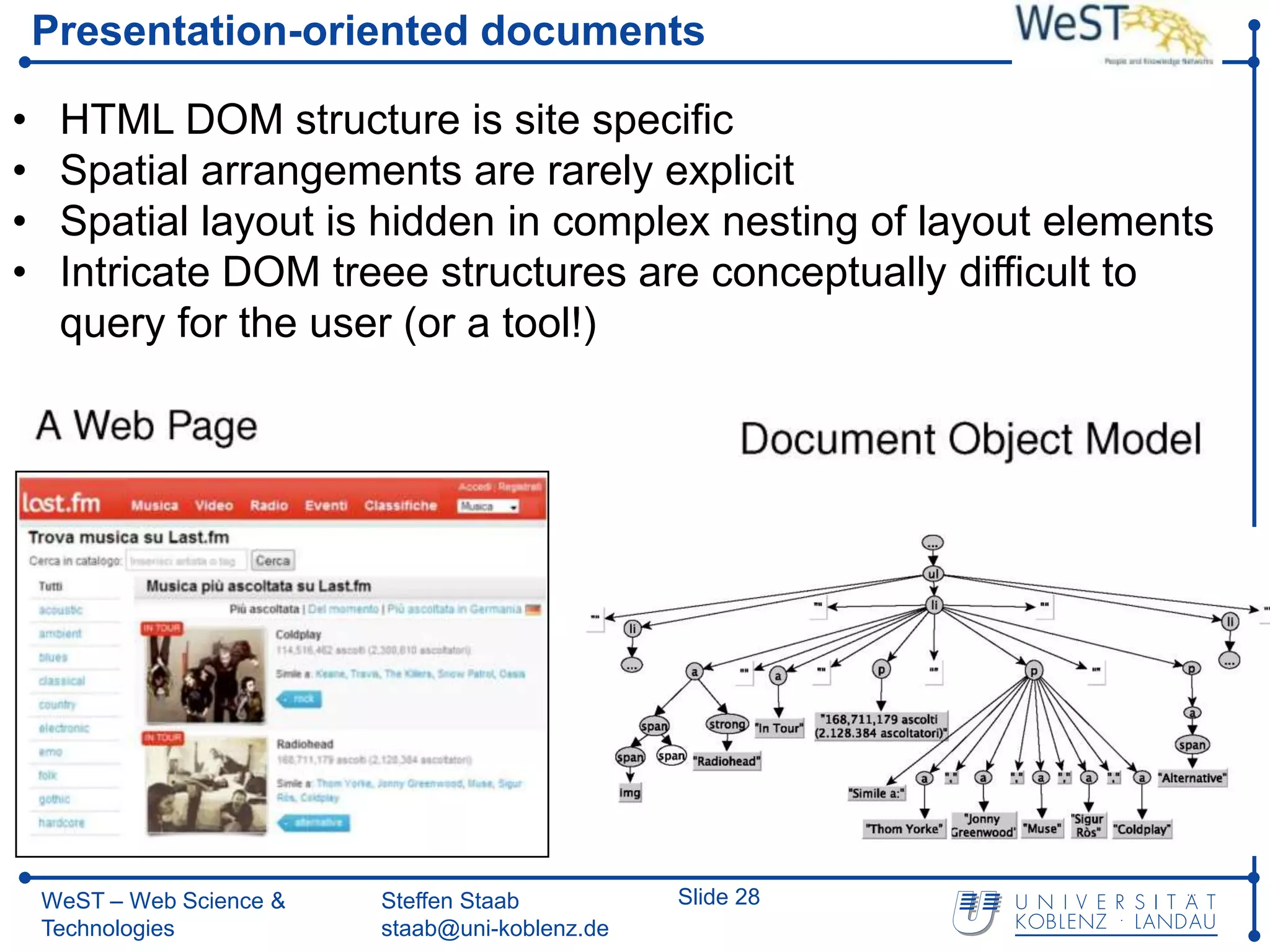
![Related Work
Web Query languages
Xpath 1.0 and XQuery1.0
Established
Too difficult to use for scraping from intricate DOM structures
Visual languages
Spatial Graph Grammars [Kong et al.] are quite complex in
term of both usability and efficiency
Algebras for creating and querying multimedia interactive
presentations (e.g. ppt) [Subrahmanian et al.]
Web wrapper induction exploiting visual interface
[Gottlob et al.] [Sahuguet et al.]
generate XPath location paths of DOM nodes
can benefit from using Spatial XPath
