Download to read offline







![Tracking User Behavior
About 75% of websites track user behavior across sites.
[Zhonghao Yu et al. WWW16]](https://image.slidesharecdn.com/webscience10-v3binclforgo-161130130142/75/10-Jahre-Web-Science-15-2048.jpg)




























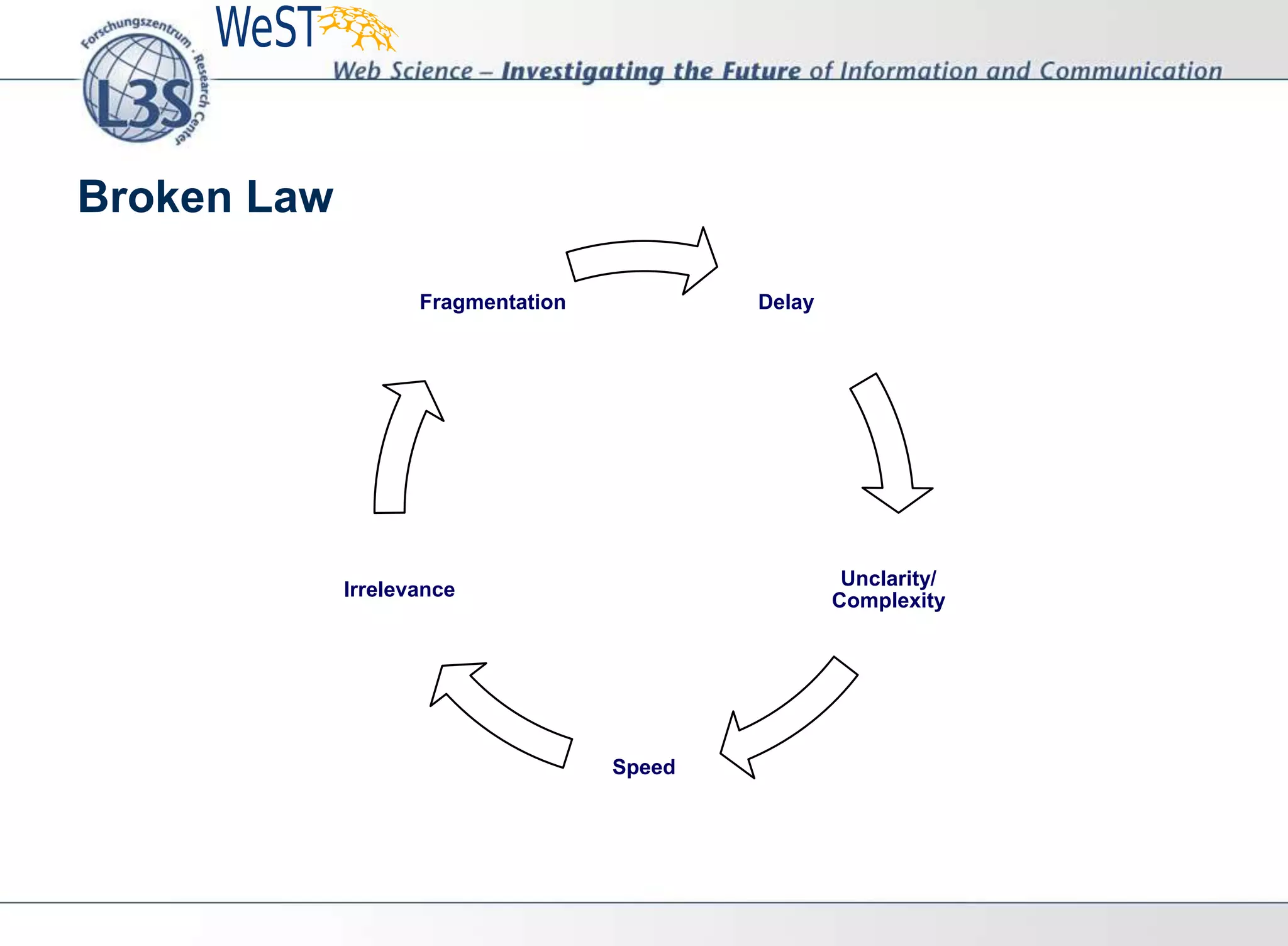


This document summarizes a presentation on the next 10 years of Web Science. It discusses social challenges like discrimination and trust, legal challenges regarding regulation and tracking, political challenges from misinformation and participation, and technical challenges from artificial intelligence and security. The presentation outlines the 10 year initiative of the Web Science Network of laboratories and highlights talks from researchers at companies like Google, Facebook, and Stanford. It promotes collaborative projects like the Web Science Observatory and Summer School.























































