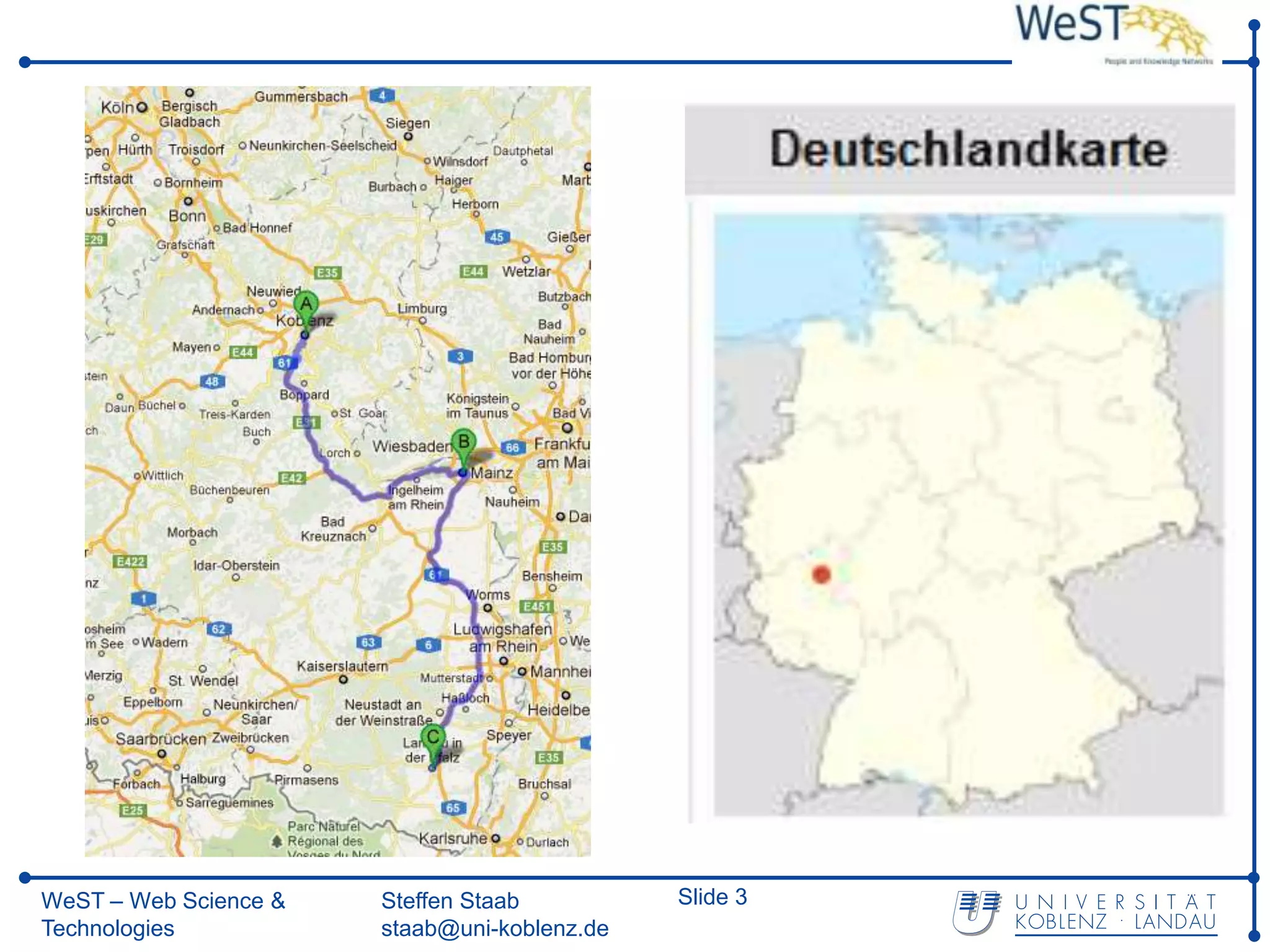
WeST – Web Science & Steffen Staab Slide 29
Technologies staab@uni-koblenz.de](https://image.slidesharecdn.com/informationextractionpucriov20120308-final-120312122126-phpapp01/75/Information-extraction-for-building-knowledge-basis-29-2048.jpg)

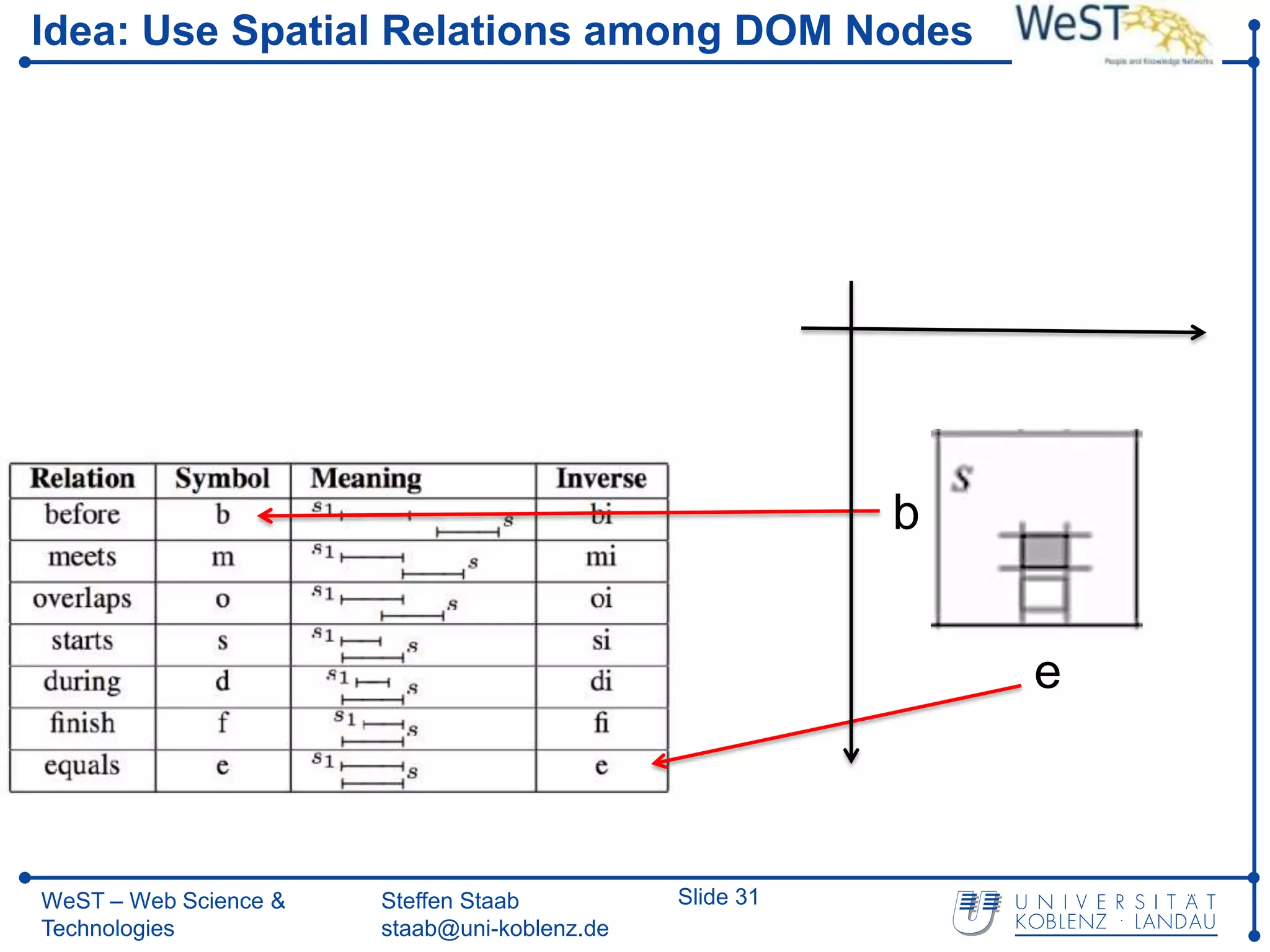
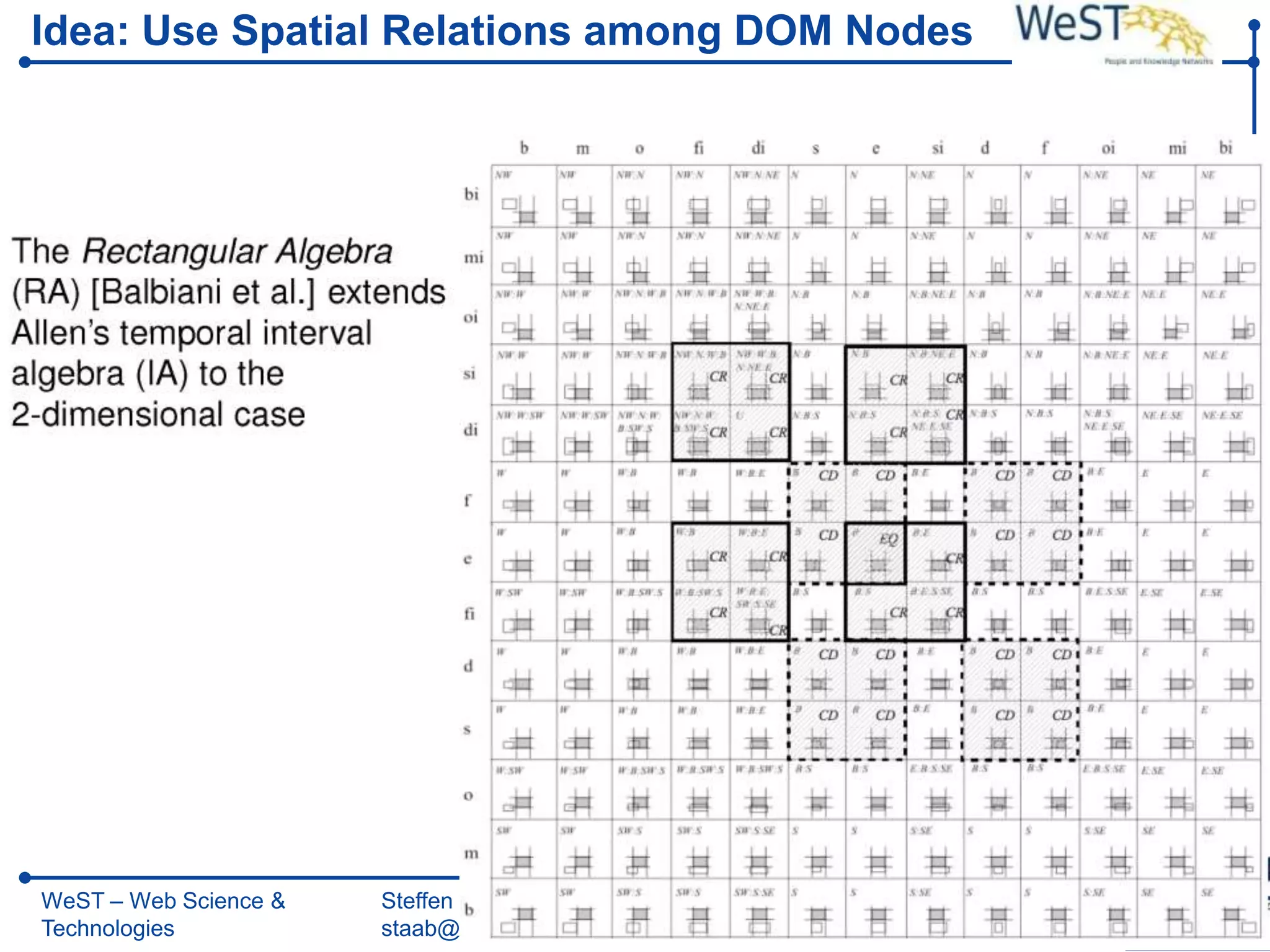
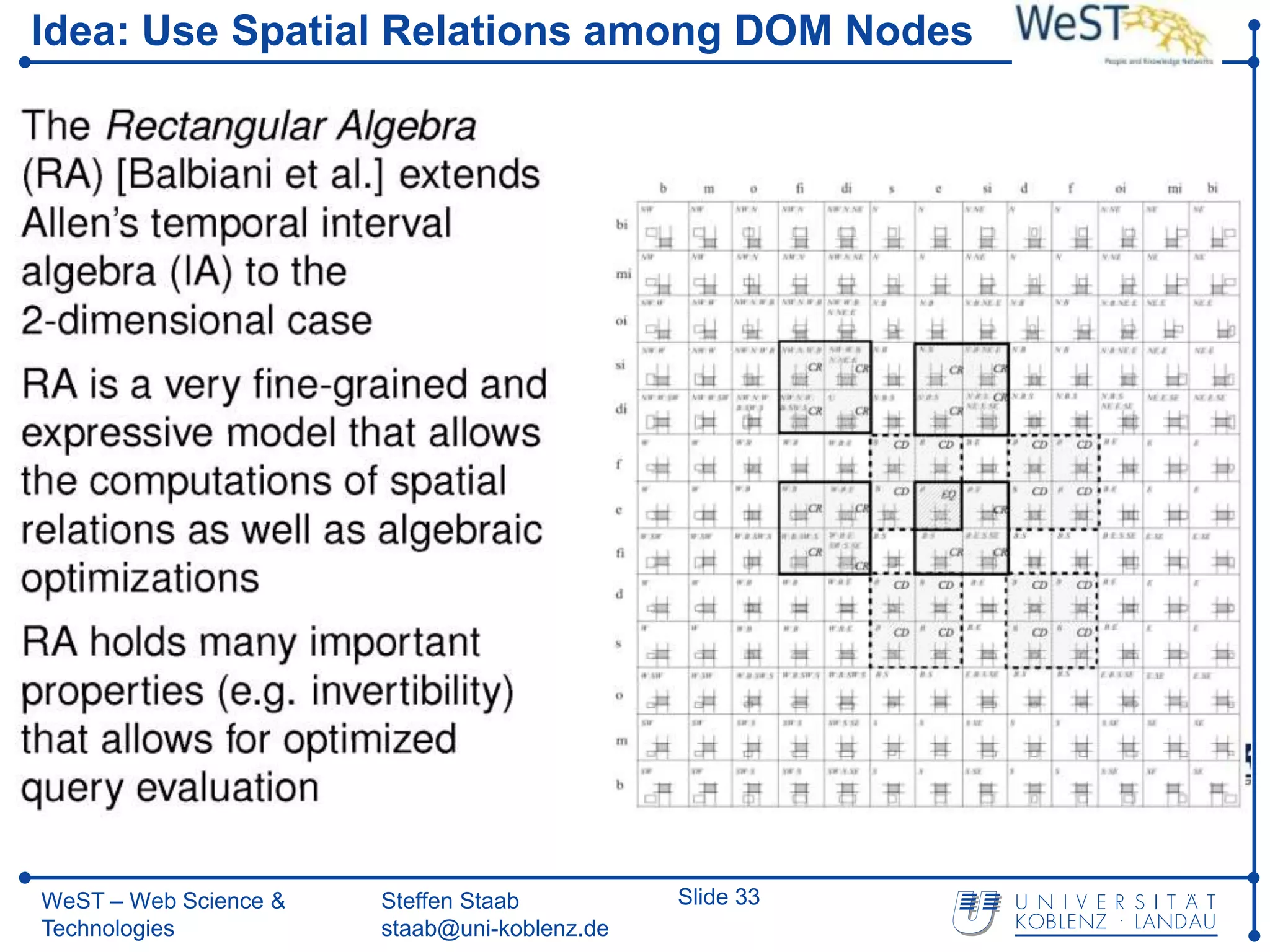
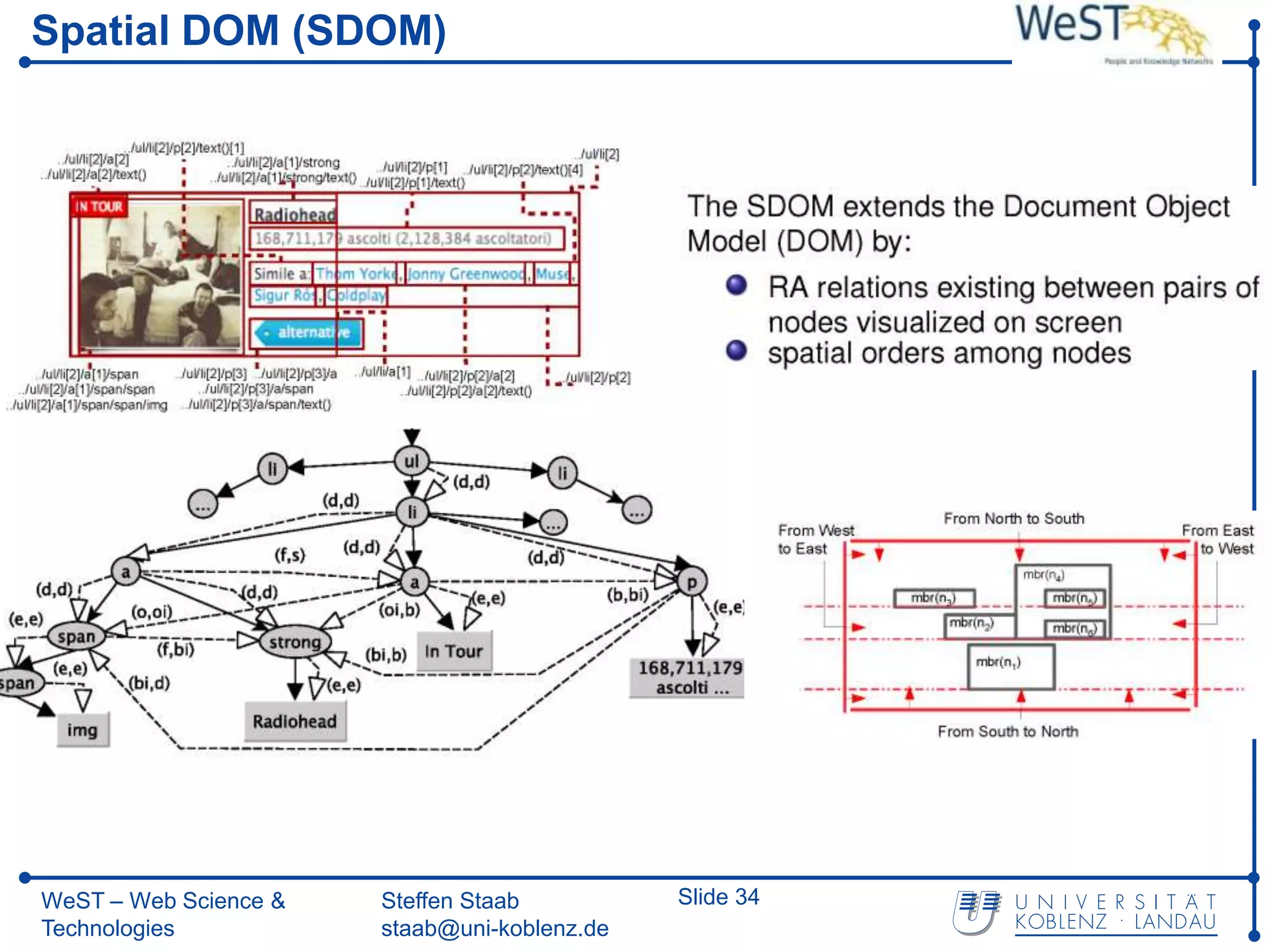

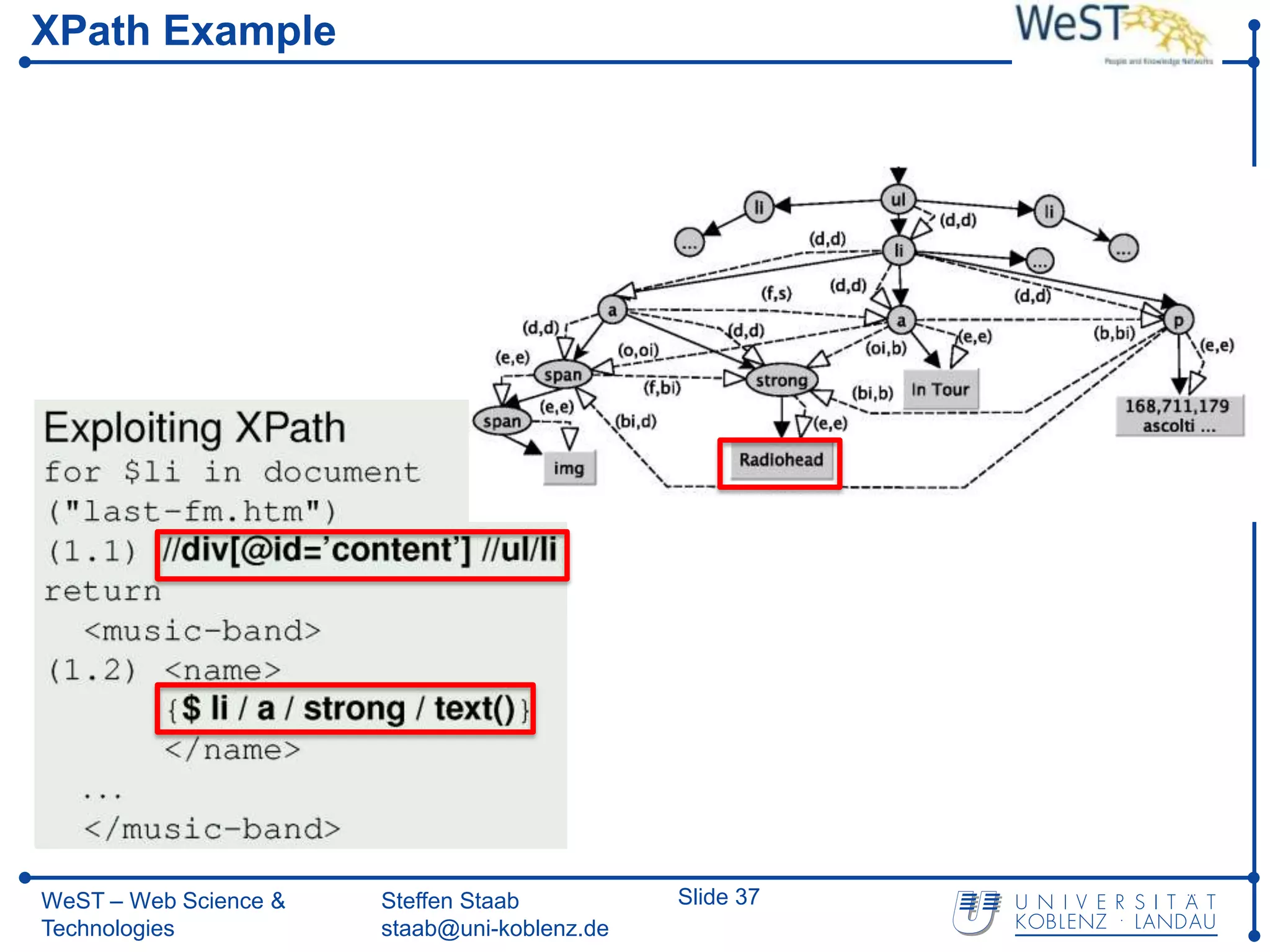
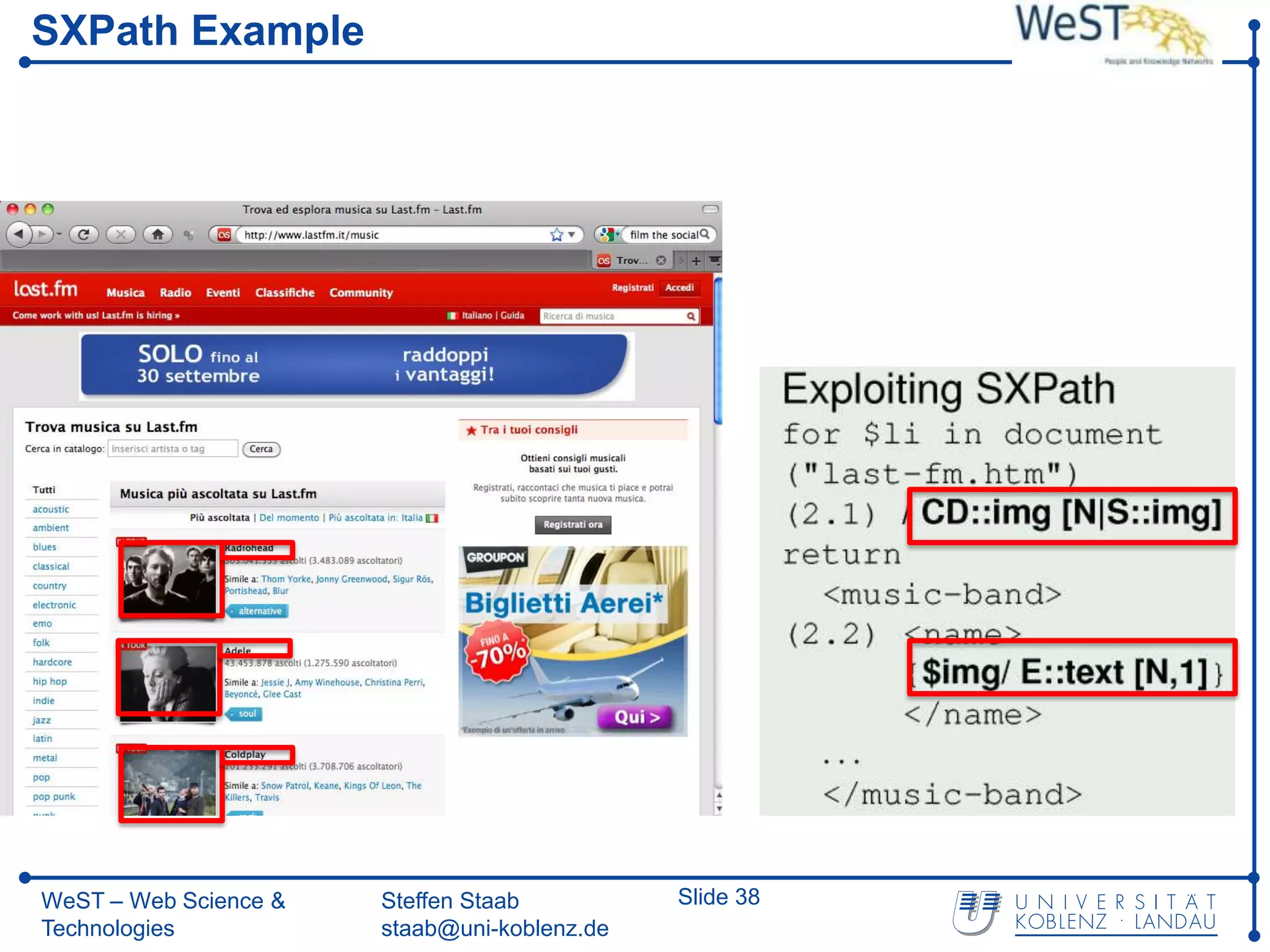
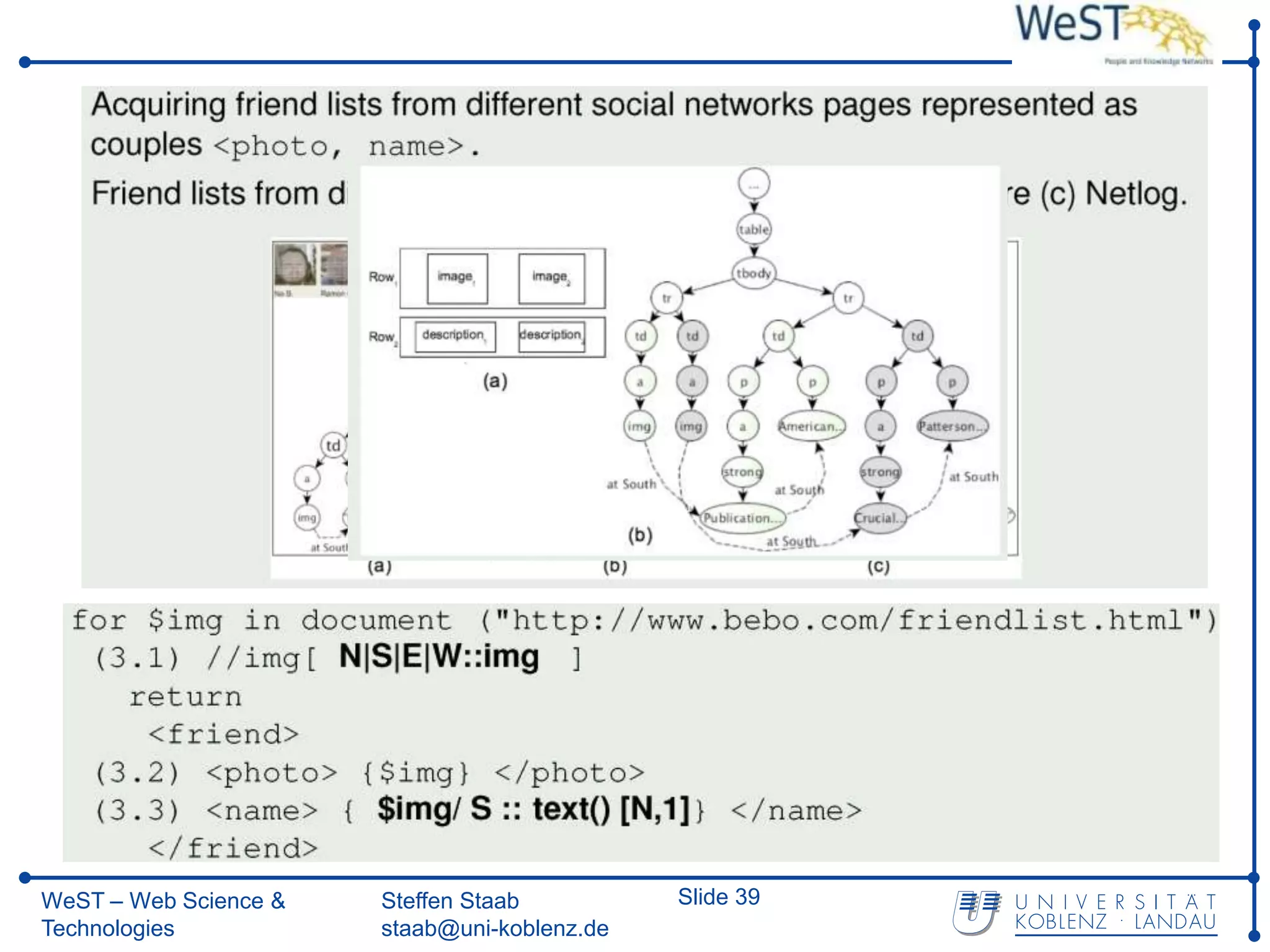
![From XPath 1.0 towards Spatial Querying with SXPath
SXPath features
adopts intuitive path notation:
axis::nodetest [pred]*
adds to XPath
spatial axes
spatial position functions
natural semantics for spatial querying
maintains polynomial time combined complexity
WeST – Web Science & Steffen Staab Slide 40
Technologies staab@uni-koblenz.de](https://image.slidesharecdn.com/informationextractionpucriov20120308-final-120312122126-phpapp01/75/Information-extraction-for-building-knowledge-basis-39-2048.jpg)







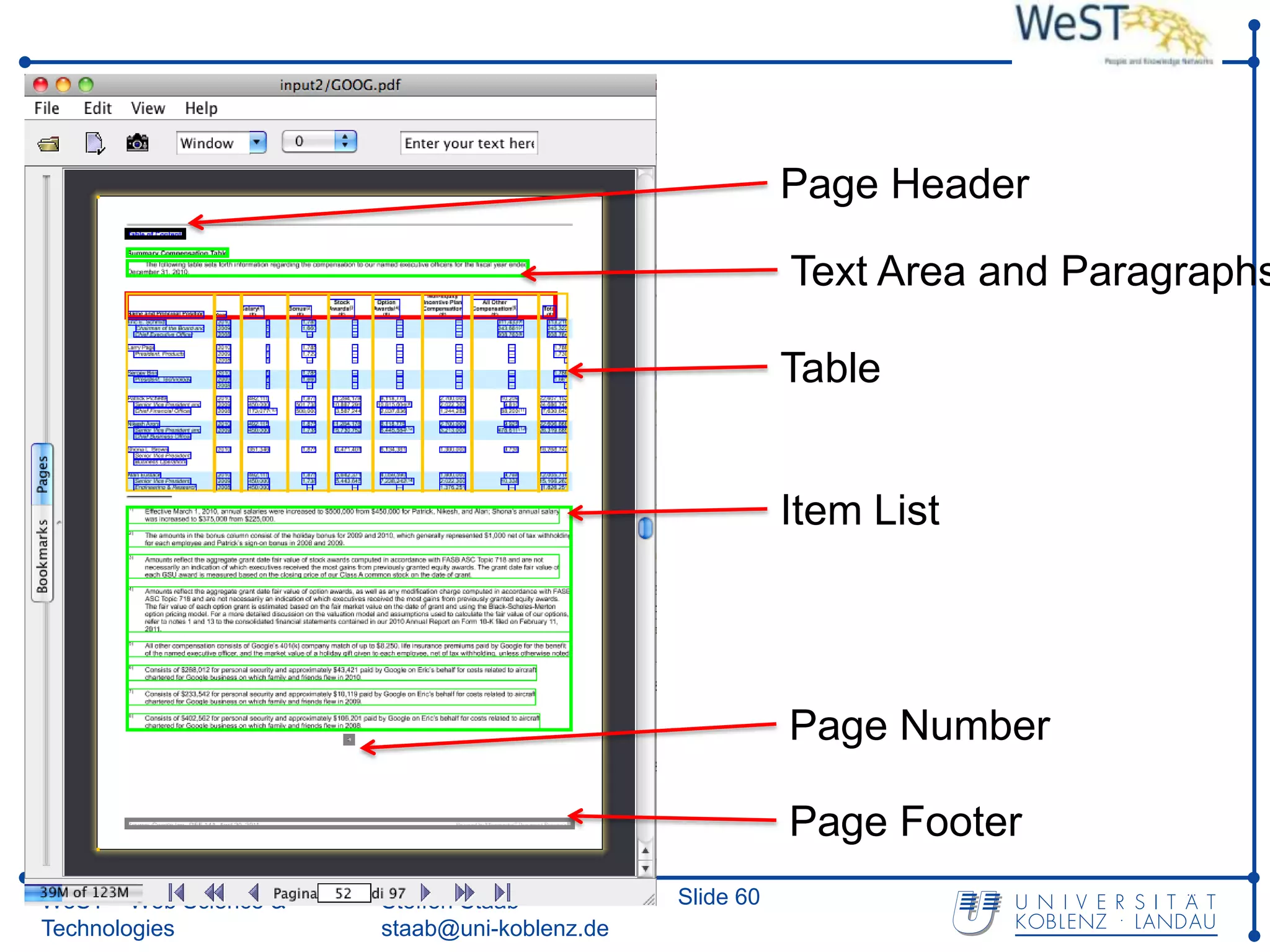

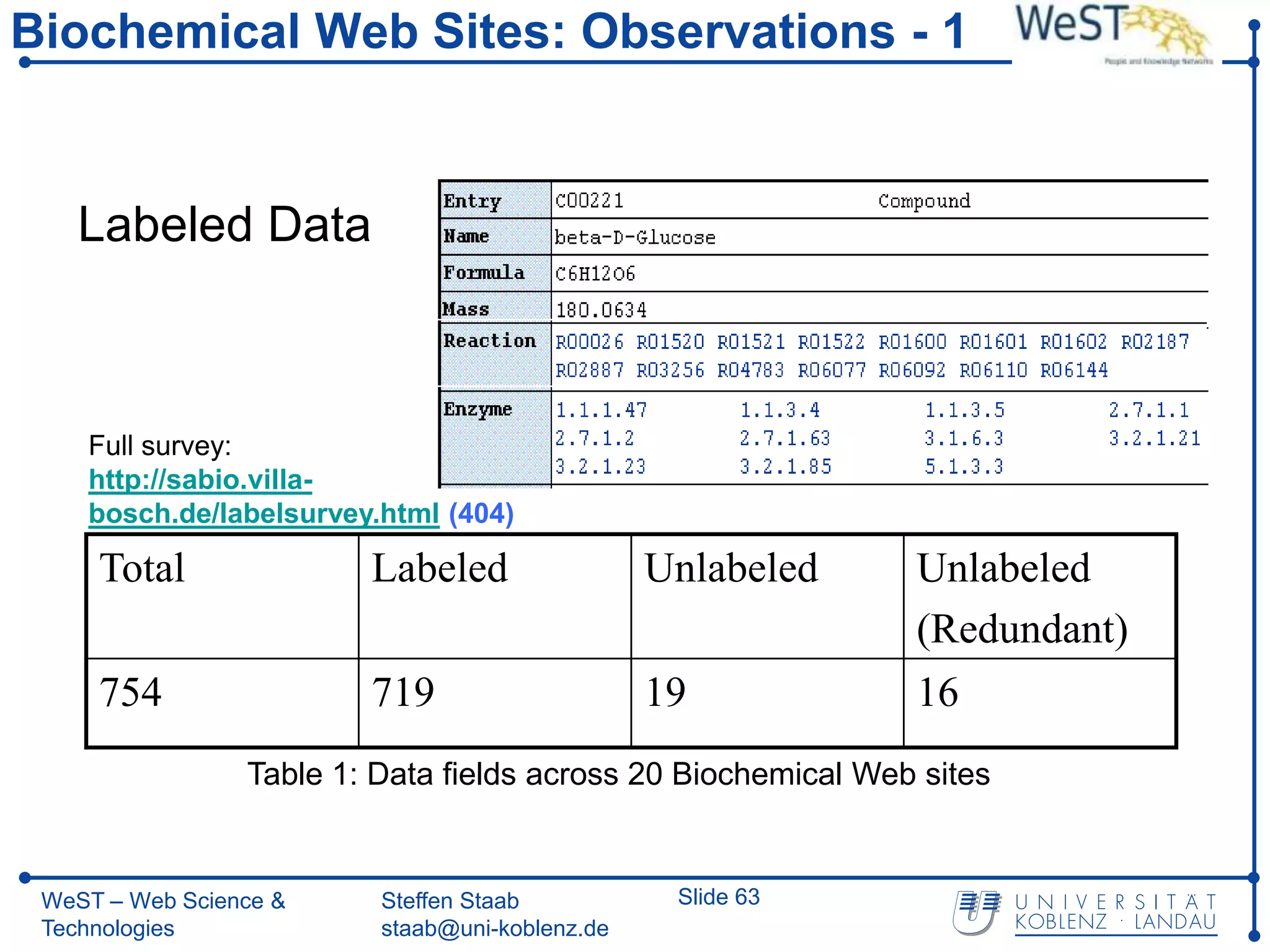
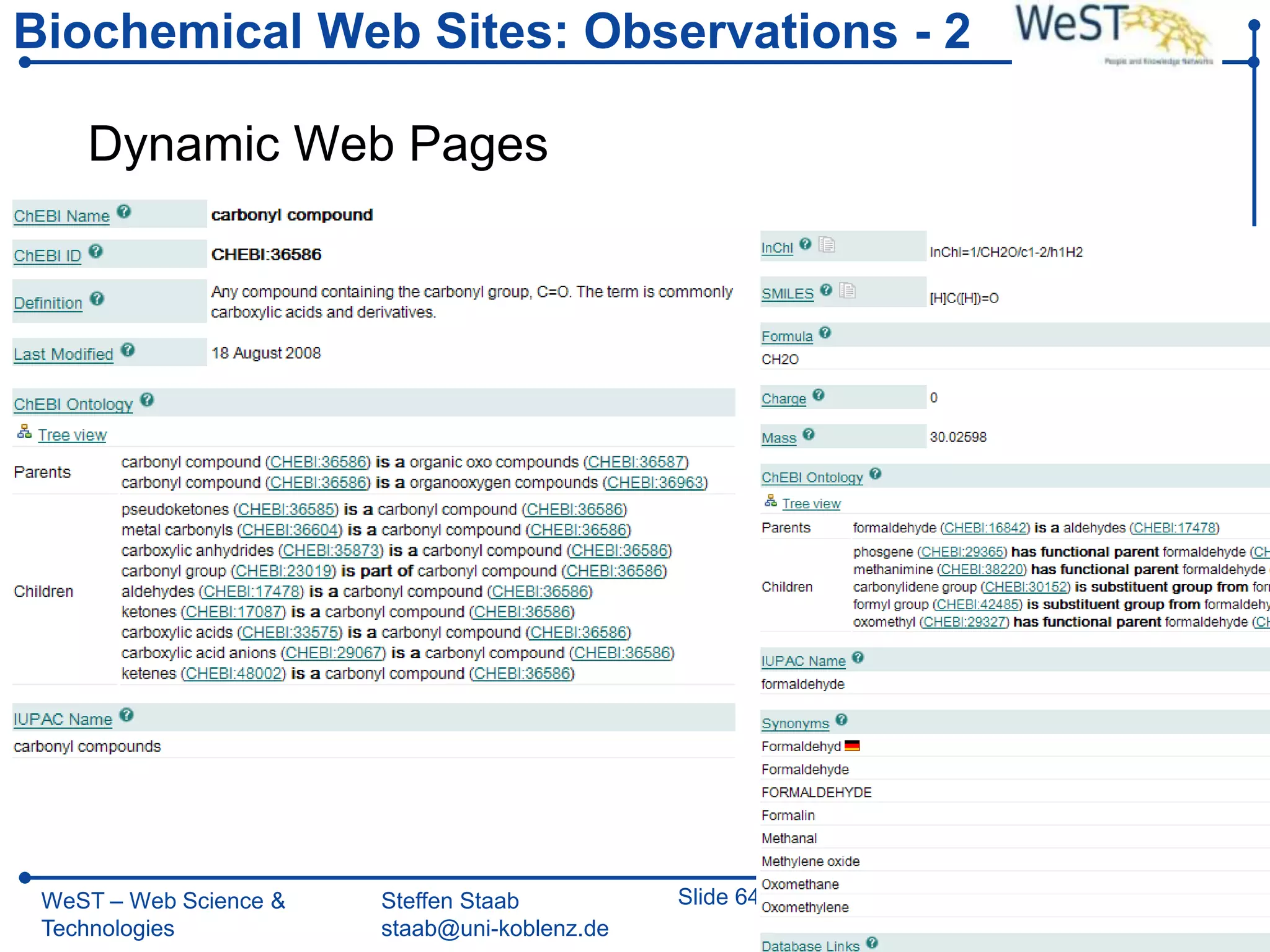
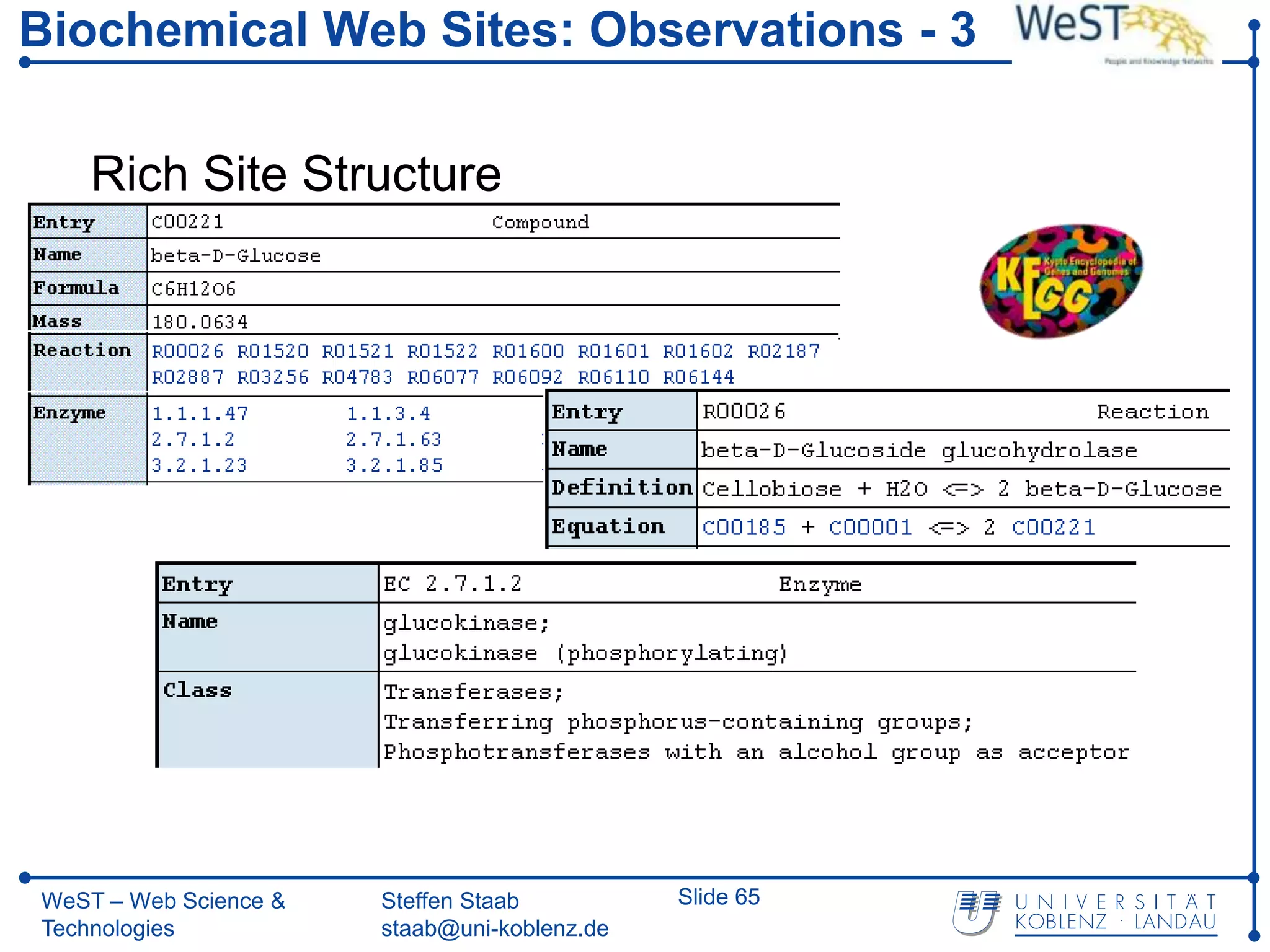



![Page-Level Wrapper Induction – 1
D1 = {C00221, beta-D-Glucose, …, R01520, 1.1.1.47,…}
O1 = {Entry, Name,…, Reaction, R00026, Enzyme,…, 3.2.1.21}
//*[text()]
D2 = {C00185, Cellobiose,…, R00306, 1.1.99.18,… }
O2 = {Entry, Name,…, Reaction, R00026, Enzyme,…, 3.2.1.21}
WeST – Web Science & Steffen Staab Slide 69
Technologies staab@uni-koblenz.de](https://image.slidesharecdn.com/informationextractionpucriov20120308-final-120312122126-phpapp01/75/Information-extraction-for-building-knowledge-basis-65-2048.jpg)

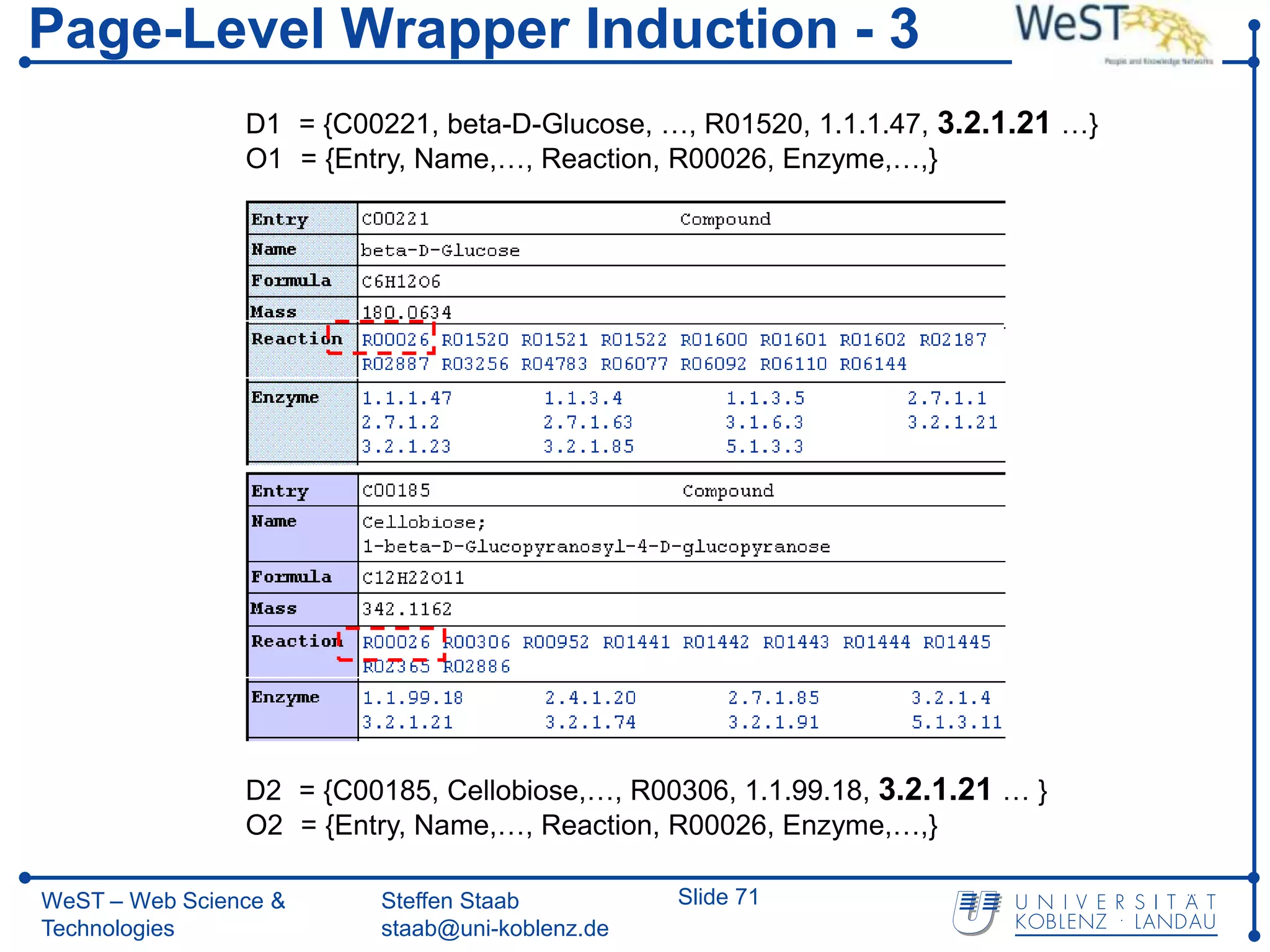
![Page-Level Wrapper Induction - 4
Selecting Labels for Data
html/…./table[1]/tr[8]/td[1]/…/code[1]/a[1]
(“1.1.1.47” )
html/…./table[1]/tr[6]/th[1]/…/code[1]/
(“Reaction”)
html/…./table[1]/tr[8]/th[1]/…/code[1]/
(“Enzyme”)
WeST – Web Science & Steffen Staab Slide 72
Technologies staab@uni-koblenz.de](https://image.slidesharecdn.com/informationextractionpucriov20120308-final-120312122126-phpapp01/75/Information-extraction-for-building-knowledge-basis-68-2048.jpg)
![Page-Level Wrapper Induction - 5
Anchor the Path
Enzyme - html/table[1]/tr[8]/th[1]/code[1]/
html/table[1]/tr[8]/td[1]/code[1]/a[1]
html/table[1]/tr[8]/td[1]/code[1]/a[2]
//*[text()=‘Enzyme’] ../…./../td[1]/code[1]/a[position()≥2]/text()
Pivot Relative Generalize
WeST – Web Science & Steffen Staab Slide 73
Technologies staab@uni-koblenz.de](https://image.slidesharecdn.com/informationextractionpucriov20120308-final-120312122126-phpapp01/75/Information-extraction-for-building-knowledge-basis-69-2048.jpg)







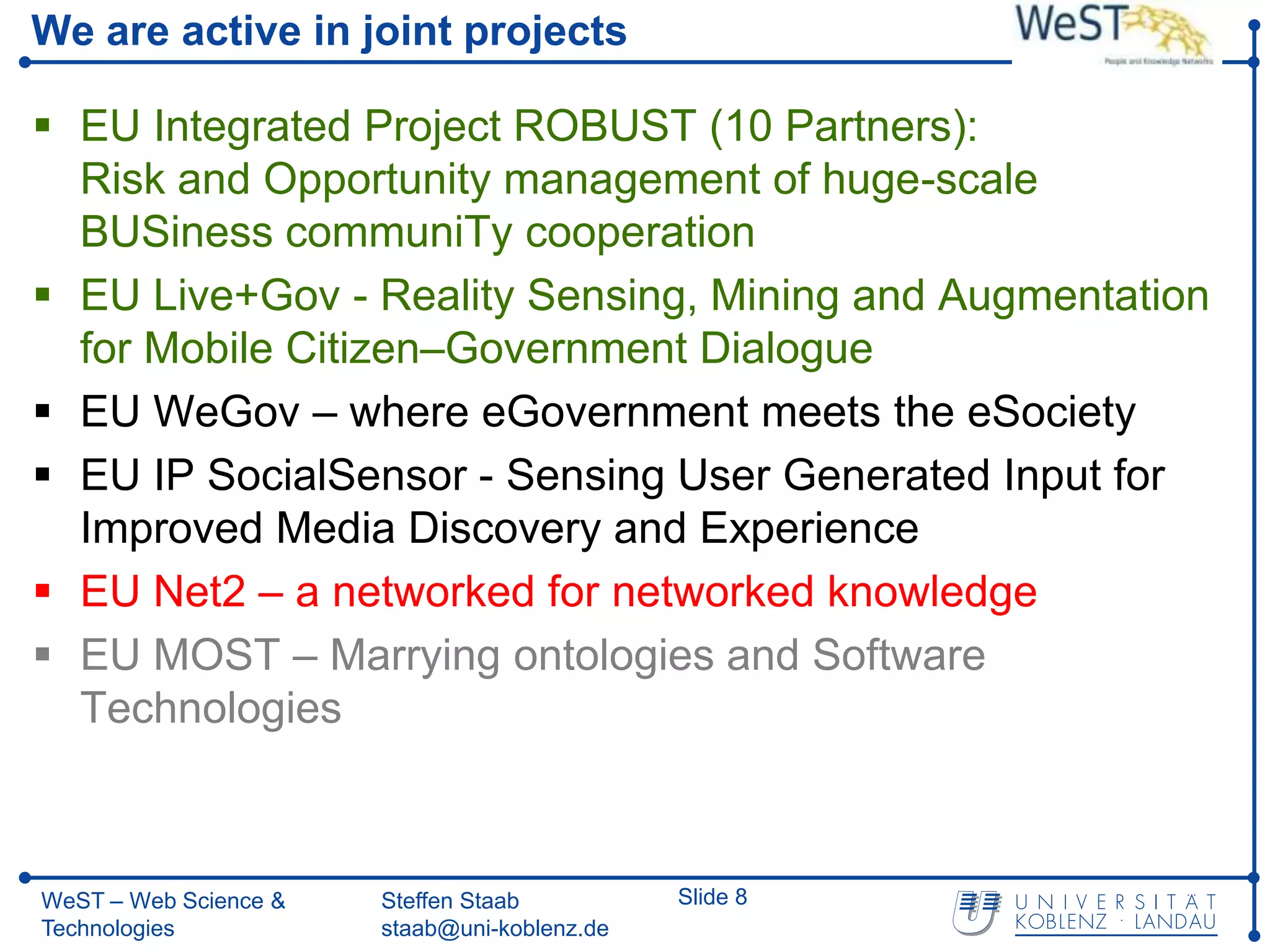
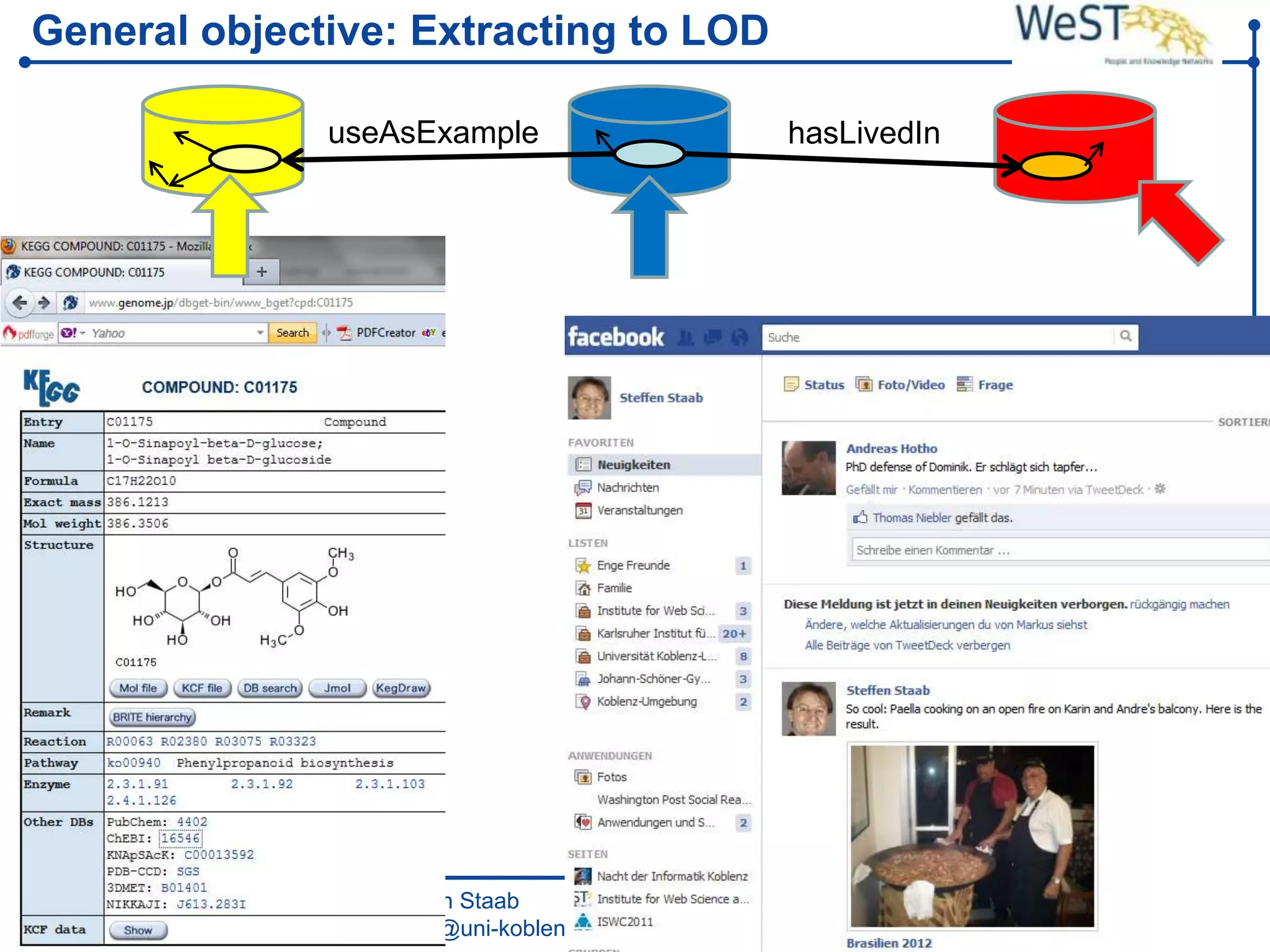
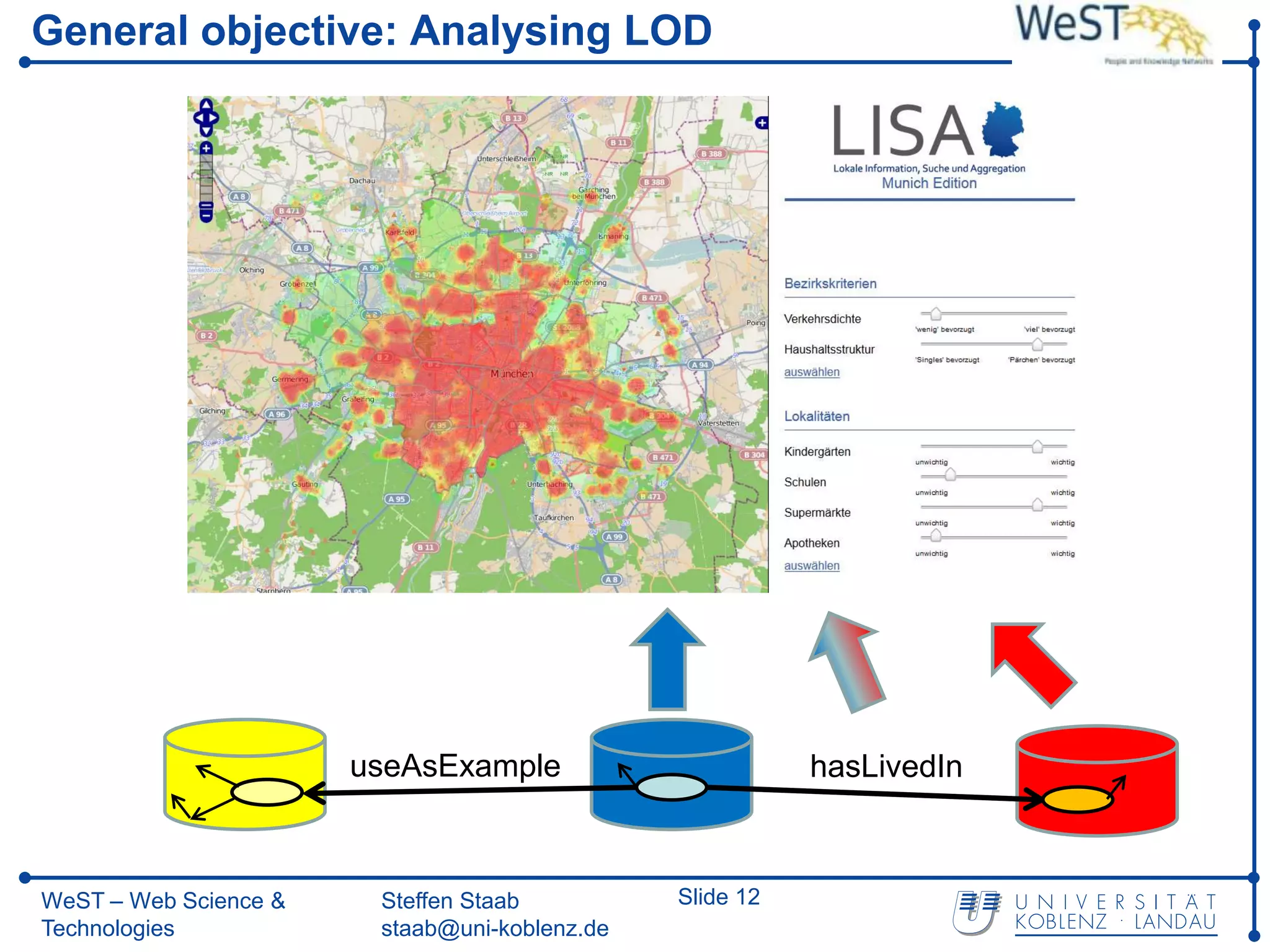
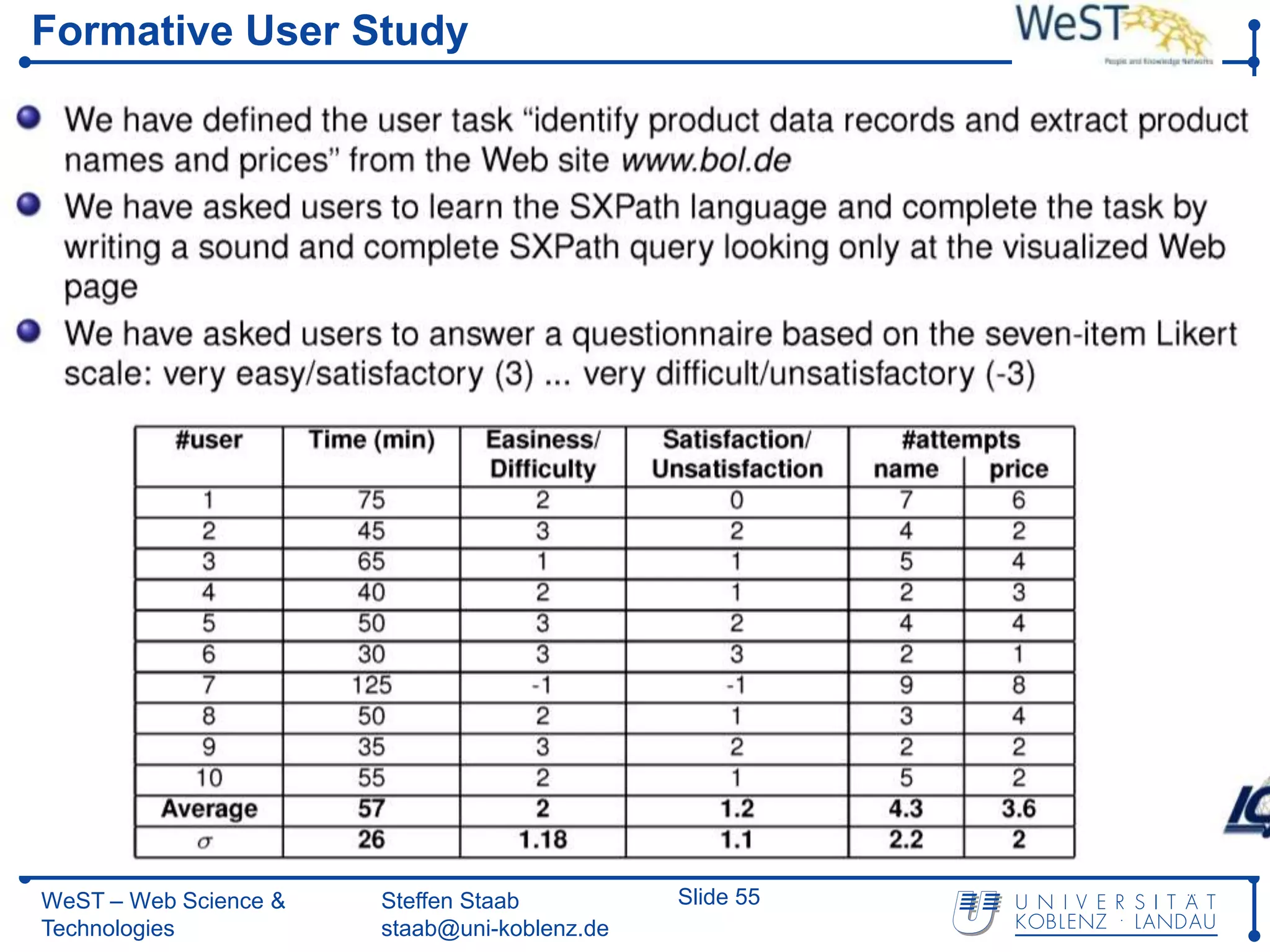
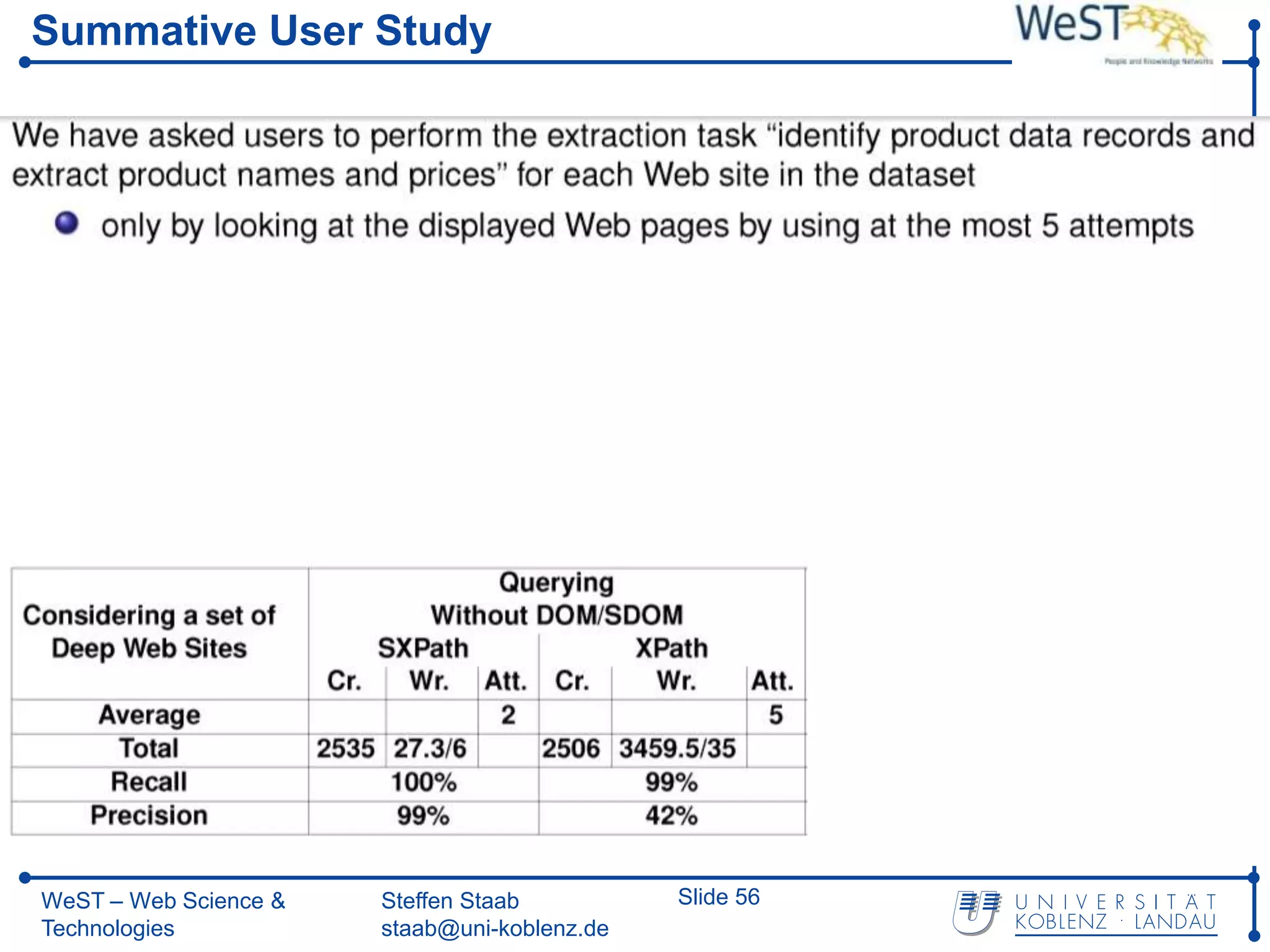
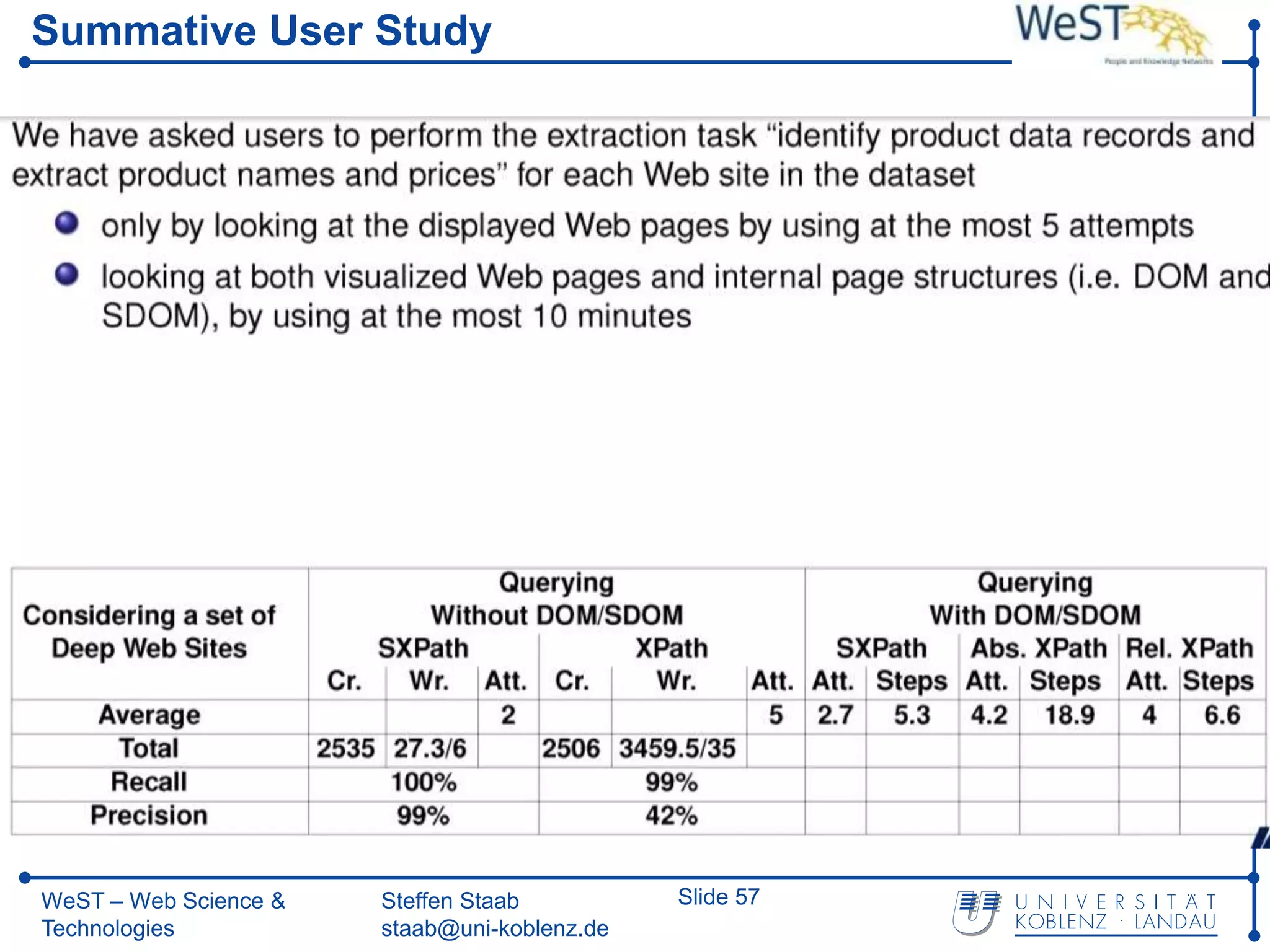
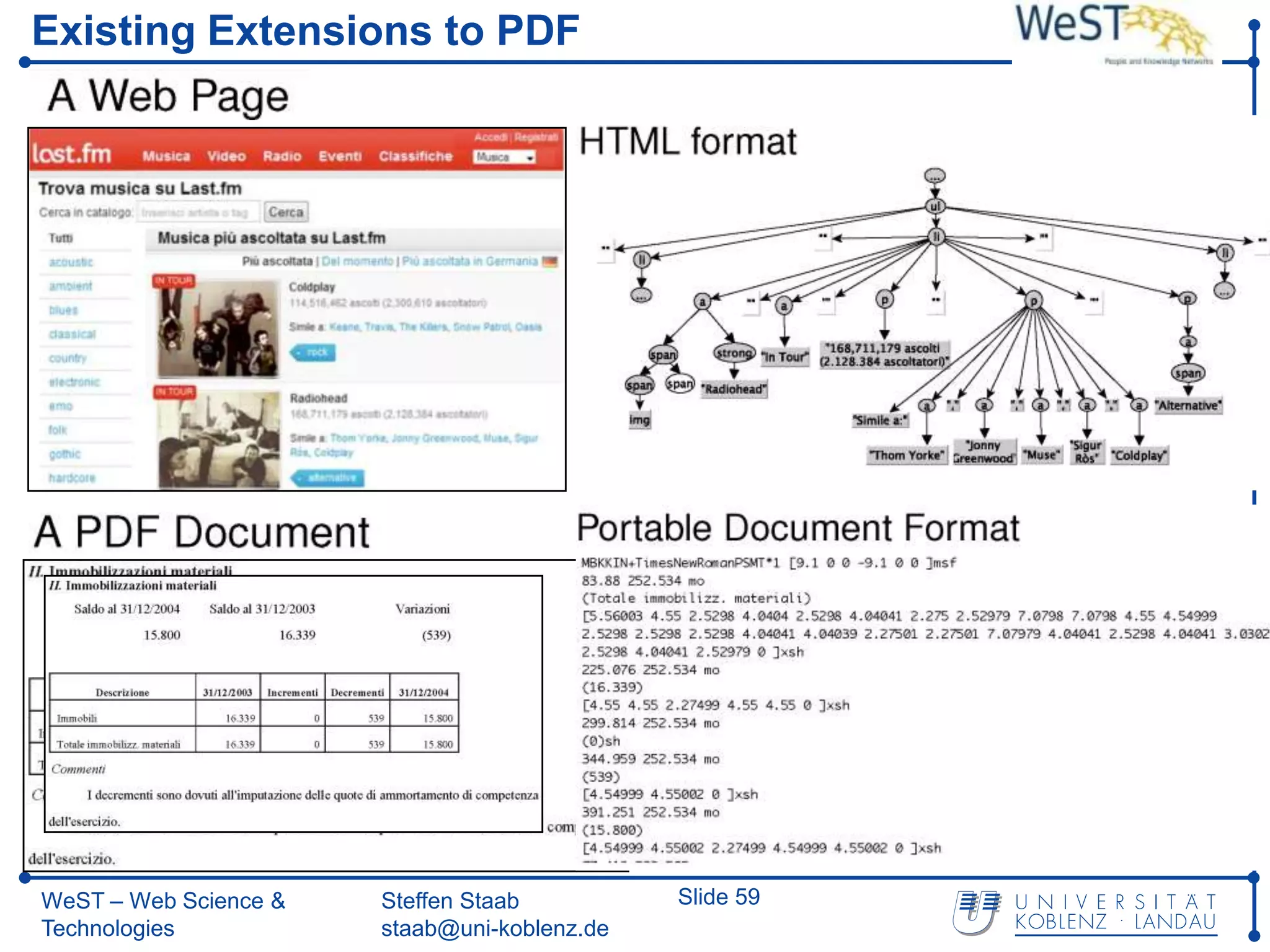
This document summarizes a presentation about the WeST (Web Science & Technologies) institute at the University of Koblenz Landau in Germany. WeST conducts research in areas like the semantic web, social web, multimedia web, and software web. It organizes conferences and schools, builds applications, and teaches master's programs in web science. WeST is also involved in several European Union projects related to risk management, open government data, e-government, social media, and linking ontologies and software technologies. The presentation provides an overview of WeST's research areas, projects, and educational activities.




















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














